

机器学习系列(4) 线性回归
多元线性回归
一、多元回归的基本假设
- 线性性和可加性
线性性:X1每变动一个单位,Y相应变动a1个单位,与X1的绝对数大小无关
可加性:X1对Y的影响独立于其他变量 - 误差性之间相互独立
- 自变量之间相互独立
- 误差项的方差应该为常数
- 误差项应该呈正太分布
二、线性回归的基本原理
1.线性回归的任务,就是构造一个预测函数来映射特征矩阵X和标签值y的线性关系,这个预测函数本质急救室我们需要构建的模型,构建预测函数的核心就是找出模型的参数向量w

我们首先定义损失函数,然后通过最小化损失函数的某种变化来求解参数向量,以此将单纯的求解问题转化为一个最优化问题,在多元线性回归中,我们损失函数定义如下
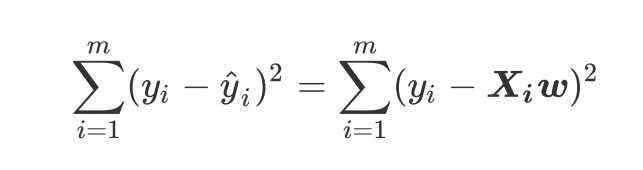
这个损失函数代表了向量y - y的L2范式平方结果,L2范式本质是欧式距离,y和y分别为真实标签和预测值,损失函数实在计算真实标签和预测值之间的距离。这个损失函数哼浪了我们构造的模型的预测结果和真实标签的差异,因此我们希望预测结果和真实结果差异性越小越好,我们把目标转化为

三、代码实现
导入数据集
from sklearn.linear_model import LinearRegression as LR
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.datasets import fetch_california_housing as fch
import pandas as pd
housevalue = fch()
X = pd.DataFrame(housevalue.data)
y = housevalue.target
print(X.shape, y.shape)
print(housevalue.feature_names)
X.columns = housevalue.feature_names
训练集测试集拆分
# 训练集测试集划分
x_train,x_test, y_train,y_test = train_test_split(X, y, test_size=0.3, random_state = 420)
for i in [x_train, x_test]:
i.index = range(i.shape[0])
x_train.shape
建模
# 建模
reg = LR().fit(x_train, y_train)
yhat = reg.predict(x_test)
yhat
# 模型具体参数
reg.coef_
*zip(x_train.columns, reg.coef_)] # 参数
# 截距
reg.intercept_
模型评估
# 模型评估
from sklearn.metrics import mean_squared_error as MSE
MSE(yhat, y_test) # 均方误差
# r2
from sklearn.metrics import r2_score
r2_score(yhat, y_test)
r2 = reg.score(x_test,y_test)
r2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号