
如何用 GPU 训练模型?
包括两步:
1)Convert parameters and buffers of all modules to CUDA Tensor.
2)Send the inputs and targets at every step to the GPU.
注意:模型和数据要迁移到同一块显卡上。
举个例子:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
#==============================================================================
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
#==============================================================================
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # -1 此处自动算出的是320
x = self.fc(x)
return x
model = Net()
# 把所建立的模型全部迁移到 GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#==============================================================================
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#==============================================================================
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
# 将输入、输出迁移到 GPU
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
#==============================================================================
# test
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
下面我们改进一下代码用一个更复杂的卷积神经网络来训练,首先定义一个如下的网络结构:
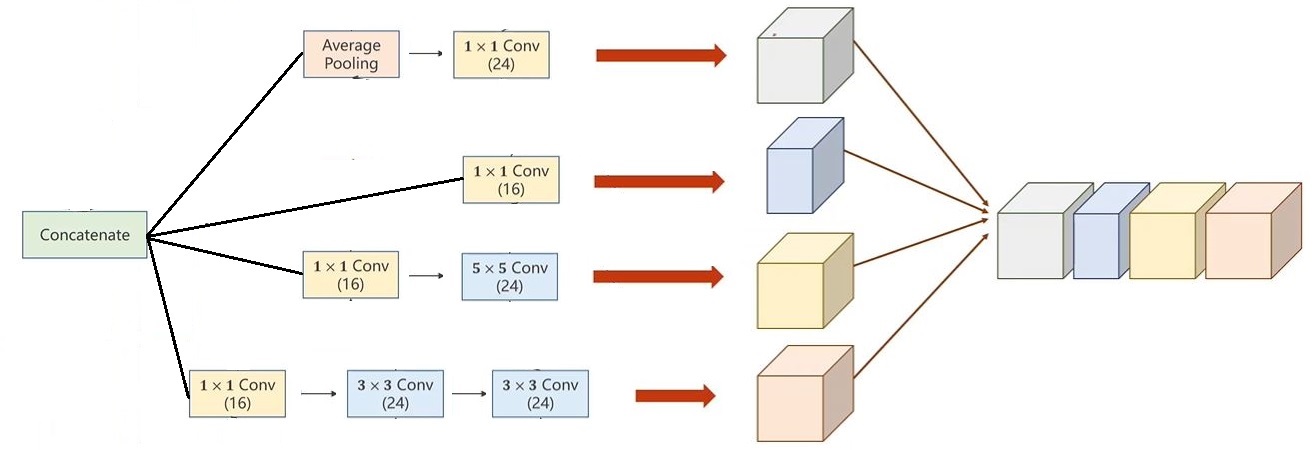
这个网络就是包含了各种尺寸的卷积核,因为我们并不知道哪种合适所以就都放在一起,训练的时候,合适的卷积核对应的值就会变大。代码如下:
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
def forward(self, x):
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) # b,c,w,h c 对应的是 dim=1
把这个网络加到我们之前设计的模型中,整体代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
#==============================================================================
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
#==============================================================================
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16
self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应
self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.pooling(self.conv2(x)))
x = self.incep2(x)
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
# 把所建立的模型全部迁移到 GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#==============================================================================
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#==============================================================================
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
# 将输入、输出迁移到 GPU
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
#==============================================================================
# test
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号