

可迭代对象
先上一张图,来描述一个大概的关系:
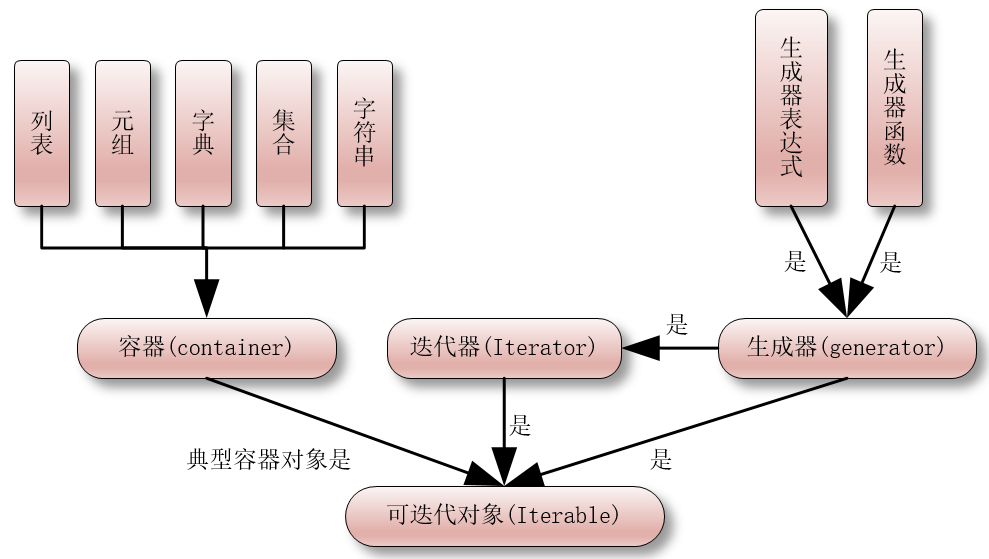
在Python世界里,一切皆对象。对象根据定义的维度,又可以分为各种不同的类型,比如:文件对象,字符串对象,列表对象。。。等等。
那什么对象才能叫做可迭代对象呢?实现了__iter__方法的对象就叫做可迭代对象,只有实现了__iter__方法的对象才能被for循环迭代。
1. 典型容器(container)
容器就是一个用来存储多个元素的数据结构,容器中的元素可通过迭代获取,一次性加载所有元素到内存。
for循环迭代的流程如下:
1)调用可迭代对象的__iter__方法返回一个迭代器对象(iterator),这里便解释了为什么只要实现了__iter__方法才能被for遍历。
2)不断调用迭代器的__next__方法返回元素。
3)直到迭代完成后,处理 StopIteration 异常。
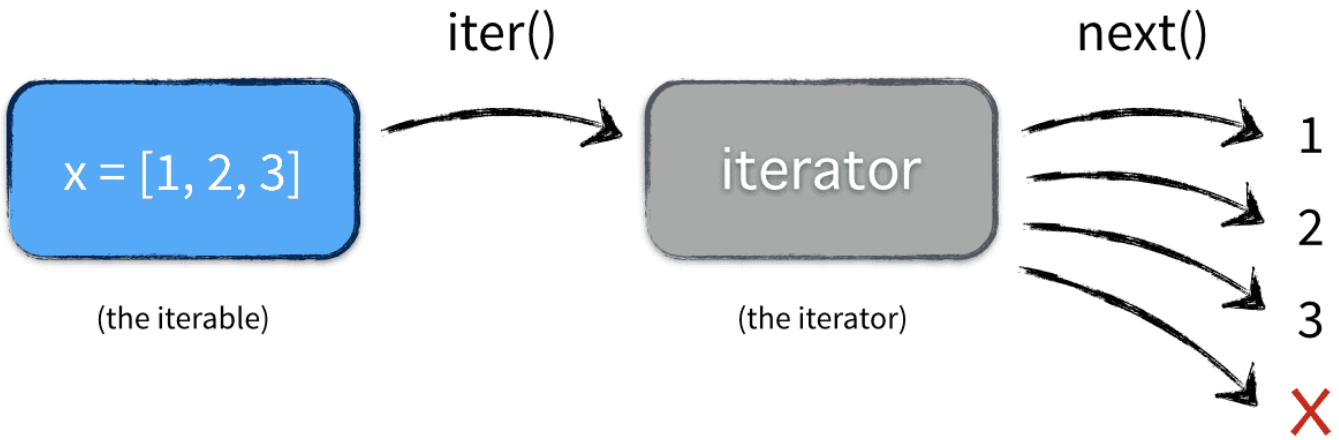
注:next()方法内部调用了对象的__next__()方法,iter()方法内部调用了对象的__iter__()方法。
from collections.abc import Iterable # 可迭代对象
from collections.abc import Iterator # 迭代器
x = [1, 2, 3]
print(isinstance(x, Iterable)) # True
print(isinstance(x, Iterator)) # False
for num in x: # 解释器解释完后其实变成这样子:for num in iter(x),也等价于:for num in x.__iter__()
print(num)
y = iter(x) # 我们来直接操作返回的这个迭代器对象
print(next(y)) # 1
print(next(y)) # 2
print(next(y)) # 3
Python内置的enumerate函数可以把一个list或者tuple变成可以返回索引-元素对的可迭代对象,这样就可以在for循环中同时迭代索引和元素本身。
season = ['spring','summer','fall','winter']
print(enumerate(season))
"""
output:
<enumerate object at 0x00000217E72FDEC0>
"""
print(list(enumerate(season))) # list函数可以将一个可迭代对象变成list
"""
output:
[(0, 'spring'), (1, 'summer'), (2, 'fall'), (3, 'winter')]
"""
for i, element in enumerate(season):
print(i,element)
"""
output:
0 spring
1 summer
2 fall
3 winter
"""
2. 迭代器(Iterator)
- 迭代器是一个带状态的对象。之所以说是带状态的对象是因为迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。
首先,迭代器必须能够获取下一个元素,故得有__next__方法,又迭代器本身也是可迭代对象,即也能被for循环遍历,所以必须同时实现__iter__和__next__方法。而
容器内部只实现了__iter__方法,它的遍历需要借助另外一个迭代器来完成。
1)__iter__():该方法返回一个实例化的迭代器对象
2)__next__():该方法返回下一个元素
注:对容器而言:里面实现的 __iter__ 方法返回的迭代器不是自己,而是任意一个实现了 __next__ 方法的对象,两个方法是分离的,换句话说:容器借助它人来
帮自己完成遍历。对迭代器而言:__iter__方法返回的迭代器实例就是自己,表示自身即是自己的迭代器,自己完成对自己的迭代。
- 迭代器不会一次性把所有元素加载到内存,而是需要的时候才生成返回结果(不同于容器)。
- 迭代器实现了__next__方法,所以可以直接通过next()函数来返回下一个元素。
下面我们来自定义一个迭代器类:
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器 a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己。
def __next__(self):
# print("call __next__")
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 10000: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值
obj = Fib()
for n in obj:
print(n)
# 第二次再迭代就没有输出了
for n in obj:
print(n)
a. 执行上面这个代码的时候,为什么程序是正常结束的,而 StopIteration 异常没有报出来?
解释:for会循环显式地侦听StopIteration。for语句的目的是循环由迭代器提供的序列,而StopIteration是正常的,预期的信号,告诉谁没有什么更多的产物。
for不捕获被迭代的对象引发的其他异常,只捕获 StopIteration。
b. 为什么第二次迭代会没有输出呢?
解释:迭代器对象是一个带状态的不可逆的对象,由于第一次迭代就已经把所有元素都输出了,状态意味着结束了,第二次再迭代自然也就没有元素输出了。
而容器是每次都会重新去获取一个新的迭代器,它的迭代器与自身分离,故它们就可以多次遍历。
如果遇到第二次遍历无输出的一些问题,可以看看是迭代器对象还是容器对象。
alist = [1, 2, 3]
for x in alist: # 等价于 for x in iter(alist),每次都返回一个新的迭代器
print(x)
# 再遍历,输出依然正常
for x in alist:
print(x)
3. 生成器(generator)
为什么要有生成器?通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,
不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面的类一样写__iter__()和__next__()方法了,只需要一个yiled关键字。
生成器的特点和迭代器一样:不会一次性把所有元素加载到内存,而是显示或者隐式调用 next 的时候才执行代码并生成返回结果(相同于迭代器,不同于容器)。
要创建一个generator,有很多种方法。
1)把一个列表生成式的[]改成(),就创建了一个generator
generator保存的是算法,每次可以调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
但是不断调用next(g)实在是太麻烦,正确的方法是使用for循环,因为generator也是可迭代对象,即也实现了__iter__方法。
g = (x * x for x in range(10))
print(type(g)) # <class 'generator'>
for n in g:
print(n)
2)通过函数返回一个生成器对象
理解生成器函数最重要的是理解它的执行流程:普通函数是顺序执行,遇到 return 语句或者最后一行函数语句就返回。而生成器函数则类似于条件等待机制,
在函数执行过程中遇到 yield 时就返回并挂起函数,当再次调用 next 或者 for 循环取下一个元素(隐式调用next) 时,原本等待在 yield 处的函数
就会继续往下走,直到再遇到一个 yield。举一个简单的例子:
def fib(max_value):
n, a, b = 0, 0, 1
while n < max_value:
yield b # 此处会不停地挂起、执行、挂起、执行...直到抛出StopIteration
a, b = b, a + b
n = n + 1
return 'done'
for x in fib(10):
print(x)
- 生成器也是可以嵌套的,就类似于递归,下面举一个先序遍历树的例子,构造的树形如下:
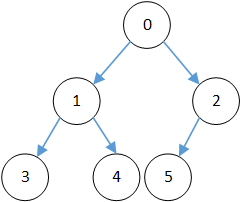 ==> 先序遍历输出:0 1 3 4 2 5
==> 先序遍历输出:0 1 3 4 2 5
class Node:
def __init__(self, value):
self._value = value
self._children = []
def __repr__(self):
return 'Node({!r})'.format(self._value)
def add_child(self, node):
self._children.append(node)
def __iter__(self):
return iter(self._children)
def depth_first(self):
yield self
for c in self: # Node类实现了__iter__方法,故可以被for迭代,返回的是 self._children 的迭代器,即实际上迭代的是 []
for e in c.depth_first(): # 由子迭代器返回元素
yield e # 然后自身再返回子迭代器返回的元素,并挂起,子迭代器也递归挂起
root = Node(0)
child1 = Node(1)
child2 = Node(2)
root.add_child(child1)
root.add_child(child2)
child1.add_child(Node(3))
child1.add_child(Node(4))
child2.add_child(Node(5))
for ch in root.depth_first():
print(ch) # 每次生成器返回一个 node 对象,并打印出该结点存储的 value
"""
output:
Node(0)
Node(1)
Node(3)
Node(4)
Node(2)
Node(5)
"""
生成器每次返回的是一个Node对象,那它是怎么嵌套的呢,下面给个示意图帮助理解:
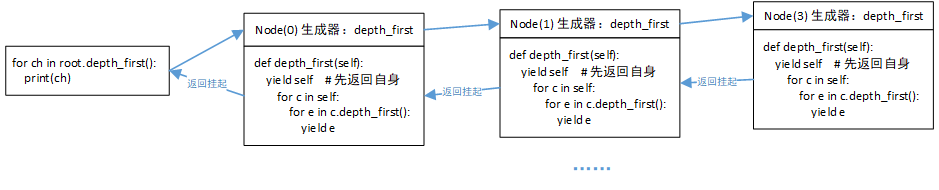
由嵌套的生成器层层返回结果,并挂起自身,然后最上层的生成器再返回并挂起。
- 迭代器内部的__iter__方法必须得返回迭代器实例,由于生成器是一个特殊的迭代器,所以可以将__iter__定义成生成器,for循环隐式调用next后得到一个生成器对象。
class Countdown:
def __init__(self, start):
self.start = start
def __iter__(self): # 定义成生成器,可以避免去实现__next__方法
n = self.start
while n > 0:
yield n
n -= 1
for rr in Countdown(30):
print(rr)
注:这种用类来封装生成器函数的做法,也可以通过内部的属性来记录更多的信息或者状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号