pycharm-webdriver
webdriver的含义
- webdriver(selenium2)是一个用于web应用程序的自动测试工具
- 提供了一套友好的api
- webdriver完全就是一套类库,不依赖于任何测试框架,除了必要的浏览器驱动
说明:api:应用编程接口说明webdriver类库内封装非常多的方法,要使用这些方法,就要友好的调用命名规则
webdriver元素定位方法
- id
- name
- class_name
- tag_name
- link_text
- partial_link_text
- xpath
- css
定位方式分类-汇总
1)id、name、class_name:为元素属性定位
2)tag_name:为元素标签名称
3)link_text、partial_link_text:为超链接定位(a标签)
4)xpath:为元素路径定位
5)css:为css选择器定位
元素定位书写步骤:
- 导入selenium包-----------form selenium import webdriver
- 导入time包-----------------form time import sleep)
- 实际化火狐----------------driver = webdriver.firefox()
- 打开注册-------------------driver.get(链接.............)
- 打开8种里的其中一种定位方法---------------driver.find_element_by_ xx("xxx")
- 使用.send_keys方法发送数据----------------.send_keys("随意输入要测试的数值")
- 暂停三秒------------------sleep(3)
- 关闭浏览器--------------quit()
在第四和第五步骤还有一种方法可以替代:
url
第一种写法:url="xx\\xx\\xx\\xx" xx是用来写路径
第二种写法:url=r"xx\xx\xx\xx"
第三种写法:file:///xx/xx/xx/xx
r作用:被r修饰的字符串,字符串中的转义符不做转义使用
\ 反斜杠为转义字符,所以必须两个\\
/ 斜杠 用于计算机的除法
第一种:id-定位方法
方法:find_elemt_by_id(属性)
案例:打开这个链接,用id的方法来找到用户名和密码的输入框,并输入admin和4563,输完之后暂停三秒再关闭浏览器

第二种:name-定位方法
方法:find_elemt_by_name(属性)
案例:打开这个链接,用name的方法来找到邮箱和密码的输入框,并输入email和76787随后暂停三秒并关闭浏览器
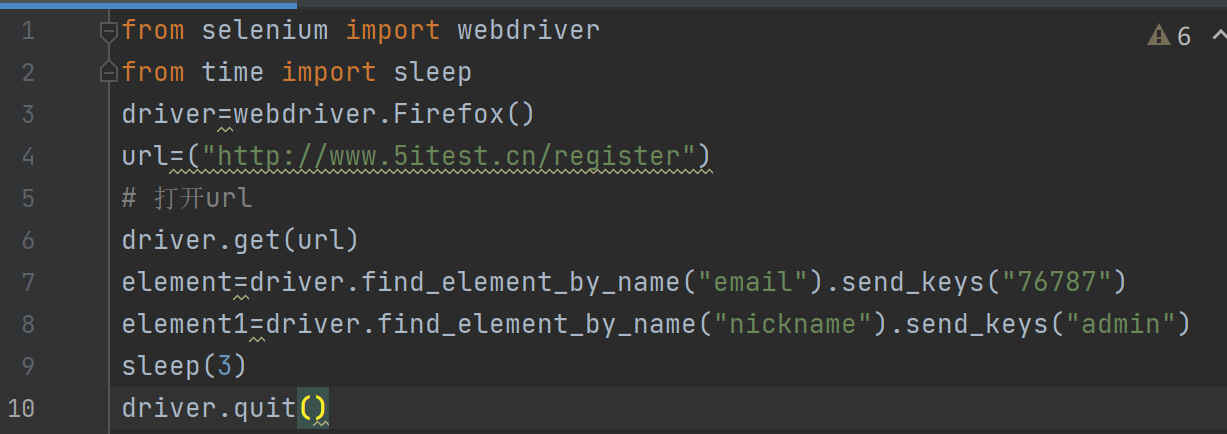
第三种:class_name-定位方法
方法:find_elemt_by_class_name(属性)
案例:打开这个链接,用class_name的方法来找到密码的输入框,并输入76787,随后暂停三秒再关闭浏览器
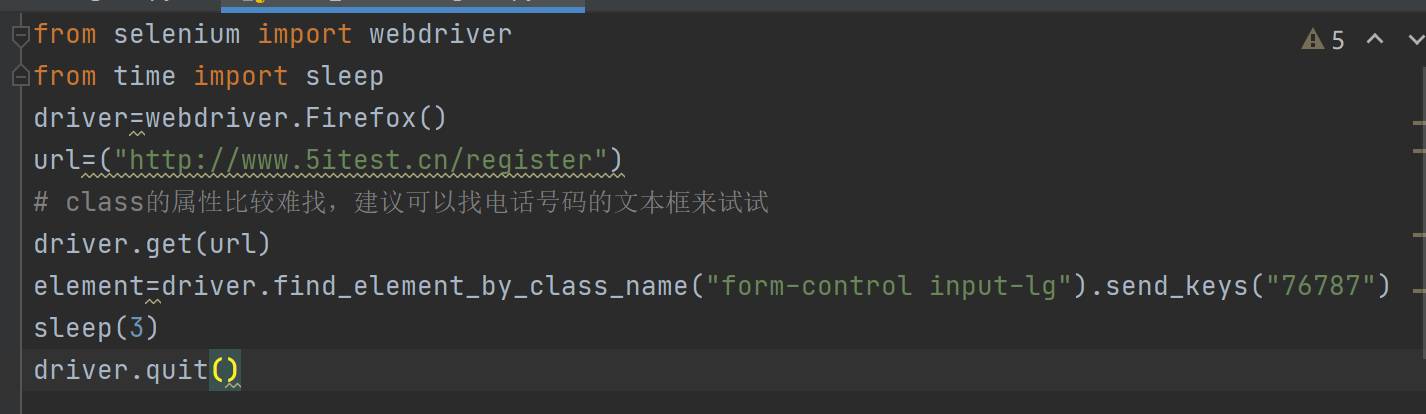
第四种:tag_name定位方法
通过标签名来定位,例如input或者a

方法:find_element_by_tag_name(标签名称)
前提:元素标签名在当前页面必须为唯一元素,或定位符合条件第一个元素
返回:符合条件的第一个元素
第五种:link_text定位方法
这个定位与前面4个不同的是,这个是用来定位超链接文本(<a>标签</a>)
方法:find_element_by_link_text(全部文本值)
注:需要传入a标签内的所有文本(空格也要)
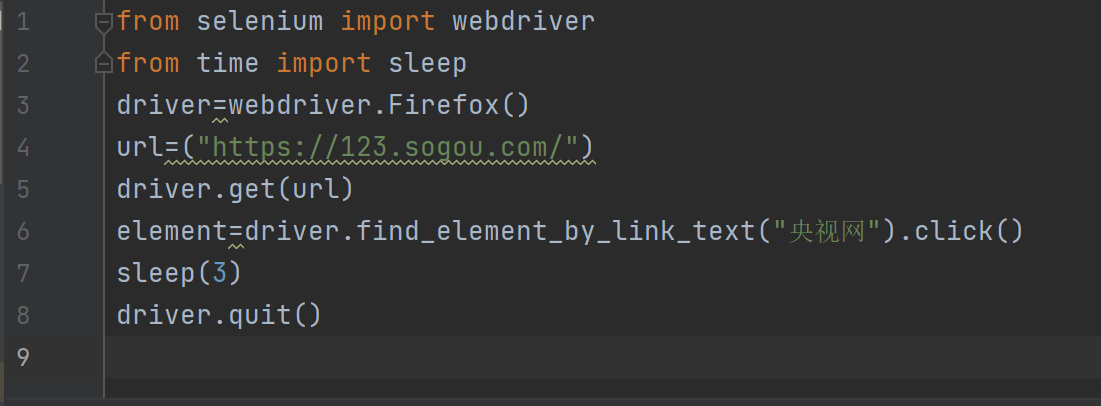
第六种:Partial_link_text定位方法
与link_text方法差不多相同,都是定位超链接,区别在于前者是局部匹配而后面的link是全部匹配
方法:find_element_by_partial_link_text(局部文本)
前面的6种方法都是find_element_by_xxx()
而这里要注意的是带s的方法:find_elements_by_xxx()
作用:定位查找所有符合条件的元素
返回的定位元素格式为数组(列表)格式
说明:列表数据格式的读取需要指定下标(下标从0开始)
例:
...
friver.find_elements_by_tag_name("input")[1].send.keys("xxx")
...
第七种:Xpath定位策略(方式)
1.路径-定位
绝对路径
相对路径
2.利用元素属性定位
3.层级与属性结合定位
4.属性与逻辑结合定位
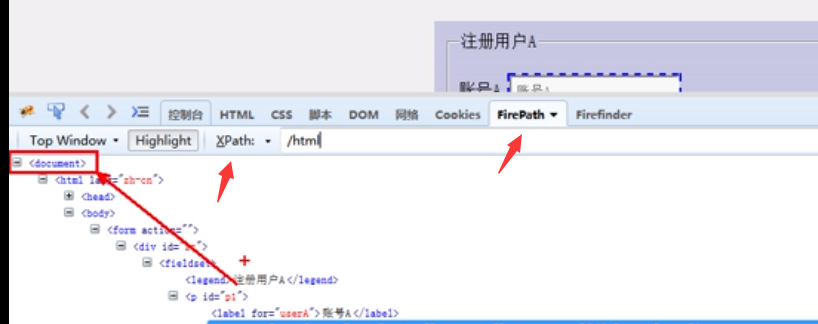
方法:dirver.find.element_by_xpath()
4种定位都用上面这个方法
注:绝对路径以单斜杠/开头,中间不能跳跃元素
相对路径以双斜杠//开头,后面必须跟标签名称或*,且还需要加个@来修饰例如://*[@xx=""]
在不知道路径的时候,鼠标放在要定位的那一行元素右键复制xpath 就不用再写路径了
示例:
利用元素属性定位-相对路径
注:绝对路径为
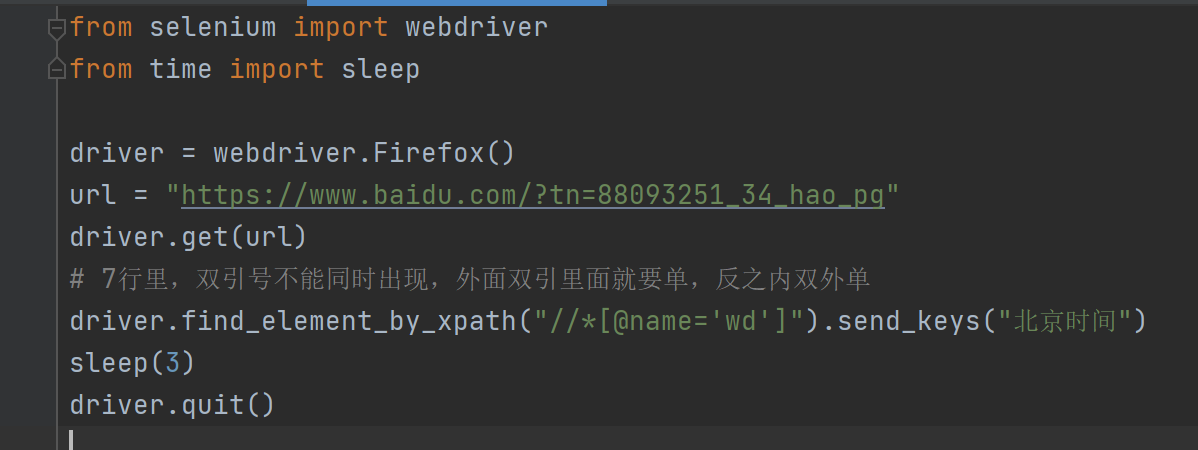
层级与属性结合定位
说明:要找的元素没有属性,但它的父级有
例://*[@id="p1"]/input
id=p1是父级里的属性,而input是当前元素的标签名
下面截图的右边的id=userA是定位元素里的属性,加与不加都可,加了更加固定元素的定位
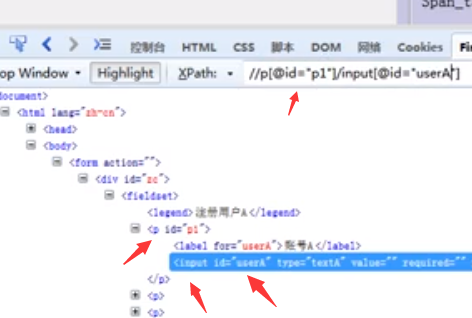
属性与逻辑结合定位
说明:解决元素之间相同属性重名问题,比如两个标签相同且属性也相同那么再书写的时候再多加一个属性,注意后面的@不要忘记加
例://*[id="tral" and @class= "tral" ]
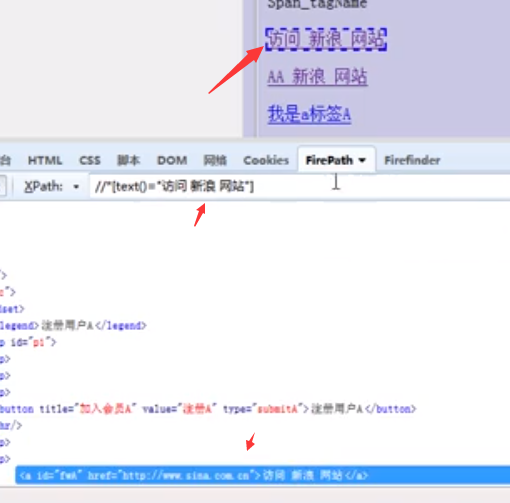
Xpath-延伸
//*text()="xxx"]----------文本内容是写在xxx里
//*[starts-with(@id,"xxx")]----------属性以xxx开头的元素,xxx可写完整也可不写完整
(感觉这个方法有点鸡肋,在不知道有什么属性的时候怎么写呢)

//*[contains-with(@id,"sxx")]-- --------属性中含有sxxx的元素
跟前面的方法差不多一样
注:在写属性的时候,字符必须得是连贯,不能是随意拎出来的
例:password属性
错误的:pwd、sod.....等
正确的:pas、wor.....等
第八种:css定位常用策略(方式)
- id选择器
- class选择器
- 元素选择器
- 属性选择器
- 层级选择器
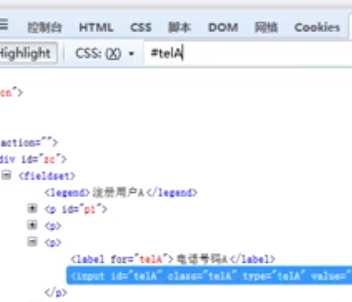
id选择器
说明:根据元素id属性来选择
格式:#id
如:#user (选择id属性值为user的所有元素)
方法:
find_element_by_css_selector("#xx")
class选择器
说明:根据元素class属性来选择(必须要有class属性,大部分输入电话号码的框才有class属性)
格式:.class
如:.tela (选择class属性为tela的所有元素)
方法:
find_element_by_css_selector(".xx")
元素选择器
说明:根据元素的标签名来选择
格式:element
如:input (选择所有input元素)
属性选择器
说明:根据元素的属性名和值来选择
格式:[attribute=value]
如:[type="password"] (选择所有type属性值为password的值)
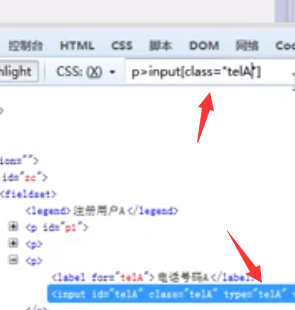
层级选择器
说明:根据元素的父子关系来选择
格式:element>element
如:p>input 则返回所有p元素下所有的input标签
提示:>可以用空格代替
如:p input 或者 p[type="password"] input
在父的标签里也可以写个属性固定住,那子级里就不用写属性了
空格与>可以灵活使用,到底是父写属性固定住还是子写属性固定住,也需要更加的灵活使用

css延伸
- [type^="p"]说明type属性以p字母开头的元素
- [type$="p"]说明type属性以d字母结束的元素
- [type*="w"]说明type属性含w字母的元素
最后↓↓↓
还有第九种方法(了解)
by类
这种是使用by类的封装的方法,所以需要导入by类包
首先先导包:from selenium.webdriver.common.by.import.By
方法:find_element(By.ID,"user")
需要两个参数,第一个参数为定位的类型有by提供。第二个参数为定位的具体方式
例子:
find_element(By.css_SELECTOR,"#email").send.............
find_element(By.XPATH,//*[@id="email"].send..............

 浙公网安备 33010602011771号
浙公网安备 33010602011771号