

Go学习(基础)
数据类型
数字类型
| 类型 | 描述 |
|---|---|
| int8/int16/int32/int64 | 有符号整数 |
| uint8/uint16/uint32/uint64 | 无符号整数 |
| float32/float64 | IEEE-754 32/64位浮点型数; 与Java的对应:float32 => float;float64 => double 自动类型推导为 float64 开发中建议尽量使用 float64,因为 math 包下面的计算都是用此类型 |
byte |
类似uint8 |
rune |
类似 int32 |
| uint | 32或64位 |
| int | 与 uint 一样大小 |
unitptr |
无符号整型,用于存放一个指针 |
八进制:增加前缀 0 来表示八进制数(如:077)
十六进制:增加前缀 0x 来表示十六进制数(如:0xFF)
10的幂运算:使用 E 来表示10的连乘(如:1E3 = 1*10^3 = 1000)
永远不要相信浮点数结果精确到了最后一位,也永远不要比较两个浮点数是否相等
(转化为二进制时会损失精度)
// 浮点数比较方案
func CompareFloat() {
var floatValue1 float32
floatValue1 = 10
floatValue2 := 10.0
p := 0.00001
// 使用 math 函数代替 == 比较
if math.Dim(float64(floatValue1), floatValue2) < p {
fmt.Println("floatValue1 和 floatValue2 相等")
}
}
复数类型
| 类型 | 描述 |
|---|---|
complex64/complex128 |
32/64位实部和虚部 |
与复数相对,我们可以把整型和浮点型这种日常比较常见的数字称为实数
复数是实数的延伸。通过两个实数(计算机中使用浮点数表示)构成,实部(real)和虚部(imag)
// a b 均为实数,i 称为虚数单位
// a = 0,z 为普通实数
// a ≠ 0,z 为纯虚数
z = a + bi
z := complex(a, b)
// 获取实部
a := real(z)
// 获取虚部
b := imag(z)
推荐使用 complex128 作为计算类型,因为相关函数大都使用这个类型的参数
字符串
标准库API:strings package - strings - pkg.go.dev
默认通过UTF-8编码的字符序列,当字符为ASCII码时则占用1个字节,其它字符根据需要占用2-4个字节
(可以包含非ANSI字符,如:「Hello, 学院君」)
Go 语言标准库并没有内置的编码转换支持
是一种不可变值类型
不支持单引号
对特定字符进行转义,可以通过 \ 实现
常见需要转义字符:
\n:换行符\r:回车符\t:tab 键\u或 \U :Unicode 字符\\:反斜杠自身
可以使用`构建多行字符串(+也可以实现)
func TestString() {
results := `
first line
second line
third line`
fmt.Println("results:", results)
}
切片:
// 是一个左闭右开的区间
func strSplice() {
str := "hello, world"
str1 := str[:5] // 获取索引5(不含)之前的子串
str2 := str[7:] // 获取索引7(含)之后的子串
str3 := str[0:5] // 获取从索引0(含)到索引5(不含)之间的子串
}
遍历方式:
- Unicode字符遍历:[for 循环](#for 循环)
- 字节数组遍历
// 两种方式中英文字符串遍历结果不同
// 字节数组遍历
for i := 0; i < len(str); i++ {
// 依据下标取字符串中的字符,值类型为 byte
fmt.Println("index:", i, ",value:", str[i])
}
// Unicode 字符遍历
str := "Hello, 世界"
for i, ch := range str {
// ch 的类型为 rune
fmt.Println(i, ch)
}
底层字符类型(对字符串中的单个字符进行了单独的类型支持):
byte,代表UTF-8编码中单个字节的值
(uint8类型的别名,两者是等价的,因为正好占据 1 个字节的内存空间)rune,代表单个 Unicode 字符
(int32类型的别名,正好占据 4 个字节的内存空间。rune操作可查阅 Go 标准库 unicode )
将Unicode字符编码转化为对应的字符,可以使用 string 函数进行转化
数组
数组是值类型
一维
// 声明(支持语法糖省略长度声明,编译期自动计算长度)
// 声明时数组的长度为一个常量或一个常量表达式(编译期即可计算结果的表达式)
var variable_name [capacity]data_type{element_values}
var variable_name [...]data_type{element_values}
var variable_name [capacity]data_type{index:value,index:value} //设置指定下标的值
// 初始化
// SIZE可以不写(括号必需保留),会自动根据值的个数进行推到并设置
var variable_name = [SIZE]variable_type{val_1,val_2,...,val_SIZE}
var variable_name = []variable_type{val_1,val_2,...,val_SIZE}
// 访问略
// 示例
var balance [10] int
balance := []int{1, 2, 5, 7, 8, 9, 3}
// 长度不满零值填充
balance := [10]int{1, 2, 5, 7, 8, 9, 3}
// 指定下标值,其余零值填充
balance := [10]int{1:2, 5:7}
多维
// 声明
var variable_name [SIZE1][SIZE2]...[SIZEN] variable_type
// 示例(二维数组)
var a1 [3][4] int
var a2 = [3][4]int{
{0, 1, 2, 3}, /* 第一行索引为 0 */
{4, 5, 6, 7}, /* 第二行索引为 1 */
{8, 9, 10, 11}, /* 第三行索引为 2 */
}
遍历参考[for 循环](#for 循环)
不指定长度的定义或引用,其实是切片(Slice)
作为形参
作为形参时,参数数组的长度必需与传入的数组一致
func method(arr [SIZE]type) [return_types] {}
// 没有长度的是切片
func method(arr []type) [return_types] {}
把一个大数组传递给函数会消耗很多内存。有两种方法可以避免这种现象:
- 传递数组的指针
- 使用数组的切片
切片(Slice)
切片与数组的区别:
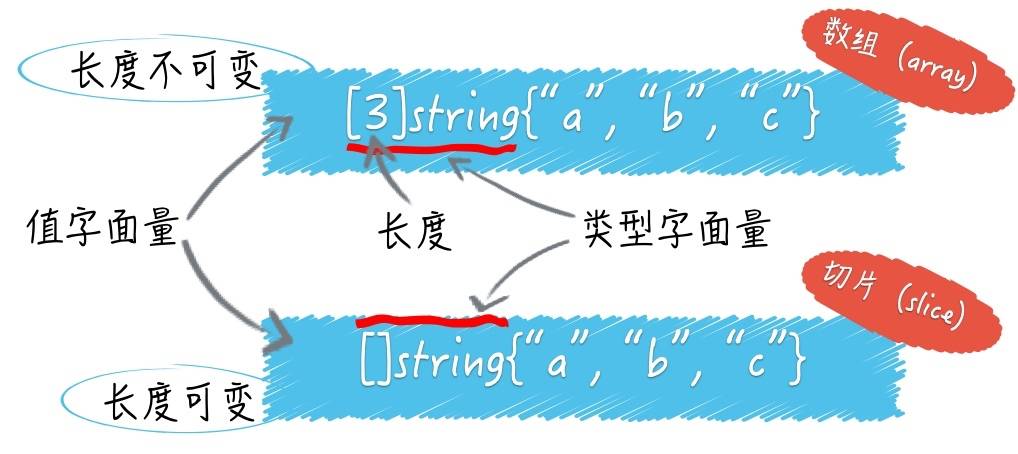
- 切片的类型字面量中只有元素的类型,没有长度
- 切片的长度可以随着元素数量的增长而增长(但不会随着元素数量的减少而减少)
- 切片是对数组的抽象
- 切片长度不固定,支持追加元素,支持动态扩容(数组长度不可变,切片就是为了解决这个问题)
- 切片未初始化之前会填充元素类型对应的零值,此时:
len=cap - 遍历参考[for 循环](#for 循环)
- 删除元素:通过切片的切片实现伪删除;
操作图示:Go Slice Tricks Cheat Sheet (ueokande.github.io) - 数据共享:基于切片创建切片时(两者数组指针都指向同一个数组),修改任意一个切片都会影响到另一个切片(解决:使用
append方法append方法会重新分配新的内存) 切片是引用类型
// 声明
// 1、常规声明(相比数组不定义长度)
var identifier []type = []data_type{v1, v2, v3, ... , vN}
// 2、使用 make() 声明
var identifier []type = make([]type, len)
identifier := make([]type, len [,cap])
// 3、基于数组|切片(通过数组|切片截取产生)
identifier := predefined_array|predefined_slice[startInclude:endExclude]
identifier := predefined_array|predefined_slice[startInclude:]
identifier := predefined_array|predefined_slice[:endExclude]
identifier := predefined_array|predefined_slice[:]
// 元素追加
old_slice = append(numbers, 1,2,3,4)
// 追加另一个切片
old_slice = append(numbers, other_slice...)
// 拷贝(以较小的长度为准;都是复制前N个元素)
copy(numbers1,numbers)
// 元素删除
slice3 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
// 使用append创建新的slice会分配新的内存空间,可以避免数据共享问题
slice4 := append(slice3[:0], slice3[3:]...) // append实现,删除前三个元素
slice5 := append(slice3[:1], slice3[4:]...) // append实现,删除中间的三个元素
slice6 := append(slice3[:0], slice3[:7]...) // append实现,删除最后三个元素
slice7 := slice3[:copy(slice3, slice3[3:])] // copy实现,删除开头前三个元素
事实上,使用直接创建的方式来创建切片时,Go 底层还是会有一个匿名数组被创建出来,然后调用基于数组创建切片的方式返回切片,只是上层不需要关心这个匿名数组的操作而已。
所以,最终切片都是基于数组创建的,切片可以看做是操作数组的指针
指针&长度&容量解释:
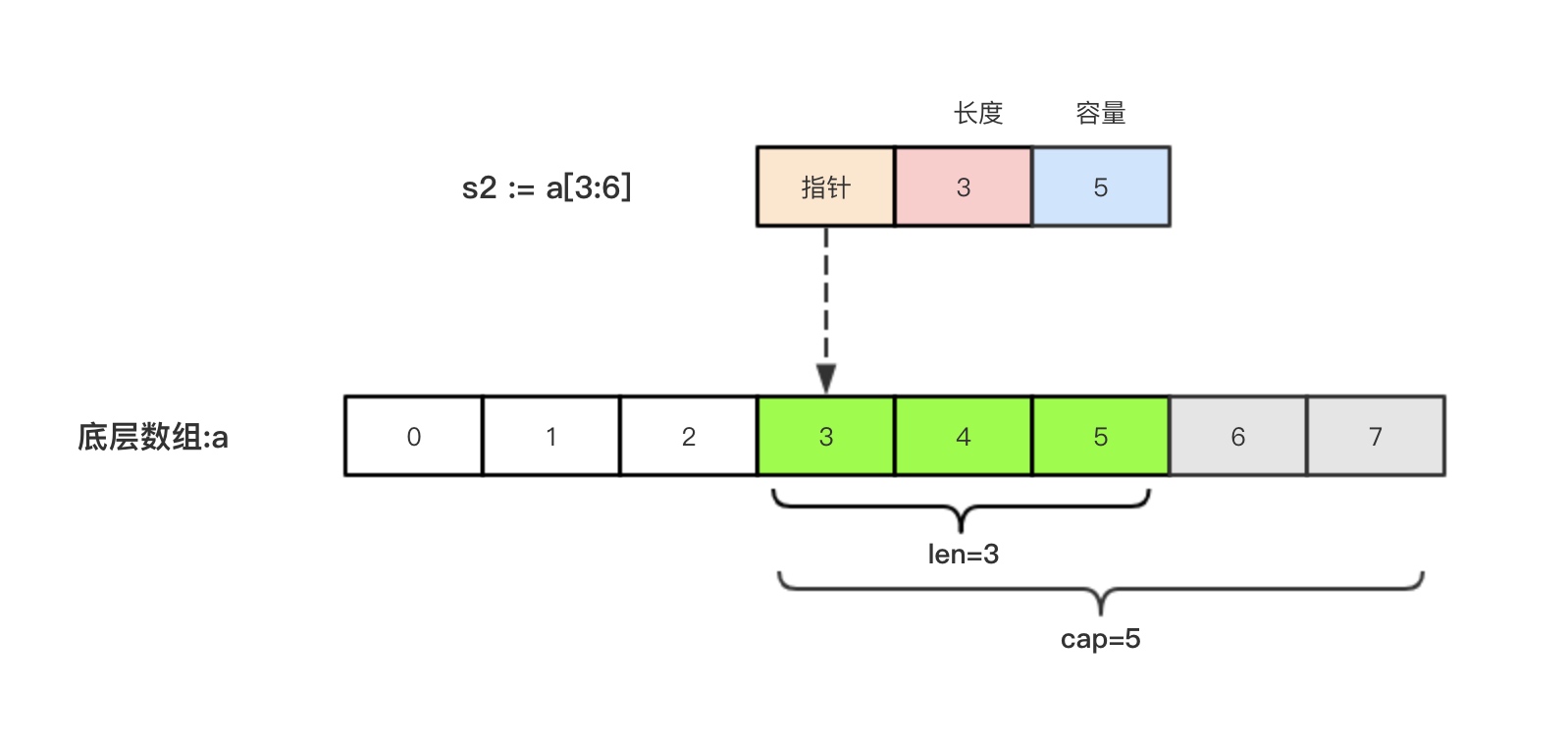
指针:指向数组起始下标
长度:对应切片中元素的个数
容量:切片起始位置到底层数组结尾的位置(可分配的存储空间)
一个切片的容量初始值根据创建方式的不同而不同:
- 对于基于数组和切片创建的切片,默认容量是从切片起始索引到对应底层数组的结尾索引
- 对于通过内置
make函数创建的切片,在没有指定容量参数的情况下,默认容量和切片长度一致
字典(Map)
- 使用
hash实现,是一种无序的键值对集合 - 如果仅仅是声明,此时
map = nil,不能赋值;必需初始化后才能进行赋值
【初始化方式:make()或直接初始化】 - 声明
map的key类型时,要求数据类型必须是支持通过==或!=进行判等操作的类型;为了提高性能,类型长度越短越好(通常设置为整型或长度较短的字符串)
【底层使用哈希表实现;出现哈希冲突时,使用原始键判等】
/* 声明变量,默认 map 是 nil */
var map_variable map[key_data_type]value_data_type
/* 使用 make 函数 */
map_variable = make(map[key_data_type]value_data_type)
// 判断key是否存在于map中
// 如果exists=true,则value为对应的值
value, exists := map_variable[key]
// 删除元素
delete(map_variable, key)
// 示例
// 分别定义(或者 := 定义并初始化)
var testMap = map[string]int
// 此时 testMap == nil,不能添加键值对
// testMap["three"] = 3 // panic: assignment to entry in nil map
// 1、直接初始化
testMap = map[string]int{
"one": 1,
"two": 2,
}
// 2、使用 make() 初始化
testMap = make(map[string]int)
testMap["one"] = 1
testMap["two"] = 2
指针与unsafe.Pointer
变量本质是对一块内存空间的命名,可以通过引用变量名来使用这块内存空间存储的值;指针则用来指向这些变量值所在的内存地址的值
- 指针变量通常缩写为
ptr - 赋值必需是对应变量的内存地址,即
ptr = &var_name - 在指针类型前面加上
*号(val = *ptr,间接引用符)来获取指针所指向的内容 - 格式化输出时,可以通过
%p来标识指针类型
- 为开发者提供操作变量对应内存数据结构的能力
- 提高程序的性能
指针指向的内存地址的大小是固定的,32位机器上占 4 个字节,64位机器上占 8 个字节
(与指向内存地址存储的值类型无关)
// 声明
var var_name *var_type
var var_name new(var_type)
// 示例
a := 100
var ptr *int // 声明为指针类型 ==> 本身是一个内存地址值,需要通过内存地址进行赋值
ptr = &a // 初始化指针类型值为变量a的内存地址(& 可以获取变量所在的内存地址)
fmt.Println(ptr) // 内存地址:0xc0000aa058
fmt.Println(*ptr) // 该地址内存储的值:100
var ip *int /* 指向整型 */
var fp *float32 /* 指向浮点型 */
空指针
- 当一个指针被定义后没有分配到任何变量时,它的值为
nil,即空指针。 - 在概念上
nil和其它语言的null、None、nil、NULL一样,都指代零值或空值。
unsafe.Pointer
unsafe.Pointer是一个万能指针,可在任何指针类型之间做转化,绕过了Go的安全机制,
是一个不安全的操作uintptr是 Go 内置的可用于存储指针的整型,而整型是可以进行数学运算的!因此,将unsafe.Pointer转化为uintptr类型后,就可以让本不具备运算能力的指针具备了指针运算能力
是特别定义的一种指针类型,可以包含任意类型变量的地址
官方说明:
- 任何类型的指针都可以被转化为
unsafe.Pointer; unsafe.Pointer可以被转化为任何类型的指针;uintptr可以被转化为unsafe.Pointer;unsafe.Pointer可以被转化为uintptr。
// 规则 1 2
i := 10
var p *int = &i
// int 类型指针先转换为 unsafe.Pointer,再转换为 *float32
var fp *float32 = (*float32)(unsafe.Pointer(p))
*fp = *fp * 10
fmt.Println(i) // i=100
// 规则 3 4
arr := [3]int{1, 2, 3}
ap := &arr
// unsafe.Sizeof 获取数组元素偏移量
// 获取到arr的指针,通过unsafe.Pointer转化为uintptr类型,再加上数组元素偏移量,
// 即得到该数组第二个元素的内存地址,后通过unsafe.Pointer将其转化为int类型指针赋值给sp指针,并进行修改
sp := (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(ap)) + unsafe.Sizeof(arr[0])))
*sp += 3
fmt.Println(arr) // arr=[1 5 3]
指针数组
var ptr [SIZE]*type
// 示例:整数型指针数组
var ptr [5]*int
指向指针的指针
一个指针变量存放的是另一个指针变量的地址
var ptr **type
// 示例
var ptr **int
访问指向指针的指针变量值需要使用两个*号
func method() {
a := 3000
var ptr *int
var pptr **int
/* 指针 ptr 地址 */
ptr = &a
/* 指向指针 ptr 地址 */
pptr = &ptr
/* 获取 pptr 的值 */
fmt.Printf("变量 a = %d\n", a)
fmt.Printf("指针变量 *ptr = %d\n", *ptr)
fmt.Printf("指向指针的指针变量 **pptr = %d\n", **pptr)
}
指针作为形参
func method(x, y *var_type) {
// fixme 内部使用都需要满足 *x *y 格式(都是通过内存地址操作对应的值)
}
流程控制
条件语句
// if
if condition {
// do something
}
// if...else...
if condition {
// do something
} else {
// do something
}
// if...else if...else...
if condition1 {
// do something
} else if condition2 {
// do something else
} else {
// catch-all or default
}
- 条件语句不需要使用圆括号将条件包含起来
(); - 无论语句体内有几条语句,花括号
{}都是必须存在的; - 左花括号
{必须与if或者else处于同一行; - 在
if之后,条件语句之前,可以添加变量初始化语句,使用;间隔,
比如:if score := 100; score > 90 { work_code }
分支语句
Switch
-
不需要用
break来明确退出一个case
只有在case中明确添加fallthrough关键字,才会继续执行紧跟的下一个case -
单个
case中,可以出现多个结果选项(通过逗号,分隔) -
所有
case候选值必需同switch变量(表达式)相同类型(否则编译错误) -
有两种写法
//变量 var_name 可以是任何类型,而 val1 和 val2 则可以是同类型的任意值 // 1、精确匹配 switch var_name { case val1: // 匹配项中不需要添加 break(在下一个case出现之前当前case自动结束) ... case val2, val3: // 合并分支;case 中可以存在多个 value ... case val4: // 如果一个case中没有业务逻辑,Go认为这是一个空语句,会直接退出(也不会执行default) // 如果希望当前case执行完成后继续执行下一个case,声明一个 fallthrough 即可 case val5: // 业务代码 ... default: ... } // 2、条件匹配(不设定switch之后的表达式) var_name := some value switch { case condition(A): // 业务代码 case condition(B): // 业务代码 default: // 默认处理 }
Type Switch(fixme)
switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际存储的变量类型
switch x.(type){
case type:
statement(s)
case type:
statement(s)
/* 你可以定义任意个数的case */
default: /* 可选 */
statement(s)
}
实例:
func method() {
// 定义接口
var x interface{}
switch i := x.(type) {
case nil:
fmt.Printf(" x 的类型 :%T", i)
case int:
fmt.Printf("x 是 int 型")
case float64:
fmt.Printf("x 是 float64 型")
// case 项也可以是 func
case func(int) float64:
fmt.Printf("x 是 func(int) 型")
// 可以测试多个可能符合条件的值
case bool, string:
fmt.Printf("x 是 bool 或 string 型")
default:
fmt.Printf("未知型")
}
}
Select(fixme)
- 与操作系统中的
select比较相似- 与
switch有相似的控制结构,但这些case中的表达式必须都是Channel的收发操作
- 是一个控制结构;
- select 随机执行一个可运行的 case;
- 如果没有 case 可运行,select 将阻塞,直到有 case 可运行;
- 默认的 default (如果存在)必需可以正常执行
select {
case communication clause :
statement(s)
case communication clause :
statement(s)
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s)
}
- 每个 case 都必须是一个
Channel - 所有
Channel表达式都会被求值 - 所有被发送的表达式都会被求值
- 如果任意某个
Channel可以执行,它就执行;其他被忽略 - 如果有多个 case 可以运行,select 会随机公平的选出一个执行;其他被忽略
- 如果没有 case 可以运行:
- 存在 default ,执行 default
- 没有 default,阻塞直到某个
Channel可以进行(Go 不会对 channel 或值进行求值)
select的知识点小结如下:
- select 语句只能用于信道的读写操作
- select 中的 case 条件(非阻塞)是并发执行的,select 会选择先操作成功的那个 case 条件去执行,如果多个同时返回,则随机选择一个执行,此时将无法保证执行顺序。对于阻塞的 case 语句会直到其中有信道可以操作,如果有多个信道可操作,会随机选择其中一个 case 执行
- 对于 case 条件语句中,如果存在信道值为 nil 的读写操作,则该分支将被忽略,可以理解为从 select 语句中删除了这个 case 语句
- 如果有超时条件语句,判断逻辑为如果在这个时间段内一直没有满足条件的 case ,则执行这个超时 case 。如果此段时间内出现了可操作的 case ,则直接执行这个 case 。一般用超时语句代替 default 语句
- 对于空的 select{} ,会引起死锁
- 对于 for 中的 select{} ,也有可能会引起 cpu 占用过高的问题
循环语句
- 不支持
whie和do-while结构的循环语句 - 可以通过
for-range结构对可迭代集合进行遍历 - 支持
continue和break来控制循环 - 支持高级的
break停止指定循环:break label(label是自定义的循环名称,同Java)
循环类型
for 循环
// 三种形式,只有一种使用分号
// 1、与 C 的 for 同(同 Java ,没有括号)
for init; condition; post { }
for i := start; i < end; i++ { }
// 2、与 C 的 while 同
for condition { }
// 3、与 C 的 for(;;) 同
for { }
// 使用 break 结束循环
【for-range】for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环
for key, value := range oldMap {
newMap[key] = value
}
示例:
func method() {
numbers := [6]int{1, 2, 3, 5}
for i, x := range numbers {
fmt.Printf("第 %d 位 x 的值 = %d\n", i, x)
}
}
嵌套循环
// 同 Java ,没有括号
for [condition | ( init; condition; increment ) | Range]
{
for [condition | ( init; condition; increment ) | Range]
{
statement(s)
}
statement(s)
}
跳转语句
break & contine
- 通过
break语句跳出循环,通过continue语句进入下一个循环 - 高级的
break停止指定循环:break label(label是自定义的循环名称,同Java)
goto(不建议使用)
可以无条件的转移到过程中指定的行
通常与条件语句配合使用,实现条件转移,构成循环、跳出循环的等功能
一般不建议使用goto,以免造成程序流程混乱,使程序难以理解或调试困难
面向对象
- 由一系列具有相同类型或不同类型的数据构成的数据集合(类似
Java中的类) - 没有
class、extends、implements之类的关键字和相应的概念,借助结构体实现类的声明 - 不支持构造函数、析构函数,通过定义
NewXXX这样的全局函数作为类的初始化函数 - 指针方法与值方法(Go 语言不支持隐藏的
this指针,所有的东西都是显式声明) toString实现:方法名固定为String;手动实现;无需显示调用- 使用点号 (
.) 操作符访问结构体成员,格式为:"结构体.成员名"
new() vs. make()
都在堆上分配内存,但行为不同,适用于不同的类型
new(T)为每个新的类型 T 分配一片内存,初始化为 0 并返回类型为 *T 的内存地址
返回一个指向类型为 T,值为 0 的地址的指针,适用于值类型数组、结构体,相当于 &T{}make(T)返回一个类型为 T 的初始值,只适用于三种内建的的引用类型:切片、map、channel
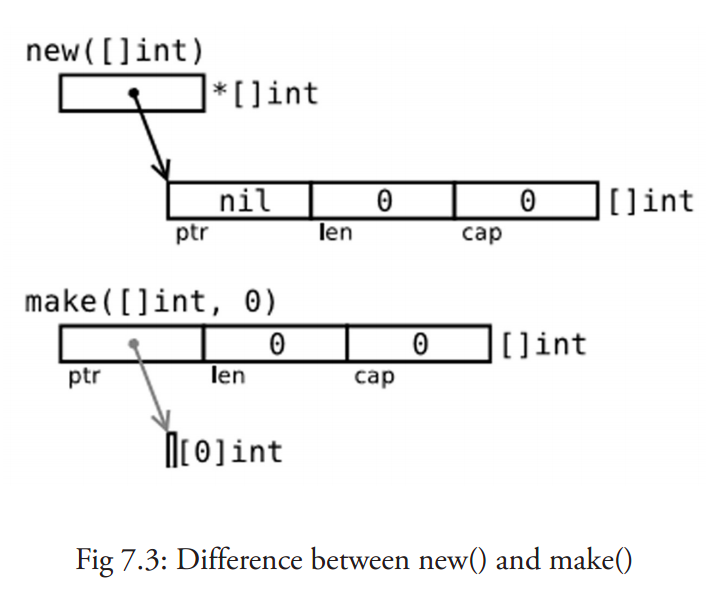
定义与初始化
// 结构体声明
type struct_variable_type struct {
field1 type
field2 type
...
field3 type
}
// 结构体变量声明
var variable_name struct_variable_type
variable_name := structure_variable_type {value1, value2...valueN}
// 或者定义 NewXXX 方法
/* 结构体定义 */
type Circle struct {
radius float64
}
func NewCircle(radius float64) *Circle{
return &Circle(radius: radius)
}
成员方法
在 func 和方法名之间声明方法所属的类型(有的地方将其称之为接收者声明)
// 该方法属于 Circle 类型对象中的方法
func (c Circle) getArea() float64 {
//c.radius 即为 Circle 类型对象中的属性
return 3.14 * c.radius * c.radius
}
// 方法定义没错,但不属于 Circle 类型对象的方法
func getArea2(c Circle) float64 {
return math.Pi * c.radius * c.radius
}
// 方法可以接收入参
func (c Circle) getPerimeter(x, y int) float64 {
fmt.Println("x=", x, ",y=", y)
return math.Pi * c.radius * 2
}
// circle.SetRadius1(100),circle的radius不会变
func (c Circle) SetRadius1(radius float64) {
c.radius = radius
}
// circle.SetRadius2(100),circle的radius会设置为参数值
func (c *Circle) SetRadius2(radius float64) {
c.radius = radius
}
func main() {
var c1 Circle
c1.radius = 10.00
// 方法调用
fmt.Println("Area of Circle(c1) = ", c1.getArea())
// getArea2 不是 Circle 类对象的方法
// fmt.Println("Area of Circle(c1) = ", c1.getArea2())
area := getArea2(c1)
fmt.Println("area = ", area)
fmt.Println("Perimeter of Circle(c1) = ", c1.getPerimeter(10, 15))
// c1 属性值不变
c1.SetRadius1(100)
// c1 属性值正常修改
c1.SetRadius2(100)
}
指针方法:接收者类型为指针的成员方法(如:func (c *Circle) SetRadius(){})
值方法:接收者类型为非指针的成员方法(如:func (c Circle) SetRadius(){})
(传入的结构体变量是值类型(类型本身为指针类型除外),因此传入函数内部的是外部结构体实例的值拷贝,修改不会作用到外部结构体实例)
区别:
- 归属于
struct_variable_type的成员方法只是该类型下所有可用成员方法的子集
归属于*struct_variable_type的成员方法才是该类型下的完整可用方法集合 - 调用指针方法时,Go 底层会自动将
struct_variable_type转换为对应的指针类型*struct_variable_type,即(&struct_variable_type).method()
- 自定义数据类型的方法集合中仅会包含它的所有「值方法」
- 该类型对应的指针类型包含的方法集合才囊括了该类型的所有方法,包括所有「值方法」和「指针方法」
- 指针方法可以修改所属类型的属性值,而值方法则不能
组合实现继承与方法重写
封装:结构体
继承:组合(将一个类型嵌入另一个类型,构建新的类型结构)
推荐使用指针方式实现继承,组合指针类型性能更好
多态:方法重写
(组合的不同类型包含同名方法,若子类没有重写则无法直接调用【只能显式调用】)
type Animal struct {
Name string
}
type Pet struct {
Name string
}
func (a Animal) Call() string {
return "Animal的叫声..."
}
func (a Animal) GetName() string {
return a.Name
}
func (p Pet) GetName() string {
return p.Name
}
// 通过组合实现继承
type Dog struct {
// 设置别名
animal Animal
// 以指针方式继承某个类型的属性和方法(调用不变;性能更好)
*Pet
}
// ”继承“实现方法重写
func (d Dog) Call() string {
return "汪汪汪。。。"
}
func main() {
animal := models.Animal{Name: "中华田园犬"}
dog := models.Dog{Animal: animal}
// 调用重写的方法
fmt.Println(dog.Call())
// 调用”父类“方法
fmt.Println(dog.Animal.Call())
// 组合的多个结构体拥有同名方法且子类没有重写的话,只能够显式调用
//fmt.Println(dog.GetName())
fmt.Println(dog.Pet.GetName())
fmt.Println(dog.Animal.GetName())
}
属性&成员方法可见性
-
不是传统的面向对象编程语言的可见性,而是基于包的维度
-
包与文件系统的目录结构存在映射关系
-
归属同一个包的 Go 代码具备以下特性:
- 归属于同一个包的源文件包声明语句要一致,即同一级目录的源文件必须属于同一个包;
- 在同一个包下不同的源文件中不能重复声明同一个变量、函数和类(结构体);
-
main函数作为程序的入口函数,只能存在于main包中 -
Go 语言类属性和成员方法的可见性都是包一级的,而不是类一级的
(所有变量、函数、自定义类属性或成员方法,可见性都根据其首字母大小写来决定。大写则包外可访问)
接口
如果说 goroutine 和 channel 是支撑起 Go 语言并发模型的基石,那么接口就是 Go 语言整个类型系统的基石
- 侵入式&非侵入式
侵入式接口:实现类必须明确声明自己实现了某个接口(如:Java)
非侵入式接口:类与接口的实现关系不通过显式声明,而是系统根据两者的方法集合进行判断 - Go 从设计上避免了侵入式接口
- 一个类只要实现了某个接口要求的所有方法,我们就说这个类实现了该接口(不用显式声明)
(如果一个接口的方法集合是某个类成员方法集合的子集,我们就认为该类实现了这个接口) - 通过关键字
interface来声明接口 - 通过组合实现接口继承
- 组合的情况下,只有实现了全部接口定义才会判定为完整实现(否则为单接口实现或不实现)
(接口的实现不是强制的,是根据类实现的方法来动态判定的) interface{}是一个空接口,可以用于表示任意类型
(范围太宽泛了,需要在运行时通过反射对数据进行类型检查)
// 接口定义
type IFile interface {
Read(buf []byte) (n int, err error)
}
// 接口实现
type File struct {
}
func (f *File) Read(buf []byte) (n int, err error) {
return 0, nil
}
// 继承 & 完整实现
type A interface {
Foo()
}
type B interface {
A
Bar()
}
type T struct {}
//func (t T) Foo() {}
// 只有同时实现组合类中的所有方法(包含依赖类)才会被判定为实现
func (t T) Bar() {}
- 如果实现类中的成员方法都是值方法,进行接口赋值时,传递类实例的值类型或指针类型均可,否则只能传递指针类型实例
从代码性能角度来说,值拷贝需要消耗更多的内存空间,统一使用指针类型代码性能会更好
type Integer int
type Math interface {
Add(i Integer) Integer
}
// 这种情况属于是 Integer 实现了接口,可以通过 Integer 或 &Integer 调用
type (i Integer) Add(b Integer) Integer {
return
}
// 这种情况属于是 *Integer 实现了接口,只能通过 &Integer 调用
type (i *Integer) Add(b Integer) Integer {
return
}
func main() {
var a Integer = 1
// 将类实例赋值给接口
// 值类型实现方法,可以通过值或指针类型调用
var m1 Math = a
// 指针类型实现方法,只能通过指针类型调用
var m1 Math = &a
}
- 在 Go 语言中,只要两个接口拥有相同的方法列表(与顺序无关),那么它们就是等同的,可以相互赋值
(前提:接口变量持有的是基于对应实现类的实例值,即接口与接口间的赋值基于类实例与接口间的赋值)
类型断言
实现方式:
.(type):type对应的就是要断言的类型,一般用于基本数据类型- 反射:
reflect包提供的TypeOf函数,一般用于结构体
类型断言是否成功需要在运行期才能够确定
断言语法.左边的变量必需是接口类型(建议使用空接口转换,避免引入多余的接口定义)
Go中的父类与子类(不确定官方是否也这么称呼)与面向对象编程语言(如
Java)中的概念完全不同,决不能够映射过去理解Go语言结构体类型的断言,即使子类和父类属性名和成员方法列表完全一致,子类的实例并不归属于父类;
同理,父类实现了某个接口,并不代表组合类的子类也实现了这个接口Go 使用
组合而非继承来构建类与类之间的层级关系,所以子类实例并不是同时父类类型
type Integer int
type Number interface {}
// 接口断言
var i Integer = 1
var n Number = &i
// n 必须是接口才能进行类型断言
if _, ok := n.(Number); ok {
// 只能在运行期间确定结果
}
// 子类的实例并不是父类实例
type IAnimal interface {}
type Animal struct {}
type Dog struct {
animal *Animal
name string
// 同时 Dog 实现接口 IAnimal
}
// var dog IAnimal = dog
// 引入空接口,避免引入冗余接口
var dog interface{} = dog
// ok=true,类型断言:满足接口及自身类型
_, ok := dog.(IAnimal|Dog)
// ok=false,类型断言:”子类型“并不是”父类型“ ==》 组合
_, ok := dog.(Animal)
// 使用反射获取实际类型
func myPringf(args ...interface{}) {
for _, arg := range args {
switch reflect.TypeOf(arg).Kind() {
case reflect.Int:
// codes
case reflect.Int:
// codes
}
}
}
// 通过 reflect.TypeOf(arg) 可获取真实类型
空接口、反射、泛型
Go 打破了传统面向对象编程中类与类之间继承的概念,通过组合实现方法和属性的复用,也不存在类似的继承关系树,也没有所谓的祖宗类(如:java.lang.Object);接口与实现也没有关键字进行约
空接口
- 类与接口的实现关系是通过类所实现的方法在编译期推断出来的
- 所有类都实现了空接口,反过来,空接口也可以指向任意类型
- 最典型的应用场景是声明函数支持任意类型的参数
// 空接口可以指向任意类型
var v1 interface{} = "这里可以是任意类型"
func method(args ...interface{}) {}
反射
常用的,分别可以通过 reflect.TypeOf 和 reflect.ValueOf 函数获取变量的类型与存储任何类型的值
反射的解析在运行时完成,对性能有一定影响;如非必须,尽量不要使用反射
// 通过反射获取成员变量、方法及执行方法
// 获取类型值:如果包含指针方法则使用如下方法获取类型值
//dogValue := reflect.ValueOf(&dog).Elem()
dogValue := reflect.ValueOf(dog)
// 获取所有属性和成员方法
for i := 0; i < dogValue.NumField(); i++ {
fmt.Println("name:", dogValue.Type().Field(i).Name)
fmt.Println("type:", dogValue.Type().Field(i).Type)
fmt.Println("value:", dogValue.Field(i))
}
// 获取所有方法并执行
for i := 0; i < dogValue.NumMethod(); i++ {
fmt.Println("name:", dogValue.Type().Method(i).Name)
fmt.Println("type:", dogValue.Type().Method(i).Type)
fmt.Println("exec result:", dogValue.Method(i).Call([]reflect.Value{}))
}
泛型(空接口&反射)
当前版本go version go1.17.2官方还未支持泛型
fixme TODO
空结构体
struct {}
该类型实例值只有一个,即struct{}{},且 Go 程序中永远只会存一份,且占据的内存空间是0
典型应用:通道(channel)作为传递简单信号的介质时使用空结构体进行声明
错误处理
error 类型
- 标准模式,
error接口 - 自定义错误:组合
error接口并实现Error()方法
// 「卫述语句」 模板
n, err := Foo(0)
if err != nil {
// 错误处理
} else {
// 使用返回值 n
}
// 构建错误实例
err := errors.New('错误信息')
// fmt.Errorf() 格式化错误信息
// 自定义错误
type PathError struct {
Op string
Path string
Err error
}
func (pe PathError) Error() string {
return pe.Op + pe.Path + pe.Err.Error()
}
panic & recover & defer
类比:
panic recover defer组合起来实现了面向对象编程中的try...catch...finally功能
一个完整的示例:
func divide() {
// 通过 defer 提前定义兜底逻辑(先入后出;不论是否发生 panic 都会执行)
defer func() {
// 通过 recover 捕获 panic(当前函数退出执行,回到调用的地方继续)
if err := recover(); err != nil {
fmt.Printf("Runtime panic caught: %v\n", err)
}
// 不使用 recover 恢复的话,整个程序会直接停止
fmt.Println("程序异常")
}()
var i = 1
var j = 0
// 抛出 panic 的函数(手动或默认)
if j == 0 {
panic("参数异常")
}
var k = i / j
fmt.Printf("%d / %d = %d\n", i, j, k)
}
func main() {
// 执行可能发生 panic 的业务
divide()
// 恢复以后继续执行
fmt.Println("继续执行main函数")
}
panic
相当于是Go语言版的异常(类比Java中的try)
当代码运行异常且又没有在编码时显式返回错误时,Go 会抛出panic,或「运行时恐慌」
panic函数支持的入参是interface{}
遇到
panic的执行逻辑:
- 中断当前协程后续代码执行
- 执行终端代码之前定义的
defer语句(按先入后出顺序)- 程序退出并输出
panic错误信息
func main() {
i := 1
j := 0
if j == 0 {
// 手动抛出 panic
panic("除数不能是0")
}
}
recover
通过recover()函数对panic进行捕获和处理(类比Java中的catch)
在defer中捕获panic运行时恐慌,defer执行完成后,退出抛出panic的当前函数再回到调用它的地方继续执行后续代码
defer
-
用于释放资源或程序运行过程中抛异常执行的兜底逻辑(似
Java中的finally;不论是否异常都会执行) -
可以是简单的一行语句或使用匿名函数
-
一个函数/方法中可以存在多个
defer语句,defer语句的调用顺序遵循先进后出的原则
(最后一个defer语句将最先被执行;即使在循环中,依然遵循先进后出) -
尽量在函数/方法的前面定义
defer,避免遗漏 -
抛出异常后,Go 会中断后续代码的执行,因此定义在异常代码以后的
defer不会执行
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
// 在函数执行完成或执行抛异常时执行
defer f.Close()
defer func () {
// 一条语句无法执行的动作可使用匿名函数实现
}
}
变量
-
init函数在main函数之前执行func init() { fmt.Println("This is init function") } func main() { fmt.Println("This is main function") } // 输出内容 // This is init function // This is main function -
不同类型的值不能使用
==或!=运算符比较 -
标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,那使用这种标识符的对象就可以被外部包的代码所使用(客户端需导入),这被称为导出
(类似于面向对象中的public); -
标识符如果以小写字母开头,则对包外不可见,但在整个包的内部是不可见且可用的
(类似于面向对象中的private) -
一行代表一个语句结束(不需要以分号
;结束,由编译器自动完成)
如果打算将多个语句写在同一行,则必须使用;进行区分(不建议使用) -
变量
-
全局变量与局部变量可以同名,参考全局变量
-
类型推导动作在编译期完成 ==> Go是静态语言
// 变量声明 var identifier type // 1、指定变量类型(不赋值则使用类型默认值) var v_name v_type var v_name v_type = value // 2、类型推导 var v_name = value // 3、省略 var,使用 := 进行声明;只能用于声明局部变量 v_name := value // 下面使用 := 的定义是正确的 var outer = true func main() { // a、打印方法外定义的变量定义 fmt.Println(outer) // b、如果是全局变量,可以进行重新定义(包括类型可以不一样)(fixme 应该不是同一个变量了) outer := "使用 := 重新定义变量" fmt.Println(outer) // c、如下定义不能编译通过 // var inner [string] = "局部变量" // fmt.Println(inner) // inner := "使用 := 重新定义局部变量无法编译通过" // fmt.Println(inner) } // 局部变量:同类型多个变量 // 1、指定类型(三个变量类型一致;可以是全局变量) var vname1,vname2,vname3 type vname1,vname2,vname3 = v1, v2, v3 // 2、类型推导(可以是不同的类型;可以是全局变量;并行|同时赋值) var vname1,vname2,vname3 = v1, v2, v3 // 3、初始化声明(可以是不同的类型;变量必须不能是已经在方法内部声明过的;并行|同时赋值) vname1,vname2,vname3 := v1, v2, v3 // 全局变量:类型不同的多个变量声明(只能是全局变量) var ( v_name_1 type1 v_name_2 type2 ) -
-
值类型与引用类型
- 值类型
- 所有像
int、float、bool和string这些基本类型都属于值类型,使用这些类型的变量直接指向存在内存中的值 - 当使用等号
=将一个变量的值赋值给另一个变量时,如:j = i,实际上是在内存中将 i 的值进行了拷贝 - 可以通过
&i来获取变量 i 的内存地址(取址符) - 值类型的变量的值存储在栈中
- 所有像
- 引用类型
- 更复杂的数据通常会需要使用多个值,这些数据一般使用引用类型保存
- 一个引用类型的变量 r1 存储的是 r1 的值所在的内存地址(数字),或内存地址中第一个值所在的位置(这个内存地址也称指针)
- 同一个引用类型的指针指向的多个值在内存中可以是连续的,也可以是分散的
- 值类型
-
局部变量禁止只声明不使用;全局变量允许只声明不使用
var outer string = "全局变量允许只声明不使用" func main() { // Unused variable 'inner' var inner = "局部变量禁止只声明不使用" } -
如果想要简单的交换两个变量的值,可以使用
a, b=b, a -
空白标识符
_也被用于抛弃值,如值 5 在_, b := 5, 7中被抛弃
_实际上只是一个可写变量,不能获取其值
(Go 语言中你必须使用所有被声明的变量,但有时你并不需要使用从一个函数得到的所有返回值) -
并行赋值也被用于当一个函数返回多个返回值
val, err = Func1(var1)
常量
-
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型
-
不能出现任何需要运行期才能获取结果的表达式(无需担心常量之间的类型转换,它们都是非常理想的数字)
-
定义格式
// 类型说明符可省略 const identifier [type] = value // 支持同时定义多个同类型变量 const c_name_1, c_name_2 = value1, value2 // 可以定义同名的局部和全局常量 const a1, a2, a3 = "a1", 23, true func method() { // 这么定义不会报错 const a1, a2 = "aa1", "aa2" // 优先输出局部变量定义,没有则输出全局变量值 fmt.Println(a1, a2, a3) } -
常量还可以用作枚举
const ( Unknown = 0 Female = 1 Male = 2 ) -
常量定义中可以使用
len()、cap()、unsafe.Sizeof()计算表达式的值(必需是内置函数)const ( a = "abc" b = len(a) c = unsafe.Sizeof(a) ) -
iota,特殊常量,可以认为是一个可以被编译器修改的常量
在每一个const关键字出现时,被重置为0,然后再下一个const出现之前,每出现一次iota,其所代表的数字就会自动增加1// 定义一 const ( a = iota b = iota c = iota ) // 接上定义二 // const出现,值被重置 const ( d = iota e = iota f = iota ) // a=0,b=1,c=2 // d=0,e=1,f=2 // 简写为 const ( a = iota b c ) -
复杂一些的用法
// 示例一 const ( a = iota // a=0 b // b=1 c // c=2 d = "ha" // d="ha",iota+=1=3 e // e="ha",iota+=1=4 f = 100 // f=100,,iota+=1=5 g // g=100,,iota+=1=6 h = iota // 恢复计数 h=7 i // i=8 ) // 示例二 const ( i = 1 << iota // i=1<<0=1 j = 3 << iota // j=3<<1=6 k // k=3<<2=12 l // l=3<<3=24 )
运算符
-
算术运算符
含
+、-、*、/、%、++、--%(取余运算只能用于整数)不同类型的整型值不能直接进行算术运算,必需先转化相同类型再执行计算
自增/自减运算符,只能作为语句,不能作为表达式,且只能用作后缀,不能放到变量前面
func method() { a := 10 b := 20 var c int c = a + b c = a - b c = a * b c = a / b c = a % b // 等效于:a=a+1 a++ // 等效于:a=a-1 a-- // 没有 ++a 或 --a 的操作 } -
关系运算符
含
==、!=、>、<、>=、<=各种类型的整型变量都可以直接与字面常量进行比较
var intVal1 int8 = 1 // 字面常量为 int if intVal1 == 8 { fmt.Println("intValue1 = 8") }else { fmt.Println("intValue1 != 8") } -
逻辑运算符
含
&&、||、!- 没有单与、单或
- go的风格是不必将逻辑运算符计算使用括号包裹
func method() { a := true b := true // go 的风格是不必将逻辑运算使用括号包裹 if a || b { fmt.Println("a||b is true") } // 逻辑运算符中没有单与、单或 // if a | b{} } -
位运算符
可以对整数在内存中的二进制位进行操作
含
&、|、^运算符 说明 &与运算,全真为真 ` ` ^异或运算,相同为假,不同为真 <<左移运算符,左移n位就是乘以2的n次方(高位丢弃,低位补0) >>右移运算符,右移n位就是除以2的n次方 -
赋值运算符
运算符 说明 实例 =将一个表达式的值赋给一个左值 C = A + B +=相加后再赋值 C += A 等于 C = C + A -=相减后再赋值 C -= A 等于 C = C - A *=相乘后再赋值 C *= A 等于 C = C * A /=相除后再赋值 C /= A 等于 C = C / A %=求余后再赋值 C %= A 等于 C = C % A <<=左移后赋值 C <<= 2 等于 C = C << 2 >>=右移后赋值 C >>= 2 等于 C = C >> 2 &=按位与后赋值 C &= 2 等于 C = C & 2 ^=按位异或后赋值 C ^= 2 等于 C = C ^ 2 ` =` 按位或后赋值 -
其他运算符
运算符 说明 实例 &变量内存地址 &var_name返回变量的实际地址*(fixme)指针变量 *var_name是一个指针变量 -
运算符优先级(由高到低)
优先级 运算符 7 ^ ! 6 * / % <> & &^ 5 + - | ^ 4 == != < = > 3 <- 2 && 1 ||
函数
- 最少有一个 main 函数
- 函数名称,参数列表和返回值(类型,个数,顺序)一起构成了函数签名
- 标准库提供了多种可动用的内置的函数(存在于
builtin和unsafe标准库)
Go 语言内置函数可以参考 built 包文档 - 函数本身也是 Go 的一种数据类型
分为三种:
- 普通函数
- 匿名函数(闭包)
- 类方法
定义:
// 1、可以返回多个值
// 2、如果没有返回值,return_types 可缺省
// 3、入参类型相同可使用简单定义
func function_name( [parameter list] ) [return_types] {
// function body
}
func function_name( [parameter list] ) (type1,type2,...,typeN) {
// function body
}
func max(a, b int) int {
// 方法体省略
return ret
}
func swap(x, y string) (string, string) {
return y, x
}
类方法:相当于Java中的一个类拥有的自定义方法
函数参数
按值传参
Go 语言默认使用按值传参来传递参数,也就是传递参数值的一个副本,在调用过程中不会影响到实际参数
引用传参
可以实现在函数中修改形参值的同时修改实参值
默认使用引用传参的类型:切片(slice)、字典(map)、接口(interface)、通道(channel)等
传递给函数的参数是一个指针,而指针代表的是实参的内存地址,修改指针引用的值即修改变量内存地址中存储的值,所以实参的值也会被修改
(这种情况下,传递的是变量地址值的拷贝,所以从本质上来说还是按值传参)
引用传递的一个例子:
// 引用传递入参及方法体有所不同
func swap(x *int, y *int) {
var tmp int
tmp = *x
*x = *y
*y = tmp
}
变长参数
在参数类型前加上 ... 前缀(只能作为形参存在,且必须是最后一个)
//定义:numbers 为变长参数
func myfunc(vars ...data_type) {
for _, val := range vars {
fmt.Println(val)
}
}
// 调用:加后缀表明变长参数
slice := []data_type{v1,v2,v3}
myfunc(slice...)
任意类型的变长参数(泛型)
指定变长参数类型为 interface{}
Go 语言并没有在语法层面提供对泛型的支持(当前go version = go1.17.2 windows/amd64)
interface{}是一个空接口,可以用于表示任意类型
(范围太宽泛了,需要在运行时通过反射对数据进行类型检查)
(多)返回值
- 多返回值
- 命名返回值
// 多返回值之间通过英文逗号分隔;使用括号包裹
func method(var1 type,var2 type) (return_type1,return_type2) {
// work code
}
// 命名返回值
func method(var1 type,var2 type) (ret type, err error) {
// 在函数中直接对返回变量进行赋值
// work code
// return 后面不用再写返回变量
}
func add(a, b *int) (c int, err error) {
if *a < 0 || *b < 0 {
err = errors.New("Error message")
return
}
c = *a + *b
return
}
匿名函数与闭包
// 1、将匿名函数赋值给变量
add := func(a, b int) int {
return a + b
}
// 调用匿名函数 add
fmt.Println(add(1, 2))
// 2、定义时直接调用匿名函数
func(a, b int) {
fmt.Println(a + b)
} (1, 2)
闭包:引用了自由变量(未绑定到特定对象的变量,通常在函数外定义)的函数,被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的上下文环境也不会被释放(比如传递到其他函数或对象中)
「闭」的意思是「封闭外部状态」,即使外部状态已经失效,闭包内部依然保留了一份从外部引用的变量
闭包只能通过匿名函数实现,我们可以把闭包看作是有状态的匿名函数;
反过来,如果匿名函数引用了外部变量,就形成了一个闭包(Closure)
- 匿名函数作为形参
// 匿名函数作为参数传递
add := func(a, b int) int {
return a + b
}
// 立即调用;关键字:call;函数对应的定义是:func(int, int) int
func(func_name func(int, int) int) {
fmt.Println(func_name(1, 2))
}(add)
// 匿名函数作为参数传递:抽离匿名函数
func main(){
add := func(a, b int) int {
return a + b
}
handleAdd(1, 2, add)
}
// 函数对应的定义是:func(int, int) int
func handleAdd(a, b int, func_name func(int, int) int) {
fmt.Println(func_name(a, b))
}
- 匿名函数作为返回值
可以通过将函数返回值声明为函数类型来实现业务逻辑的延迟执行
func main() {
// 获取返回的匿名函数
addFunc := deferAdd(1, 2)
// 执行真正的函数动作
fmt.Println(addFunc())
}
// 匿名函数对应的定义是:func() int
func deferAdd(a, b int) func() int {
return func() int {
return a + b
}
}
- 高阶函数:接收其他函数作为形参,或者把其他函数作为结果返回的函数
Map-Reduce-Filter 模式
准确的说是一种处理思想(不与固定场景绑定)
多用于处理集合
Map-Reduce-Filter 并不是一个整体,而是要分三步实现:Filter、Map 和 Reduce(以字典类型切片为例)
- 首先将字典类型切片按照条件过滤,即
Filter- 再将过滤后的字典类型切片转化为一个字符串类型切片(
Map,字面意思就是映射)- 最后再将转化后的切片元素转化为目标类型执行计算
(Reduce,字面意思就是将多个集合元素通过迭代处理减少为一个)
示例:
// 计算一个 []map[string]string 中 age 字段的累加
// 1、过滤
func itemsFilter(items []map[string]string, f func(map[string]string) bool) []map[string]string {
newSlice := make([]map[string]string, len(items))
for _, item := range items {
if f(item) {
newSlice = append(newSlice, item)
}
}
return newSlice
}
// 2、映射
func mapToString(items []map[string]string, f func(map[string]string) string) []string {
newSlice := make([]string, len(items))
for _, item := range items {
newSlice = append(newSlice, f(item))
}
return newSlice
}
// 3、计算
func fieldSum(items []string, f func(string) int) int {
var sum int
for _, item := range items {
sum += f(item)
}
return sum
}
管道 & 流式编程
func SumAge(users []User, pipes ...func([]User) interface{}) int {
var ages []int
var sum int
// 传入函数切片
for _, f := range pipes {
result := f(users)
// fixme result.(type)
switch result.(type) {
case []User:
// 判断结果类型并更新形参
users = result.([]User)
case []int:
ages = result.([]int)
}
}
if len(ages) == 0 {
log.Fatalln("没有在管道中加入 mapAgeToSlice 方法")
}
for _, age := range ages {
sum += age
}
return sum
}
变量用域
变量可以在三个地方声明:
- 函数内定义的变量称为局部变量
- 函数外定义的变量称为全局变量
- 函数定义中的变量称为形式参数
局部变量
- 在函数体内声明
- 作用域只在函数体内
- 参数和返回值变量也是局部变量
全局变量
- 在函数体外声明
- 可以在整个包甚至外部包(被导出后)使用
全局变量与局部变量名称可以相同,但是函数内的局部变量会被优先考虑
形式参数(形参)
出现在函数/方法形参表中的变量(当作局部变量使用)
初始化局部和全局变量
| 数据类型 | 初始化默认值 |
|---|---|
| int | 0 |
| float32 | 0 |
pointer(fixme) |
nil |
语言范围
range关键字用于for循环中迭代数组array、切片slice、链表channel或集合map等元素
个人理解:使用for循环遍历数组、切片、链表或集合用到的一个关键字
| Range表达式 | 第一个值 | 第二个值[可选的] |
|---|---|---|
| Array 或者 slice a [n]E | 索引 i int | a[i] E |
| String s string type | 索引 i int | rune int |
| map m map[K]V | 键 k K | 值 m[k] V |
| channel c chan E | 元素 e E | none |
// 迭代string时,index为索引,value为字符(Unicode值)
for index|key, value := array|slice|channel|map|string {
// 业务代码
}
类型转换
- 将一种数据类型的变量转换为另外一种类型的变量
- 不支持隐式类型转换
// type_name 为类型,expression 为表达式
type_name(expression)
i := 32
float32(i)
//var a int32 = 3
//var b int64
//b = a
//fmt.Printf("b 为 : %d", b)
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号