

HTTP
概念
-
用于从WWW服务器传输超文本到本地浏览器的传送协议
-
应用层协议,由请求和响应构成
-
标准的客户端服务器(C/S)模型
-
无状态
-
在Internet中所有的传输都是通过
TCP/IP进行的(HTTP协议通常承载于TCP协议之上,有时也承载于TLS/SSL协议层之上,即HTTPS)![]()
-
HTTP默认的端口号为80,HTTPS的端口号为443

特点
- HTTP协议永远都是客户端发起请求,服务器回送响应
- 支持客户端/服务器模式。支持基本认证和安全认证
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记
- HTTP 0.9和1.0使用非持续连接:限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后,即断开连接
HTTP 1.1使用持续连接:不必为每个web对象创建一个新的连接,一个连接可以传送多个对象,采用这种方式可以节省传输时间- 无状态:HTTP协议是无状态协议(导致每次连接传送的数据量增大)
无状态协议
- 协议的状态是指下一次传输可以“记住”这次传输信息的能力
- HTTP是不会为了下一次连接而维护这次连接所传输的信息
- 设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息
- 由于Web服务器不保存发送请求的Web浏览器进程的任何信息,因此HTTP协议属于无状态协议(Stateless Protocol)
无状态与Connection:keep-alive区别
- HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)
- 从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性
- Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间
工作流程
- 一次HTTP操作称为一个事务,其工作过程可分为四步:
- 首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始
- 建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容
- 服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容
- 客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接(HTTP/1.0)
- HTTP是基于传输层的TCP协议,而TCP是一个端到端的面向连接的协议。所谓的端到端可以理解为进程到进程之间的通信
头域
请求信息

- 三部分分别为:请求行、请求头(可多行)、空行、请求体
- 请求体前的空行为必需
请求方法
-
OPTIONS - 返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送
*的请求来测试服务器的功能性 -
HEAD - 向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新
-
GET - 向特定的资源发出请求
-
POST - 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改
-
PUT - 向指定资源位置上传其最新内容
-
DELETE - 请求服务器删除Request-URI所标识的资源
-
TRACE - 回显服务器收到的请求,主要用于测试或诊断
-
CONNECT - HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器
-
PATCH - 用来将局部修改应用于某一资源,添加于规范RFC5789
-
方法名称区分大小写
-
HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的
响应信息
-
结构
![]()
![]()
-
三部分分别为:状态行、响应头(可多行)、空行、响应信息(非必需)
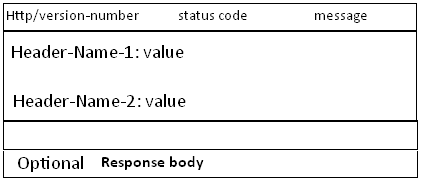

HTTP常见请求头 & HTTP常见响应头
解决HTTP无状态的问题
-
通过Cookies保存状态信息
![]()
-
通过Session保存状态信息
-
一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息
当程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否已包含了一个session标识 - 称为 session id,如果已包含一个session id则说明以前已经为此客户端创建过session,服务器就按照session id把这个 session检索出来使用(如果检索不到,可能会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应中返回给客户端保存
-
实现方式:
-
使用Cookie实现
服务器给每个
Session分配一个唯一的JSESSIONID,并通过Cookie发送给客户端。
当客户端发起新的请求的时候,将在Cookie头中携带这个JSESSIONID。这样服务器能够找到这个客户端对应的Session![]()
-
使用URL回写实现
- 服务器在发送给浏览器页面的所有链接中都携带
JSESSIONID的参数,这样客户端点击任何一个链接都会把JSESSIONID带会服务器 - Tomcat对Session的实现,是一开始同时使用Cookie和URL回写机制(优先使用Cookie,如果被禁用就是用URL回写)
- 服务器在发送给浏览器页面的所有链接中都携带
-
-
-
TOKEN


缓存实现原理
- WEB缓存(cache)位于Web服务器和客户端之间
- 缓存会根据请求保存输出内容的副本(当下一个请求来到的时候:如果是相同的URL,缓存直接使用副本响应访问请求,而不是向源服务器再次发送请求)
客户端缓存生效的常见流程
- 服务器收到请求时,返回的 200 OK 中回送该资源的
Last-Modified和ETag(Entity Tags)头,客户端将该资源保存在cache中,并记录这两个属性。- 客户端需要发送相同的请求时,会在请求中携带
If-Modified-Since和If-None-Match两个头。这两个头的值分别是响应中的Last-Modified和ETag值。- 服务器通过这两个头判断本地资源未发生变化,客户端不需要重新下载,返回
304响应

Web 缓存机制
HTTP/1.1中缓存的目的是为了在很多情况下减少发送请求,同时在许多情况下可以不需要发送完整响应。
- 前者减少了网络回路的数量;HTTP利用一个“过期(expiration)”机制来为此目的
- 后者减少了网络应用的带宽;HTTP用“验证(validation)”机制来为此目的
HTTP 定义了三种缓存机制:
Freshness:允许一个回应消息可以在源服务器不被重新检查,并且可以由服务器和客户端来控制
(Expires回应头给了一个文档不可用的时间。Cache-Control中的max-age标识指明了缓存的最长时间)Validation:用来检查一个缓存的回应是否仍然可用
(如果一个回应有一个Last-Modified回应头,缓存能够使用If-Modified-Since来判断是否已改变,以便判断根据情况发送请求)Invalidation:在另一个请求通过缓存的时候,常常有一个副作用
(如果一个URL关联到一个缓存回应,但是其后跟着POST、PUT和DELETE的请求的话,缓存就会过期)
HTTP应用
断点续传
- 将上传/下载的任务人为划分为几个部分
- 通过
Header里的两个参数实现,Range(客户端发送请求)和Content-Range(服务器回复响应)
# 请求头:指定第一个字节的位置和最后一个字节的位置
Range:(unit=first byte pos)-[last byte pos]
# 响应头:当前接受的范围和文件总大小
Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity legth]
# 示例
Range: bytes=0-499 表示第 0-499 字节范围的内容
Range: bytes=500-999 表示第 500-999 字节范围的内容
Range: bytes=-500 表示最后 500 字节的内容
Range: bytes=500- 表示从第 500 字节开始到文件结束部分的内容
Range: bytes=0-0,-1 表示第一个和最后一个字节
Range: bytes=500-600,601-999 同时指定几个范围
Content-Range: bytes 0-499/22400
# 响应完成后
# 不使用断点续传方式
HTTP/1.1 200 OK
# 使用断点续传方式
HTTP/1.1 206 Partial Content
-
增强校验
场景:URL对应的文件内容在服务器端发生变化
-
Last-Modified
-
Etag
-
If-Range:判断实体是否发生改变,如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体
# 格式 If-Range: Etag | Last-Modified # If-Range 可以使用 Etag 或者 Last-Modified 返回的值。当没有 ETage 却有 Last-modified 时,可以把 Last-modified 作为 If-Range 字段的值 If-Range: “627-4d648041f6b80” If-Range: Fri, 22 Feb 2013 03:45:02 GMTIf-Range 必须与 Range 配套使用
- 如果请求报文中没有 Range,那么 If-Range 就会被忽略
- 如果服务器不支持 If-Range,那么 Range 也会被忽略
- 如果请求报文中的 Etag 与服务器目标内容的 Etag 相等,即没有发生变化,那么应答报文的状态码为 206
- 如果服务器目标内容发生了变化,那么应答报文的状态码为 200
-
用于校验的其他HTTP头信息:If-Match/If-None-Match、If-Modified-Since/If-Unmodified-Since
-
-
工作原理
Etag 由服务器端生成,客户端通过 If-Range 条件判断请求来验证资源是否修改。请求一个文件的流程如下:
- 第一次请求:
- 客户端发起 HTTP GET 请求一个文件
- 服务器处理请求,返回文件内容以及相应的 Header,其中包括 Etag(例如:627-4d648041f6b80)(假设服务器支持 Etag 生成并已开启了 Etag)状态码为 200
- 第二次请求(断点续传):
- 客户端发起 HTTP GET 请求一个文件,同时发送 If-Range(该头的内容就是第一次请求时服务器返回的 Etag:627-4d648041f6b80)
- 服务器判断接收到的 Etag 和计算出来的 Etag 是否匹配,如果匹配,那么响应的状态码为 206;否则,状态码为 200
- 第一次请求:
-
检测服务器是否支持断点续传
- 使用
CURL检测 - 能够找到
Content-Range,说明服务器支持断点续传 - 有些服务器还会返回
Accept-Ranges,输出结果Accept-Ranges: bytes,说明服务器支持按字节下载
- 使用
多线程下载的原理
- 下载工具开启多个发出HTTP请求的线程;
- 每个
http请求只请求资源文件的一部分:Content-Range: bytes 20000-40000/47000 - 合并每个线程下载的文件
http代理
虚拟主机
- 把一台运行在互联网上的服务器划分成多个“虚拟”的服务器,每一个虚拟主机都具有独立的域名和完整的Internet服务器(支持WWW、FTP、E-mail等)功能。
- 一台服务器上的不同虚拟主机是各自独立的,并由用户自行管理。
- 一台服务器主机只能够支持一定数量的虚拟主机,当超过这个数量时,用户将会感到性能急剧下降
虚拟主机是用同一个WEB服务器,为不同域名网站提供服务的技术。Apache、Tomcat等均可通过配置实现这个功能
HTTP认证方式
HTTP请求报头: Authorization
HTTP响应报头: WWW-Authenticate
HTTP认证是基于质询/回应(challenge/response)的认证模式
基本认证
basic authentication(HTTP1.0提出的认证方法)
- 基于
用户名和口令的登录验证 - 将
username:passwd用BASE64加密后放在请求头Authorization中 密码明文传输
认证步骤:
- 客户端访问一个受
http基本认证保护的资源 - 服务器返回
401,要求客户端提供用户名和密码进行认证
(认证失败,响应头会加上WWW-Authenticate: Basic realm="请求域") - 客户端将输入的用户名密码用
Base64进行编码后,采用非加密的明文方式传送给服务器
Authorization: Basic Base64(username:passwd) - 服务器解析
Authorization并认证;如果成功,返回相应的资源。失败,返回401,要求重新进行认证
摘要认证
digest authentication(HTTP1.1提出的基本认证的替代方法)

- 可以看做是基本认证的增强版本,不包含密码的明文传递
- 使用
MD5加密是为了达成"不可逆"(如果密码太过简单,可通过字典或查表暴力破解)
步骤:
- 客户端请求一个需要认证的页面,但是不提供用户名和密码
- 服务器返回
401响应,并提供认证域(realm),及一个随机生成的、只使用一次的密码随机数nonce - 提示输入用户名&密码
- 添加认证头,重新发起请求
HTTPS传输协议原理
全称Hypertext Transfer Protocol over Secure Socket Layer,是HTTP的安全版。
HTTP下加入SSL层,HTTPS的安全基础是SSL
两种基本的加解密算法类型
- 对称加密:密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES等
- 非对称加密:密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有
RSA、DSA等
HTTPS通信过程
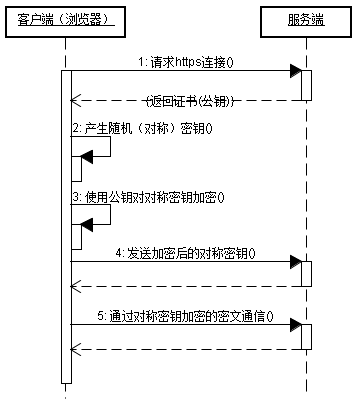
HTTPS通信的优点
- 客户端产生的密钥只有客户端和服务器端能得到;
- 加密的数据只有客户端和服务器端才能得到明文;
- 客户端到服务端的通信是安全的
版本演进
HTTP/0.9
# 请求
GET /index.html
# 响应
<html>
<body>Hello World</body>
</html>
- 只有一个命令
GET - 协议规定,服务器只能回应HTML格式的字符串,不能回应别的格式
- 服务器响应回复数据完毕,就关闭TCP连接
HTTP/1.0
# 请求
# 第一行是请求命令,必须在尾部添加协议版本(HTTP/1.0)
# 后面就是多行头信息,描述客户端的情况
GET / HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*
# 响应
# 格式:"头信息 + 一个空行(\r\n) + 数据"。其中,第一行是"协议版本 + 状态码(status code) + 状态描述"
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html>
<body>Hello World</body>
</html>
-
任何格式的内容都可以发送
-
除了
GET命令,还引入了POST命令和HEAD命令 -
HTTP请求和回应每次都必须包括头信息(HTTP header),用来描述一些元数据
-
新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等
-
回应格式:"头信息 + 一个空行(
\r\n) + 数据"。第一行是"协议版本 + 状态码(status code) + 状态描述" -
Content-Type 字段
- 1.0版规定,头信息必须是 ASCII 码,后面的数据可以是任何格式。因此,服务器回应的时候,必须告诉客户端,数据是什么格式
- 总称为
MIME type,每个值包括一级类型和二级类型,之间用斜杠分隔 - 支持自定义类型
MIME type还可以在尾部使用分号,添加参数MIME type不仅用在HTTP协议,还可以用在其他地方,比如HTML网页
-
Content-Encoding 字段
- 服务器响应时说明数据的压缩方法
- 客户端在请求时,用
Accept-Encoding字段说明自己可以接受哪些压缩方法
-
客户端请求的时候,可以使用
Accept字段声明自己可以接受哪些数据格式 -
缺点
-
每个TCP连接只能发送一个请求(发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接)
-
TCP连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)
解决办法:
- 有些浏览器在请求时,用了一个非标准的
Connection字段
Connection: keep-alive- 要求服务器不要关闭TCP连接,以便其他请求复用。服务器同样回应这个字段(除非客户端或浏服务器主动关闭连接)
- 但是这不是标准字段,不同实现的行为可能不一致,因此不是根本的解决办法
- 有些浏览器在请求时,用了一个非标准的
-
HTTP/1.1
-
持久连接(persistent connection)
- 新增特性
- TCP连接默认不关闭,可以被多个请求复用,也不用声明
Connection: keep-alive - 客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接
- 规范的做法是,客户端在最后一个请求时,发送
Connection: close,明确要求服务器关闭TCP连接 - 目前,对于同一个域名,大多数浏览器允许同时建立6个持久连接
-
管道机制
- 新增特性
- 在同一个TCP连接里面,客户端可以同时发送多个请求(管道机制则是允许浏览器同时发出A请求和B请求,但是服务器还是按照顺序,先回应A请求,完成后再回应B请求)
-
Content-Length 字段
一个TCP连接现在可以传送多个回应,必需要区分数据包是属于哪一个回应的。
这就是
Content-length字段的作用,声明本次回应的数据长度# 告诉浏览器,本次回应的长度是3495个字节,后面的字节属于下一个回应 Content-Length: 34951.0版中,
Content-Length字段不是必需的(TCP连接关闭,标明数据包接收完成) -
分块传输编码
-
使用
Content-Length字段的前提条件是,服务器发送回应之前,必须知道回应的数据长度 -
产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)【对于耗时操作来说,服务器要等到所有操作完成才能发送数据,效率不高】
-
1.1版规定可以不使用
Content-Length字段,而使用"分块传输编码"(chunked transfer encoding) -
请求或回应的头信息有
Transfer-Encoding字段,就表明回应将由数量未定的数据块组成HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked 25 This is the data in the first chunk 1C and this is the second one 3 con 8 sequence 0 -
每个非空的数据块之前,会有一个16进制的数值,表示这个块的长度
-
最后是一个大小为0的块,就表示本次回应的数据发送完了
-
-
1.1版还新增了许多动词方法:
PUT、PATCH、HEAD、OPTIONS、DELETE -
客户端请求的头信息新增了
Host字段,用来指定服务器的域名(可以将请求发往同一台服务器上的不同网站) -
缺点
- 一个TCP连接里面,所有的数据通信是按次序进行的(服务器只有处理完一个回应,才会进行下一个回应;可能会造成"队头堵塞"(Head-of-line blocking))
- 解决方法:1. 减少请求数;2. 同时多开持久连接
- 如果HTTP协议设计得更好一些,这些额外的工作是可以避免的
HTTP/2
- 二进制协议
- 多工
- 数据流
- 头信息压缩
- 服务器推送
参考地址:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号