Kioskcached(1)之 Memcached & Redis & Kioskcached 性能测试对比
前言:本文仅仅是作者自己在学习过程中的一次实验而已,或许因为各种因素会导致实验结果与你之前的认知不太一样,因此请你带着批判的眼光看待本文(本文不具有实际环境的参考性)。
一:测试目的
在了解了一些NoSQL的知识之后,我发现Memcached是一个多线程的模型,对于一个NoSQL数据库,如果不考虑数据持久化功能(读写磁盘),剩余的内存操作应该是非常快的。但是多线程就意味着需要互斥和同步,锁是必须的,因此我设想多线程或许还会影响其性能而没有单线程快,这也是我为了验证自己的想法做的测试,因此也有了我标题中提到的我自己的项目 Kioskcached——一款单线程的简易key-value数据库。
二:测试环境
OS : RedHat 7
Kernel : Linux version 3.10.0-514.el7.x86_64
CPU : Intel(R) Core(TM) i5 CPU M 520 @ 2.40GHz
Mem : 8G//备注:除了测试三个数据库的QPS,我还使用Google的 gperftools 工具我的项目做了
CPU PROFILER,找出了代码中占用CPU最多的函数,并考虑优化它。
三:测试过程及结果
1.Memcached
1:启动Memcached,使用默认大小64M就够了,我们存取的数据量大概是10M左右,(100B(key+value)*100000(nums) = 10M)。

2:测试代码如下:
https://github.com/yangbodong22011/kioskcached/tree/master/test/Memcached
3: 编译运行
$ g++ testFoot.cpp -lmemcached -lprofiler
$ ./a.out 100000 //插入10万条数据
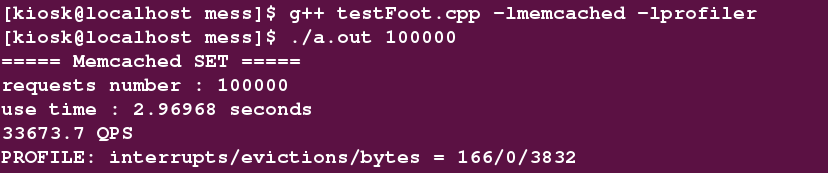
测试得到 QPS 为: 33673.7
2.Redis
1:源码安装Redis之后,./redis-server启动Redis服务器
2:在src目录下有 redis-benchmark 可执行文件,这是官方自带的Redis性能测试工具。
$ ./redis-benchmark -h 127.0.0.1 -c 1 -n 100000 -d 100
-c : client的数量,1表示只有一个客户端
-n : 100000 : 表示10万次请求
-d : 100 : 表示一次数据量为100字节
3:测试结果
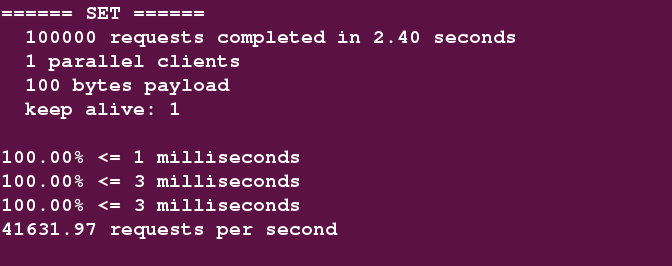
测试得到 QPS 为: 41631.97
3.Kioskcached
1:一款内存缓存型数据库,采用C/C++开发,网络库部分使用Redis源码,单线程IO多路复用模型避免了锁的争用,保证了操作的原子性。使用C++11 unordered_set管理内存数据结构。
2: Kioskcached的测试情况:
- 当value的值为100字节时 : QPS = 316275

使用gperftools找出使用CPU前几位的函数为:

$ cat output.txt
Total: 259 samples
34 13.1% 13.1% 56 21.6% std::_Hashtable::_M_find_before_node
21 8.1% 21.2% 22 8.5% _int_malloc
17 6.6% 27.8% 23 8.9% std::_Hashtable::_M_rehash_aux
...... 剩余的省略输出结果说明(按照列数往下):
| 序号 | 说明 |
|---|---|
| 1 | 分析样本数量(不包含其他函数调用) |
| 2 | 分析样本百分比(不包含其他函数调用) |
| 3 | 目前为止的分析样本百分比(不包含其他函数调用) |
| 4 | 分析样本数量(包含其他函数调用) |
| 5 | 分析样本百分比(包含其他函数调用) |
| 6 | 函数名 |
- 当value的值为1000字节时 : QPS = 203203
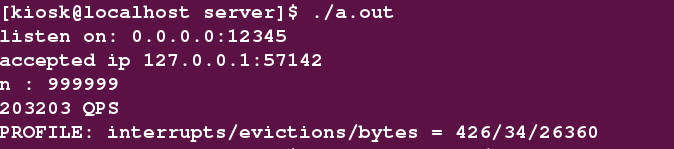
使用gperftools找出使用CPU前几位的函数为:
Total: 426 samples
78 18.3% 18.3% 78 18.3% __read_nocancel
64 15.0% 33.3% 70 16.4% _int_malloc
28 6.6% 39.9% 57 13.4% std::_Hashtable::_M_find_before_node
...... 剩余的省略
可以发现与100字节相比较,此时read系统调用占用CPU已经成为了第一。- 当value的值为10000字节时

使用gperftools找出使用CPU前几位的函数为:
Total: 521 samples
102 19.6% 19.6% 102 19.6% __read_nocancel
79 15.2% 34.7% 83 15.9% _int_malloc
42 8.1% 42.8% 42 8.1% __GI_epoll_wait
29 5.6% 48.4% 52 10.0% std::_Hashtable::_M_find_before_node
malloc 还是我们的难题和瓶颈。
...... 剩余的省略
3 : 总结
可以看出像:
_int_malloc
std::_Hashtable::_M_find_before_node
std::_Hashtable::_M_rehash_aux
__read_nocancel这些都消耗非常多的CPU,要是优化的话先从它们入手,我自己可以处理的是malloc 和 std::_Hashtable::_M_find_before_node。
四:改进方法
- 重新找寻Hash函数,做适配替代目前的Hash函数。
- 使用tcmalloc等第三方性能优于glibc ptmalloc的内存分配器。
[完]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号