Java中解析XML的方法
在Java中使用Sax解析xml
在Java中使用Dom解析xml
Dom解析功能强大,可增删改查,操作时会将xml文档对象的方式读取到内存中,因此适用于小文档
Sax解析是从头到尾逐行逐个元素读取内容,修改较为不便,但适用于只读的大文档
Sax采用事件驱动的方式解析文档,简单说,如同看电影一样,从头到尾看一遍就完了,不能回退(Dom可来来回回读取)
在看电影的过程中,每遇到一个情节,一段泪水,一次擦肩,你都会调动大脑和神经去接收或处理这些信息
同样,在Sax的解析过程中,读取到文档开头、结尾,元素的开头和结尾都会触发一些回调方法,你可以在这些回调方法中进行相应事件处理
这四个方法是:startDocument() 、 endDocument()、 startElement()、 endElement
此外,光读取到节点处是不够的,我们还需要characters()方法来仔细处理元素内包含的内容
将这些回调方法集合起来,便形成了一个类,这个类也就是我们需要的触发器
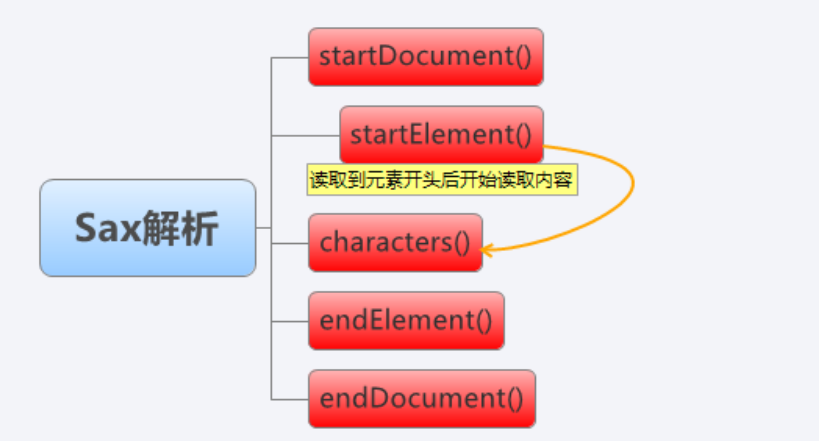
如上图,在触发器中,首先开始读取文档,然后开始逐个解析元素,每个元素中的内容会返回到characters()方法
接着结束元素读取,所有元素读取完后,结束文档解析。
现在我们开始创建触发器这个类,要创建这个类首先需要继承DefaultHandler
创建SaxHandler类
1 import org.xml.sax.Attributes; 2 import org.xml.sax.SAXException; 3 import org.xml.sax.helpers.DefaultHandler; 4 5 6 public class SaxHandler extends DefaultHandler { 7 8 /* 此方法有三个参数 9 arg0是传回来的字符数组,其包含元素内容 10 arg1和arg2分别是数组的开始位置和结束位置 */ 11 @Override 12 public void characters(char[] arg0, int arg1, int arg2) throws SAXException { 13 String content = new String(arg0, arg1, arg2); 14 System.out.println(content); 15 super.characters(arg0, arg1, arg2); 16 } 17 18 @Override 19 public void endDocument() throws SAXException { 20 System.out.println("\n…………结束解析文档…………"); 21 super.endDocument(); 22 } 23 24 /* arg0是名称空间 25 arg1是包含名称空间的标签,如果没有名称空间,则为空 26 arg2是不包含名称空间的标签 */ 27 @Override 28 public void endElement(String arg0, String arg1, String arg2) 29 throws SAXException { 30 System.out.println("结束解析元素 " + arg2); 31 super.endElement(arg0, arg1, arg2); 32 } 33 34 @Override 35 public void startDocument() throws SAXException { 36 System.out.println("…………开始解析文档…………\n"); 37 super.startDocument(); 38 } 39 40 /*arg0是名称空间 41 arg1是包含名称空间的标签,如果没有名称空间,则为空 42 arg2是不包含名称空间的标签 43 arg3很明显是属性的集合 */ 44 @Override 45 public void startElement(String arg0, String arg1, String arg2, 46 Attributes arg3) throws SAXException { 47 System.out.println("开始解析元素 " + arg2); 48 if (arg3 != null) { 49 for (int i = 0; i < arg3.getLength(); i++) { 50 // getQName()是获取属性名称, 51 System.out.print(arg3.getQName(i) + "=\"" + arg3.getValue(i) + "\""); 52 } 53 } 54 System.out.print(arg2 + ":"); 55 super.startElement(arg0, arg1, arg2, arg3); 56 } 57 }
测试类:
1 public class TestDemo { 2 3 public static void main(String[] args) throws Exception { 4 // 1.实例化SAXParserFactory对象 5 SAXParserFactory factory = SAXParserFactory.newInstance(); 6 // 2.创建解析器 7 SAXParser parser = factory.newSAXParser(); 8 // 3.获取需要解析的文档,生成解析器,最后解析文档 9 File f = new File("books.xml"); 10 SaxHandler dh = new SaxHandler(); 11 parser.parse(f, dh); 12 } 13 }
Dom解析:
1 public class Demo { 2 3 public static void main(String[] args) throws Exception { 4 //创建解析器工厂实例,并生成解析器 5 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 6 DocumentBuilder builder = factory.newDocumentBuilder(); 7 //创建需要解析的文档对象 8 File f = new File("books.xml"); 9 //解析文档,并返回一个Document对象,此时xml文档已加载到内存中 10 //好吧,让解析来得更猛烈些吧,其余的事就是获取数据了 11 Document doc = builder.parse(f); 12 13 //获取文档根元素 14 //你问我为什么这么做?因为文档对象本身就是树形结构,这里就是树根 15 //当然,你也可以直接找到元素集合,省略此步骤 16 Element root = doc.getDocumentElement(); 17 18 //上面找到了根节点,这里开始获取根节点下的元素集合 19 NodeList list = root.getElementsByTagName("book"); 20 21 for (int i = 0; i < list.getLength(); i++) { 22 //通过item()方法找到集合中的节点,并向下转型为Element对象 23 Element n = (Element) list.item(i); 24 //获取对象中的属性map,用for循环提取并打印 25 NamedNodeMap node = n.getAttributes(); 26 for (int x = 0; x < node.getLength(); x++) { 27 Node nn = node.item(x); 28 System.out.println(nn.getNodeName() + ": " + nn.getNodeValue()); 29 } 30 //打印元素内容,代码很纠结,差不多是个固定格式 31 System.out.println("title: " +n.getElementsByTagName("title").item(0).getFirstChild().getNodeValue()); 32 System.out.println("author: " + n.getElementsByTagName("author").item(0).getFirstChild().getNodeValue()); 33 System.out.println(); 34 } 35 } 36 37 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号