Java-HashMap中的扰动函数、初始化容量、负载因子以及扩容链表拆分
1.扰动函数
在hashmap中,put操作是这样进行的:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
其中会涉及到hash(key)的运算,hash并不是直接使用hashCode(),而是这样:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里的操作就称之为扰动函数
根据取模操作中的&和(length-1)这篇文章中提到的,计算出hash后我们可以使用&进行取模操作来确定放置在哪里。
现在问题是:计算hash时,为什么不直接用hashCode(),而是
// 把哈希值右移16位,之后与原哈希值做异或运算。
(h = key.hashCode()) ^ (h >>> 16)
先说结论:
增大随机性,优化散列效果,让数据元素更加均匀的散列(减少碰撞)。
1.1 实例
1.1.1 Hash的取值范围
在Java中,hashCode() 方法返回的哈希值是一个32位的有符号整数(int类型)。
因此,哈希值的取值范围是从 [-2147483648, 2147483647](即 -2^31 到 2^31-1)。
1.1.2 扰动函数的计算过程
对于扰动hash的函数的计算,做一个拆分。
/**
* 扰动函数计算hash
*
* @param key .
* @return hash
*/
final int hashAndLog(Object key) {
int hashCode;
if (key == null) {
return 0;
}
hashCode = key.hashCode();
int rightShift = hashCode >>> 16;
int result = hashCode ^ rightShift;
log.info("int: {},[sourceHash] hashCode : {}", String.format("%-12s", hashCode), to2$Padding(hashCode, 32));
log.info("int: {},[rightShift] hashCode >>> 16 : {}", String.format("%-12s", rightShift), to2$Padding(rightShift, 32));
log.info("int: {},[result] hashCode ^ rightShift: {}", String.format("%-12s", result), to2$Padding(result, 32));
return result;
}
/**
* int值转为2进制显示
*
* @param number num
* @param padding 填充0 总长度
* @return Binary
*/
public static String to2$Padding(int number, int padding) {
String binaryString = Integer.toBinaryString(number);
return String.format("%" + padding + "s", binaryString).replace(' ', '0');
}
测试用例
@Test
void name4() {
String str = "abc";
int i = hashAndLog(str);
}
输出结果
int: 96354 ,[sourceHash] hashCode : 00000000000000010111100001100010
int: 1 ,[rightShift] hashCode >>> 16 : 00000000000000000000000000000001
int: 96355 ,[result] hashCode ^ rightShift: 00000000000000010111100001100011
上面的过程可以用下面的图来表示

1.2 总结
1.异或的特性是什么?
当使用异或运算符(^)对两个二进制数进行操作时,有以下基本规则:
-
相同为0:如果两个操作数的对应位相同,则结果为0。 例如:0 ^ 0 = 0,1 ^ 1 = 0
-
不同为1:如果两个操作数的对应位不同,则结果为1。 例如:0 ^ 1 = 1,1 ^ 0 = 1
2.通过将哈希值向右移动16位(h >>> 16),将原哈希值的高位移动到了低位。
将原来的高16位移到低16位后,高16位被0补位,全是0。这个时候,原来的高16位:
- 如果是0:0 ^ 0 = 0,则还是0
- 如果是1:1 ^ 0 = 1,则还是1
可以发现,高16位的结果并不会受影响。
3.高16位变成低16位后,与原来的低16位做异或运算。
md这里没想清楚,等我再悟一悟。
下面是个实际的例子。
- 10万个不重复的单词
- 128个格子,相当于128长度的数组。
现在就是说这10万个数据怎么放进去这128的数组里。


y值就是每个位置的数据量。
-
没有使用前,有的位置数据多,有的位置数据少,分布的不够均匀。
-
使用了扰动函数后,每个位置的数据量均衡许多。
2.初始化容量和负载因子
2.1 初始化容量
在Java-取模操作中的&和(length-1)这篇文章中提到过,为了方便快速取模,我们通常将数组大小设置为2n
现在有一个问题,如果在初始化HashMap时,我们将初始化容量设置为17会怎么样?
@Test
void name5() {
HashMap<String,Object> hashMap = new HashMap<>(17);
}
点进去这个构造方法。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
可以看到调用 this(initialCapacity, DEFAULT_LOAD_FACTOR)传递到另一个构造方法。
public HashMap(int initialCapacity, float loadFactor) {
// 初始化容量小于0,抛异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始化容量最大值
if (initialCapacity > MAXIMUM_CAPACITY)
// static final int MAXIMUM_CAPACITY = 1 << 30;
initialCapacity = MAXIMUM_CAPACITY;
// 负载因子 小于0或者不是个数字,抛异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 负载因子直接赋值
this.loadFactor = loadFactor;
// 阈值需要计算,比如刚刚这里传了个初始化容量17进来,tableSizeFor(17)
this.threshold = tableSizeFor(initialCapacity);
}
- loadFactor:负载因子
- tableSizeFor:阈值
tableSizeFor(initialCapacity)用来计算阈值。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
上面的注释里也能看到,最大容量是这个。
1 左移 30 位的结果是 1073741824。换句话说,
MAXIMUM_CAPACITY的值被设置为 1073741824。
static final int MAXIMUM_CAPACITY = 1 << 30;
容量为啥不是2^32次方?
HashMap为了保持高效性和性能,限制了容量必须是2的幂次。
而2^32是一个超过Java中int类型表示范围的数值(231-1是int类型的最大值),所以HashMap的最大容量被限制为1 << 30,即2的30次方。
这里再补充一句,还记不记得Java中hashCode的取值范围?
在Java中,hashCode() 方法返回的哈希码(哈希值)是一个32位的整数,其取值范围是从[ -231,231-1],即[-2147483648,2147483647]。
废话完了,现在来解释下tableSizeFor这个函数,这个函数是为了找到最邻近输入值的那个最小2n。
看懂这个函数,最主要就是搞清楚|=是个啥玩意?
|=是位运算中的按位或赋值操作符。它将右操作数的位值与左操作数的位值进行按位或运算,并将结果赋值给左操作数。
具体来说,n |= n >>> x 的含义是将 n 的高 x 位的值复制到低 x 位上,实现了一种类似于向上取整的操作。
n |= n >>> 1 表示将 n 的高一半位的值复制到低一半位上,相当于将 n 的最高位复制到次高位上。
n |= n >>> 2 表示将 n 的高两半位的值复制到低两半位上,相当于将 n 的最高两位复制到次高两位上。
以此类推,n |= n >>> 4、n |= n >>> 8 和 n |= n >>> 16 会将 n 的高半部分的值复制到低半部分的对应位置上。
以上面的17为例。
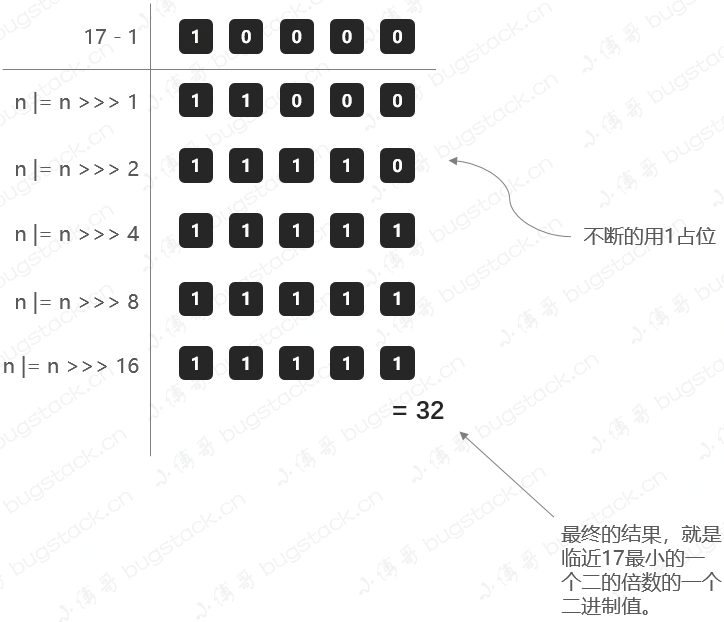
第一次就是把头一个1复制到第二个1,第二次就是把头两个1复制到次两个1...
有点感觉了对不,那为啥开始计算前,也就是最开始要减去1呢?
考虑到HashMap的容量必须是2的幂次,减去1可以确保在计算过程中不会出现直接得到小于
cap的2的幂次值的情况。
int n = cap - 1;
假设进来直接是2n,没有做减法,我们写个函数验证下。
static final int tableSizeFor(int cap) {
int MAXIMUM_CAPACITY = 1 << 30;
int n = cap;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
@Test
void name5() {
int i = tableSizeFor(16);
log.info("size: {}", i);
}
输出结果
size: 32
哦豁,变32了,浪费了嘛,所以,要排除掉本身就是2n的情况。
2.2 负载因子
要选择一个合理的大小下进行扩容,默认值0.75,就是说。
当阈值容量占了3/4时赶紧扩容,减少Hash碰撞。
同时0.75是一个默认构造值,在创建HashMap也可以调整,如果你希望用更多的空间换取时间,可以把负载因子调的更小一些,减少碰撞。
是说数组(绿色)位置的元素数量超过loadFactor,还是所有的(绿色+紫色)元素数量超过loadFactor?
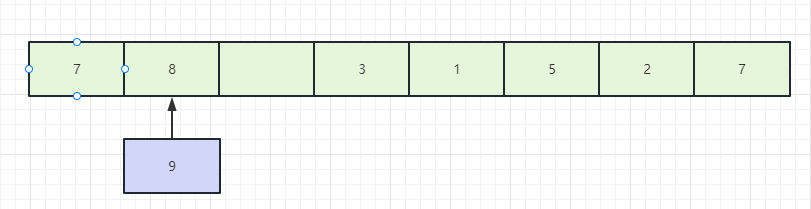
先说结论,是所有的元素,后文分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号