requests和beautifulsoup笔记
一、requests库
1.引入 :import requests
2.基本get 请求:
response = requests.get('http://httpbin.org/get')
print(response.text)
带参get请求:
response = requests.get('http://httpbin.org/get?name = zhangsan & age = 20')
print(response.text)
print('============')
data = {'name':'zhangsan','age':20}
response = requests.get('http://httpbin.org/get',params= data)
print(response.text)
3.添加加headers实现了爬虫浏览器的伪装。
headers = {'user-Agent':"Mozilla/5.0(windows NT 10.0;win64;X64)AppleWebkit/537.36(KHTML,like Gecko)chrome/70.0.3538.102 Safari/537.36"}
response = requests.get('http://httpbin.org/post',headers = headers)
print(response.text)
4.post请求
# post请求加上一个Headers请求
data = {'name':'zhangsan','age':22}
headers = {'user-Agent':"Mozilla/5.0(windows NT 10.0;win64;X64)AppleWebkit/537.36(KHTML,like Gecko)chrome/70.0.3538.102 Safari/537.36"}
response = requests.post('http://httpbin.org/post',headers = headers)
print(response.json())
5.获取cookie
response = requests.get('http://www.baidu.com')
print(response.cookies)
二、BeautifulSoup库
- 引入:from bs4 import BeautifulSoup
- BeautifulSoup库官方推荐使用lxml作为解析器,效率更高
- 解析得到的Soup文档可以使用find()和find_all()方法及selector()方法定位需要的元素
- 标签选择器:
import requests
from bs4 import BeautifulSoup
res = requests.get('http://httpbin.org')
soup = BeautifulSoup(res.text,'lxml')
print(soup.title) #title标签,<title>httpbin.org</title>
print(soup.title.name) #获取了title的name属性
print(soup.p) #p标签,如果有多个p标签只会返回访问的第一个内容
print(soup.code.string) #获取code标签里面的文字
print(soup.head.title.string) #嵌套选择
print(soup.p.contents) #获取子节点
print(soup.a.parents) #获取父节点
5.find_all (name,attrs,recursive,text,**kwargs) 可根据标签名、属性、内容、文档查找内容
print(soup.find_all(attrs = {'name':'elements'}))
print(soup.find_all('ul'))
attrs传入的是一个字典类型,传入的键名就是属性的名称,键值就是属性的值
6.find()方法与find_all()方法类似,只是find_all()方法返回的是文档中符合条件的所有tag,是一个集合(class 'bs4.element.ResultSet'), find()方法返回的一个Tag(class 'bs4.element.Tag')
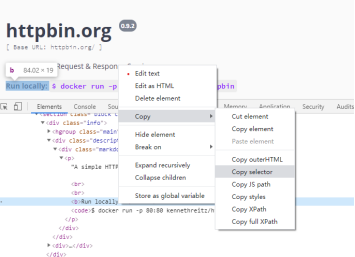
7.Selector()方法
c=soup.select('#swagger-ui > div > div > div > section > div.info > div.description > div > p > b')
print(c)
注:括号内的内容可以通过定位在网页源代码中想要提取的数据选择Copy selector得到,如下图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号