shell笔记
一,基础命令
常见使用命令
1.删除rm
rm -rf test.sh
2.编写文件
vim test.sh
i 进行编辑;完成编辑后,点击 Esc ,然后 :wq,进行保存退出。
3.查看当前文件夹下内容
ls
4.查看文件的内容
cat test.sh
5.执行bash文件的命令
./test.sh
/bin/sh test.sh
6.修改文件执行权限
chmod +x test.sh
Shell远程连接
1.远程连接服务器
ssh -p22 username@host
username就是用户信息,host就是远程连接的ip地址或者域名地址
密码输入时,看不到内容。
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$
解释:
tpadmin , 登录的用户名信息;
iZbp12wt8nsnj94x9ih6jfZ , 服务器地址(可能加密了);
”~“ ,远程登录服务器后,默认会在家目录下,这个代表家目录;
”$“ , 这个符号意味着是普通用户; “#” ,这个符号意味着是root权限的用户;
2.帮助命令--help、man
--help
ls --help
man
man ls
3.文件管理展示ls
ls
展示当前目录下的所有文件,
ls -a
展示当前目录下的所有文件,包括隐藏文件信息
ls -l
展示当前目录下的所有文件,并详细显示文件具体信息 ;相当于 “ll” 的命令
ls -al
命令的参数组合,既展示详细信息又有隐藏文件的详细信息;
4.切换工作目录cd
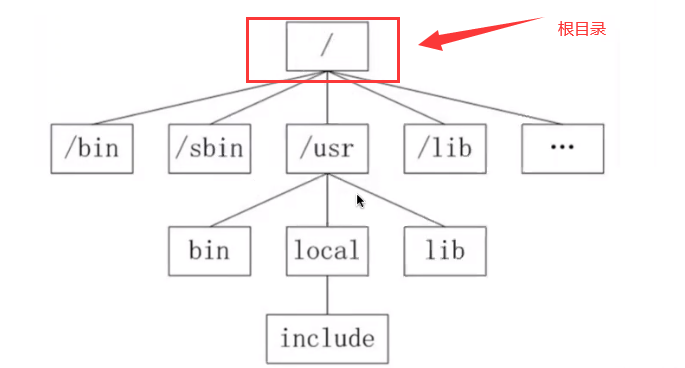
绝对路径:从根目录开始写的路径
相对路径:不是从根目录开始写的路径
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd /usr/bin
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ bin]$
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ bin]$ cd
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$
解释:通过绝对路径,进入了bin目录下,然后cd,返回到“~”家目录
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd /
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ /]$ cd home
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ home]$ ls
nohup.out temp tpadmin
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ home]$ cd tpadmin
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd ..
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ home]$ cd ./tpadmin
或者使用:cd tpadmin
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd ../../bin
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ bin]$
解释:通过相对路径,进入家目录,ls后看到了tpadmin等用户信息,这时想要返回家目录,cd tpadmin返回到了家目录。cd .. 是返回上级目录,从家返回到了home;这时home目录下有自己的用户,就可以通过cd tpadmin,通过自己的用户返回到家目录。但是怎么用相对路径进入bin目录呢?cd .. 是进去上一级目录下,也就是home,home的上一级是/根目录,所以再次使用 “..” 进入根目录,根目录下有bin目录,就进去bin目录下了。
5.查看当前路径下的绝对路径pwd
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ pwd
/home/tpadmin
6.创建新目录mkdir
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ mkdir feier
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ mkdir a/b/c -p
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
a
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ cd a
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ ls
b
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ cd b
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ ls
c
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ cd c
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$ ls
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$
解释:创建目录命令;与创建递归目录命令,注意创建递归目录时的参数-p。
7.创建新文件touch
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$ touch 1.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$ ls
1.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$ cat 1.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$
解释:touch 创建文件命令,直接会创建一个空的文件。
8.删除文件或者目录rm
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$ ls
1.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$ rm 1.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$ ls
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ c]$
解释:删除文件时,直接rm 文件名,就可以删除文件;
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ ls
c
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ rm c
rm: cannot remove `c': Is a directory
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ ls
c
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ rm -r c
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ ls
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$
解释:文件删除时,rm命令是直接删除不了的,需要加上参数 -r;
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ rm -r c
rm: cannot remove `c': No such file or directory
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ rm -rf c
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$ ls
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ b]$
解释:文件删除时,想要强制删除,加上-f的参数,就无论有没有存在该目录,都会删除掉。请谨慎使用!
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ ls
b
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ rm -ri b
rm: remove directory `b'? y
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ ls
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ touch 1
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ ls
1
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ rm -ri 1
rm: remove regular empty file `1'? n
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$ ls
1
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ a]$
解释:文件,目录进行删除时,建议用rm -ri 文件名或者目录名,会弹出询问,是否删除的提示;更加保险,所以删除文件时,建议使用此命令。-i的参数
9.拷贝cp
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ touch 1
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
1 alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cp ./1 ./feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
1 alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
1 a
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$
解释:家目录下创建1文件,进行cp到家目录下的feier目录下;
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
1 abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
1 a
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ cp -a ./a ../abc
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ cd ../abc
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$ ls
a
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$
解释:家目录下有abc和feier文件夹,feier目录下有a目录,将a目录拷贝到abc目录下;这时,需要用到参数 “-a” ,不然就会提示这是一个目录的提示
10.移动/重命名mv
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
1 abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ mv 1 f
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata f feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ mv f ./abc
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd abc/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$ ls
a f
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$
解释:同级下,家目录下有1文件,将1重命名为f,直接就可以mv 1 f,这就是重命名;
如果将文件移动到某个目录下,可以使用相对路径,如重命名后的f移动到家目录下的abc目录下,命令:mv f ./abc,f文件就到了abc目录下。
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$ ls
a f
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$ cd ..
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
1 a
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ cd ../abc/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$ mv f ../feier/m
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$ ls
a
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ abc]$ cd ../feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
1 a m
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$
解释:abc目录下有个f文件,abc上一级目录是家目录,家目录下还有个feier目录;如何将abc目录下的f文件移动到feier目录下并修改名字为m呢?切换到abc目录下,执行mv f ../feier/m,目的达到
11.建立链接文件:ln
建立软连接:ln -s [目录下的文件] [目标目录]
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd ./feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
1 a m
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ cd ..
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ln -s ./feier/1 .
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
1 abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
1 a m
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ rm 1
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
a m
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ cd ..
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
1 abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cat 1
cat: 1: No such file or directory
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ rm 1
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata feier test.sh
[tpadmin@2wt8nsnj94x9ih6jfZ ~]$
解释:家目录下有feier目录,1文件在feier目录下,如何将1文件建立在家目录的软链接下呢?
命令:家目录下执行ln -s ./feier/1 .就完成了在家目录下建立的软连接。就可以直接在家目录下直接查看到1文件。
11.查找文件find
根据文件名字,查找符合条件的文件
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ touch 1.txt 2.txt 3.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
1.txt 2.txt 3.txt abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ find ./ -name 1.txt
./1.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ find ./ -name "*.txt"
./1.txt
./2.txt
./3.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$
解释:查找某个目录下是否有某个文件的命令;可以根据文件名进行搜索查找,比如创建了三个.txt文件,命令:find ./ -name 1.txt;或者说想要查找txt结尾的文件,就可以用正则匹配,命令:find ./ -name "*.txt"
12.查看文件中内容:cat,less,more,head,tail
cat 2.txt
less 2.txt
more 2.txt
head 2.txt
tail 2.txt
head -n 3 2.txt
tail -n 3 2.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ head 2.txt
1
2
3
4
5
6
7
8
9
10
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ tail 2.txt
11
12
13
14
15
16
17
18
19
20
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ head -n 3 2.txt
1
2
3
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ tail -n 3 2.txt
18
19
20
解释:都是显示文件内容,各有用处;
13.打包压缩tar,只进行gz压缩介绍
打包:将多个文件或者目录压缩成一个文件,但是总占用没有变化;
压缩:在打包基础上,通过算法将这个文件进行压缩,占用空间变小;
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
2.txt 3.txt abc alidata feier test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ tar -zcvf f.tar.gz 2.txt 3.txt
2.txt
3.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
2.txt 3.txt abc alidata feier f.tar.gz test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ rm 2.txt 3.txt
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata feier f.tar.gz test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$
解释:将家目录下的2.txt和3.txt进行压缩;命令 :tar -zcvf f.tar.gz 2.txt 3.txt其中“-zcvf”是参数,进行压缩的意思,“f.tar.gz”是压缩后文件的名字,2.txt和3.txt是将要压缩的文件
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
abc alidata feier f.tar.gz test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
a m
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ cd ..
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ tar -xf f.tar.gz
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ls
2.txt 3.txt abc alidata feier f.tar.gz test.sh
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ tar -xf f.tar.gz -C ./feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ cd feier/
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ feier]$ ls
2.txt 3.txt a m
解释:将f.tar.gz进行解压出来,解压到当前文件夹和指定的文件夹下;
参数 “-C” ,后面跟指定解压的路径
vim文本处理
1.文本编辑vi/vim
vi标准编辑器;相当于windows的笔记本
vim,升级版,可以写代码
命令行模式时,通常使用的命令是:
“gg”,两个g,跳转到文件内容的第一行;
“G”,一个大写的G,跳转到文件内容的最后一行
"$", 一个$键,从行首跳到行尾
“^”,一个小^号,就可以从行尾跳到行首
”q!“,不保存退出
"wq",保存退出
2.输出
echo
echo 123
3.输出重定向 ">"
解释:可以通过echo输出的内容,进行快速的创建一个文件
[ck186943@shell.ceshiren.com ~]$ echo 123
123
[ck186943@shell.ceshiren.com ~]$ echo 123 >1.txt
[ck186943@shell.ceshiren.com ~]$ cat 1.txt
123
[ck186943@shell.ceshiren.com ~]$ ls
1.txt a hog
[ck186943@shell.ceshiren.com ~]$
4.修改权限chmod
[ck186943@shell.ceshiren.com ~]$ ll
total 12
-rw-rw-r-- 1 ck186943 ck186943 4 Mar 5 18:04 1.txt
drwxrwxr-x 2 ck186943 ck186943 4096 Mar 5 16:41 a
-rw-rw-r-- 1 ck186943 ck186943 24 Mar 5 18:04 hog
d:代表目录
-:文件
l:连接文件
b:设备文件
rwx rwx r-x,读,写,执行
r:---4
w: ---2
x: ---1
(个人) (个人所在的组) (其他人) rw- rw- r-- 三个为一组;
chmod 666 文件;说明文件的权限是读写,人员包括(个人) (个人所在的组) (其他人)
5.查看网卡信息ifconfig
ifconfig
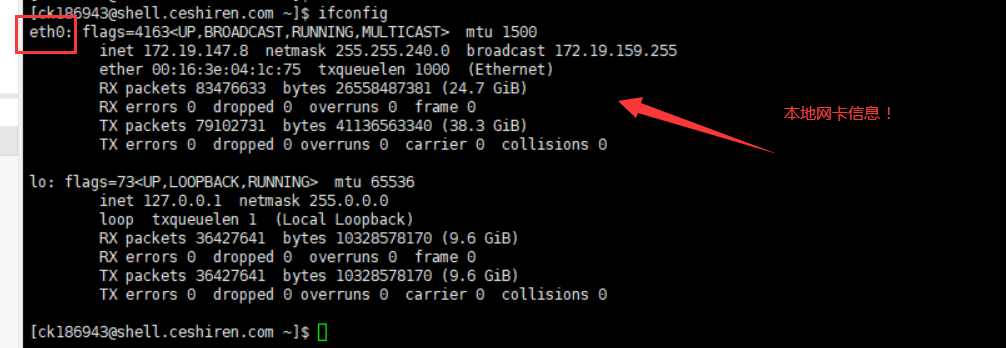
etho:代表本地网卡信息
inet:本地对应的ip地址
6.测试远程主机的连通性ping
ping,IP地址
-c ,次数,发送几次包
-i ,时间,每次发送,间隔时间
[tpadmin@iZbp12wt8nsnj94x9ih6jfZ ~]$ ping -c 3 -i 3 10.19.38.4
PING 10.19.38.4 (10.19.38.4) 56(84) bytes of data.
64 bytes from 10.19.38.4: icmp_seq=1 ttl=64 time=1.37 ms
64 bytes from 10.19.38.4: icmp_seq=2 ttl=64 time=1.34 ms
64 bytes from 10.19.38.4: icmp_seq=3 ttl=64 time=1.34 ms
--- 10.19.38.4 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 6007ms
7.打印Linux网络系统的状态信息
netstat
-t,参数,列出所有tcp
-n, 以数字形式显示地址和端口号
-p,显示进程的pid和名字
netstat -tnp
8.登出exit
退出linux,返回本地
Linux常用命令之性能统计
1.硬件简介
cpu,内存,硬盘,网卡
2.查看cpu信息:cat/proc/cpuinfo
[ck186943@shell.ceshiren.com ~]$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
stepping : 1
microcode : 0x1
cpu MHz : 2499.994
cache size : 40960 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 20
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch arat fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt
bogomips : 4999.98
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
stepping : 1
microcode : 0x1
cpu MHz : 2499.994
cache size : 40960 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 20
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch arat fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt
bogomips : 4999.98
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
processor : 代表着cpu,服务器一半都有两个cpu。
model name : 代表着cpu型号
3.查看进程命令top
top - 20:39:00 up 127 days, 9:20, 13 users, load average: 0.03, 0.04, 0.05
Tasks: 147 total, 1 running, 125 sleeping, 20 stopped, 1 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3881920 total, 198736 free, 230596 used, 3452588 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1210256 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4747 root 20 0 116268 15956 4252 S 0.3 0.4 210:58.18 node_exporter
17884 root 10 -10 151908 27512 5680 S 0.3 0.7 47:31.26 AliYunDun
1 root 20 0 43324 2904 1532 S 0.0 0.1 44:39.54 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:02.35 kthreadd
解释:
127 days, 9:20 ,13 users ;意思:运行了多少天,多少小时, 多少个用户在使用。
load average: 0.33, 0.04, 0.05 ; 意思:一分钟的负载,5分钟的负载,15分钟的负载。(目前是双核的服务器,当负载大于2的时候,说明了,性能就很不好了。)
Tasks:147 ,total, 1 running,125 sleeping, 20 stopped, 1 zombie; 意思: 就是服务器现在占用多少进程,有几个在跑,几个睡眠,几个停止,几个僵尸进程;(当僵尸进程太多时,就会造成服务器资源的占用,当用户跑应用时,就会造成很慢,影响不好,系统上一般是没有僵尸进程的,不受系统管制。)
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st 。意思:us:用户使用的;sy:操作系统本身(linux内核);id:空闲,等待;wa:io硬盘网络(当磁盘读写不过来后,cpu会一直等待,wa就会居高不下); st :虚拟机,一般不用
KiB Mem : 3881920 total, 198736 free, 230596 used, 3452588 buff/cache 意思:总内存,空闲内存,已用内存,缓存(cpu往内存写的)
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
S代表着,进程的运行状态:running, sleeping, stopped, zombie
4.测试系统负载
命令1:{ yes > /dev/null & } && sleep 30 && ps -ef | grep yes | awk '{print $2}' | xargs kill
解释:yes命令会一直运行,30秒后,将进程杀死;
注意:cpu的变化,负载的变化,进程的运行状态,运行时间变化
命令2:for i in $(seq 0 $(($(cat /proc/cpuinfo | grep processor | wc -l)-1))); do taskset -c $i yes > /dev/null & done && sleep 60 && ps -ef | grep yes | awk '{print $2}' | xargs kill
解释:去查找有个核,几个进程在跑,然后一个进程,分别运行yes命令,运行60s后,将进程杀死。
注意:cpu的变化,负载的变化,进程的运行状态,运行时间变化
5.介绍top命令,参数
只想查看一个进程的top参数?怎么做?
top -p 进程id(PID) -d 1 -n 4
意思:
-p,获取指定端口的进程的数据
-d ,间隔时间,每隔多长时间更新一次,
-n , 获取多次cpu的执行情况,top -n 4
6.内存 free
内存运行速度快
[ck186943@shell.ceshiren.com ~]$ free
total used free shared buff/cache available
Mem: 3881920 220740 207568 2120716 3453612 1228940
Swap: 0 0 0
[ck186943@shell.ceshiren.com ~]$
[ck186943@shell.ceshiren.com ~]$ free -h
total used free shared buff/cache available
Mem: 3.7G 219M 198M 2.0G 3.3G 1.2G
Swap: 0B 0B 0B
[ck186943@shell.ceshiren.com ~]$
total:总物理内存;
used :已经使用的物理内存
free:没有使用的物理内存
shared:多进程共享内存
buff/cache:读写缓存内存,这部分内存是当空闲来用的,当free内存不足时,linux内核会将此内存释放
buffer是即将要被写入磁盘的,而cache是被从磁盘中读出来的;
available :还能被“应用程序”使用的物理内存
Swap,交换区当物理内存不够用时,会将占用硬盘的内存,供当前系统使用,(通过调整Swap,有时可以越过系统性能瓶颈,节省系统升级费用)
7.IO(Input Output)
硬盘IO,网卡读取和传输数据
需要安装工具,
Ubuntu:
apt install -y sysstat
apt install iftop
apt install strace
CentOs
yum install -y sysstat
yum install -y epel-release
yum install -y iftop
yum install strace
硬盘IO:读写就影响到了计算机开机的快慢,如果有程序中的应用,读写要求较高,那么硬盘就会影响程序应用的快感。
写:dd if=/dev/zero bs=1024 count=4096000 of=test.iso
读:dd if=test.iso bs=64k | dd of=/dev/null
命令:iostat 1
参数:
1: 一秒执行一次,查看一次结果
-c :只看cpu的情况 iostat -c
-d:只看硬盘设备的情况 iostat -d
执行写的命令,如下:
avg-cpu: %user %nice %system %iowait %steal %idle
1.01 0.00 10.61 88.38 0.00 0.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 328.00 2752.00 129936.00 2752 129936
avg-cpu: %user %nice %system %iowait %steal %idle
0.50 0.00 1.51 92.46 0.00 5.53
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 359.00 5452.00 123008.00 5452 123008
avg-cpu: %user %nice %system %iowait %steal %idle
2.02 0.00 2.53 29.80 0.00 65.66
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 548.00 12024.00 37884.00 12024 37884
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
avg-cpu: %user %nice %system %iowait %steal %idle
0.50 0.00 0.00 0.00 0.00 99.50
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
解释:%iowait:就是硬盘的使用情况,硬盘使用率升高,别的都要在等待它,那么它就是影响程序应用慢的原因,随着写应用的结束它的值也趋近于0;
%idle:这个是衡量cpu是否忙碌,随着它的值,从小到大变化,意味着:它的空闲从小到大的变化。值越大,越空闲。
tps:事务处理数,
kB_read/s:读取速度
kB_wrtn/s:写入速度
kB_read:总共读取
kB_wrtn:总共写入
网络IO
网络带宽一般有10m的,读写并不是很快,一般没有硬盘的速度快
命令:iftop
shell.ceshiren.com => 39.106.113.77 0b 7.47Kb 5.61Kb
<= 0b 434b 326b
shell.ceshiren.com => 101.71.245.110 2.61Kb 2.47Kb 2.49Kb
<= 184b 184b 184b
shell.ceshiren.com => 100.100.30.26 0b 1.34Kb 1.35Kb
<= 0b 74b 74b
shell.ceshiren.com => 100.100.2.136 0b 154b 328b
<= 0b 228b 411b
TX: cum: 31.4KB peak: 41.2Kb rates: 3.05Kb 10.6Kb 11.4Kb
RX: 5.29KB 5.09Kb 920b 1.38Kb 1.92Kb
TOTAL: 36.7KB 45.6Kb 3.95Kb 12.0Kb 13.4Kb
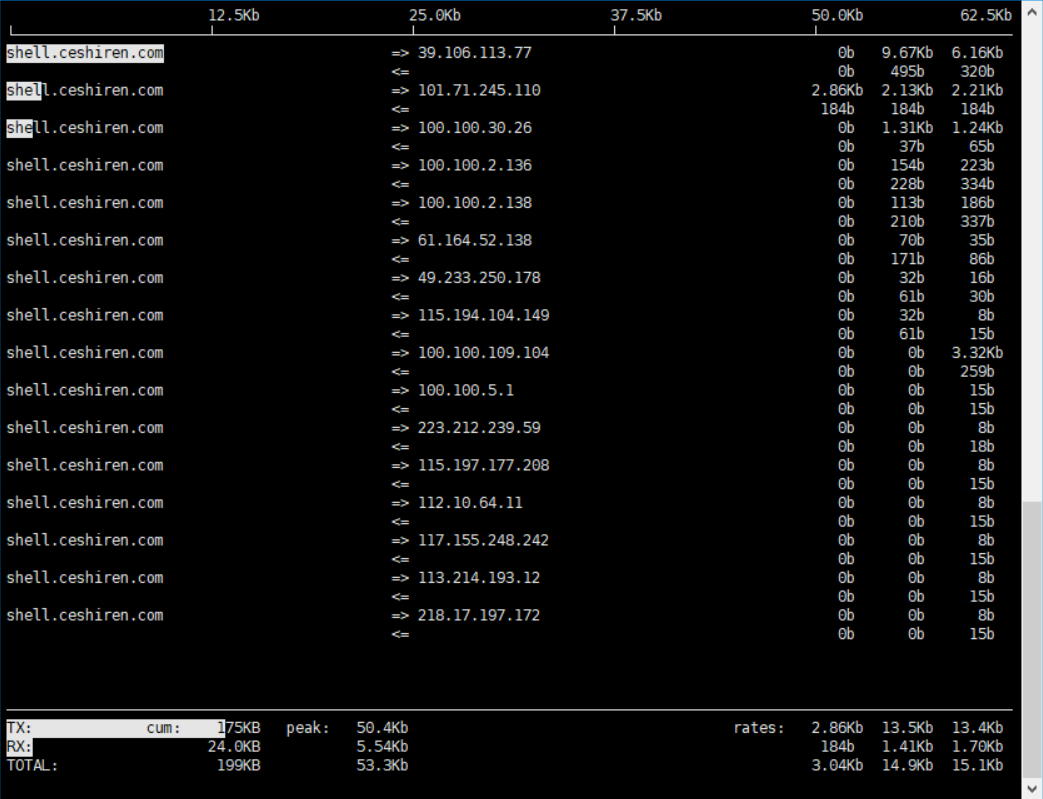
解释:
TX :发送
RX :接收
TOTAL :全部的流量
cum :运行iftop到目前时间的总流量
peak :峰值流量
rates : 分别表示过去 2s 10s 40s 的平均流量
<= => :这两个左右箭头,表示的是流量的方向
测试文件:http://mirrors.aliyun.com/centos/8.2.2004/isos/x86_64/CentOS-8.2.2004-x86_64-dvd1.iso (已失效)
wget http是下载某个路径的文件,可以测试接收的大小;
访问服务器,下载服务器的大文件时,可以测试发送的大小;
接收的带宽,在linux显示的具体数据,除以8,才是真正的发送和接收大小,注意换算。
Linux常用统计命令
排序sort
文本排序,
去重uniq
uniq -c,去掉重复的,并显示重复的数量
wc统计字节数
[ck186943@shell.ceshiren.com test]$ cat wc_demo.txt
hello world
hi
hogwarts
[ck186943@shell.ceshiren.com test]$ cat wc_demo.txt | wc
4 4 25
[ck186943@shell.ceshiren.com test]$
解释:
4行,4个单词,25个字符
参数:
-c :统计字节数:chars
-l :统计行数
-w :统计单词数
-L :打印最长行的长度
Linux三剑客
管道
Linux提供管道符“|”将两个命令隔开,管道符左边命令的输出就会作为管道符右边命名的输入
正则
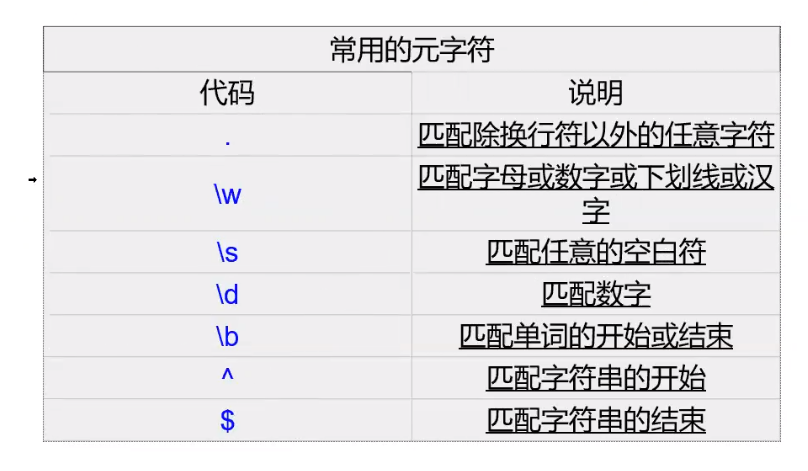
正则表达式就是记录文本规则的代码
举例子:
匹配“hi”的单词:\bhi\b,正则直接匹配。
匹配“hi”单词后面有“lucy”单词的情况:\bhi\b.*\blucy\b,正则直接匹配
匹配以0开头,然后是两个数字,然后一个连字号“-”,最后是8个数字:0\d{2}-\d{8},正则直接匹配
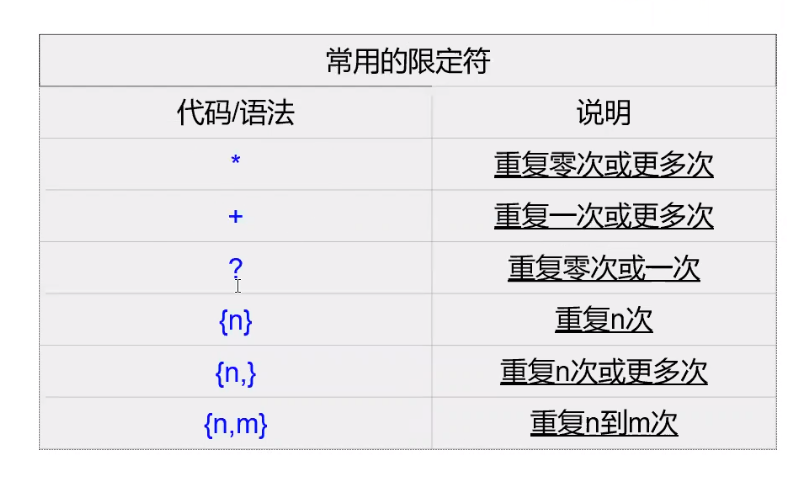
-
匹配a字母开头的单词:
\ba\w*\b -
匹配刚好6个字符的单词:
\b\w{6}\b -
匹配一个或者更多连续的数字:
\d+(sed中没有\d,[0,9]进行代替) -
匹配5位到12位的qq号:
^\d{5,12}$多一个,少一个都不行
grep过滤
命令形式:grep [OPTIONS] PATTERN [FILE];就是grep +参数+ 正则+ 文件
-v :显示不被正则匹配到的行
-n :显示行数
-C :返回匹配行和匹配行的前后两行
grep -C2 2 text.txt
-A :返回匹配行和匹配行的后一行
-B :返回匹配行和匹配行的前一行
实战1
查找文件内容中包含root的行数,文件1.txt
查找文件内容中不包含root的行数
grep -n root 1.txt
grep -nv root 1.txt
[ck186943@shell.ceshiren.com ~]$ grep error -r aaa
aaa/b.log:error
aaa/b.log:error
aaa/a.log:error
aaa/a.log:error
aaa/a.log:error
[ck186943@shell.ceshiren.com ~]$ ls
1.txt aaa test.sh
解释:grep error -r aaa查找aaa文件夹 下的所有log日志的错误
实战2
查找以s开头的行
查找以n结尾的行
grep -n ^s 1.txt
grep -n n$ 1.txt
sed过滤
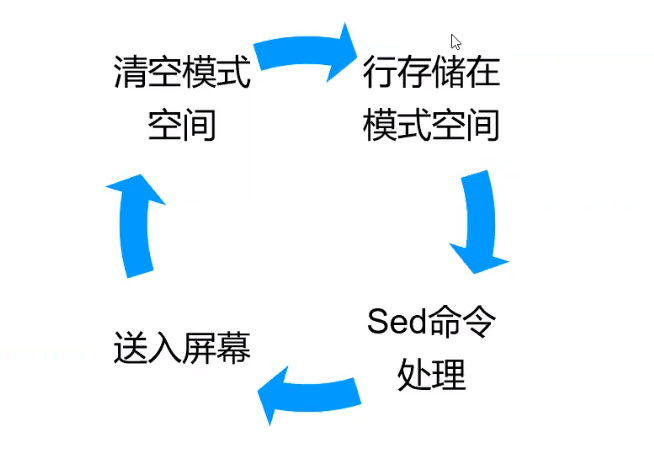
定义:sed是流编辑器,一次处理一行内容
命令形式:sed [-hn..] [-e<script >] [-f <script文件>] [文本文件]
-h 显示帮助
-n 仅显示script处理后的结果
-e<script> 以选项中指定的script来处理输入的文本文件
-f<script文件>以选项中指定的script文件来处理输入的文本文件
常见的几个动作:
a :新增 sed -e '4 a newline'
c :取代 sed -e '2,5c No 2-5 number'
d :删除 sed -e '2,5d'
i :插入 sed -e ‘ 2i newline‘ 插入是在前面,新增在后面
p :打印 sed -n ’/root/p‘
s :取代 sed -e 's/old/new/g' /g,全局
实战1
查看帮助
man sed
sed -h
???怎么查找帮助文档的信息呢?
“/”,输入查找内容。大小写的“N”,去上下查找输入的内容
在第四行后添加新字符串(流处理,原文件并未改变)
sed -e '4 a newline testfile' test.txt
实战2
在第二行后加上 newline
sed ’2 a newline‘ test.txt
在第三行前加上 newline
sed -e ’3 i newline‘ test.txt
实战3
全局替换
sed -e ’s /root/newroot/g‘ test.txt /g 全局替换
直接修改文件内容
sed -i 's/root/hello/g' test.txt i 参数很恐怖,一定要确认再三后,执行
注!sed和grep的区别:
grep只能查找
sed,增、删、取代、插入、等都可以达到,更多操作文本的操作。
awk过滤
定义:把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分在进行后续处理
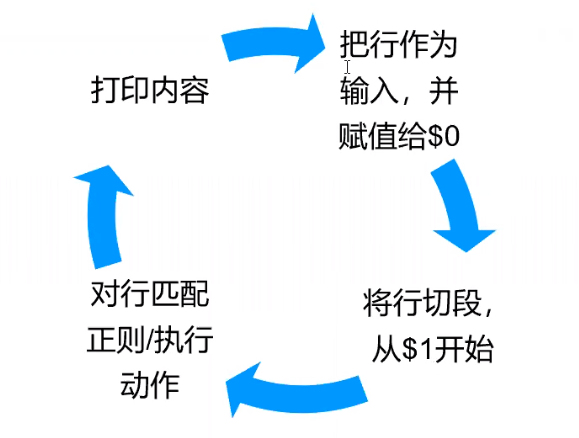
命令形式:awk 'pattern + action' [FILE]
解析,-pattern :正则表达式
-action : 对匹配到的内容执行的命令(默认为输入每行内容)
常用参数:
BEGIN 处理文本之前要执行的操作
END 处理文本之后要执行的操作
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数
NR 已读的记录数
常用参数:
OFS 输入域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
$0 整条记录
$1 表示当前行的第一个域。。。以此类推
实战1
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
awk -F : '/root/{print $0}' /etc/passwd
打印/etc/passwd/的第二行信息
awk -F : 'NR==2{print $0}' /etc/passwd
NR :参数,已读的记录数
实战2
使用begin加入标题
awk -F : 'BEGIN{print "BEGIN END"}/root/{print $1,$2}' /etc/passwd
自定义分隔符?
提示:RS 控制记录分隔符
echo '111|222|333|444|555' | awk -F : '{print $0}'
ps:这个命令只能将”:“分割,”|“不能分割
echo '111|222|333|444|555' | awk 'BEGIN{RS="|"}{print $0}'
RS需要用到BEGIN
Bash编程语法
变量
your_name="abc"
echo your_name
只读变量
a="123"
readonly a
删除变量
unset variable_name
特性:只在当前的shell页面中有效
变量类型:
字符串:your_name="hogwarts"
拼接字符串:greeting=”hello,”$your_name“!“
数组:array_name=(value0 value1 value2 value3)
取数组 valuen=${array_name[n]}
单独赋值 array_name[0]=value00
[ck186943@shell.ceshiren.com ~]$ a=(a b c d)
[ck186943@shell.ceshiren.com ~]$ echo ${a[1]}
b
[ck186943@shell.ceshiren.com ~]$ echo ${a[5]}
[ck186943@shell.ceshiren.com ~]$ echo ${a[00]}
a
[ck186943@shell.ceshiren.com ~]$ echo ${a[*]}
a b c d
实战
1数组初始化
my_array=(A B "C" D)
echo ${my_array[0]}
2数组单个定义
[ck186943@shell.ceshiren.com ~]$ c[0]=1
[ck186943@shell.ceshiren.com ~]$ echo ${c[0]}
1
[ck186943@shell.ceshiren.com ~]$ c[4]=4
[ck186943@shell.ceshiren.com ~]$ echo ${c[4]}
4
[ck186943@shell.ceshiren.com ~]$ echo ${c[@]}
1 4
[ck186943@shell.ceshiren.com ~]$ echo ${c[2]}
[ck186943@shell.ceshiren.com ~]$
解释:
定义单个数组,语法
if定义
if condition
then
command 1
command 2
...
fi
例子:
[ck186943@shell.ceshiren.com ~]$ if [2==2];then echo "true";else echo "false";fi
-bash: [2==2]: command not found
false
[ck186943@shell.ceshiren.com ~]$ if [ 2==2 ];then echo "true";else echo "false";fi
true
[ck186943@shell.ceshiren.com ~]$
解释:==号的时候,一个中括号,"<"">"的时候,两个中括号
[ck186943@shell.ceshiren.com ~]$ if [[ 2>1 ]];then echo "2>1";else echo "2<1";fi
-bash: unexpected token 284 in conditional command
-bash: syntax error near `2>'
[ck186943@shell.ceshiren.com ~]$ if [[ 2 > 1 ]];then echo "2>1";else echo "2<1";fi
2>1
[ck186943@shell.ceshiren.com ~]$
解释:注意空格
实战
比较两个变量的大小并输出不同的值
-eq :相等
-lt :小于
-gt :大于
[ck186943@shell.ceshiren.com ~]$ a=10
[ck186943@shell.ceshiren.com ~]$ c=20
[ck186943@shell.ceshiren.com ~]$ if [ $a -eq $c ];then echo "equal"; elif [ $a -lt $c ];then echo "small"; elif [ $a -gt $c ];then echo "big";fi
small
[ck186943@shell.ceshiren.com ~]$ a=30
[ck186943@shell.ceshiren.com ~]$ if [ $a -eq $c ];then echo "equal"; elif [ $a -lt $c ];then echo "small"; elif [ $a -gt $c ];then echo "big";fi
big
[ck186943@shell.ceshiren.com ~]$ a=20
[ck186943@shell.ceshiren.com ~]$ if [ $a -eq $c ];then echo "equal"; elif [ $a -lt $c ];then echo "small"; elif [ $a -gt $c ];then echo "big";fi
equal
for循环
for var in item1 item2... itemN
do
command1
command2
...
commandN
done
举例:
for loop in 1 2 3 4 5
echo "hello"
done
实战
循环读取文件内容并输出
[ck186943@shell.ceshiren.com ~]$ for i in $(cat 1.txt);do echo $i;done
new
new000
newroot
newroot000
new111
root222222
haha哈哈
[ck186943@shell.ceshiren.com ~]$ cat 1.txt
new
new000
newroot
newroot000
new111
root222222
haha哈哈
[ck186943@shell.ceshiren.com ~]$ for i in $(cat 1.txt);do echo $i"abc0001";done
newabc0001
new000abc0001
newrootabc0001
newroot000abc0001
new111abc0001
root222222abc0001
haha哈哈abc0001
解释:for循环,循环体可以添加信息
while循环
while condition
do
command
done
举例
int=1
while(( $int<=5 ))
do
echo $int
let "int++"
done
实战
循环读取文件内容并输出
while read line;do echo $line;done<dir.txt
for和while的区别:当一行内容中有空格时,for会展示两行,while只展示一行:如下展示
[ck186943@shell.ceshiren.com ~]$ for i in $(cat 1.txt);do echo $i;done
new
new
new000
newroot
newroot000
new111
root222222
haha哈哈
[ck186943@shell.ceshiren.com ~]$ while read line;do echo $line;done<1.txt
new new
new000
newroot
newroot000
new111
root222222
haha哈哈
[ck186943@shell.ceshiren.com ~]$ cat 1.txt
new new
new000
newroot
newroot000
new111
root222222
haha哈哈
Bash基本使用
read的使用
[ck186943@shell.ceshiren.com ~]$ read a
123123
[ck186943@shell.ceshiren.com ~]$ echo $a
123123
[ck186943@shell.ceshiren.com ~]$ read a b c
123 456 789
[ck186943@shell.ceshiren.com ~]$ echo $a
123
[ck186943@shell.ceshiren.com ~]$ echo $b
456
[ck186943@shell.ceshiren.com ~]$ echo $c
789
read的默认存储值:REPLY
[ck186943@shell.ceshiren.com ~]$ read
123123
[ck186943@shell.ceshiren.com ~]$ echo $REPLY
123123
[ck186943@shell.ceshiren.com ~]$
文件参数传递
[ck186943@shell.ceshiren.com ~]$ vim test.sh
[ck186943@shell.ceshiren.com ~]$ cat test.sh
#!/bin/bash
echo $1 $2 $3
echo "文件名:"$0
echo "参数的数量:"$#
echo "参数的全部内容:"$*
echo "执行返回结果:"$?
[ck186943@shell.ceshiren.com ~]$ bash test.sh
文件名:test.sh
参数的数量:0
参数的全部内容:
执行返回结果:0
解释:文件参数传递的基本操作
加减乘除的练习:
[ck186943@shell.ceshiren.com ~]$ vim test.sh
[ck186943@shell.ceshiren.com ~]$ cat test.sh
注意:一个空格都不能错误
判断的练习
[ck186943@shell.ceshiren.com ~]$ cat test.sh
[ck186943@shell.ceshiren.com ~]$ if [ 10 -gt 5 ]
> then
> echo "big"
> fi
> big
> [ck186943@shell.ceshiren.com ~]$ if [ 10 -lt 11 ];then echo "small";fi
> small
可以放入bash文件,也可直接执行
有意思的操作
[ck186943@shell.ceshiren.com ~]$ ls
1.txt 20 a hog test.sh
[ck186943@shell.ceshiren.com ~]$ cat test.sh
解释:执行bash文件进行创建文件夹,创建文件,写入文件信息
由此可见:任何的shell命令都可以写入到sh文件中,并执行;组成一个强大的工具
实用用途
ps aux | awk '{print $3}' | grep -v %CPU
ps aux|awk 'NR>1{ sum+=$3};END {print sum}'
计算cpu'占用之和
linux进阶命令
curl命令
用来请求web服务器
1.代理支持 proxy support
curl -x 127.0.0.1:8888 https://www.baidu.com
2.get请求
-G :使用get请求
-d :指定请求数据
curl -G https://www.baidu.com
curl -X GET https://www.baidu.com
3.post请求
-d :指定post请求体
curl -d 'login=1234' https://www.baidu.com
curl -X POST https://www.baidu.com
4.保存响应内容
-o :响应内容保存
curl -o tmp.html https://www.baidu.com
5.输出通信的整个过程(三次握手,请求头)
-v :通讯过程
curl -v https://www.baidu.com
6.不输出错误和进度信息
-s :头信息,去掉
curl -s https://www.baidu.com
jq命令
简单理解json的提取器,使用前需要安装jq。
[ck186943@shell.ceshiren.com ~]$ echo '{"a":10,"b":20}'
{"a":10,"b":20}
[ck186943@shell.ceshiren.com ~]$ echo '{"a":10,"b":20}'|jq '.'
{
"a": 10,
"b": 20
}
解释:优化json代码,高亮显示。
[ck186943@shell.ceshiren.com ~]$ echo '{"subjectInfoList": [{"insurantInfoList": [{"age": "25","birthday": "1995-07-16","identifyNumber": "110101199507167925"}]}]}' |jq '.'
{
"subjectInfoList": [
{
"insurantInfoList": [
{
"age": "25",
"birthday": "1995-07-16",
"identifyNumber": "110101199507167925"
}
]
}
]
}
[ck186943@shell.ceshiren.com ~]$ echo '{"subjectInfoList": [{"insurantInfoList": [{"age": "25","birthday": "1995-07-16","identifyNumber": "110101199507167925"}]}]}' |jq '.subjectInfoList[0]'
{
"insurantInfoList": [
{
"age": "25",
"birthday": "1995-07-16",
"identifyNumber": "110101199507167925"
}
]
}
[ck186943@shell.ceshiren.com ~]$ echo '{"subjectInfoList": [{"insurantInfoList": [{"age": "25","birthday": "1995-07-16","identifyNumber": "110101199507167925"}]}]}' |jq '.subjectInfoList[0].insurantInfoList[0]'
{
"age": "25",
"birthday": "1995-07-16",
"identifyNumber": "110101199507167925"
}
[ck186943@shell.ceshiren.com ~]$ echo '{"subjectInfoList": [{"insurantInfoList": [{"age": "25","birthday": "1995-07-16","identifyNumber": "110101199507167925"}]}]}' |jq '.subjectInfoList[0].insurantInfoList[0].age'
"25"
解释:可以通过jq,一级一级的取值
json中取值,进行重组数组,注意json格式取值
[ck186943@shell.ceshiren.com ~]$ echo '{"a":1,"b":2,"c":3}' |jq [.a,.b,.c]
[
1,
2,
3
]
解释:重组数组时,jq后面是[],是没有点的、;也可以重组为对象:
[ck186943@shell.ceshiren.com ~]$ echo '{"a":1,"b":2,"c":3}' |jq '{"f":.a,"f2":.b}'
{
"f": 1,
"f2": 2
}
[ck186943@shell.ceshiren.com ~]$ echo '{"a":1,"b":2,"c":3}' |jq '{"f":.a,"f2":.b}' | grep f
"f": 1,
"f2": 2
也就可以和三剑客重组了
linux实战
[ck186943@shell.ceshiren.com ~]$ w | awk '{print $1}' | sed 1,2d |sort |uniq -c |wc -l
18
查看多少人登录环境
环境安装
1.GitBash
2.华为镜像站
https://mirrors.huaweicloud.com
3.阿里云
https://developer.aliyun.com/mirror/
python,推荐python版本3.7+
https://mirrors.huaweicloud.com/python/
推荐将python指向python3,软连接进行链接
ln 命令指向
4.python3文档
中文版文档:https://docs.python.org/zh-cn/3/tutorial/index.html
5.PYPI,官方包开源组件
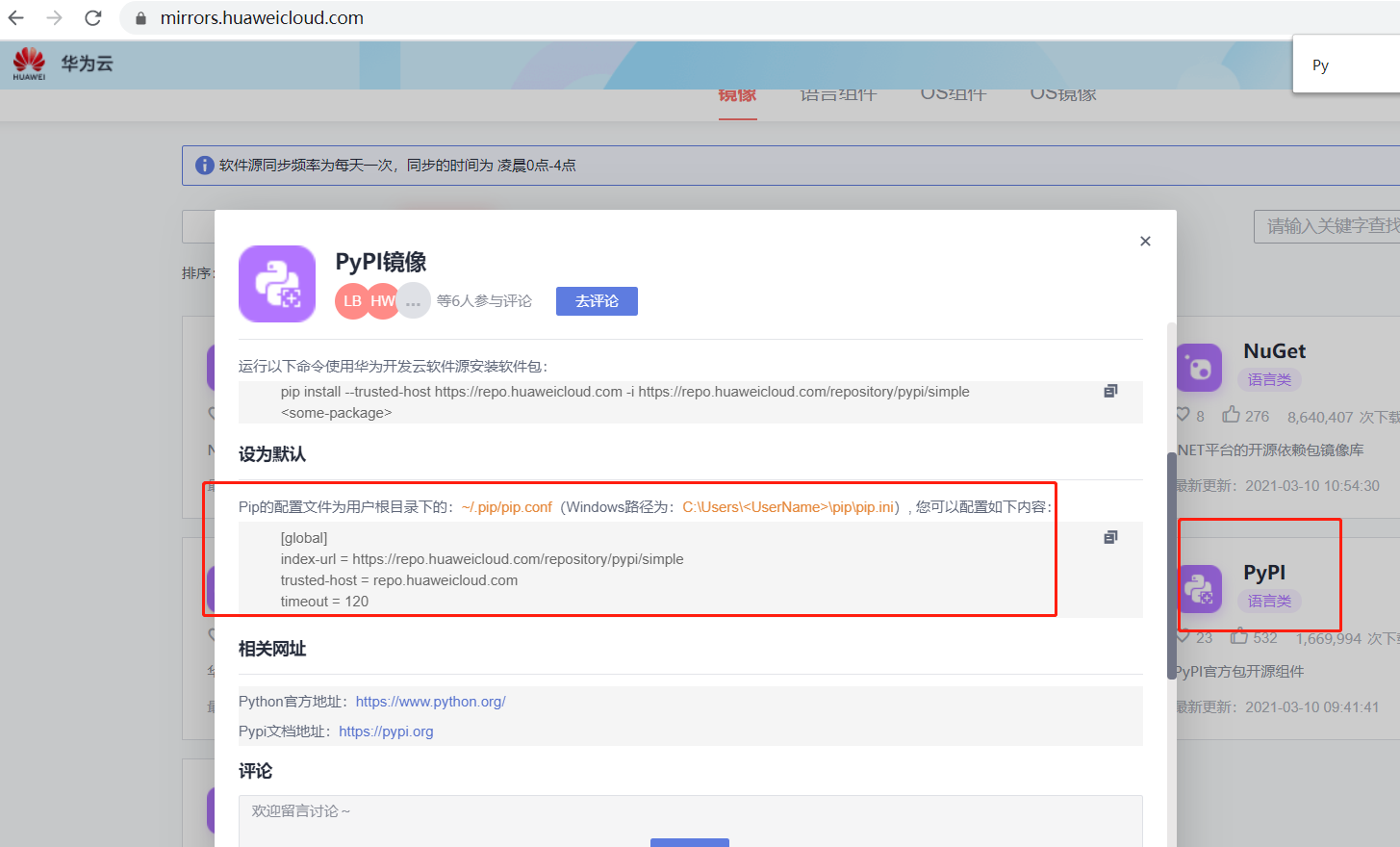
需要进行配置
才能随心所欲下载
环境变量
怎么进行随意切换python版本?
[ck186943@shell.ceshiren.com ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/ck186943/.local/bin:/home/ck186943/bin
解释:PATH变量决定优先使用哪个Python,而windos直接修改环境变量的前后位置就好
需要软连接进行指定到前一个目录下的位置。python3和python2下载时,放入不同的目录下;
[ck186943@shell.ceshiren.com ~]$ which python
/usr/local/bin/python
[ck186943@shell.ceshiren.com ~]$ python -V
Python 3.6.8
[ck186943@shell.ceshiren.com ~]$ cd /usr/local/bin
[ck186943@shell.ceshiren.com bin]$ ll
total 0
lrwxrwxrwx 1 root root 16 Oct 9 20:53 python -> /usr/bin/python3
解释:/usr/local/bin,是第一个目录,软连接了第二个目录下的python3,如果第一个目录没有python2的话,那么查看python版本的时候,肯定是优先显示python3版本。
当软连接执行完成后,需要更新下环境变量: . ~/.bash_profile
ln -s /usr/bin/python /usr/local/bin/python
[ck186943@shell.ceshiren.com ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/ck186943/.local/bin:/home/ck186943/bin
[ck186943@shell.ceshiren.com ~]$ which python
/usr/local/bin/python
[ck186943@shell.ceshiren.com ~]$ /usr/bin/python
Python 2.7.5 (default, Nov 6 2016, 00:28:07)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-11)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
> > > quit()
> > > [ck186943@shell.ceshiren.com ~]$ ln -s /usr/bin/python /usr/local/bin/python
解释:当尝试进行将python2软练到第一个目录时,提示了权限的问题,但是就是这个思路,进行更换python的运行环境。
java和python区别
1.指定类型,类型的约束,维护很好;python返回类型是什么,很难知道是什么;比如java,编译的时候有错误就会提示错误。但是python没有这个。所以在严谨的语言里面,大家都不会使用python
2.性能,场景来区分,都是C语言写的,python多了一些解释,还有一些库,没有强类型约束。历史原因。
java都是很严谨的工程要求;主要还是使用生态不一样!
php,go写web
java的jdk
大型企业,一般使用open
https://www.oracle.com/java/technologies/javase-downloads.html
个人使用搜索时,都是oracle的jdk。
阿里的只能运行在linux上面
使用Maven
前端很重要的一个引擎
NodeJS安装
准确的说不是一门语言,而是运行时,前后端都可以使用。
go,后台引擎的使用go;后台开发使用java
版本坑,工具有的只能低版本使用
对应的包管理工具:npm,进行安装appuim
[ck186943@shell.ceshiren.com ~]$ node
> console.log('hello from hogwrts')
> hello from hogwrts
> undefined
启动检查
阿里云安装appuim更方便一点,使用cnpm:淘宝的国内镜像版客户端
Android SDK
也是大坑
模拟器安装,
https://developer.android.com/studio#cmdline-tools (目前打不开。。)
代理设置
http_proxy=http://127.0.0.1:3128 https_proxy=http://127.0.0.1:3128 curl https://www.google.com
解释:当直接访问,google时,可能肯本访问不到,这时候可以代理的方式进行访问,就会速度快很多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号