solr学习篇(二) solr 分词器篇
关于solr7.4搭建与配置可以参考 solr7.4 安装配置篇 在这里我们探讨一下分词的配置
目录
1.关于分词
1.分词是指将一个中文词语拆成若干个词,提供搜索引擎进行查找,比如说:北京大学 是一个词那么进行拆分可以得到:北京与大学,甚至北京大学整个词也是一个语义
2.市面上常见的分词工具有 IKAnalyzer MMSeg4j Paoding等,这几个分词器各有优劣,大家可以自行研究
在这篇文章,我先演示IKAnalyzer分词器 下载:IKAnalyzer
2.拷贝相关Jar包与配置
下载解压后 把这两个jar文件复制到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib中
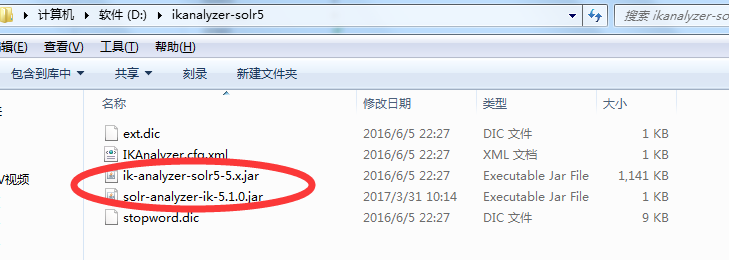
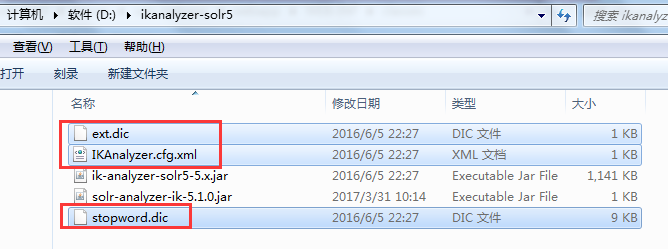
然后在solr-7.4.0\server\solr-webapp\webapp\WEB-INF\目录下新建一个classes目录,把下面三个文件复制进去
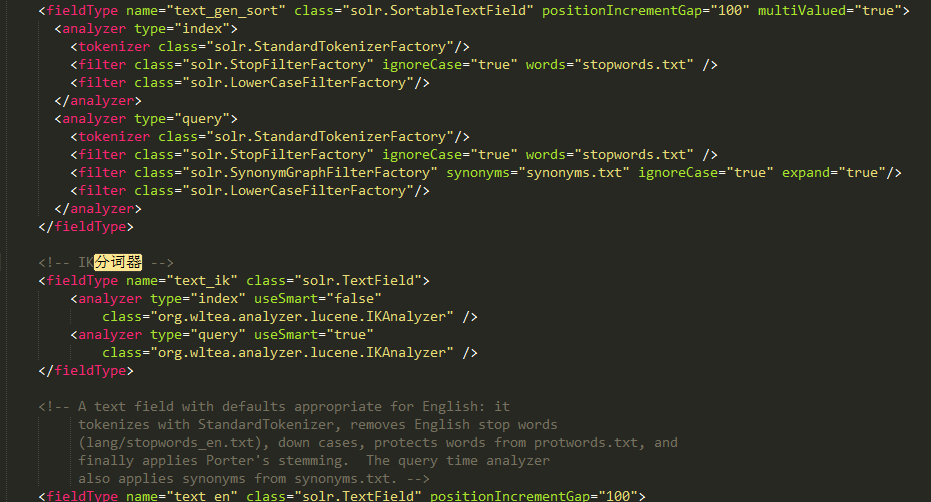
进入之前创建的core 在solr-7.4.0\server\solr\newCore\conf下打开managed-schema.xml 添加如下代码:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer" /> <analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer" /> </fieldType>
在这里我们发现并没有schema.xml。这是因为Solr版本中(Solr5之前),在创建core的时候,Solr会自动创建好schema.xml,但是在之后的版本中,新加入了动态更新schema功能,这个默认的schema.xml确找不到了,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema,并且没有后缀。乍一看,以为是打不开的文件,当然没有什么能难倒程序员的,用Sublime Text 3打开,发现了熟悉的文字,这不就是之前的schema.xml文件吗。

3.验证成功
打开服务,打开你所创建的core
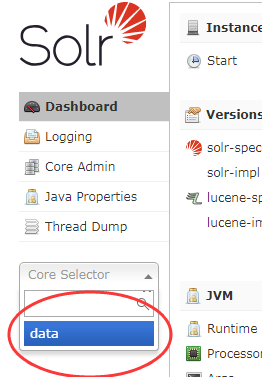
选择Analysis 输入要搜索的中文 选择FieldType为text_ik 可以发现分词成功
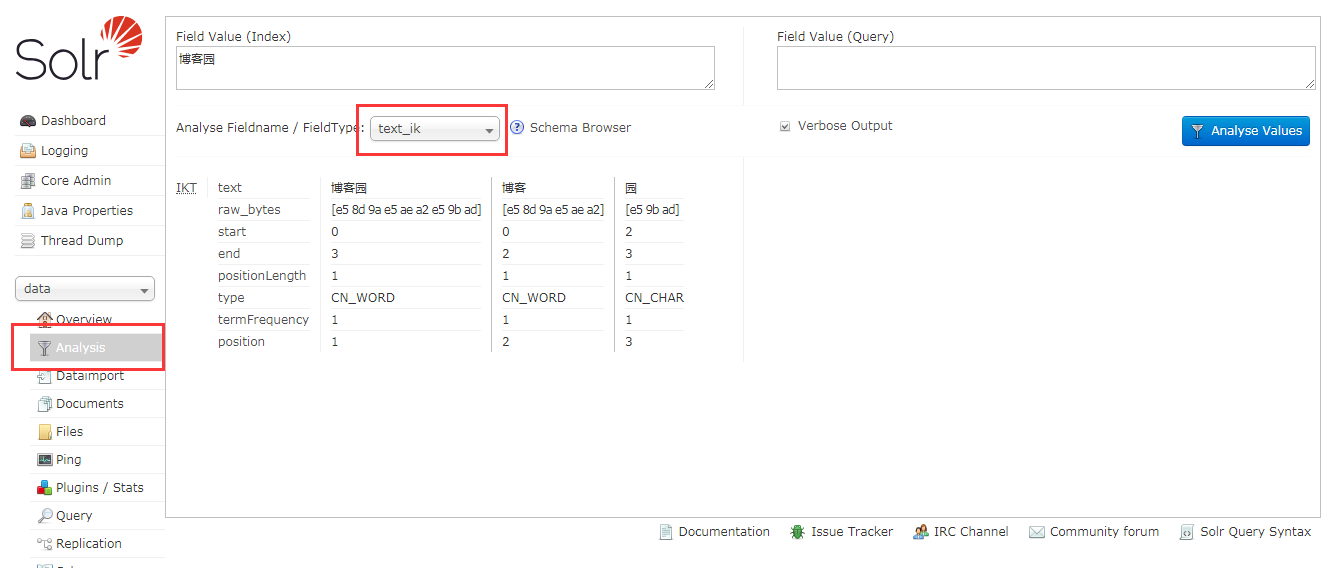
注意filedType一定选择我们配置的分词类型text_ik
----------------------------------------------------------------分割线----------------------------------------------------
有朋友私信说配置好了并没有ik
这是因为本文中我用的 上一篇中的第一种方式创建的code,这种方式连接数据库不是特别好,应该使用第二种命令创建。
但是命令创建后的conf目录是需要去 solr{home}\example\example-DIH\solr\db下的文件进行复制。 详情请参考下一篇。
- 学习本是一个不断抄袭、模仿、练习、创新的过程。
- 虽然,园中已有本人无法超越的同主题博文,为什么还是要写。
- 对于自己,博文只是总结。在总结的过程发现问题,解决问题。
- 对于他人,在此过程如果还能附带帮助他人,那就再好不过了。
- 由于博主能力有限,文中可能存在描述不正确,欢迎指正、补充!
- 感谢您的阅读。如果文章对您有用,那么请轻轻点个赞,以资鼓励。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号