
单词统计
做以下题目要求
输出某个英文文本文件中 26 字母出现的频率,显示字母出现的百分比,精确到小数点后面两位。
那么,我们要怎么解决这个问题呢?
一、问题分析
首先我们拿到这个问题之后,我们首先是要将文本的数据读出,然后将文本中的内容进行分割,注意,现在是按照字母进行分割的,然后,将相同的字母进行统计记录其数量,并且记录其所有字母的数量。求出百分比,这样问题就解决了。
二、代码实现
按照我们的思路,我们要先把文本中的内容读出,读出之后,要将他存在数组或者map中,这里我们使用map进行存储,因为map带有分割的更简便的机制。
1 try { 2 // IO操作读取文件内容 3 FileReader fr = new FileReader("piao.txt"); 4 BufferedReader br = new BufferedReader(fr); 5 6 HashMap<String, Integer> map = new HashMap<String, Integer>(); 7 8 String string = null; 9 Integer count = 0;// 每个字母的次数 10 Integer total = 0;// 总共多少个字母 11 12 while ((string = br.readLine()) != null) { 13 char[] ch = string.toCharArray(); 14 total = total + ch.length; 15 for (int i = 0; i < ch.length; i++) { 16 if ((ch[i] <= 'Z' && ch[i] >= 'A') || (ch[i] <= 'z' && ch[i] >= 'a')) { 17 ch[i] = Character.toLowerCase(ch[i]); 18 count = map.get(ch[i] + ""); 19 if (count == null) { 20 count = 1; 21 } else { 22 count++; 23 } 24 map.put(ch[i] + "", count); 25 } 26 27 } 28 }
在这里将文本内容进行存储的时候,我们是按照行进行存储的。当读取到的内容在字母范围之内的时候,我们就将存储到map中,然后,每当读取到的内容产生重复的时候,就在单词对应后面的count处的数量加1。
然后遍历map中的值,通过键值进行输出,在输出的时候直接求出所占百分比。要注意问题的要求,保留两位小数。
1 for (String str : map.keySet()) { 2 double sum = 0; 3 sum = map.get(str) * 100.0 / total; 4 BigDecimal a = new BigDecimal(sum); 5 a = a.setScale(2, BigDecimal.ROUND_HALF_UP); 6 System.out.println(str + "出现的次数为:" + map.get(str) + " "); 7 System.out.println("百分比为:" + a + "%"); 8 }
这样,一个问题就解决了。
三、结果截图
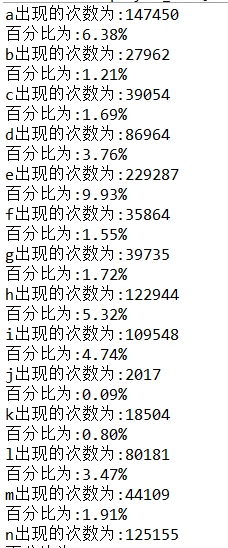
接下来,我们将这个问题在升级一下,我们可以读取任意文件,并输出单个文件中的前 N 个最常出现的英语单词。
一、问题分析
具体的思路和上一部分的问题解决方案不是相差太多,关键是我们怎么去将单词一个一个的分割出来。
二、代码分析
这里,我们仍然使用map进行分割,要想得到单词,首先我们可以用非单词符号进行分割,然后将单词储存在map中。当有这个单词的时候,就在与这个单词关联的数量后面加1.
scan = new Scanner(System.in); System.out.println("请指定文件路径:"); String f = scan.nextLine(); File file = new File(f); if (!file.exists()) { System.out.println("文件不存在"); return; } scanner = new Scanner(file); // 单词和数量映射表 HashMap<String, Integer> hashMap = new HashMap<String, Integer>(); while (scanner.hasNextLine()) { String line = scanner.nextLine(); // \w+ : 匹配所有的单词 // \W+ : 匹配所有非单词 String[] lineWords = line.split("\\W+");// 用非单词符来做分割,分割出来的就是一个个单词 Set<String> wordSet = hashMap.keySet(); for (int i = 0; i < lineWords.length; i++) { // 如果已经有这个单词了, if (wordSet.contains(lineWords[i])) { Integer count = hashMap.get(lineWords[i]); count++; hashMap.put(lineWords[i], count); } else { hashMap.put(lineWords[i], 1); } } }
然后进行排序,最后将单词排序进行输出。
三、实验截图

总结:本周测试代码全程使用map进行操作,加深了对map的使用,尤其对map中的各部分的分割更加的熟悉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号