Spring源码——@Component,@Service是如何被解析?
引言
在Spring中,Component、Service是在工作中经常被使用到的注解,为了加深对Spring运行机制的理解,今天我们一起来看一下Spring中对Component等注解的处理方式
Component注解源码
在Component注解的源码中(已去掉多余无关内容)
/**
* Indicates that an annotated class is a "component".
* Such classes are considered as candidates for auto-detection
* when using annotation-based configuration and classpath scanning.
*当使用基于注释的配置和类路径扫描时,此类将被视为自动检测的候选。
*
* <p>Other class-level annotations may be considered as identifying
* a component as well, typically a special kind of component:
* e.g. the {@link Repository @Repository} annotation or AspectJ's
* 其他类级别的注释也可以被视为标识一个组件,通常是一种特殊的组件,,如Repository AspectJ注解
* {@link org.aspectj.lang.annotation.Aspect @Aspect} annotation.
*
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Indexed
public @interface Component {
/**
* The value may indicate a suggestion for a logical component name,
* to be turned into a Spring bean in case of an autodetected component.
* @return the suggested component name, if any (or empty String otherwise)
* 该值表明bean组件名称,以在自动检测到组件的情况下将其转换为Spring bean
*/
String value() default "";
}
上面第一段注释中其实已经告诉我们,Component 注解它是作为在基本注解方式配置Spring定义的时候,被其标注的类作为自动检测的候选对象
通俗点讲就是,当使用Component-scan时,如果指定的包里面包含了被Component注解标识的类,其会被作为Spring bean对象,自动注册到Spring容器中。
第二段注释告诉我们,其在作为元注解标注其它注解的时候,,而这个被Component标注了的注解,通常说明这个注解是被用来标注一些有结特殊用途的Bean对象,比如Controller、Service、AspectJ等注解
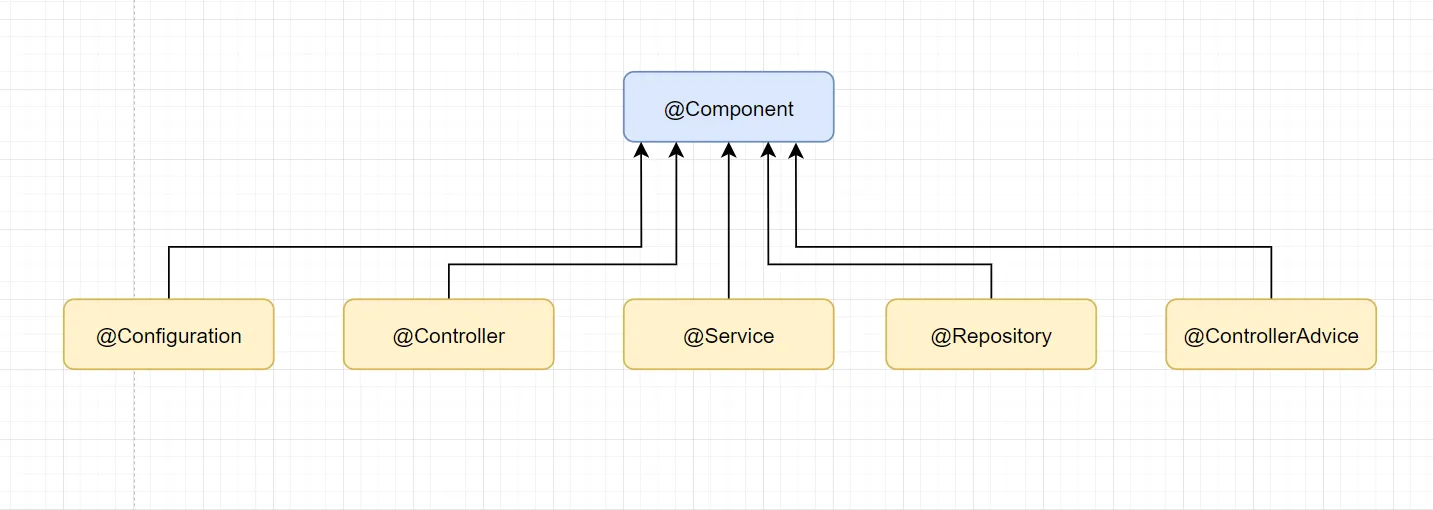
通过以上对源码的阅读,我们知道Component注解是在被Component-scan处理的时候,进行处理的
component-scan处理
在Spring的配置文件中,如果要使用Component注解,并将其标注了的类作为bean对象注册到Spring容器中,我们通常会配置一个指定的扫描路径,如下
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
<!--要使用 context 标签,必须要指定其命名空间,以便Spring自动找到对应的Handler -->
http://www.springframework.org/schema/context
<!-- 指定Context标签的规范约束,方便编辑器进行自动提示 -->
https://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.xx.xx"/>
</beans>
Spring在处理的时候,会通过前缀context,找到与其相对应的NamespaceHandlerSupport
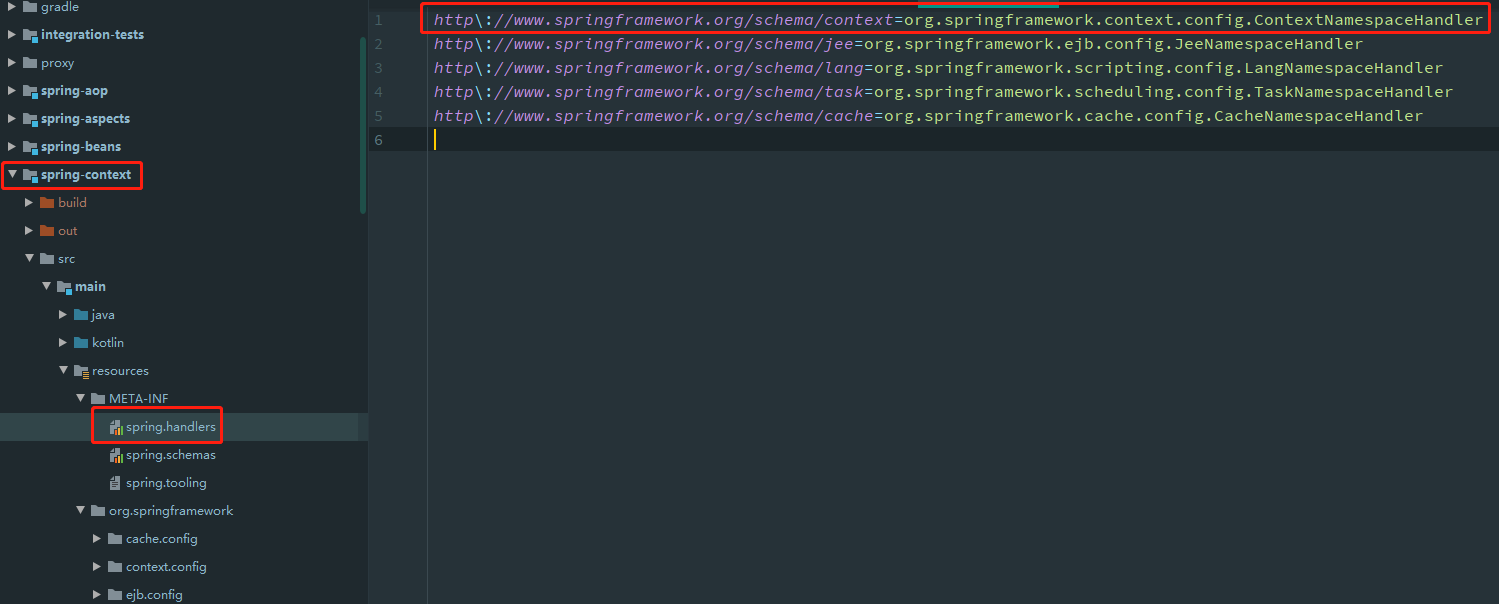
ContextNamespaceHandler 处理
org.springframework.context.config.ContextNamespaceHandler源码如下
public class ContextNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
registerBeanDefinitionParser("property-placeholder", new PropertyPlaceholderBeanDefinitionParser());
registerBeanDefinitionParser("property-override", new PropertyOverrideBeanDefinitionParser());
registerBeanDefinitionParser("annotation-config", new AnnotationConfigBeanDefinitionParser());
registerBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());
registerBeanDefinitionParser("load-time-weaver", new LoadTimeWeaverBeanDefinitionParser());
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
registerBeanDefinitionParser("mbean-export", new MBeanExportBeanDefinitionParser());
registerBeanDefinitionParser("mbean-server", new MBeanServerBeanDefinitionParser());
}
}
对于每一个context开头的标签,都加入了对应的解析器,context:component-scan 对应着 ComponentScanBeanDefinitionParser解析器
ComponentScanBeanDefinitionParser 解析
ComponentScanBeanDefinitionParser里面最核心的parse方法,该方法是从其父类BeanDefinitionParser 继承而来的方法
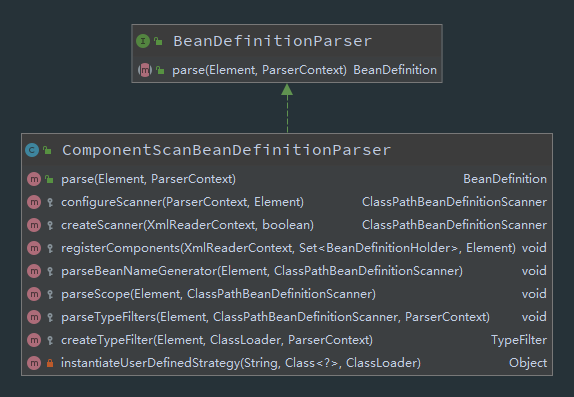
该方法源码如下
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 获取<context:component-scan>节点的base-package属性值
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
// 解析占位符
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
// 解析base-package(允许通过,;\t\n中的任一符号填写多个)
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
// 构建和配置ClassPathBeanDefinitionScanner
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
// 使用scanner在执行的basePackages包中执行扫描,返回已注册的bean定义
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
// 组件注册(包括注册一些内部的注解后置处理器,触发注册事件)
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
通过以上,我们看到,最终是通过ClassPathBeanDefinitionScanner的doScan方法返回的BeanDefinitionHolder集合,然后注册到Spring容器中。
注:BeanDefinitionHolder是beanName与其对应BeanDefinition的包装类
细节
registerComponents(parserContext.getReaderContext(), beanDefinitions, element)
这个方法会使用AnnotationConfigUtils工具类向Bean容器注册几个常用的内部Bean
ConfigurationClassPostProcessor 属于BFPP,用来处理Configuration import importResources等注解
AutowiredAnnotationBeanPostProcessor 属于BPP,用来处理Autowired依赖注入
CommonAnnotationBeanPostProcessor 属于BPP,用来处理@Resouces @PostConstruct @PreDestroy等注解
ClassPathBeanDefinitionScanner.doScan
doScan方法源码如下
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 遍历basePackages
for (String basePackage : basePackages) {
// 扫描basePackage,将符合要求的bean定义全部找出来
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 遍历所有候选的bean定义
for (BeanDefinition candidate : candidates) {
// 解析@Scope注解,包括scopeName和proxyMode
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 使用beanName生成器来生成beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
// 处理beanDefinition对象,例如,此bean是否可以自动装配到其他bean中
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 处理定义在目标类上的通用注解,包括@Lazy,@Primary,@DependsOn,@Role,@Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查beanName是否已经注册过,如果注册过,检查是否兼容
if (checkCandidate(beanName, candidate)) {
// 将当前遍历bean的bean定义和beanName封装成BeanDefinitionHolder
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 根据proxyMode的值,选择是否创建作用域代理
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册beanDefinition
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
findCandidateComponents(basePackage),这个方法通过basePackages,和一个默认的TypeFilter(被Component注解标注了的作为默认的IncludeFilter对象)就可以获取到被Component标注了的类
处理的时候,由于是获取的元注解,所以只要是Component注解的派生注解,也能被获取到。(包括Configuration注解,这个注解非常重要,重要。请参考----)
到此,我们就清楚了@Component的处理逻辑
所以,如果想要自己扩展一个能够标注一个特殊bean对象的注解时,这个注解必须被Component作为元注解标注
想一想
刚刚上面我们讲了Spring配置文件中配置 Component-scan的方式处理@Component注解,那么大家想一下在纯注解配置的情况下,是如何处理的呢?
在XML配置文件中
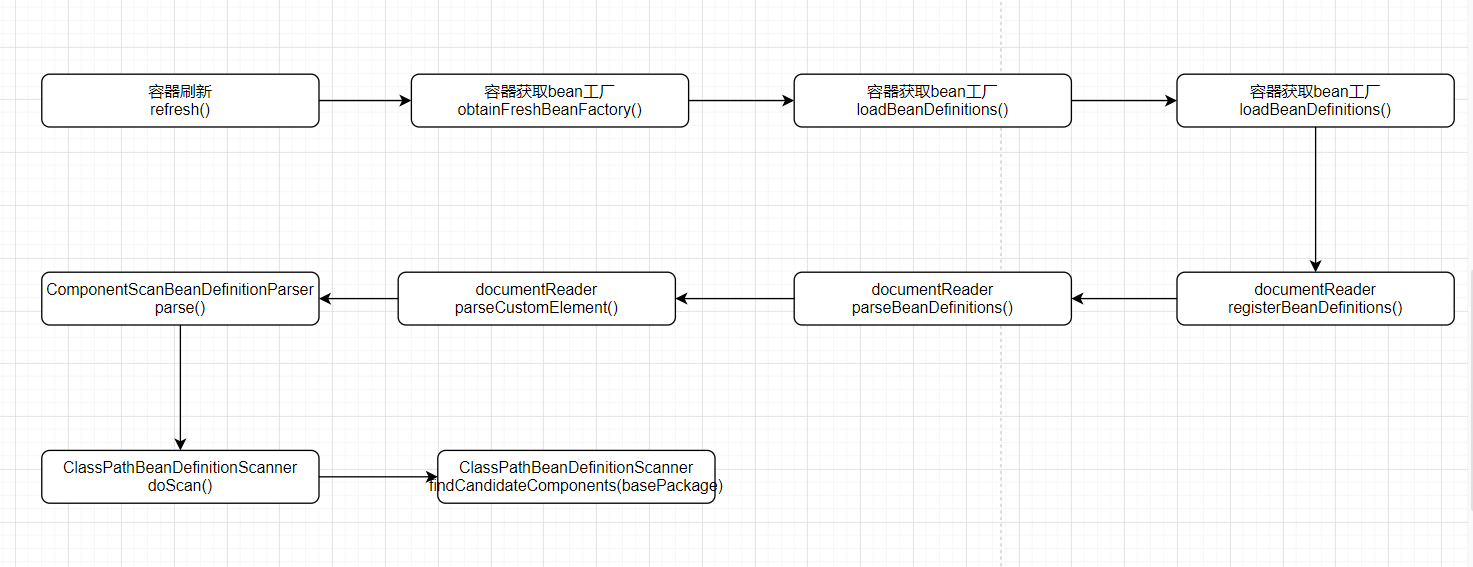
纯注解的处理方式
在使用注解的时候,初始化AnnotatedBeanDefinitionReader时,会向容器中注册一个CongifurationClassPostProcessor这么一个BDRPP。
处理@ComponentScan注解就是在CongifurationClassPostProcessor的postProcessBeanDefinitionRegistry的执行过程中处理的,它会将
此时容器中beanDefinitionsMap中的bean定义全部取出来,检查这些bean定义对象中是否有@Configuration注解,如果有,将使用ConfigurationClassParser进行parse解析,解析的时候,就会解析其类上面的ComponentScan、Import、ImportResource等进行处理,如果发现ComponentScans ComponentScan等注解调用ComponentScanAnnotationParser解析,再调用ClassPathBeanDefinitionScanner进行处理,然后就跟XML文件处理方式一样了
扩展
自定义注解请参考————Spring扩展———自定义bean组件注解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号