Python第十章-模块和包
模块和包
我们以前的代码都是写在一个文件中, 而且代码也比较短.
- 假设我们现在要写一个大的系统, 不可能把代码只写到一个文件中, 迫切想把代码写到不同的文件中, 并且能够在一个文件使用另一个文件中代码. 这个时候应该怎么做?
- 如果你有一个非常棒的函数, 想在多个程序中使用, 又不想 copy, 这个时候又应该怎么做?
为了解决上面的这些问题, python 提出了一个moudle的概念.
我们每定义一个.py文件, 其实就是定义了一个moudle.在一个moudel中定义的函数,类都可以导入(import)到另外一个模块中, 也可以导入到主模块(main moudle)中.
一个文件就是一个模块, 在一个模块内可以定义变量, 函数, 类等, 也可以有合法的 python 语句.
文件名就是模块名(不包括扩展名.py). 我们可以通过一个全局变量__name__来获取这个模块的名字, 当然获取到的是个字符串.
一、模块基本使用
1.1 定义模块
定义模块其实就是创建一个.py文件.
python之父建议的的模块命名:
- 公共模块: 所有的字母小写, 不同的单词之间用下划线
_连接 - 内部模块: 用下划线
_开头, 其余与公共模块一样.
定义一个计算斐波那契数列前 n 项的模块
第 1 步: 创建一个文件fibo.py, 相当于创建了一个模块fibo.
def fib(n):
#1,1,2,3,5,8,13,21,34...
a, b = 0, 1
for i in range(n):
print(b, end=" ")
a, b = b, a + b
#print()
第 2 部: 再创建一个模块demo, 作为我们程序的入口, 这样的模块其实就是main moudle. 在主模块内部使用我们第 1 步创建的模块.
import fibo # 导入需要的模块
print(__name__) # 当前模块直接执行, 所以当前模块就是主模块 输出__main__
# 模块名就成为了在 fibo 这个模块中定义的全局变量, 函数, 类的命名空间
print(fibo.__name__) # 输出模块名
# 调用模块内定义的函数
fibo.fib(20)

1.2 模块的细节
- **使用
import加载模块的位置. **
可以放置文件的任何位置, 但是建议放置文件的开始位置来加载模块. 而且一定要保证在使用模块前先加载模块 - 首次导入模块, 会创建一个以模块名命名的命名空间. 在这个模块中定义的全局变量, 函数, 类都处于这个命名空间下
- 在新创建的命名空间中, 执行模块内的代码. 如果有全局变量, 函数, 类啥的都会完成定义工作. 如果有输出, 你也会立即看到结果.
- 使用
模块名.成员的方式来使用模块内定义的成员:全局变量, 函数, 类 - 模块内定义的类的使用要注意也是
模块名.类名的方式来使用.比如模块a中定义了一个类Person, 则创建对象的方式:p = a.Person()
二、import语句进一步讲解
2.1 给导入的模块起别名
导入模块之后, 可能模块名比较长, 想换个短点的, 我们可以给导入的模块起个别名.
import hello_world as hw
hw.foo()
注意:
起别命名之后只会创建hw命名空间, 而不会再创建hello_world命名空间. 所以这样使用是错误的:hello_world.foo()
2.2 一次导入多个模块
前面我们已经了解到使用import可以导入一个模块.
我们也可以多次使用import来导入多个模块
import a
import b
import c
上面这种写法比较啰嗦, 可以使用一个import同时导入多个模块
import a, b, c
2.3 从模块导入具体的定义(from方式导入)
单独使用import是导入整个模块, 默认的所有定义都会导入, 而且会创建新的命名空间. 并没模块的代码也会执行.
如果我们仅仅是用到模块中某个函数或者类, 这个时候, 我们可以只导入我们想要的某个定义, 而不需要导入整个模块.
语法:
from 模块 import 具体的定义
from fibo import fib # 从模块 fibo 中只导入 fib
fib(20)
说明:
- 通过
from语句导入的时候, 并不会创建新的命名空间, 而是把导入的定义放在了当前命名空间中, 所以使用的时候不需要添加命名空间. - 这种写法是错误的:
fibo.fib(20), 因为根本就不存在fibo这个命名空间 - 可以一次导入多个定义:
from fibo import fib, a, b, c - 使用通配符导入一个模块中所有的定义:
from fibo import *
from导入的作用域问题
把一个函数从一个模块导入当前模块时, 并不会改变这个函数的作用域规则. 也就是说好函数的全局命名空间仍然是那个函数定义所在的命名空间.
a.py:
n = 30
def foo():
print("a模块: n的值" + str(n))
b.py:
from a import foo, n
n = 1000
foo()
print("当前模块: n 的值:" + str(n))
#print("当前模块:n的值:",n)
#print("当前模块:n的值:%d"%n)

原因分析:
foo函数中的n, 仍然是a模块中的n
为什么呢?
在 python 中任何数据都是变量, n仅仅是对象的一个引用(符号). 导入 n 到当前模块, 仅仅是在原来的对象上多了一个引用而已.
这个两个n由于命名空间不同, 所以不是同一个n. 修改一个变量的值, 其实是让这个变量指向了一个新的对象
导入成功from a import foo, n之后是这样的:
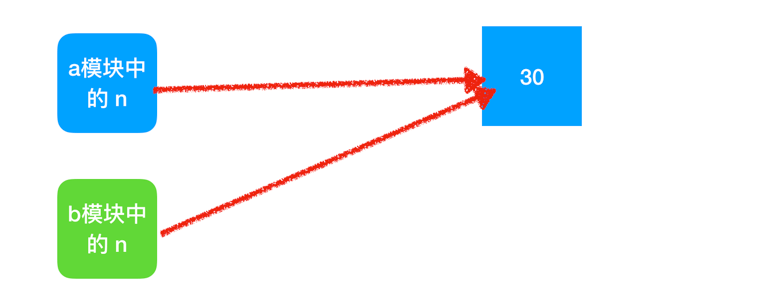
在 b 模块中修改 n 的值n = 1000 之后是这样的:
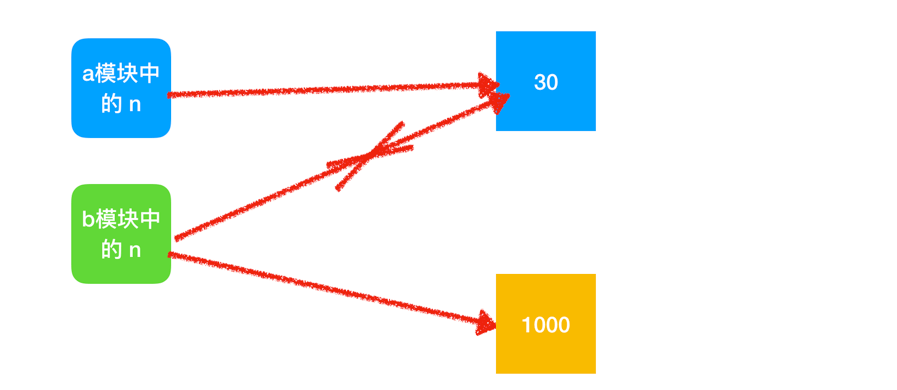
三、模块运行方式
对模块的运行方式做个总结.
到目前为止, 我们有两种方式去运行模块:
- 直接使用
python 模块名.py. 这种模块为主模块, 这样运行方式叫做以程序的方式运行. - 使用
import语句的方式来运行模块.
我们可以通过__name__属性的值来判断这个模块的运行方式.
if __name__ == "__main__":
# 是 程序的方式运行
pass
else:
# 否 以导入的方式运行
pass
四、模块搜索路径
当我们去加载一个模块的时候, python 会在指定的路径中搜索这个模块, 一旦搜索到则会立即导入. 如果搜索不到则会抛出异常.
出现下面这种情况一般是模块的路径不对导致的!

4.1 模块的默认搜索路径
python 搜索模块按照一定的顺序来搜索的:
- 当前目录
- 系统内置模块
- 安装的第三方模块
搜索路径存放在sys的path变量中.

4.2更改模块的搜索路径
两种更方式:
- 动态更改
- 持久更改
动态更改
sys.path是一个列表, 只需要在里面添加上你需要的路径即可.
sys.path.append("路径")
持久更改
设置环境变量PYTHONPATH, 在这个环境变量中设置你需要的路径即可. 只添加自己的路径即可, python 自己本身的搜索路径不受影响
五、包(package)
5.1 包概述
一个.py文件就是一个模块, 但是模块一多, 管理起来也是比较麻烦.
python 提供包是为了更好的对模块进行管理.
包可以看做是一组模块的集合, 把这组模块放在一个包的名称下.包这项技术可以解决不同的应用程序之间模块的命名冲突问题.
包包括两个必要条件:
- **一个文件夹. **
这个文件夹的名字其实就是包的名字.包的命名规则和公共文件的命名一致:全部字符小写, 不同的单词之间用空格隔开. - 在前面的文件夹下的一个
__init__.py的初始化文件.
这个文件可以为空, 也可以定义一些导入模块时候的初始化代码.
注意:
一个包中可以有自己的子包, 子包也可以再有子包... 每一个包都会有一个自己的__init__.py文件.
5.2 从包中导入模块
定义包是为了更好的管理模块, 有几种导入模块的方式!
假设有这样的一个包结构:
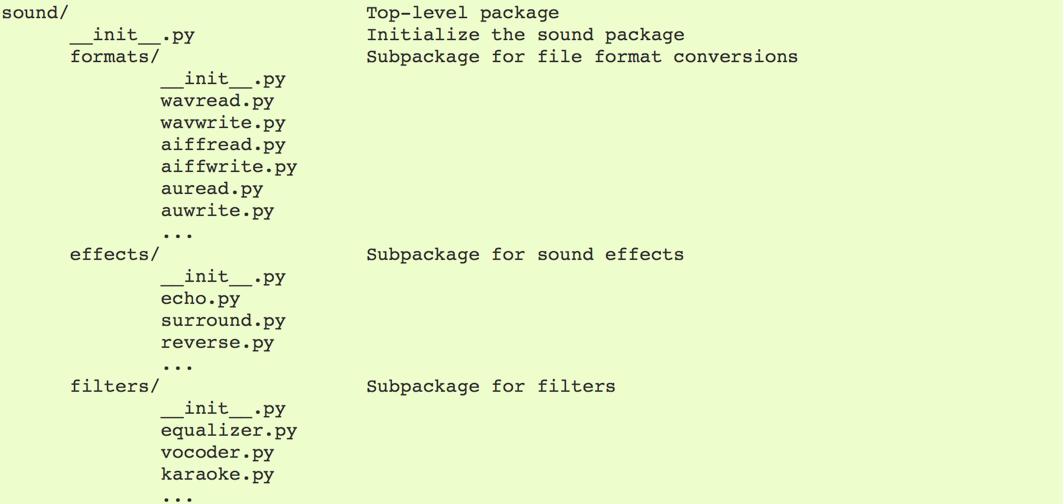
使用import导入模块
# 导入 echo 模块
import sound.effects.echo
# 使用的时候必须使用全名
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
使用from导入模块
# 导入 echo 模块
from sound.effects import echo
# 只需要包名即可
echo.echofilter(input, output, delay=0.7, atten=4)
使用from直接导入模块中的定义
# 从模块中导入定义
from sound.effects.echo import echofilter
# 直接调用导入的函数即可
echofilter(input, output, delay=0.7, atten=4)
注意:
当我们多个模块中都导入同一个模块的时候, 只有第一次导入的时候才会执行包的__init__()和模块中的代码.
可以这样理解: 当导入某个模块的时候, 会先查找某个模块是否已经导过, 如果已经导入过, 就直接使用不再重新导入.
使用*通配符导入
使用from 包 import *, 可以导入整个包下所有的模块.
但是由于各个操作系统的在对文件名的命名上的差异, 默认情况下这个语句一个包都导入不了.
我们可以在这个包的__init__.py定义一个列表, 这个列表中定义使用*的时候可以导入哪些包
__all__ = ["a", "b"] # 使用 * 的时候导入a 和 b 两个包
5.3使用相对导入
同一个包下的模块互相导入的时候, 也需要些完全限定名, 也就是把他们的上级的所有的包都要写上, 这是比较麻烦的.
所以, python 还是支持一种相对导入.
一个点.表示当前包, 两个点..表示表示父包
相对导包只能用在from中.
from . import my2
注意:
相对导包的原理是根据当前模块的__name__来计算的包的路径, 由于主模块的__name__值永远是__main__, 所以主模块中不能使用相对导包, 只能使用绝对路径去导包.
有了包之后, 模块都应该放入到相应的包下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号