
推荐系统(recommender systems):预测电影评分--构造推荐系统的一种方法:协同过滤(collaborative filtering )
协同过滤(collaborative filtering )能自行学习所要使用的特征
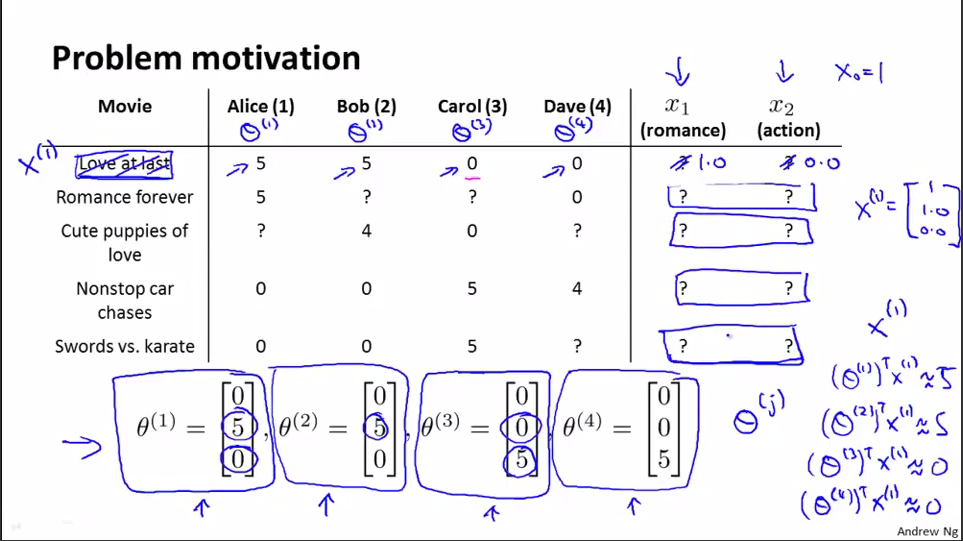
如我们有某一个数据集,我们并不知道特征的值是多少,我们有一些用户对电影的评分,但是我们并不知道每部电影的特征(即每部电影到底有多少浪漫成份,有多少动作成份)
假设我们通过采访用户得到每个用户的喜好,如上图中的Alice喜欢爱情电影,不喜欢动作电影,则我们将θ(1)设为[0,5,0],如此设置θ(2),θ(3),θ(4)的值,这样我们有了每个用户的θ的值以及他们对电影的打分,就可以推断出每部电影的x(特征)的值。
如对于上图中的第一部电影,Alice的打分是5,Bob的打分是5,Carol的打分是0,Dave的打分也是0,我们有每个用户的θ值,这样根据这些值来评估第一部电影的x1与x2的值,根据什么来评估呢,这是使θ(1)与x(1)的内积约等于5,使θ(2)与x(1)的内积约等于5,使θ(3)与x(1)的内积约等于0,使θ(4)与x(1)的内积约等于0,这样估算出x(1)的值。据此依次算出x(2)等的值。
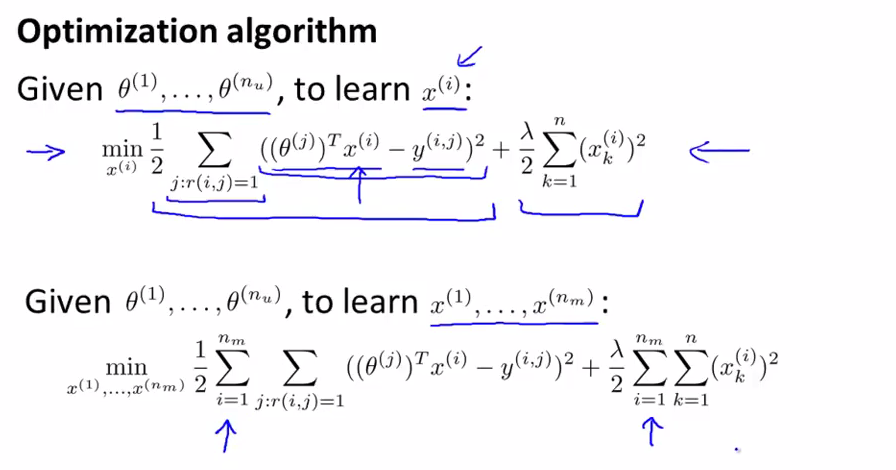
我们有nu个用户,知道这些用户的喜好,即知道用户的θ值,根据这些用户的值去估计第i部电影的特征值。
下面是对所有的电影的特征值的估计,有nm部电影。
协同过滤算法

我们将上面的两个算法结合起来,我们可以由知道x的值( 即每部电影的特征值)和每个用户对电影的打分,来推断出每个用户的喜好值(及θ的值)
也可以知道每个用户的喜好值(及θ的值)和每个用户对电影的打分来推荐出电影的特征值(即x的值)。
先有鸡还是先有蛋问题:根据θ的值可以估计x的值,根据x的值可以用来估计θ的值.
这样我们先猜测一个θ的值,然后根据这个θ的值估计出x的值,再根据x的值估计出θ的值,这样一直迭代下去,直至收敛。
这样我们就可以根据用户对电影的打分,反复进行上面的过程,来估计出θ与x的值。
总结
协同过滤算法:通过一大堆用户得到的数据,这些用户实际上在高效地进行协同合作,来得到每个人对电影的评分。只要用户对某几部电影进行了评分,每个用户就又都在帮助算法更好地学习出特征,这些特征可以被系统运用来为其它人做出更准确的电影预测。
协同是说每位用户都在为了大家的利益,学习出更好的特征

 浙公网安备 33010602011771号
浙公网安备 33010602011771号