题记01
题记
P1000 超级玛丽游戏
困难:阿哲,这么多行,用循环打岂不是累死,直接用cout输出不能输出多行;
解决1:强行使用22行cout分别输出每行的玛丽图案
解决2:使用了题解中的printf的多行输出形式(其实我觉得和上面也是差不多的QAQ)。
P5706 再分肥宅水
困难:啊这,保留三位小数是咋搞的,好像没学过!
尝试:使用其它语言中的(a*10^n +0.5)/10^n的语法然而并没有什么卵用。
解决:上CSDN查到了iomanip的库,里面内置了保留小数的函数
fix setprecision(小数位数)
然后就快乐的解决了!
我觉得不可能把所有的语法点都记住,遇到不会的就应该及时查阅资料,同时要做到遇见一个会一个
P5709 【深基2.习6】Apples Prologue
这题考验的就是细致程度了,首先存在除0的情况(小声:虽然这不符合常理),其次就是物理中常见的刹车陷阱了,即可能苹果在s分钟后早已经吃完,此时就需要分类讨论!
算法终究是数学的体现,严谨缜密的数学基础非常重要!
P2181 对角线
这题超棒!首先我发现答案是让我们输出
Cn4(组合数),也就是
$$
n(n-1)(n-2)*(n-3)/4!
$$
然后我就快乐的使用代码
ans=n*(n-1)*(n-2)*(n-3)/24;
然后快乐的WA啦!
其实我意识到了溢出的问题,不过我以为把ans设置为unsigned long long int 应该问题不大
事实是最后得了82分。
然后我就开始查阅题解了,这个时候不应该浪费时间在一无所知的地方。
浏览题解时我发现了两种方案。
#include<bits/stdc++.h>
using namespace std;
unsigned long long n,ans;
int main()
{
scanf("%lld",&n);
ans=n * (n-1) / 2 * (n-2) / 3 * (n-3) / 4;
printf("%lld\n",ans);
return 0;
}
#include <iostream>
using namespace std;
int n, ans[100], p[100];
void c(int);
int main()
{
cin >> n;
ans[0] = 1;//存储最高位
ans[1] = 1;
c(n); c(n - 1); c(n - 2); c(n - 3);
int k = 0;
for (int i = ans[0] - 1; i >= 1; i--) {//高精度除法
ans[i] += ans[i + 1] * 10;
k++;
p[k] = ans[i] / 24;
ans[i] %= 24;
}
int s = 1; //去除前导零,输出有效数字
while (p[s] == 0)s++;
for (int i = s; i <= k; i++)cout << p[i];
cout << endl;
return 0;
}
void c(int x) { //高精度乘法
int jw = 0;
for (int i = 1; i <= ans[0]; i++) {
ans[i] *= x;
ans[i] += jw;
jw = ans[i] / 10;
ans[i] %= 10;
}
while (jw > 0) {
ans[0]++;
ans[ans[0]] = jw % 10;
jw /= 10;
}
}
可以说第一种还是在我的理解范围之内的,对过大的数据进行缩小,分布除法,可以说很漂亮。
然后第二种是我第一次接触的算法——高精度算法。
这里先放上我查到的高精度模板
#include<iostream>
#include<sstream>
#include<algorithm>
#include<cstring>
#include<iomanip>
#include<vector>
#include<cmath>
#include<ctime>
#include<stack>
using namespace std;
struct Wint:vector<int>//用标准库vector做基类,完美解决位数问题,同时更易于实现
{
//将低精度转高精度的初始化,可以自动被编译器调用
//因此无需单独写高精度数和低精度数的运算函数,十分方便
Wint(int n=0)//默认初始化为0,但0的保存形式为空
{
push_back(n);
check();
}
Wint& check()//在各类运算中经常用到的进位小函数,不妨内置
{
while(!empty()&&!back())pop_back();//去除最高位可能存在的0
if(empty())return *this;
for(int i=1; i<size(); ++i)//处理进位
{
(*this)[i]+=(*this)[i-1]/10;
(*this)[i-1]%=10;
}
while(back()>=10)
{
push_back(back()/10);
(*this)[size()-2]%=10;
}
return *this;//为使用方便,将进位后的自身返回引用
}
};
//输入输出
istream& operator>>(istream &is,Wint &n)
{
string s;
is>>s;
n.clear();
for(int i=s.size()-1; i>=0; --i)n.push_back(s[i]-'0');
return is;
}
ostream& operator<<(ostream &os,const Wint &n)
{
if(n.empty())os<<0;
for(int i=n.size()-1; i>=0; --i)os<<n[i];
return os;
}
//比较,只需要写两个,其他的直接代入即可
//常量引用当参数,避免拷贝更高效
bool operator!=(const Wint &a,const Wint &b)
{
if(a.size()!=b.size())return 1;
for(int i=a.size()-1; i>=0; --i)
if(a[i]!=b[i])return 1;
return 0;
}
bool operator==(const Wint &a,const Wint &b)
{
return !(a!=b);
}
bool operator<(const Wint &a,const Wint &b)
{
if(a.size()!=b.size())return a.size()<b.size();
for(int i=a.size()-1; i>=0; --i)
if(a[i]!=b[i])return a[i]<b[i];
return 0;
}
bool operator>(const Wint &a,const Wint &b)
{
return b<a;
}
bool operator<=(const Wint &a,const Wint &b)
{
return !(a>b);
}
bool operator>=(const Wint &a,const Wint &b)
{
return !(a<b);
}
//加法,先实现+=,这样更简洁高效
Wint& operator+=(Wint &a,const Wint &b)
{
if(a.size()<b.size())a.resize(b.size());
for(int i=0; i!=b.size(); ++i)a[i]+=b[i];
return a.check();
}
Wint operator+(Wint a,const Wint &b)
{
return a+=b;
}
//减法,返回差的绝对值,由于后面有交换,故参数不用引用
Wint& operator-=(Wint &a,Wint b)
{
if(a<b)swap(a,b);
for(int i=0; i!=b.size(); a[i]-=b[i],++i)
if(a[i]<b[i])//需要借位
{
int j=i+1;
while(!a[j])++j;
while(j>i)
{
--a[j];
a[--j]+=10;
}
}
return a.check();
}
Wint operator-(Wint a,const Wint &b)
{
return a-=b;
}
//乘法不能先实现*=,原因自己想
Wint operator*(const Wint &a,const Wint &b)
{
Wint n;
n.assign(a.size()+b.size()-1,0);
for(int i=0; i!=a.size(); ++i)
for(int j=0; j!=b.size(); ++j)
n[i+j]+=a[i]*b[j];
return n.check();
}
Wint& operator*=(Wint &a,const Wint &b)
{
return a=a*b;
}
//除法和取模先实现一个带余除法函数
Wint divmod(Wint &a,const Wint &b)
{
Wint ans;
for(int t=a.size()-b.size(); a>=b; --t)
{
Wint d;
d.assign(t+1,0);
d.back()=1;
Wint c=b*d;
while(a>=c)
{
a-=c;
ans+=d;
}
}
return ans;
}
Wint operator/(Wint a,const Wint &b)
{
return divmod(a,b);
}
Wint& operator/=(Wint &a,const Wint &b)
{
return a=a/b;
}
Wint& operator%=(Wint &a,const Wint &b)
{
divmod(a,b);
return a;
}
Wint operator%(Wint a,const Wint &b)
{
return a%=b;
}
//顺手实现一个快速幂,可以看到和普通快速幂几乎无异
Wint pow(const Wint &n,const Wint &k)
{
if(k.empty())return 1;
if(k==2)return n*n;
if(k.back()%2)return n*pow(n,k-1);
return pow(pow(n,k/2),2);
}
int main()
{
}
其实高精度就和列竖式差不多(题解的批注是我的理解,当然也问了陈学长大概的思路6666)
A. XORwice
time limit per test
1 second
memory limit per test
256 megabytes
input
standard input
output
standard output
In order to celebrate Twice's 5th anniversary, Tzuyu and Sana decided to play a game.
Tzuyu gave Sana two integers aa and bb and a really important quest.
In order to complete the quest, Sana has to output the smallest possible value of (a⊕xa⊕x) + (b⊕xb⊕x) for any given xx, where ⊕⊕ denotes the bitwise XOR operation.
Input
Each test contains multiple test cases. The first line contains the number of test cases tt (1≤t≤1041≤t≤104). Description of the test cases follows.
The only line of each test case contains two integers aa and bb (1≤a,b≤1091≤a,b≤109).
Output
For each testcase, output the smallest possible value of the given expression.
Example
input
Copy
6
6 12
4 9
59 832
28 14
4925 2912
1 1
output
Copy
10
13
891
18
6237
0
Note
For the first test case Sana can choose x=4x=4 and the value will be (6⊕46⊕4) + (12⊕412⊕4) = 2+82+8 = 1010. It can be shown that this is the smallest possible value.
这是我第一次打codeforces div2的比赛,紧张。。
这题的意思就是给定一组(a,b),使得他们按位异或之和 a xor x +b xor x最小。
面对这题,我是这么做的:
#include <bits/stdc++.h>
using namespace std;
int main()
{
int num;
int a,b,pai[10000],ans[100];
cin>>num;
for (int i = 0; i < num; i++)
{
cin>>a>>b;
for (int j = 0; j < (a+b)*2; j++)
{
pai[j]=((a^j)+(b^j));
}
sort(pai,pai+(a+b));
ans[i]=pai[0];
}
for (int i = 0; i < num; i++)
{
cout<<ans[i]<<endl;
}
system("pause");
return 0;
}
首先,显然这个是会出现超时的结果的,具体为什么,我最近也在补习,计算机一秒钟大约能跑
$$
10^8
$$
次循环,而这题要求的复杂度显然已经超过了O(10^8),所以我们尽量要用更简洁,计算量更小的算法来解决这个问题。
我的问题就是直接根据题目进行直译,没有任何优化或者转化,这题让我再次充分认识到,转化是多么重要的思想!!!
于是乎我请教了学长,很快我便明白了,原来 min(a xor x +b xor x)就是a xor b!
按位异或时,二进制相同出0,不同出1,所以在算a xor x +b xor x时,若a,b二进制末位不同,则无论x为多少,该位必出1!
若a xor x +b xor x二进制末尾相同,那么只要使得x与他们相同,就能在该位输出0,观察得到最小的表达式其实就是
a xor b
通过一个小小的转化,就能使得成千上万上忆趟循环被生了下来!
还有就是万能头文件只能在如下编译器跑,否则编译错误。。。。
GNU G++11 5.1.OGNU G++14 6.4.0GNU G++17 7.3.0
用2017的我哭了。。。
今天不怕死地去打了div3
B. Yet Another Bookshelf
time limit per test
1 second
memory limit per test
256 megabytes
input
standard input
output
standard output
There is a bookshelf which can fit nn books. The ii-th position of bookshelf is ai=1ai=1 if there is a book on this position and ai=0ai=0 otherwise. It is guaranteed that there is at least one book on the bookshelf.
In one move, you can choose some contiguous segment [l;r][l;r] consisting of books (i.e. for each ii from ll to rr the condition ai=1ai=1 holds) and:
- Shift it to the right by 11: move the book at index ii to i+1i+1 for all l≤i≤rl≤i≤r. This move can be done only if r+1≤nr+1≤n and there is no book at the position r+1r+1.
- Shift it to the left by 11: move the book at index ii to i−1i−1 for all l≤i≤rl≤i≤r. This move can be done only if l−1≥1l−1≥1 and there is no book at the position l−1l−1.
Your task is to find the minimum number of moves required to collect all the books on the shelf as a contiguous (consecutive) segment (i.e. the segment without any gaps).
For example, for a=[0,0,1,0,1]a=[0,0,1,0,1] there is a gap between books (a4=0a4=0 when a3=1a3=1 and a5=1a5=1), for a=[1,1,0]a=[1,1,0] there are no gaps between books and for a=[0,0,0]a=[0,0,0] there are also no gaps between books.
You have to answer tt independent test cases.
Input
The first line of the input contains one integer tt (1≤t≤2001≤t≤200) — the number of test cases. Then tt test cases follow.
The first line of the test case contains one integer nn (1≤n≤501≤n≤50) — the number of places on a bookshelf. The second line of the test case contains nn integers a1,a2,…,ana1,a2,…,an (0≤ai≤10≤ai≤1), where aiai is 11 if there is a book at this position and 00 otherwise. It is guaranteed that there is at least one book on the bookshelf.
Output
For each test case, print one integer: the minimum number of moves required to collect all the books on the shelf as a contiguous (consecutive) segment (i.e. the segment without gaps).
Example
input
Copy
5
7
0 0 1 0 1 0 1
3
1 0 0
5
1 1 0 0 1
6
1 0 0 0 0 1
5
1 1 0 1 1
output
Copy
2
0
2
4
1
Note
In the first test case of the example, you can shift the segment [3;3][3;3] to the right and the segment [4;5][4;5] to the right. After all moves, the books form the contiguous segment [5;7][5;7]. So the answer is 22.
In the second test case of the example, you have nothing to do, all the books on the bookshelf form the contiguous segment already.
In the third test case of the example, you can shift the segment [5;5][5;5] to the left and then the segment [4;4][4;4] to the left again. After all moves, the books form the contiguous segment [1;3][1;3]. So the answer is 22.
In the fourth test case of the example, you can shift the segment [1;1][1;1] to the right, the segment [2;2][2;2] to the right, the segment [6;6][6;6] to the left and then the segment [5;5][5;5] to the left. After all moves, the books form the contiguous segment [3;4][3;4]. So the answer is 44.
In the fifth test case of the example, you can shift the segment [1;2][1;2] to the right. After all moves, the books form the contiguous segment [2;5][2;5]. So the answer is 11.
通过分析容易知道中间0的个数即为最小移动次数。
#include <bits/stdc++.h>
using namespace std;
int main()
{
int t,ans[50],s[50],len,num=0;
bool flag=false;
cin>>t;
for ( int i = 0; i < t; i++)
{
cin>>len;
for (int j = 0; j <len ; j++)
{
cin>>s[j];
}
int j=1;
while (j<=len)
{
if (s[j]==1)
{
if (s[j-1]==0&&flag==true)
{
flag=false;
num++;
}
}
if (s[j]==0)
{
if(s[j-1]==0&&flag)
{
num++;
}
if(s[j-1]==1)
{num++,flag=true;}
}
j++;
}
ans[i]=num;
num=0;
}
for (int i = 0; i < t; i++)
{
cout<<ans[i]<<endl;
}
system("pause");
return 0;
}
很凌乱,而且输出也是错的,但是我至今不知道为什么。。
下面是学长的:
#include <bits/stdc++.h>
using namespace std;
int a[100];
int main() {
ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
int t;
cin >> t;
while (t--) {
int n, p, cnt = 0;
bool f = 0;
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i];
for (int i = 1; i <= n; i++)
if (a[i] == 0) cnt++;
p = 1;
while (a[p] == 0) cnt--, p++;
p = n;
while (a[p] == 0) cnt--, p--;
cout << cnt << endl;
}
}
可以说是简洁明了啊,确实差距太大了(废话)
这里他的思路就是输出所有0减去前缀和后缀的0的个数。
算法也更加合理。
这里学到了新东西
ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
这个是能让cin变得更快的代码。
原来而cin,cout之所以效率低,是因为先把要输出的东西存入缓冲区,再输出,导致效率降低,而这段语句可以来打消iostream的输入 输出缓存,可以节省许多时间,使效率与scanf与printf相差无几
涨知识了。
还有while (t--)的判断,t=t-1,t=0就为false,反之全出true,进入循环,是一种简便的写法,值得学习
USACO Training 1.1.2 Greedy Gift Givers
Description
对于一群要互送礼物的朋友,你要确定每个人收到的礼物比送出的多多少
在这一个问题中,每个人都准备了一些钱来送礼物,而这些钱将会被平均分给那些将收到他的礼物的人。 然而,在任何一群朋友中,有些人将送出较多的礼物(可能是因为有较多的朋友),有些人有准备了较多的钱。
给出一群朋友, 没有人的名字会长于 14 字符,给出每个人将花在送礼上的钱,和将收到他的礼物的人的列表,请确定每个人收到的比送出的钱多的数目。
Input
第 1 行: 人数NP,2<= NP<=10
第 2到 NP+1 行:这NP个在组里人的名字 一个名字一行
第NP+2到最后:
这里的NP段内容是这样组织的:
第一行是将会送出礼物人的名字。
第二行包含二个数字: 第一个是原有的钱的数目(在0到2000的范围里),第二个 NGi 是将收到这个送礼者礼物的人的个数 如果 NGi 是非零的, 在下面 NGi 行列出礼物的接受者的名字,一个名字一行。
Output
输出 NP 行
每行是一个的名字加上空格再加上收到的比送出的钱多的数目。
对于每一个人,他名字的打印顺序应和他在输入的2到NP+1行中输入的顺序相同。所有的送礼的钱都是整数。
每个人把相同数目的钱给每位要送礼的朋友,而且尽可能多给,不能给出的钱被送礼者自己保留。
Sample Input 1
5
dave
laura
owen
vick
amr
dave
200 3
laura
owen
vick
owen
500 1
dave
amr
150 2
vick
owen
laura
0 2
amr
vick
vick
0 0
Sample Output 1
dave 302
laura 66
owen -359
vick 141
amr -150
Source
这次是学校的OJ
尝试着用循环做,但是自闭了,而且自闭了很久很久很久.....
后来学了新知识MAP
1,map简介
map是STL的一个关联容器,它提供一对一的hash。
- 第一个可以称为关键字(key),每个关键字只能在map中出现一次;
- 第二个可能称为该关键字的值(value);
map以模板(泛型)方式实现,可以存储任意类型的数据,包括使用者自定义的数据类型。Map主要用于资料一对一映射(one-to-one)的情況,map內部的实现自建一颗红黑树,这颗树具有对数据自动排序的功能。在map内部所有的数据都是有序的,后边我们会见识到有序的好处。比如一个班级中,每个学生的学号跟他的姓名就存在著一对一映射的关系。
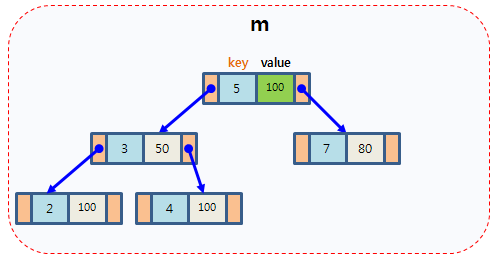
2,map的功能
自动建立key - value的对应。key 和 value可以是任意你需要的类型,包括自定义类型。
3,使用map
使用map得包含map类所在的头文件
#include
map对象是模板类,需要关键字和存储对象两个模板参数:
std:map<int, string> personnel;
这样就定义了一个用int作为索引,并拥有相关联的指向string的指针.
为了使用方便,可以对模板类进行一下类型定义,
typedef map<int,CString> UDT_MAP_INT_CSTRING;
UDT_MAP_INT_CSTRING enumMap;
4,map的构造函数
map共提供了6个构造函数,这块涉及到内存分配器这些东西,略过不表,在下面我们将接触到一些map的构造方法,这里要说下的就是,我们通常用如下方法构造一个map:
map<int, string> mapStudent;
5,插入元素
// 定义一个map对象
map<int, string> mapStudent;
// 第一种 用insert函數插入pair
mapStudent.insert(pair<int, string>(000, "student_zero"));
// 第二种 用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type(001, "student_one"));
// 第三种 用"array"方式插入
mapStudent[123] = "student_first";
mapStudent[456] = "student_second";
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是不能在插入数据的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值,用程序说明如下:
mapStudent.insert(map<int, string>::value_type (001, "student_one"));
mapStudent.insert(map<int, string>::value_type (001, "student_two"));
上面这两条语句执行后,map中001这个关键字对应的值是“student_one”,第二条语句并没有生效,那么这就涉及到我们怎么知道insert语句是否插入成功的问题了,可以用pair来获得是否插入成功,程序如下
// 构造定义,返回一个pair对象
pair<iterator,bool> insert (const value_type& val);
pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map<int, string>::value_type (001, "student_one"));
if(!Insert_Pair.second)
cout << ""Error insert new element" << endl;
我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。
6, 查找元素
当所查找的关键key出现时,它返回数据所在对象的位置,如果沒有,返回iter与end函数的值相同。
// find 返回迭代器指向当前查找元素的位置否则返回map::end()位置
iter = mapStudent.find("123");
if(iter != mapStudent.end())
cout<<"Find, the value is"<<iter->second<<endl;
else
cout<<"Do not Find"<<endl;
7, 刪除与清空元素
//迭代器刪除
iter = mapStudent.find("123");
mapStudent.erase(iter);
//用关键字刪除
int n = mapStudent.erase("123"); //如果刪除了會返回1,否則返回0
//用迭代器范围刪除 : 把整个map清空
mapStudent.erase(mapStudent.begin(), mapStudent.end());
//等同于mapStudent.clear()
8,map的大小
在往map里面插入了数据,我们怎么知道当前已经插入了多少数据呢,可以用size函数,用法如下:
int nSize = mapStudent.size();
9,map的基本操作函数:
C++ maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号