结对第二次作业
| 这个作业属于哪个课程 | <班级的链接> |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 结对学号 | 221801103 221801125 |
| 这个作业的目标 | 对已爬取的论文列表进行操作 分析已爬取到的论文信息,提取top10个热门领域或热门研究方向 |
| 其他参考文献 |
git仓库链接,代码规范链接,项目展示链接
PSP表格
- 221801103
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| • 估计这个任务需要多少时间 | 10 | 5 |
| 开发 | ||
| • 需求分析 (包括学习新技术) | 15 | 20 |
| • 生成设计文档 | 20 | 40 |
| • 设计复审 | 5 | 5 |
| • 代码规范 (为目前的开发制定合适的规范) | 5 | 3 |
| • 具体设计 | 20 | 120 |
| • 具体编码 | 2100 | 2520 |
| • 代码复审 | 60 | 240 |
| • 测试(自我测试,修改代码,提交修改) | 120 | 320 |
| 报告 | ||
| • 测试报告 | 20 | 20 |
| • 计算工作量 | 10 | 10 |
| • 事后总结, 并提出过程改进计划 | 5 | 5 |
| 合计 | 2390 | 3308 |
- 221801125
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| • 估计这个任务需要多少时间 | 10 | 5 |
| 开发 | ||
| • 需求分析 (包括学习新技术) | 15 | 20 |
| • 生成设计文档 | 20 | 40 |
| • 设计复审 | 5 | 5 |
| • 代码规范 (为目前的开发制定合适的规范) | 5 | 3 |
| • 具体设计 | 20 | 120 |
| • 具体编码 | 1800 | 2230 |
| • 代码复审 | 30 | 20 |
| • 测试(自我测试,修改代码,提交修改) | 60 | 240 |
| 报告 | ||
| • 测试报告 | 10 | 5 |
| • 计算工作量 | 20 | 5 |
| • 事后总结, 并提出过程改进计划 | 5 | 5 |
| 合计 | 2000 | 2698 |
成品展示
- 未登录

- 登录注册


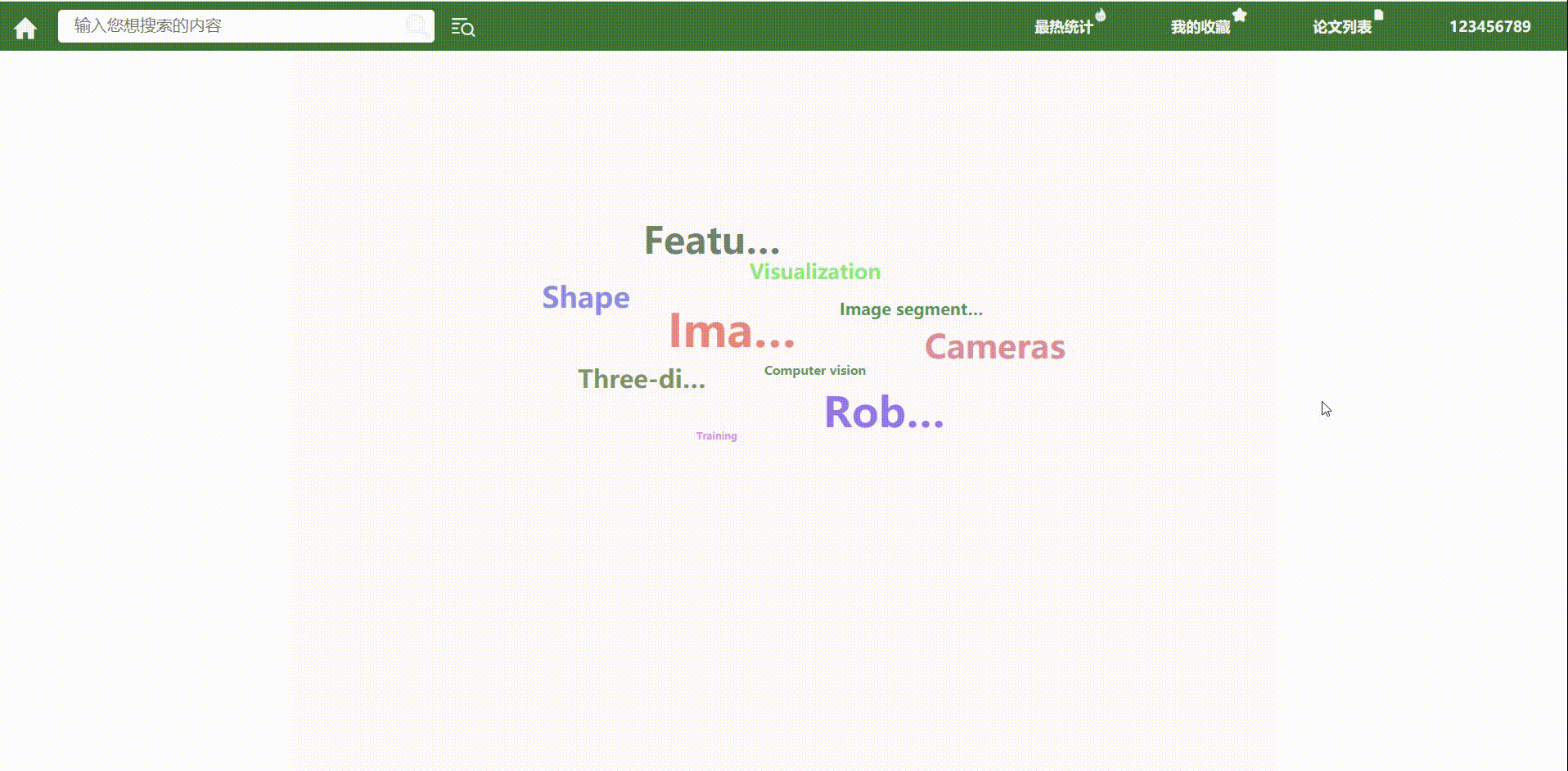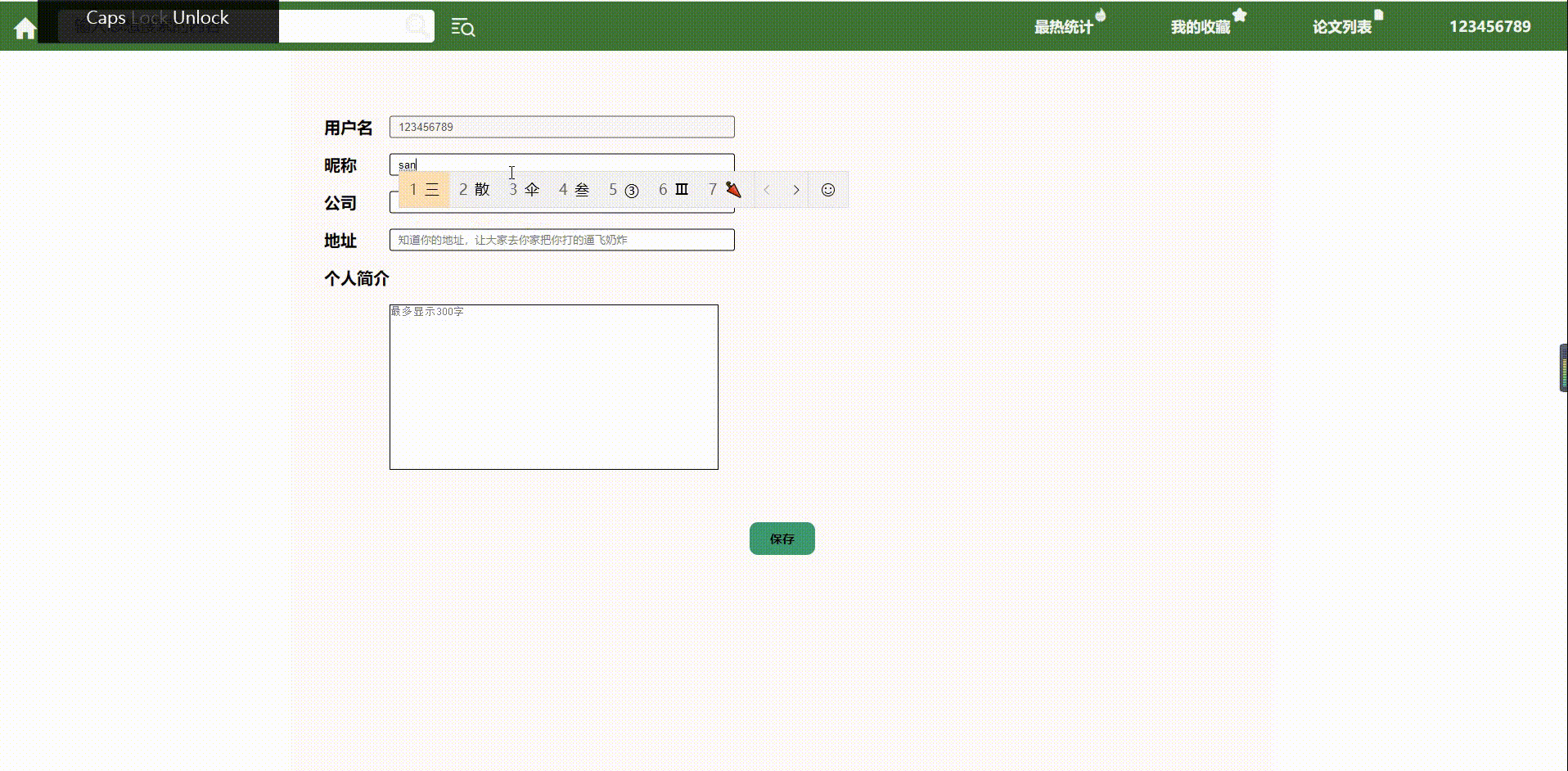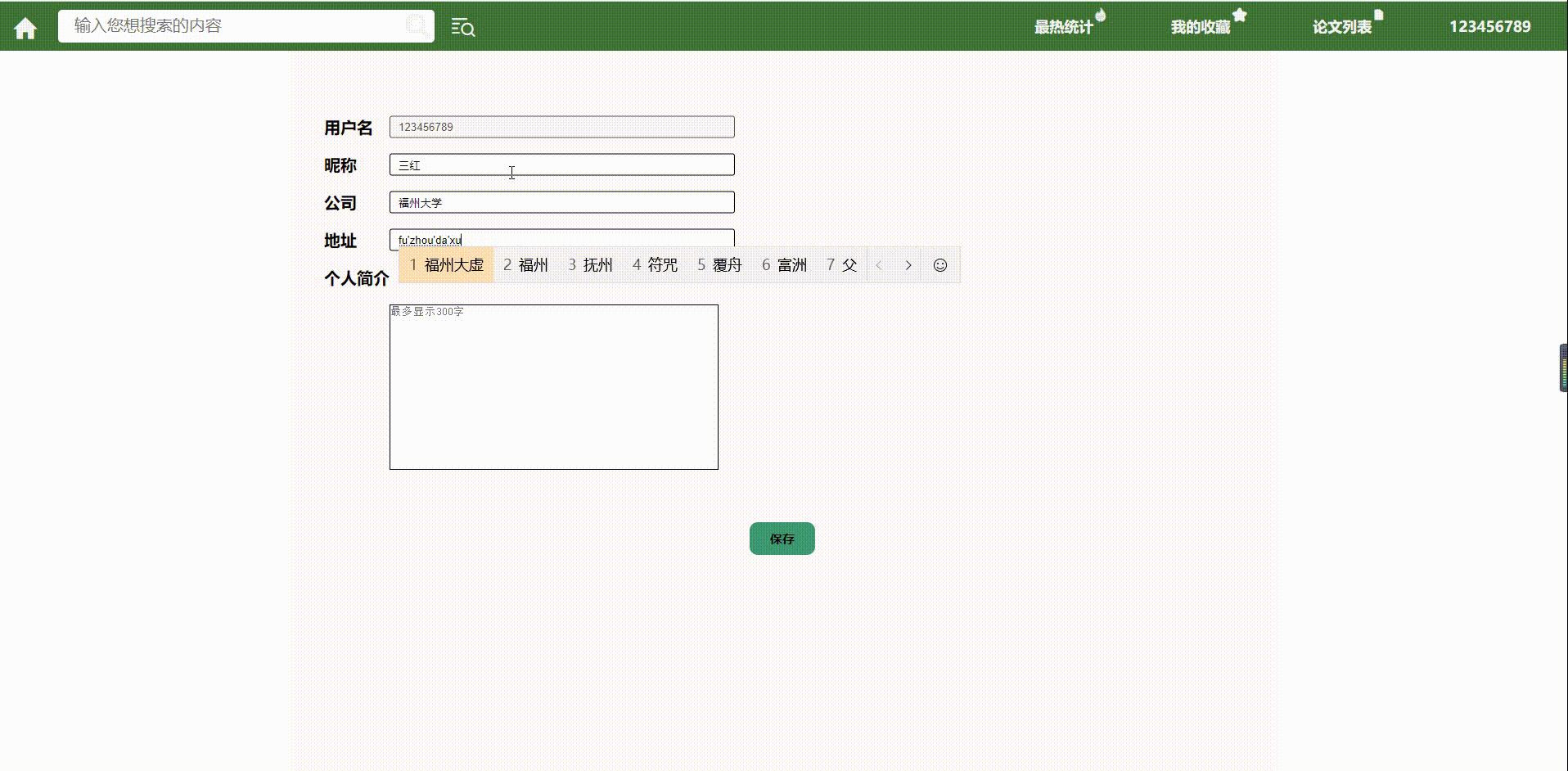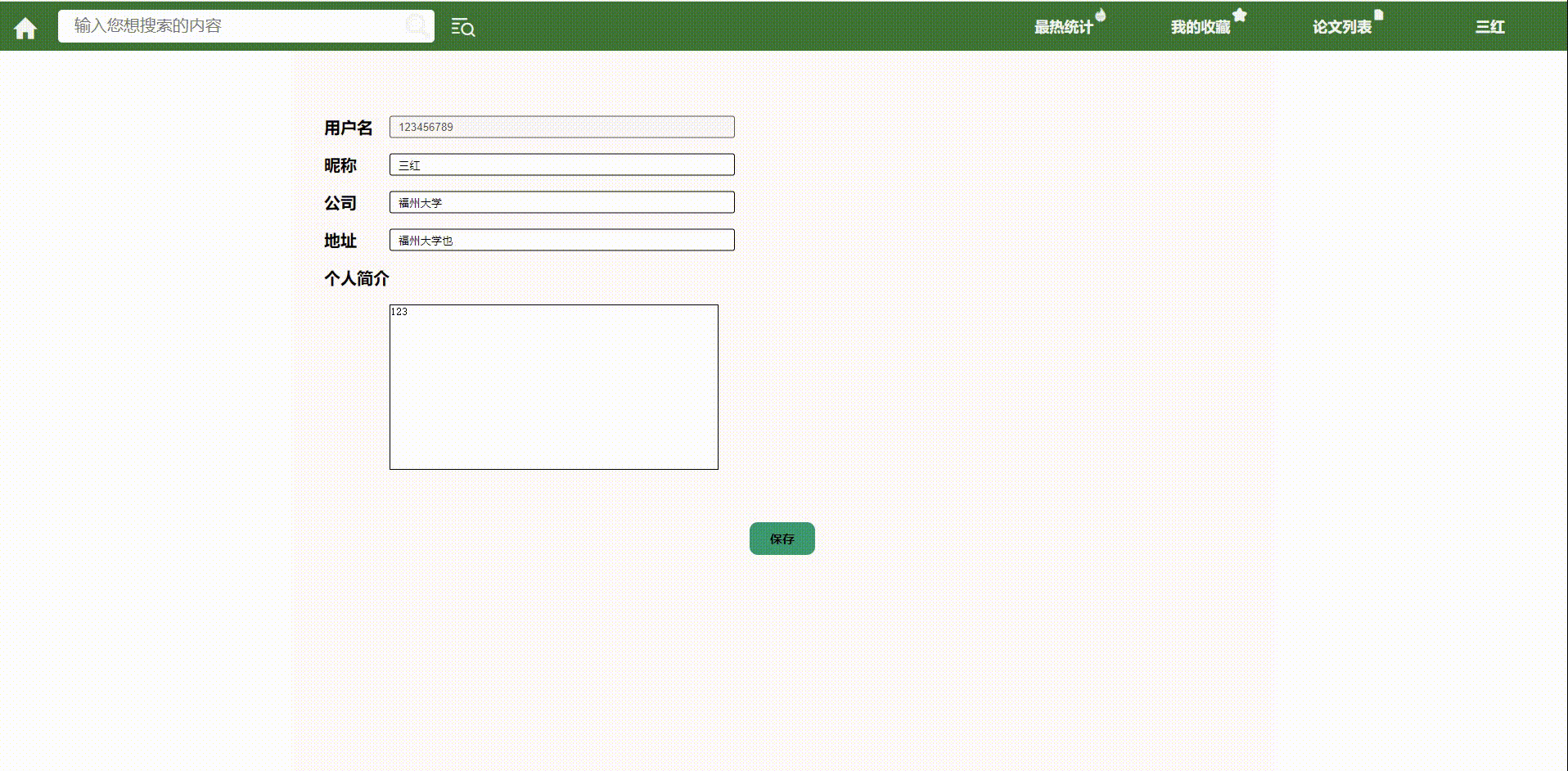
- 首页词云

- 统计
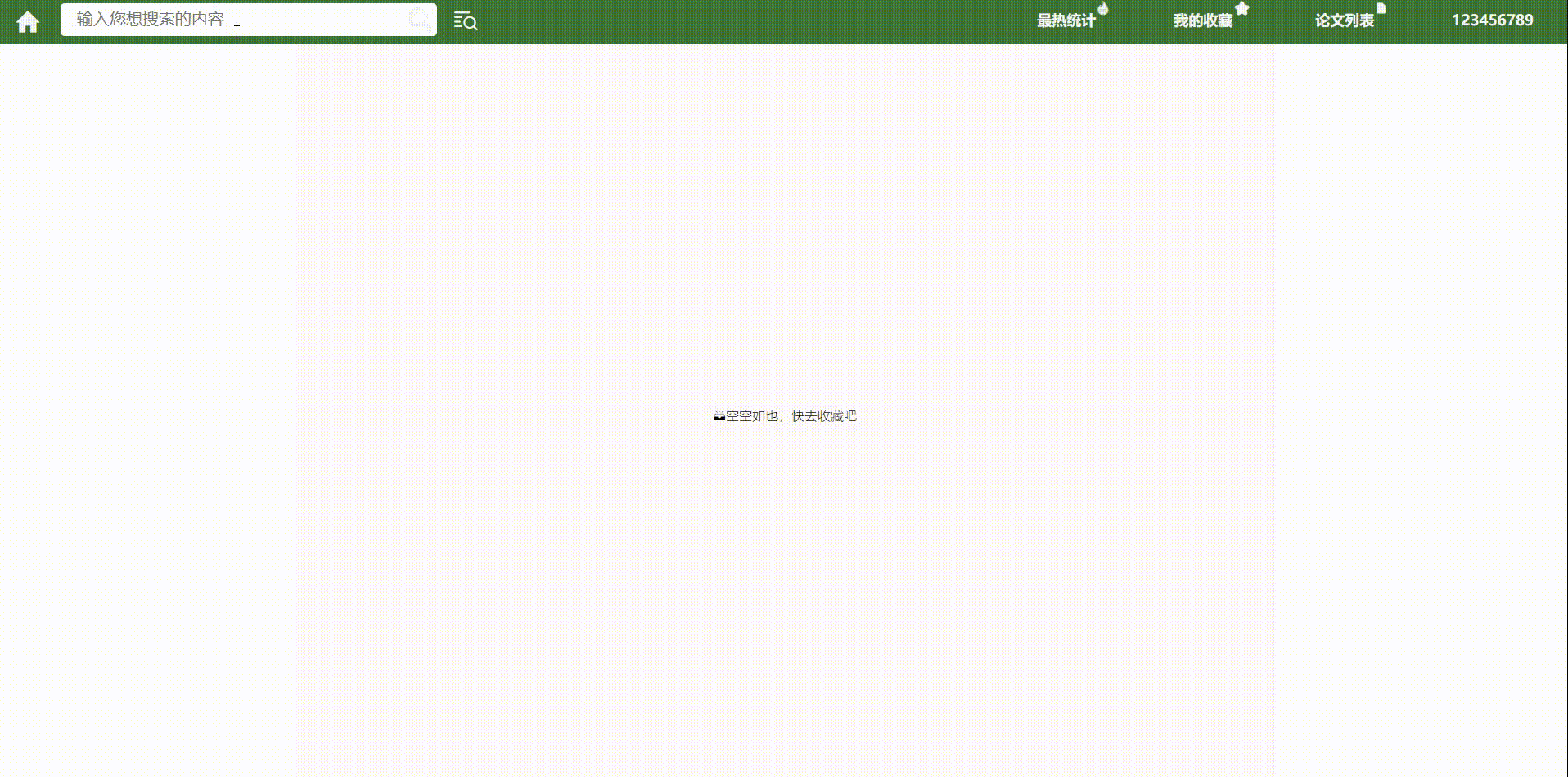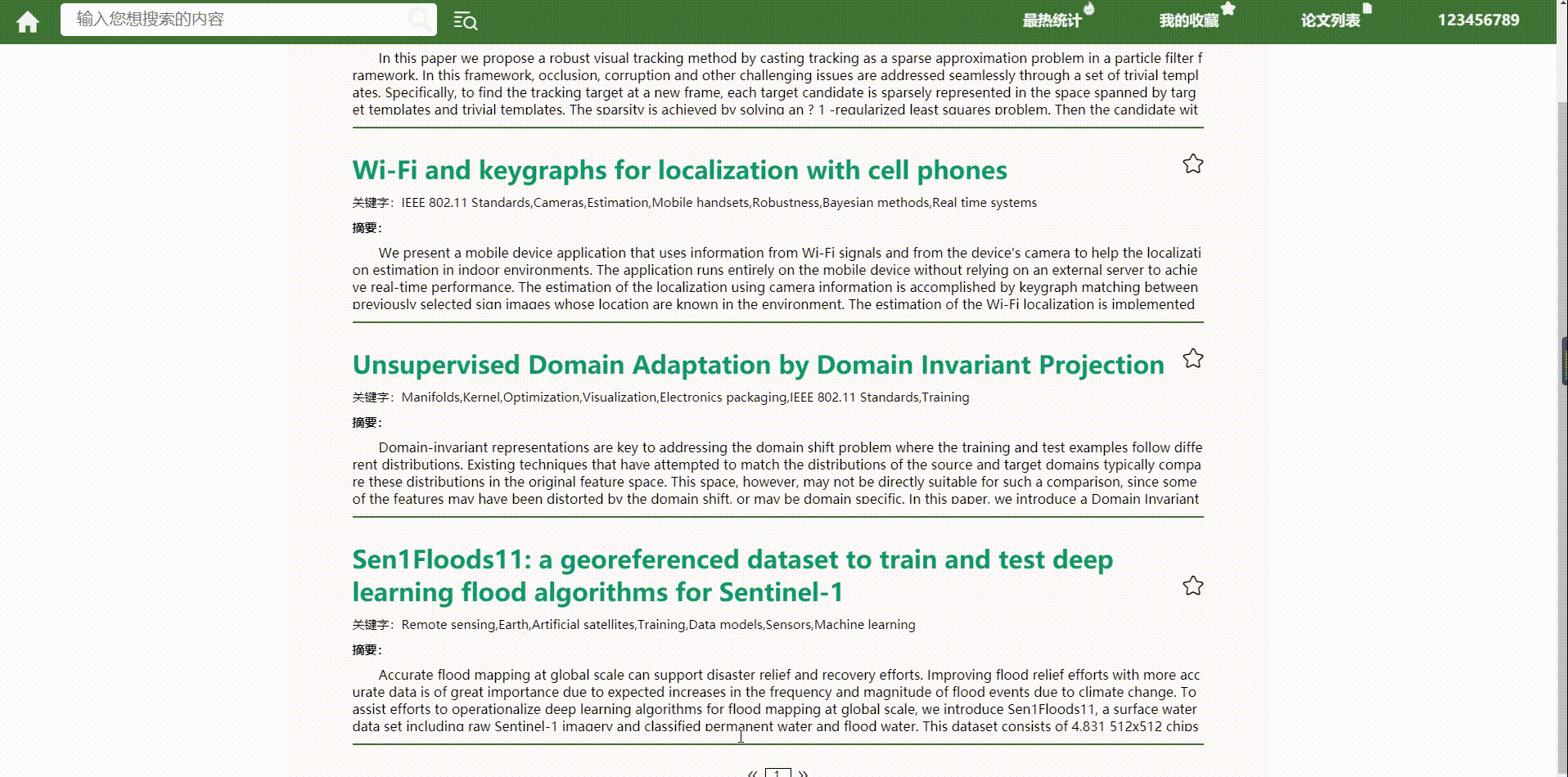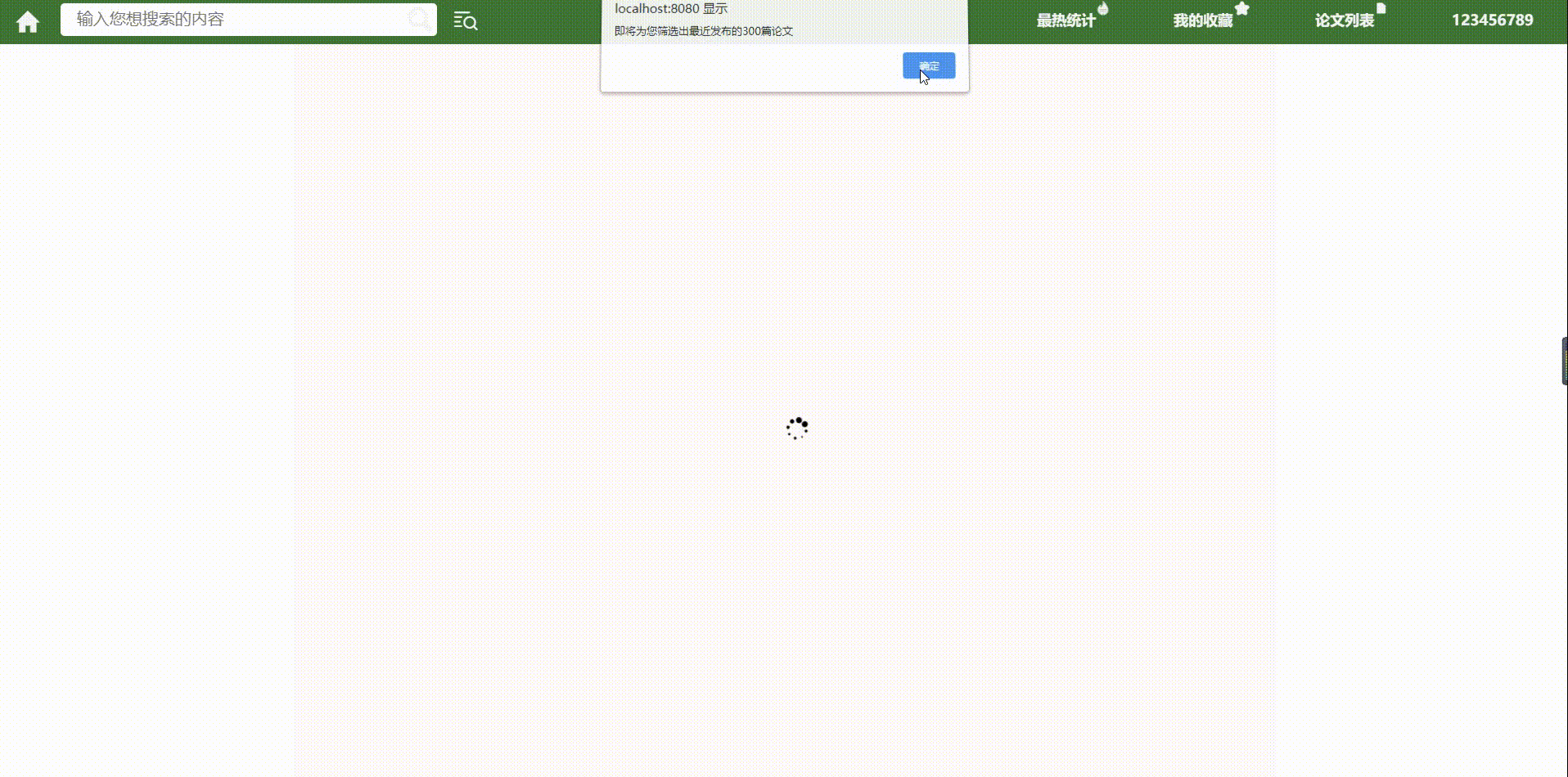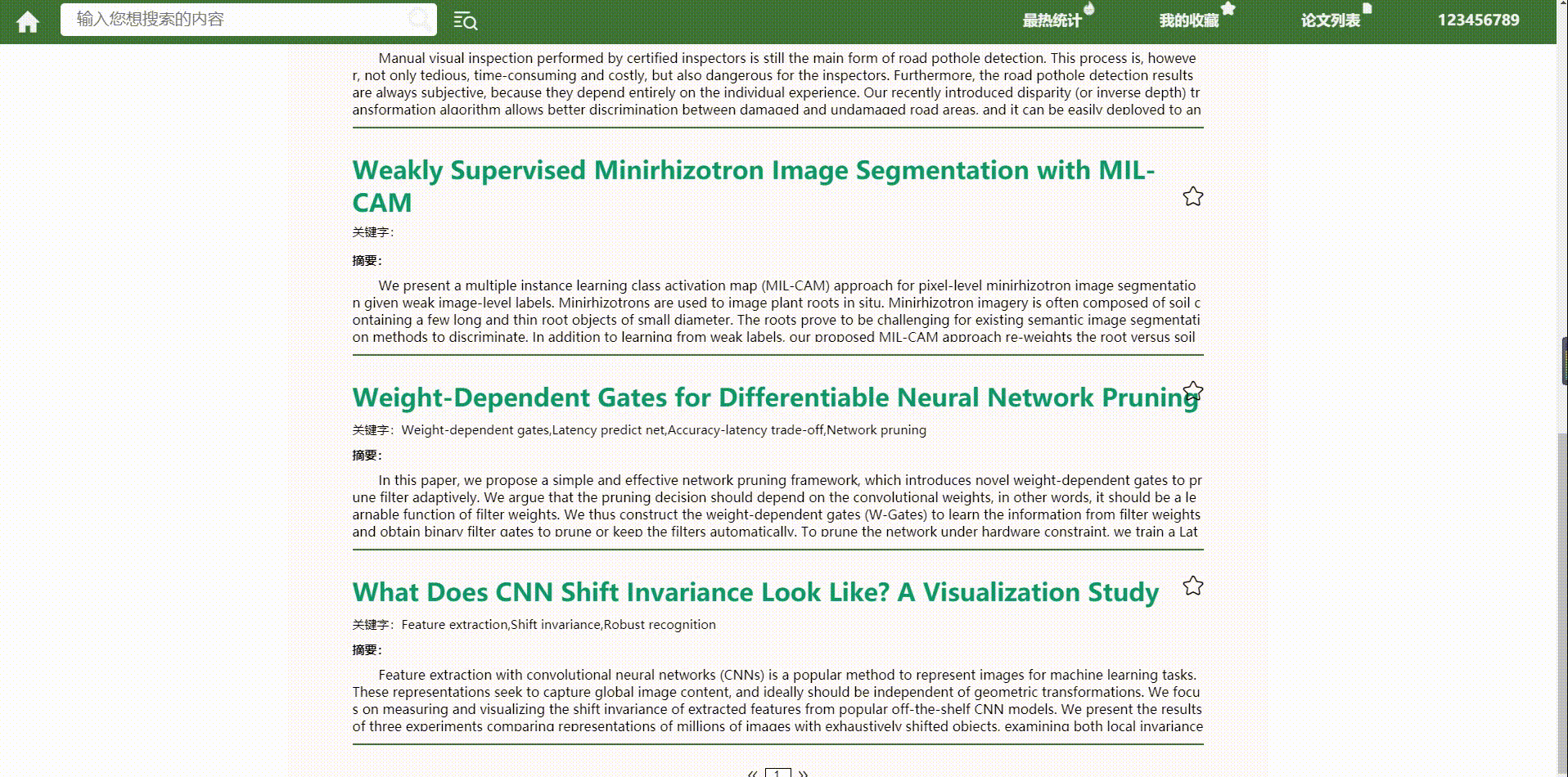
- 模糊搜索
- 个人设置
*数据库增加,收藏

- 数据库删除,取消收藏
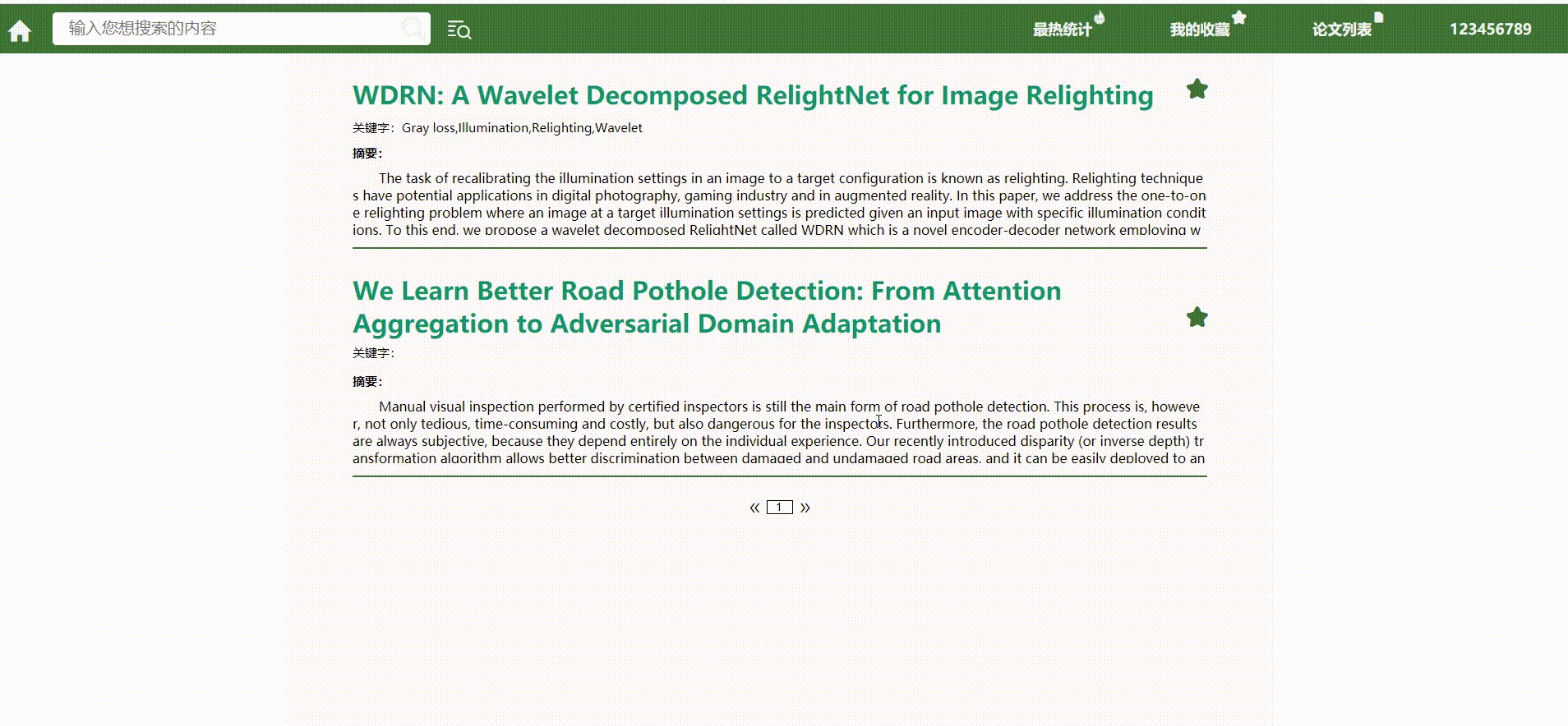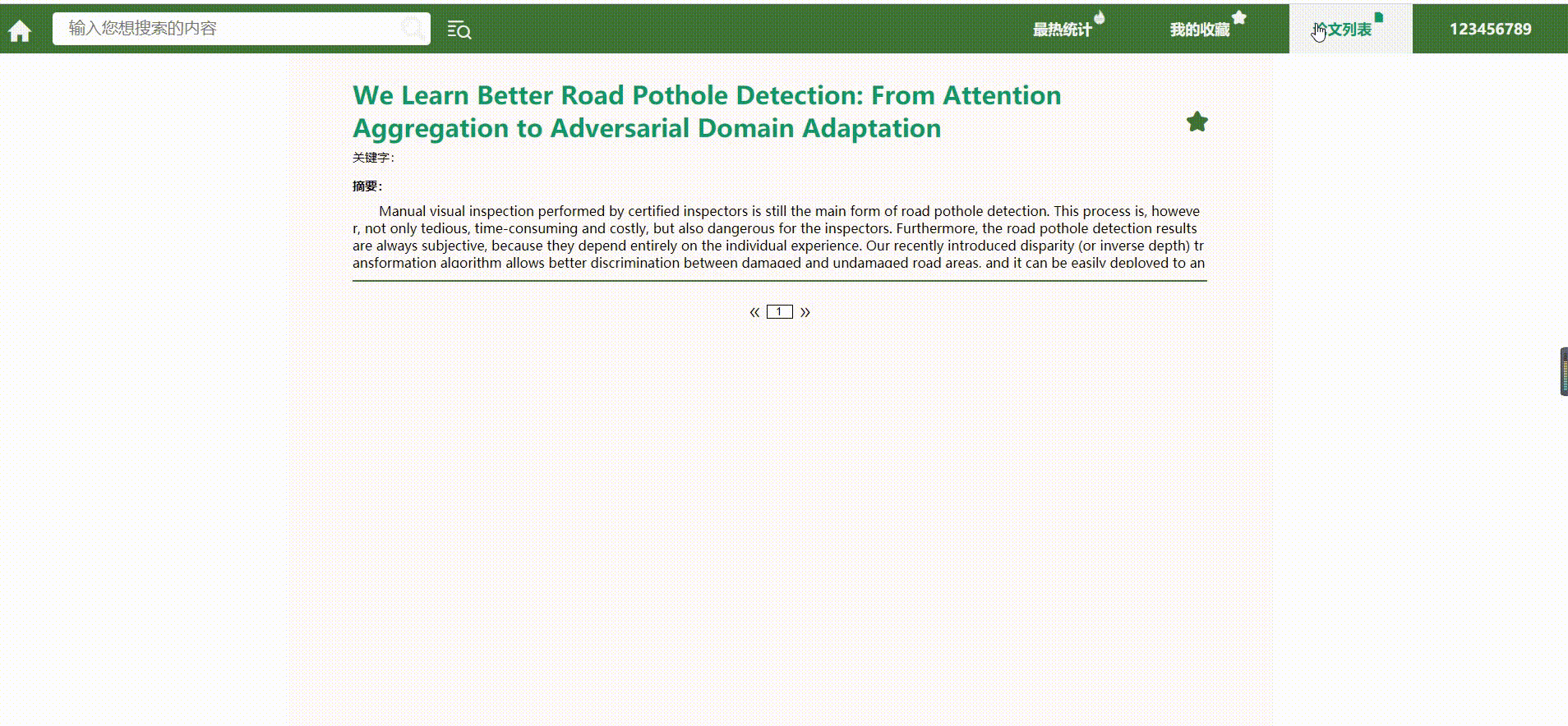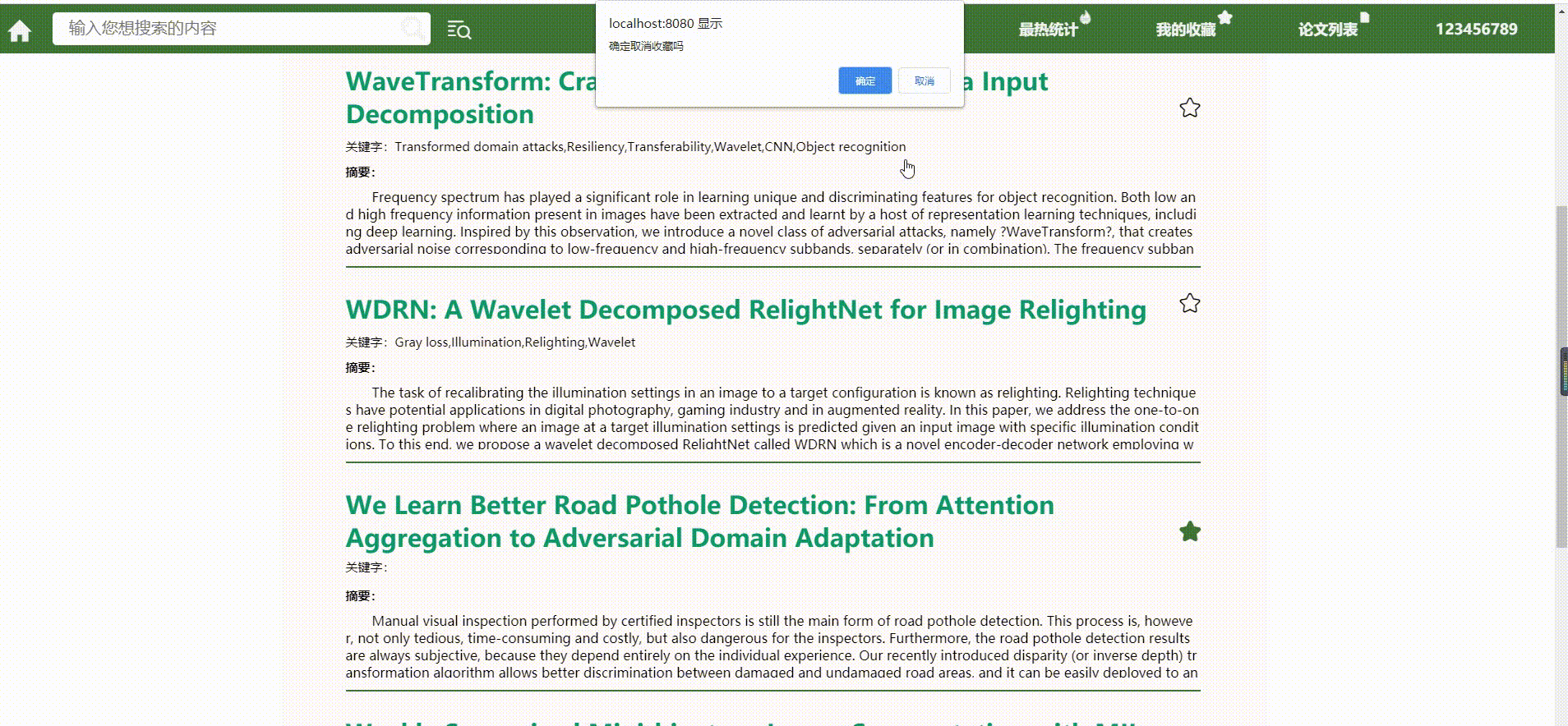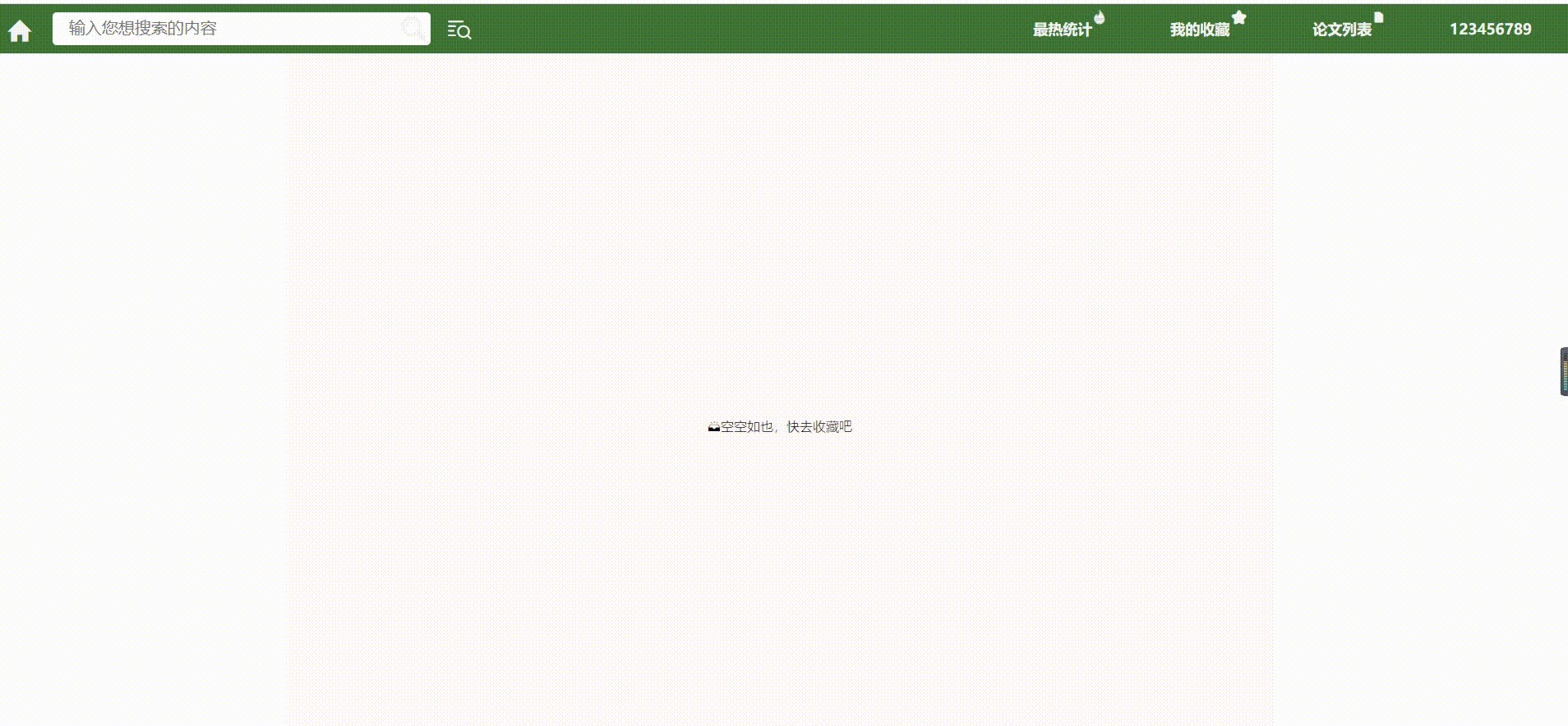
*分页功能
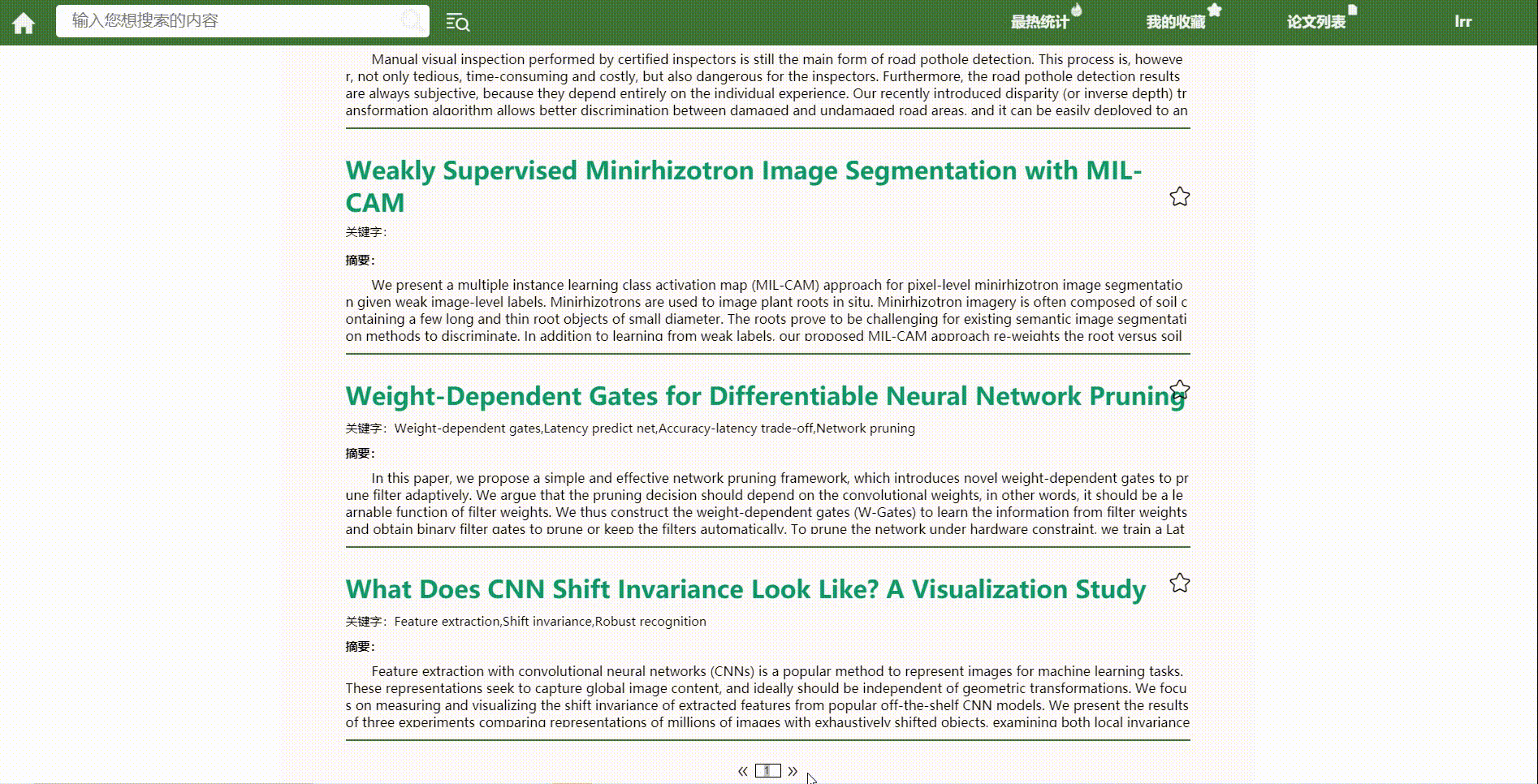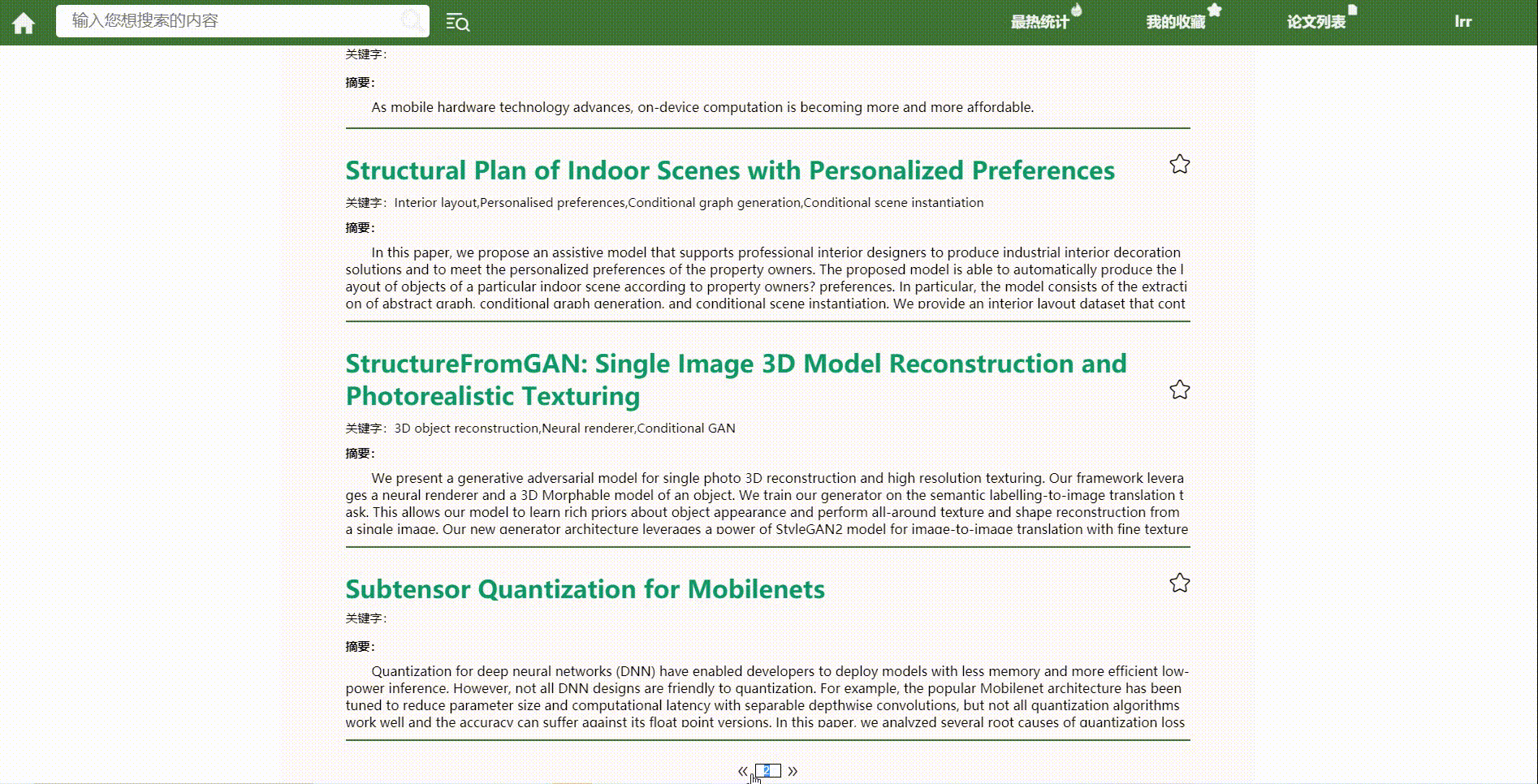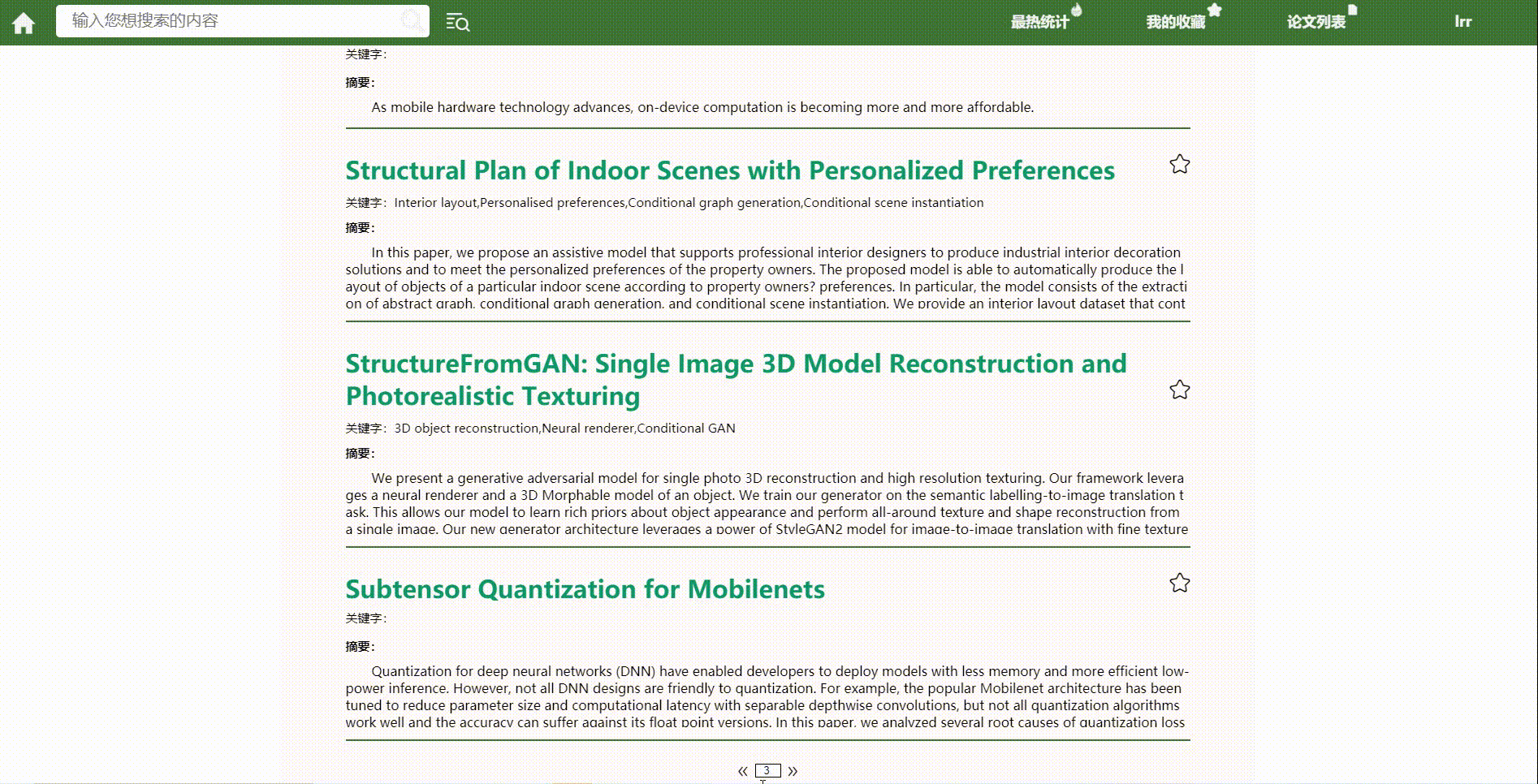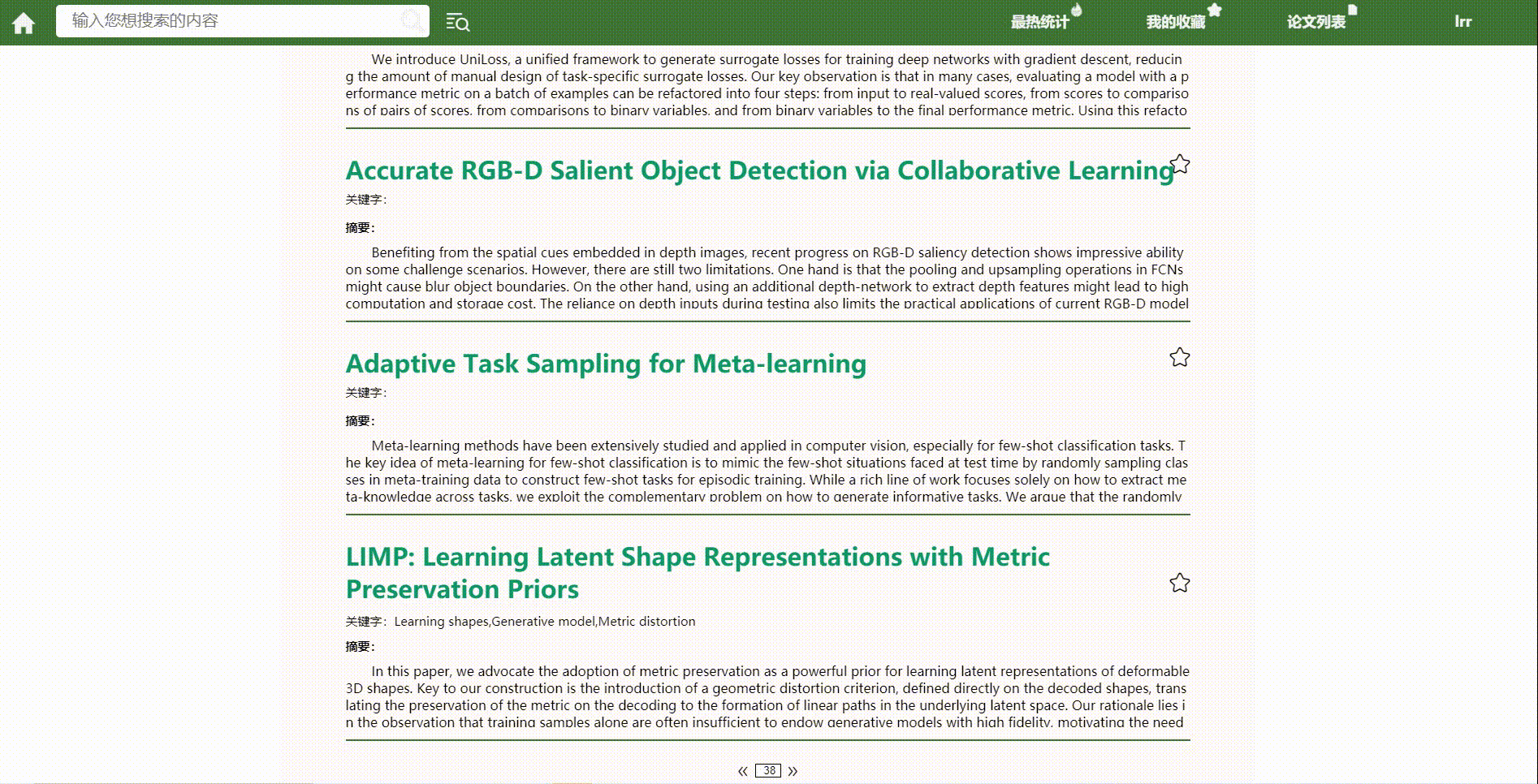
结对讨论过程描述

- 接口文档
- 根据原型设计接口文档
//第一版接口文档
1.登录注册
注册
前端:账号密码string数组
[ username,password ]
后端:int类型
0,账号已存在,
1,注册成功
2,注册失败
登录
前端:{"userName":"","password":""}
[ username,password ]
后端:false(账号密码不匹配)
(账号密码匹配)
所有的个人信息,json
{
"type" : false
"name": "",
"address": "",
"company":"",
"info":""
}
2.首页
前端:
后端:[ 前十名关键字的string数组 ]
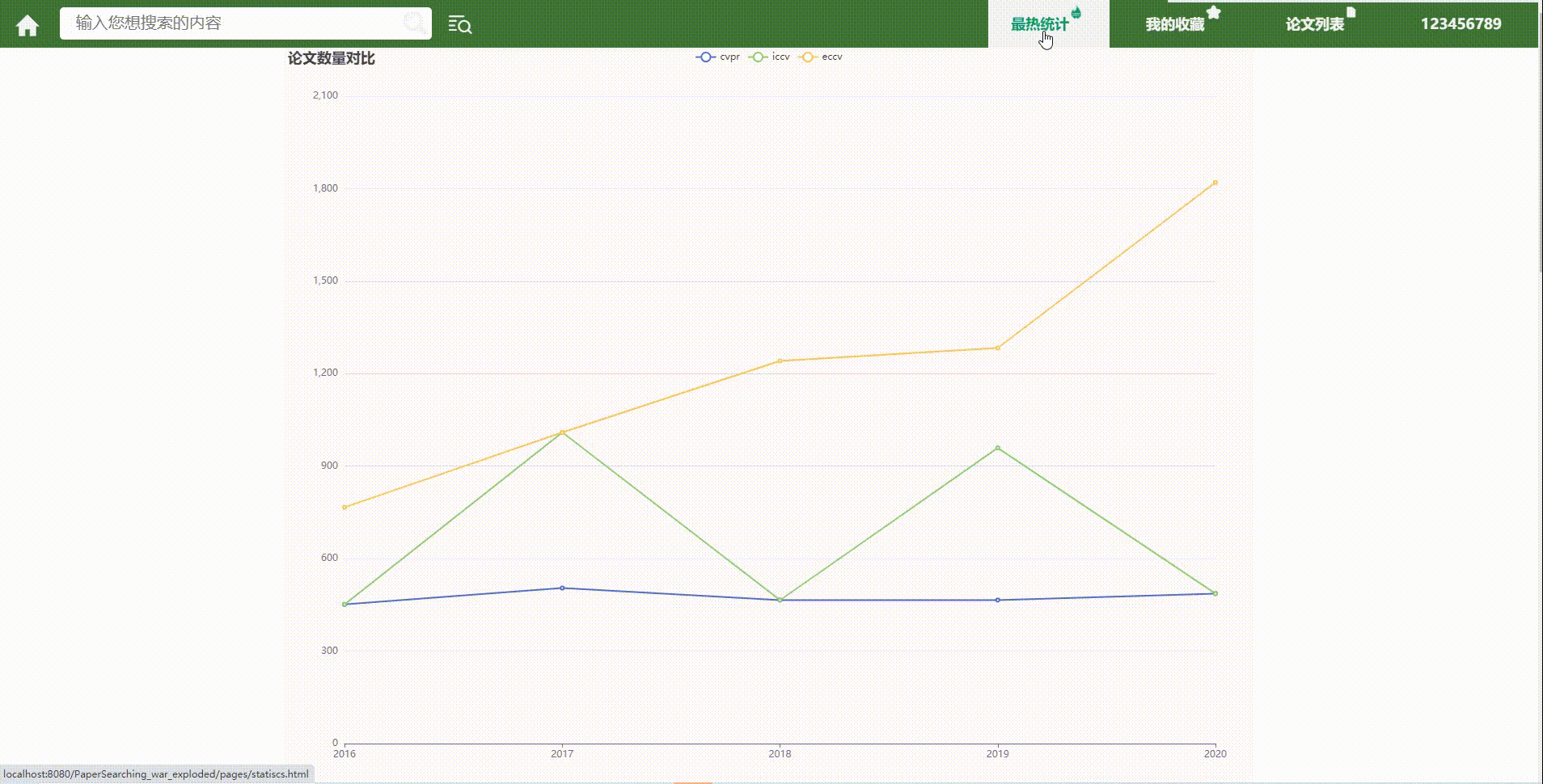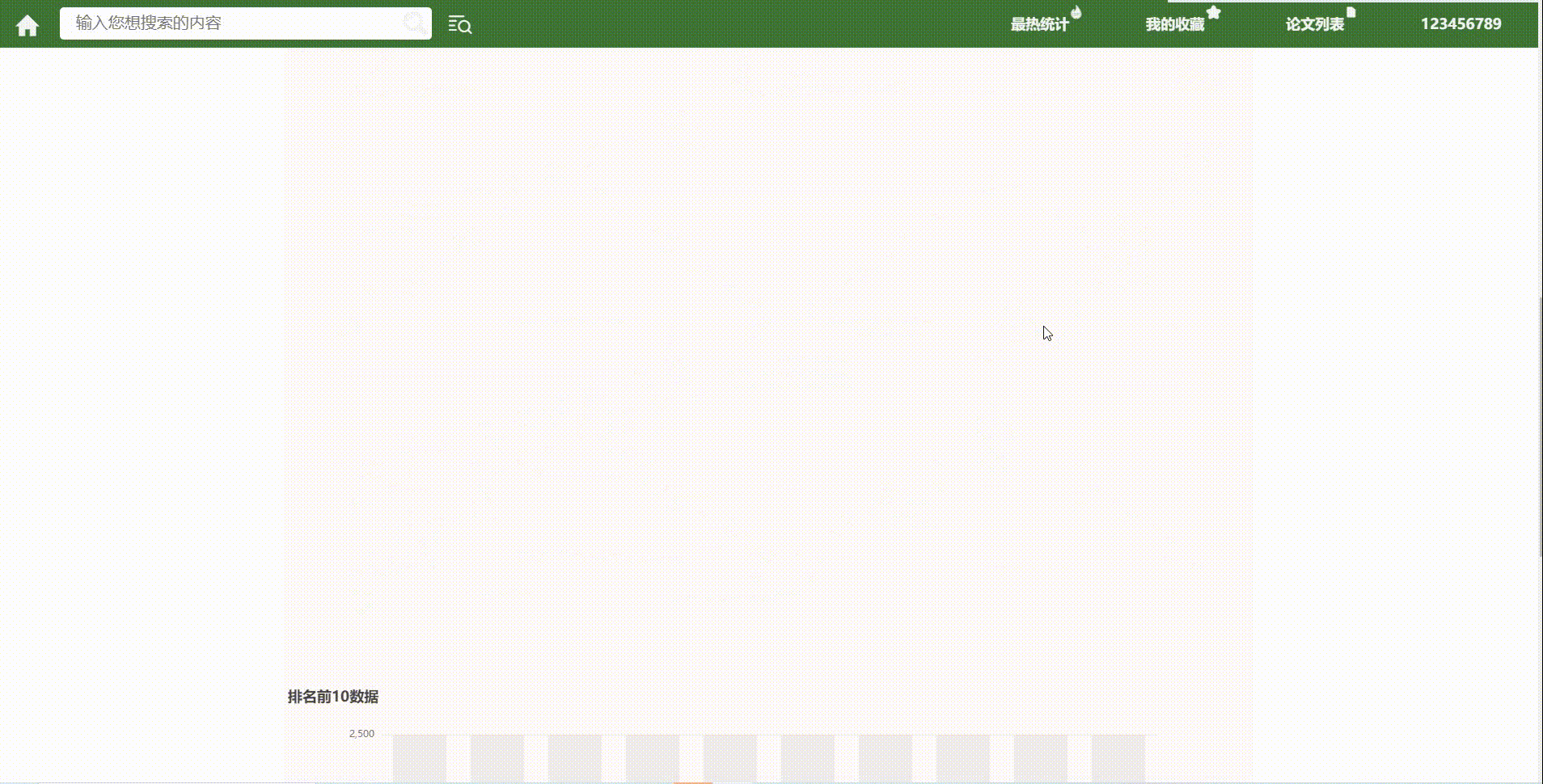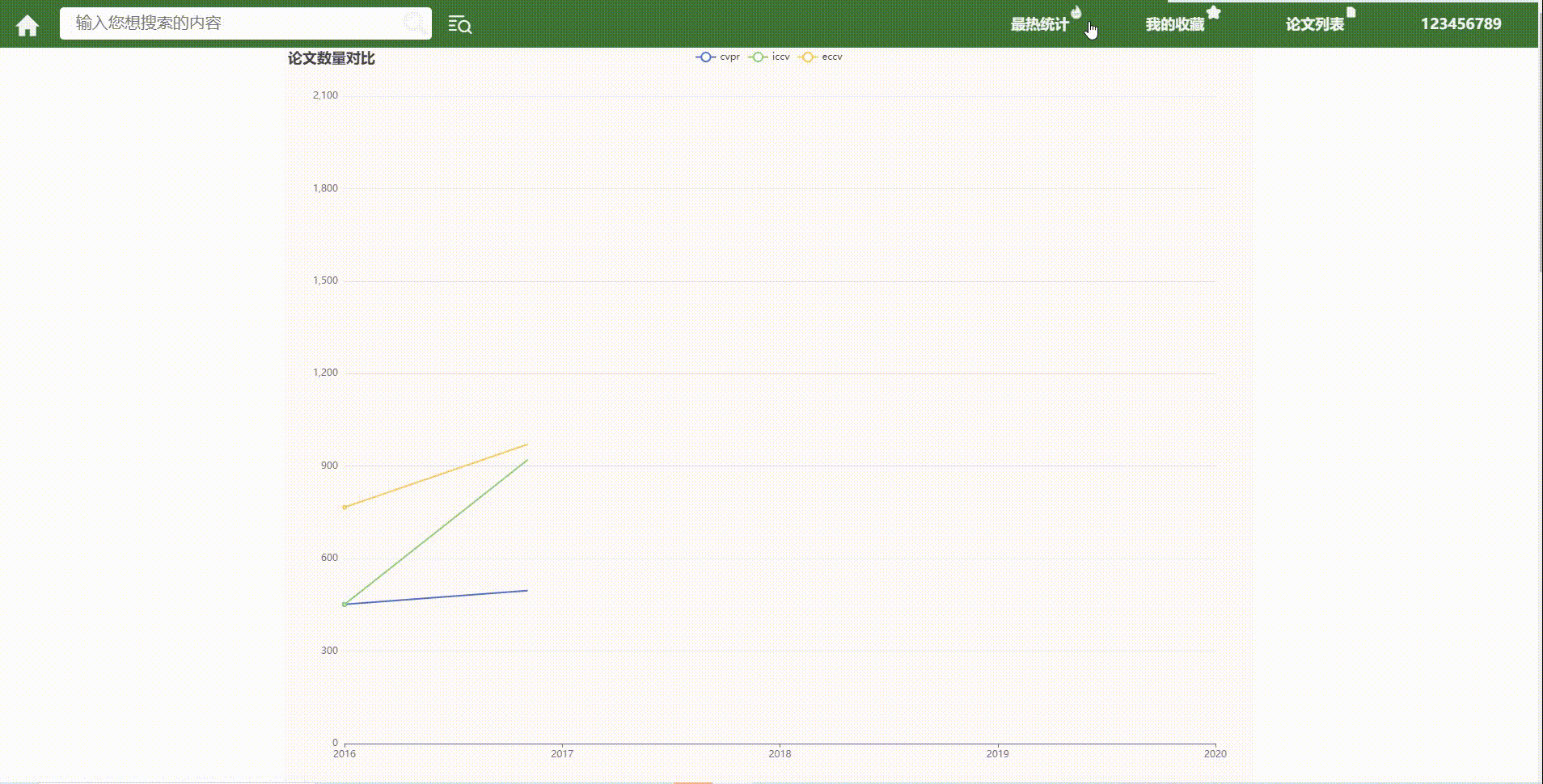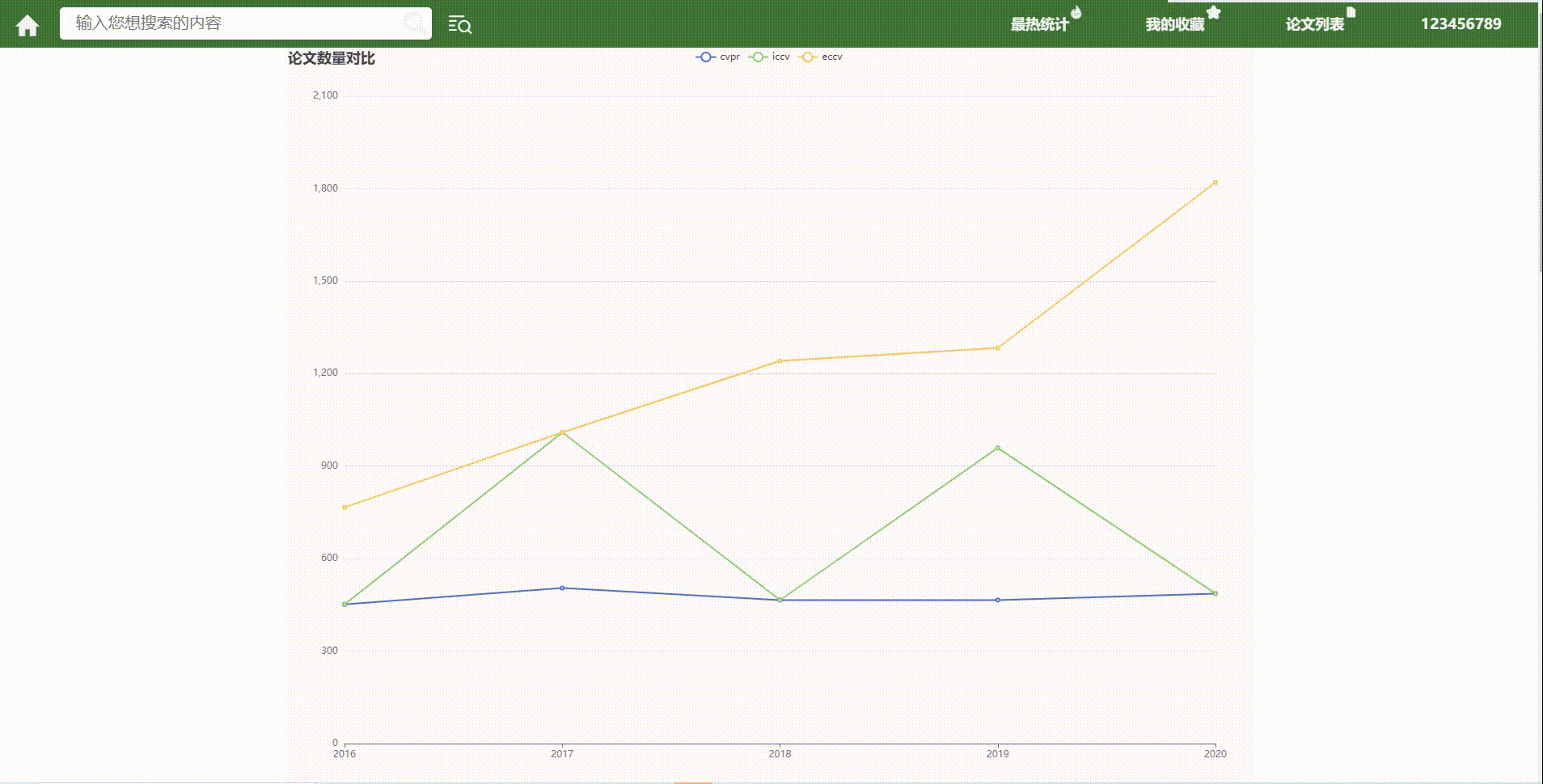
3.最热统计
前端:
后端:json数据
{
"hottest" : [热门领域string数组],
"cvpr" : [cvpr的前5月排行int数组],
"iccv" : [iccv的前5月排行int数组],
"eccv" : [eccv的前5月排行int数组],
}
4.我的收藏
前端:{"userName" :""}
后端:json
(论文图片, 标题,作者,关键字,摘要)
{
"img" : ""
"title" : "",
"author" : "",
"keyword" : "",
"info" : ""
}
5.论文列表
前端:json文件
{
"type":(int类型)
0 (关键字)
1(论文标题)
2 ( 所有论文 )
"str": "string类型传递过来的数据"
}
后端:所有符合搜索的json
标题,作者,关键字,摘要
{
"title" : "",
"author" : "",
"keyword" : "",
"info" : ""
}
6.我的设置
(修改的时候才会提交)
前端:json
{
"username" : ""
"name" : ""
"address" : ""
"company" : ""
"info" : ""
}
后端:
{
"type":true,false
}
7.论文详情页
前端:{"title" :""}
后端:返回论文json信息
标题,作者,关键字,内容
{
"title" : "",
"author" : "",
"keyword" : "",
"content" : ""
}
- 前后端分离开发
- 前端在git创建yabi分支对应开发
- 后端在git创建hanxiaotao分支对应开发
- 前端按照原型进行页面开发
- 后端进行接口文档,进行相对应操作
- 后端接口测试
- postman进行测试
- 前后端对接
- 前端运用MVC模型中M,与后端进行对接
github commit 记录
设计实现过程
实现过程
- 用户登录后点击全部论文,即可获得全部论文
- 前端向后端发送ajax请求,后端通过请求进行查询对应页码操作
- 收藏界面以及论文列表界面的收藏按钮,点击后可以收藏
- 前端向后端发送ajax请求,后端通过请求进行增删语句
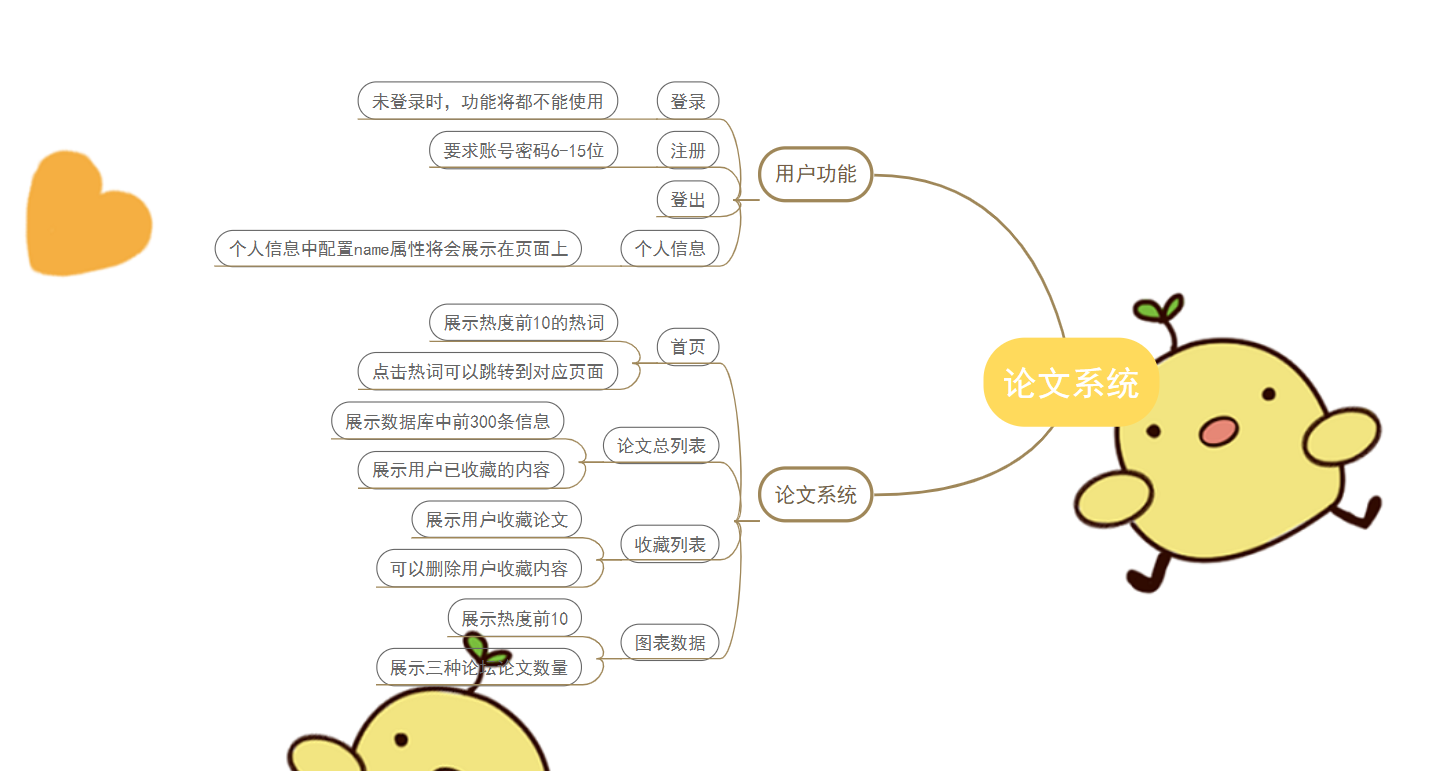
功能结构图
代码说明
-
前端代码
-
定义全局内容,避免后续更改代码内内容
-
//user内容参考 var USER_INFO = { "name" : localStorage.getItem("name")==null? "":localStorage.getItem("name"), // "userID" : localStorage.getItem("userName")==null? "":localStorage.getItem("userName"), } var DATA_NEEDED_TO_BE_CHANGED = false var HOTTEST_TOP10 = [] var HOTTEST_THREE = {} var ALL_PAGE_LIST = [] var LIKE_LIST = [] -
//ajax路径配置 const BASE_URL = "http://192.168.0.114:8080/PaperSearching_war_exploded/" const GLOBAL_BLUR_SEARCH_ALL_PAPER_AND_COUNT = BASE_URL+"PaperListServlet" const GLOBAL_BUL_DELETE_MY_COLLECT = BASE_URL+"DeleteMyCollectSevlet" const GLOBAL_BLUR_UPDATE = BASE_URL+"UpdateMyCollectServlet" const AJAX_URL = { "allPaper" : GLOBAL_BLUR_SEARCH_ALL_PAPER_AND_COUNT, //获取所有论文 "allPaperCount" : GLOBAL_BLUR_SEARCH_ALL_PAPER_AND_COUNT, //获取论文页数 "allPaperDelete" : GLOBAL_BUL_DELETE_MY_COLLECT, //论文取消收藏 "allPaperAdd" : GLOBAL_BLUR_UPDATE, //论文添加收藏 ... } -
使用jquery面向对象开发,将dom绑定以及事件分离
-
function Page(){} $.extend(Page.prototype,{ init:function(){ this.bindEvents() ... }, bindEvents:function(){ var logOut = $(".slide-down li:eq(1)") logOut.click(this.logOutFunc) }, logOutFunc:function(){ } }) var page = new Page() page.init() -
ajax异步请求数据,动态展示页面
$.ajax({ url: AJAX_URL.myPaperCount, type: "post", data: JSON.stringify({ type: 0, account: USER_INFO.userID, methods: "getPages", }), contentType: "application/json", success: (data) => { }, error: () => { alert("网络不好,什么都看不到"); }, }); }, }); $("#reg_wait").css("display", "inline-block");//等待页面
-
-
后端代码
-
servlet
-
response.setHeader("Access-Control-Allow-Origin", "*"); /* 允许跨域的请求方法GET, POST, HEAD 等 */ response.setHeader("Access-Control-Allow-Methods", "*"); /* 重新预检验跨域的缓存时间 (s) */ response.setHeader("Access-Control-Max-Age", "4200"); /* 允许跨域的请求头 */ response.setHeader("Access-Control-Allow-Headers", "*"); /* 是否携带cookie */ response.setHeader("Access-Control-Allow-Credentials", "true"); requestJson=JSONObject.fromObject( RequestToJson.getRequestPostStr(request)); if(requestJson.getString("methods").equals("getPages")) { showPapers.clear(); String account=requestJson.getString("account"); List<Paper> papers=paperserviceimpl.GetMyCollect(account); for (int i=0;i<papers.size();i++) { JSONObject jsonObject=new JSONObject(); jsonObject.put("title",papers.get(i).getTitle()); String[] authorList=papers.get(i).getAuthors().split("//"); jsonObject.put("author",authorList); String[] keywordList=papers.get(i).getKeywords().split("//"); jsonObject.put("keyword",keywordList); jsonObject.put("abstract",papers.get(i).getTheabstract()); jsonObject.put("link",papers.get(i).getPaperlink()); jsonObject.put("iscollect",paperserviceimpl.IsCollected(account,papers.get(i).getTitle())); showPapers.add(jsonObject); } System.out.println(showPapers.size()); response.getWriter().print(showPapers.size()); } if(requestJson.getString("methods").equals("getCollectList")) { int index=requestJson.getInt("page"); if(index*8<=showPapers.size()) { response.getWriter().print(showPapers.subList((index - 1) * 8, index * 8)); } else { response.getWriter().print(showPapers.subList((index - 1) * 8, (index - 1) * 8+showPapers.size()%8)); } } -
mysql
-
public HashMap<String,Integer> GetHottestKeywords() { HashMap<String,Integer> hashMap=new HashMap<>(); try { Connection connection = Jdbcutils.GetConnection(); PreparedStatement preparedStatement = connection.prepareStatement( "select * from keyword order by total desc limit 0,10"); ResultSet resultSet=preparedStatement.executeQuery(); while(resultSet.next()) { hashMap.put(resultSet.getString("keyword"), resultSet.getInt("total")); } Jdbcutils.CloseConnection(preparedStatement,connection); } catch (Exception e) { e.printStackTrace(); } return hashMap; } -
json解析
-
BufferedReader bufferedReader = new BufferedReader(new FileReader(files[k])); String paperString=""; String temp1; while((temp1 = bufferedReader.readLine())!=null) { paperString+=temp1 ; } JSONObject jsonObject = JSONObject.fromObject(paperString.substring(0, paperString.length() - 1)); /*isbn = JSONObject.fromObject( jsonObject.getJSONArray("isbn").get(0)).getString("value");*/ isbn=jsonObject.getString("articleNumber"); title = jsonObject.getString("title"); JSONArray authorArray = jsonObject.getJSONArray("authors"); for (int i = 0; i < authorArray.size(); i++) { authors += JSONObject.fromObject( jsonObject.getJSONArray("authors").get(i)).getString("name") + "//"; } if (jsonObject.containsKey("keywords")) { JSONArray jsonArray = jsonObject.getJSONArray("keywords"); JSONObject temp = JSONObject.fromObject(jsonArray.get(0)); String kwd = temp.getString("kwd"); JSONArray jsonArray1 = JSONArray.fromObject(kwd); Object[] objects = jsonArray1.toArray(); for (Object keyword : objects) { keywords += keyword + "//"; } addKeywordsCount(keywords); } if (jsonObject.containsKey("abstract")) { theabstract = jsonObject.getString("abstract"); } else { theabstract=""; } publishDate = jsonObject.getString("chronOrPublicationDate"); String datestr; if(getMonth(publishDate).equals("00")) { datestr = publishDate.substring(publishDate.length() - 4, publishDate.length()) + "-" + "01"//getMonth(publishDate) + "-01"; } else { datestr = publishDate.substring(publishDate.length() - 4, publishDate.length()) + "-" + getMonth(publishDate) + "-01"; } SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); Date utilDate = sdf.parse(datestr); java.sql.Date date=new java.sql.Date(utilDate.getTime()); conference = theConference; paperlink=jsonObject.getString("doiLink");
-
心路历程和收获
-
前端开发
- 本来以为这一次的作业比较简单,所以决定使用原生h5,css3,jq开发,但是开发到中期的时候就意识到组件没办法共享的问题,太多冗余的代码,路径太难寻找,每一个页面对于不同路径的函数渲染也不同
- 收获
- 巩固了ajax异步请求,当data没被指定时,传递过的数据是formData,导致后端接受json数据的问题
- 对路径的再次认识,通过向头部添加?,&改变url,从而获取路径数据
-
后端开发
- 这次作业相对来说比较困难,想得太简单了,就想着用原生jsp+servlet来做就ok。做到一半之后就后悔了但是也没有办法,只能迎着头皮做下去。在以后的项目开发中会去学习相关框架并选择框架去完成。但其实也算是巩固了基础知识了吧,会为以后的学习提供助力。
- 收获
- 巩固java web 、数据库 和Json 相关知识,为以后java框架学习打好了基础。
- 第一次完成完整的前后端web项目,获得了前后端合作的相关经验,如局域网对接,PostMan对接数据测试等
- 对web端http有了更深一步的认识。
评价结对队友
-
yabi
每一天都过得很充实,感觉自己的计划真的被塞得满满的,挺开心的,很期待下一次合作 -
做事认真,比较负责,遇到不懂上网去查询相关的资料让我们一起去学习,去弄懂。对时间的把握比我好,在我懒时,会督促我把进度提上来,起到了监督的作用。在结对编程的过程中,认真交流态度好到问题和bug时会一起分析解决。是一个可靠的小伙伴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号