
余思波---第一次个人编程作业
| 博客班级 | 2018计算机和综合实验班 |
| 作业要求 | 作业要求 |
| 作业目标 | 进行数据采集腾讯视频《在一起》的全部评论信息并进行分析处理生成词云图,并用git上传至自己的代码库 |
| 作业源代码 | Github地址 |
| 学号 | 211814413 |
一、时间分配
| 过程 | 时间 |
| 分析题目 | 1h |
| 查找资料 | 3h |
| 编写代码 | 5h |
| 与同学讨论 | 0.75h |
二、数据采集
在看到题目时就知道是要用上学期的爬虫知识写代码,但是基础不好导致自己做起来比较困难,重新复习了一遍爬虫ajax和正则,参考了那些学习好的大佬的代码,慢慢研究勉强弄了出来。
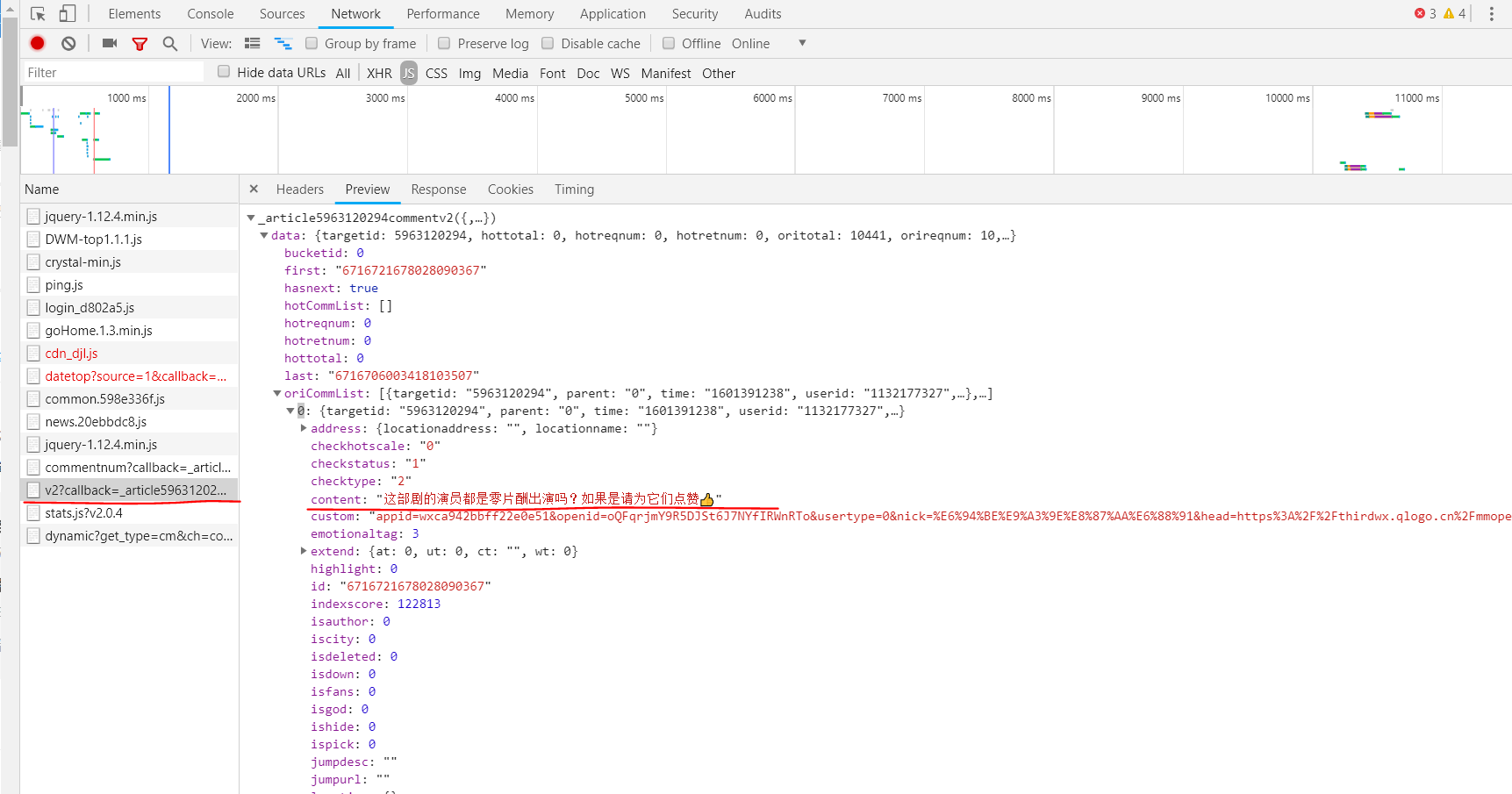 通过访问《在一起》评论页面,按下F12并重新刷新页面。
通过访问《在一起》评论页面,按下F12并重新刷新页面。
通过规律发现source的值是每次增加1,因此在代码中爬取“加载更多评论”中的代码只需要改变source的值。获取评论的方法则使用了正则表达式,并将爬取到的评论保存至本地文档。
三、数据处理
三种分词器中使用了jieba分词器进行数据处理,用easy_install jieba进行安装,在安装完成后直接import jieba导入进行使用,进行分词。

四、数据展示
对JavaScript基础也不好,借鉴别人的进行了修改,虽然基础不好但不断努力下,把处理后的数据代入后最终实现了词云图。

五、总结
基础不好,每做一步都有一步的困难,花了很多时间也还是弄不清楚的,还好最好有弄出个结果。唉,希望自己要多多努力学!
六、参考资料
GitHub创建仓库,拉取项目,提交代码,创建分支,合并分支,删除仓库以及分支
『NLP自然语言处理』中文文本的分词、去标点符号、去停用词、词性标注

 浙公网安备 33010602011771号
浙公网安备 33010602011771号