

Hadoop集群搭建
教程:http://dblab.xmu.edu.cn/blog/2441-2/
创建hadoop用户

切换到hadoop用户
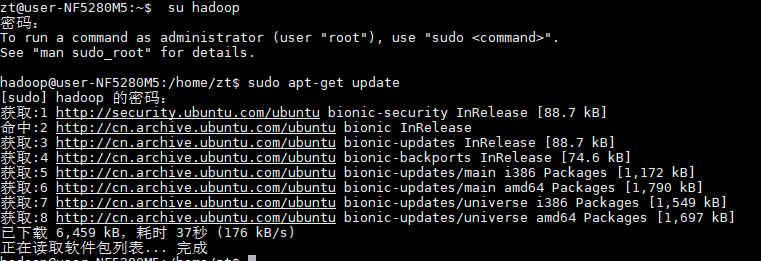
更新apt
安装vim

前面忘切换成hadoop用户,已经安装了vim,所以

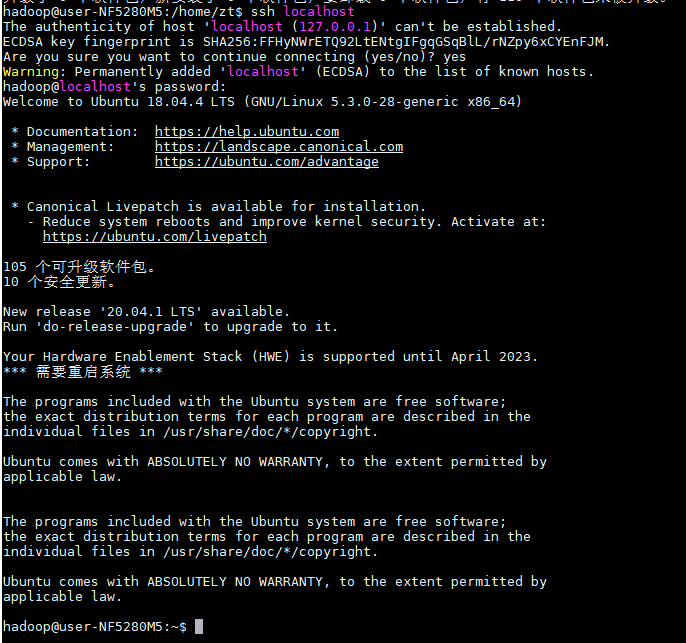
SSH登录本机
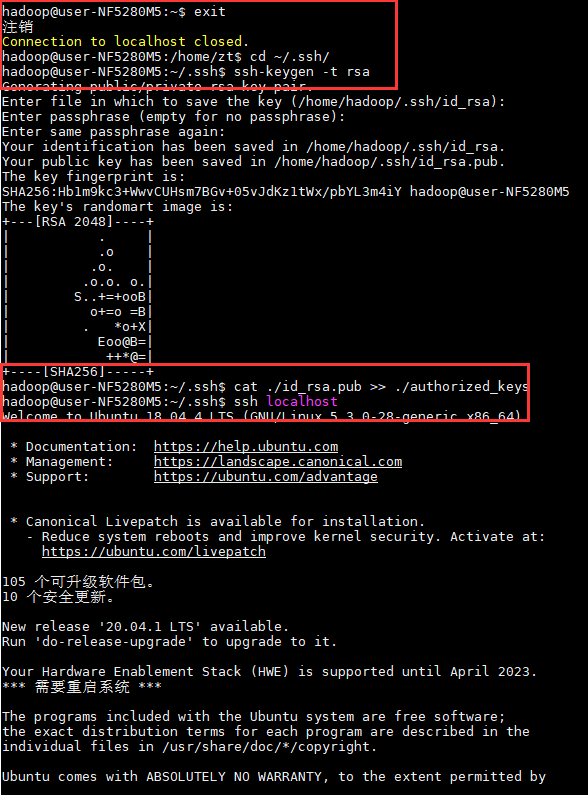
SSH配置无密码登录

安装jdk



在.bashrc文件开头添加内容


安装Hadoop


hadoop单机配置





Hadoop伪分布式配置

修改core-site.xml为如下内容


修改hdfs-site.xml为如下内容

执行 NameNode 的格式化



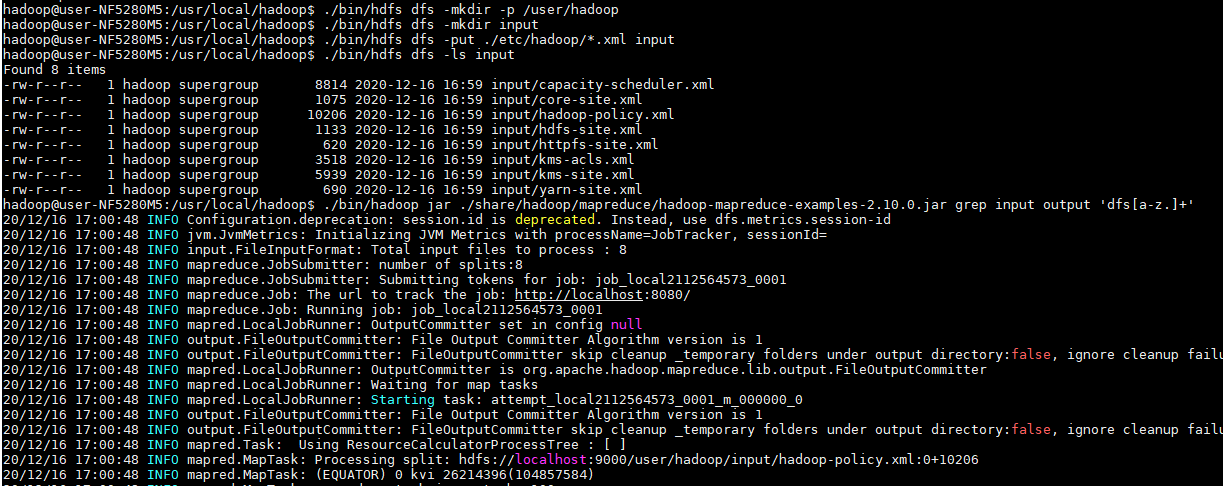
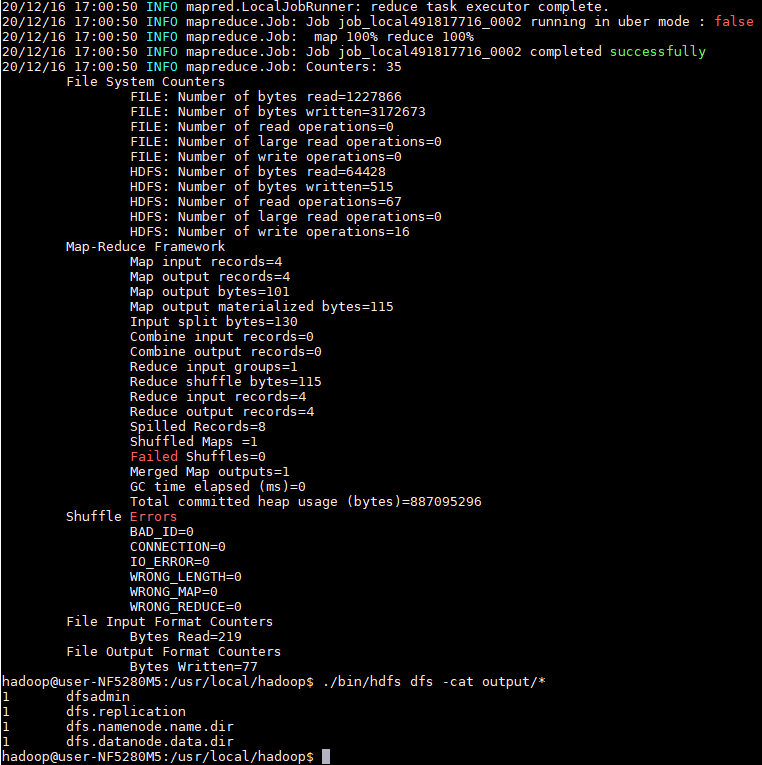
可以将结果取回到本地


Hadoop集群搭建
教程:http://dblab.xmu.edu.cn/blog/2775-2/

修改主机名,当前主机定为Master(以下其实是改过重启后的)

在其他节点上创建hadoop用户、更新apt、安装vim,然后修改主机名(依次为Slave1~3)
即分别执行以下:



分别都重启后可以观察到主机名都变化了,这里都又hadoop用户登录了
32
33 
35 
此外
34
现在再为各Slave节点安装SSH服务端、安装java(都同Master步骤,这里省略)
这时再回到Master节点在hosts文件中添加如下内容,Slave节点也要添加


然后重启各个从节点,开始ping
Master的:

Slave1的:
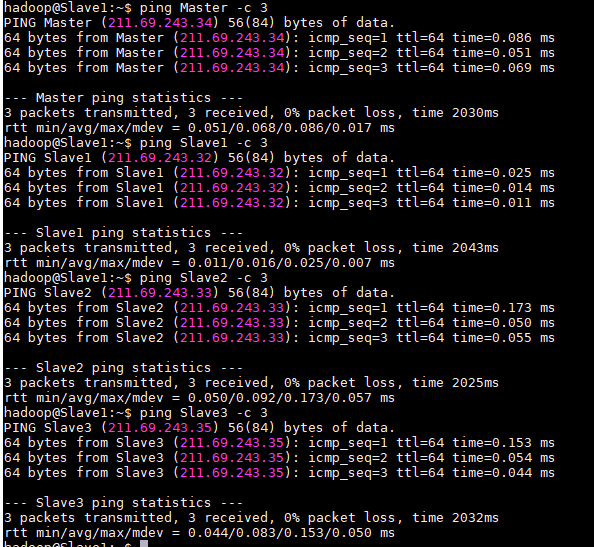
另外两个从节点也没问题,能ping通
重新为Master生成SSH免密登录公钥



在Master节点将上公匙传输到其他Slave节点
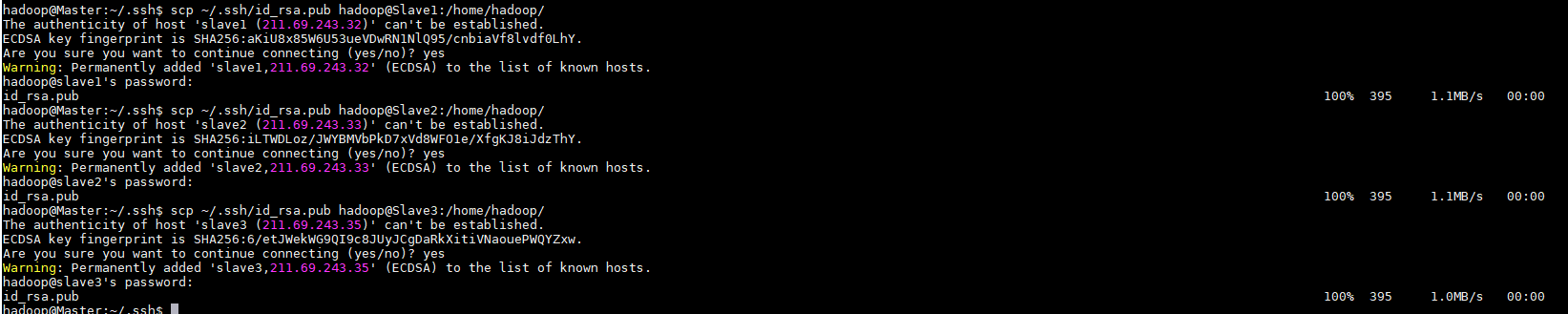
然后在各个从节点上将公钥加入授权

此时Master节点就可以免密登入Slave节点了

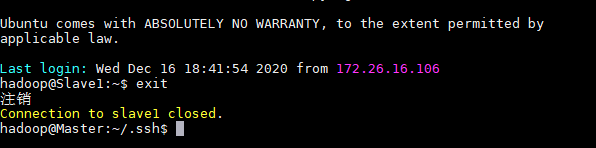
修改/usr/local/hadoop/etc/hadoop文件夹下各文件内容:
(1)slaves
注意这里hadoop3.0后slaves文件才更名为workers

在slaves中添加内容
(2)


(3)

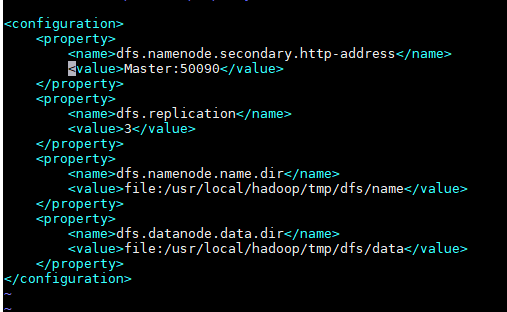
(4)

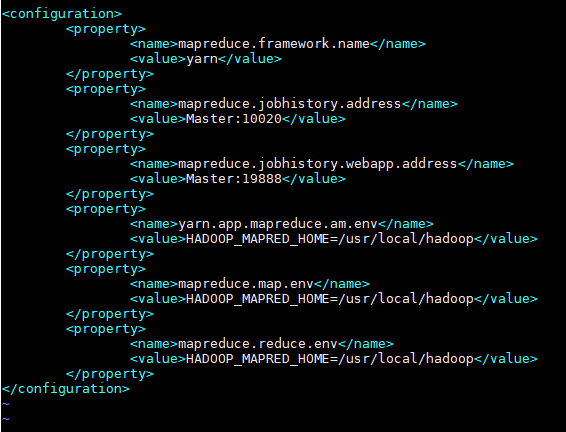
(5)

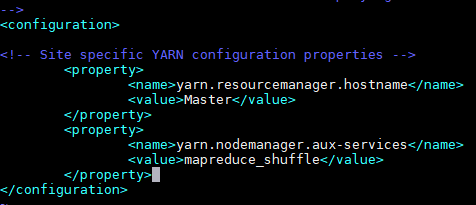
清除伪分布式下产生的临时文件,然后将Master节点上的“/usr/local/hadoop”文件夹复制到各个节点上

然后从节点上如下操作:

现在在Master节点上仅执行一次名称节点的格式化,以后不需再次操作
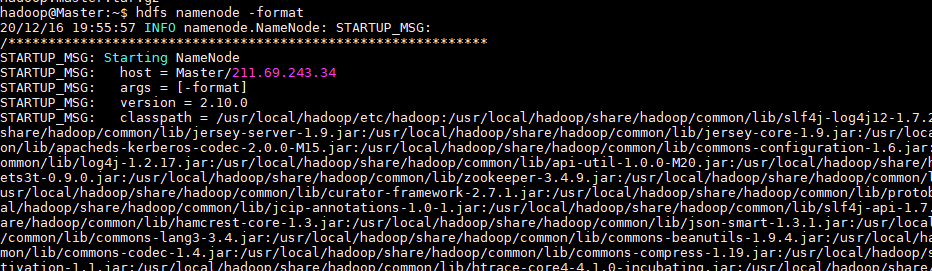

Master节点上启动!

Slave节点上



执行分布式实例


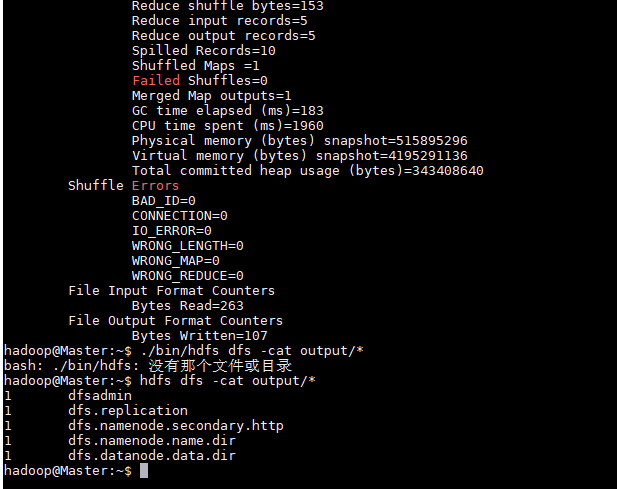
至此,顺利完成了Hadoop 集群搭建!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号