
爬取网易云研究评论与排名的联系
一.选题背景
随着物质生活的不断提高,人们对于精神生活的需求与日剧增,而音乐就是一类门槛较低,且能够满足大部分人的需求的精神食粮,同时也能在一定程度上缓和人们的心情,是比较廉价的发泄途径,所以我想通过爬虫爬取当下的音乐热门软件网易云来了解歌曲的火热程度与评论的人数是否有关。
(二)、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称
爬取网易云音乐研究评论与排名的联系
2.主题式网络爬虫爬取的内容与数据特征分析
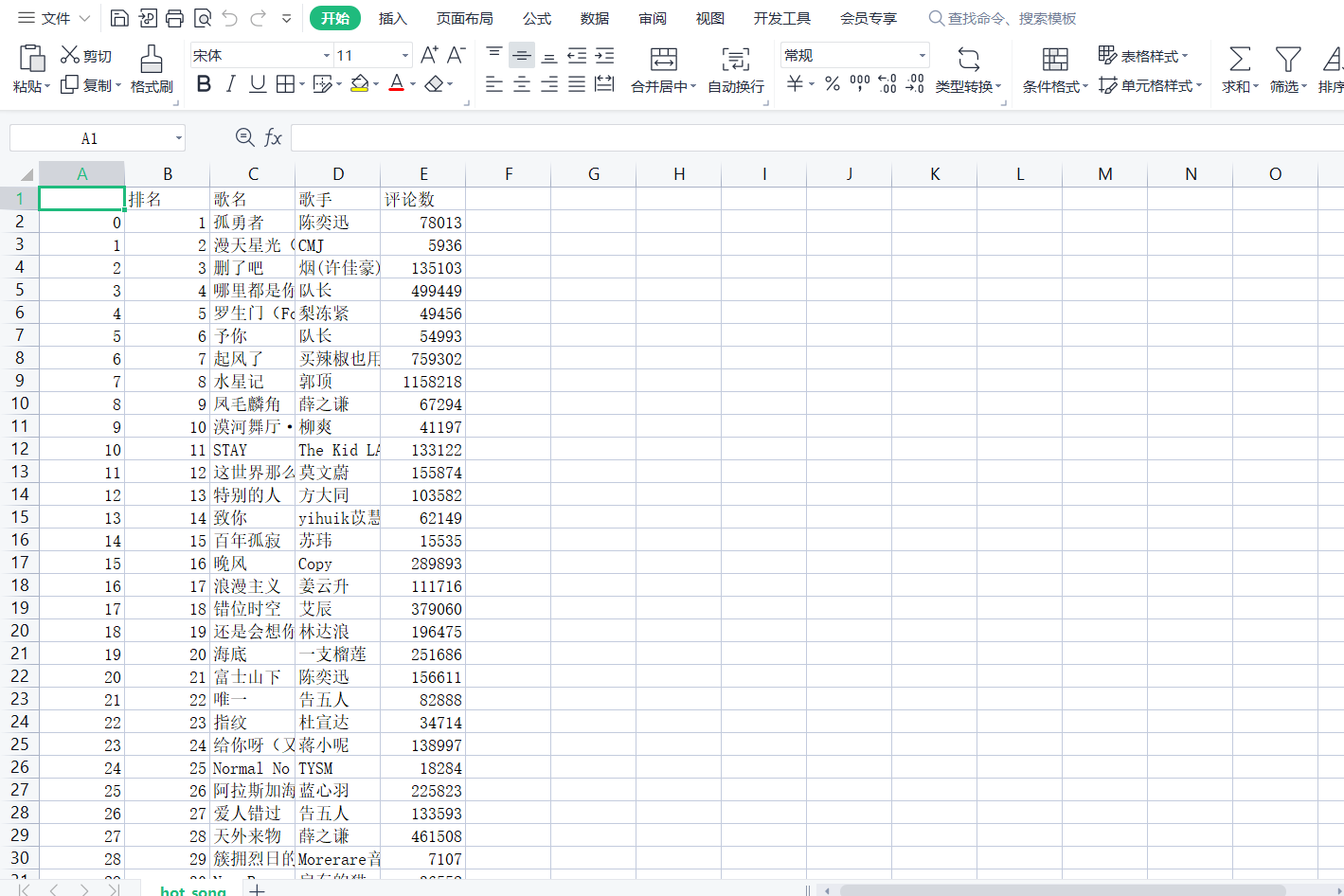
对网易云音乐的‘热歌榜的歌曲名字’,’歌曲id‘,’歌手‘,’评论数‘进行爬取
3主题式网络爬虫设计方案概述(包括实现思路与技术难点)
首先锁定网易云热歌榜页面的网址进行爬取,再而解析HTM从底部发现一个’textarea‘的文件,仔细观察可以轻松获取歌曲名字’,’歌曲id‘,’歌手‘的信息,但网易云音乐对评论这一方面进行了加密,参考网上教程,动用页面工具在歌曲页面点击’network‘观察捕获文件的头结构可以发现一个get?csrf_token=’的网址存放我们需要的评论信息,在头结构页面的最下方可以发现’params‘,’encSecKey‘,这里存放评论信息与密匙,获取评论信息需要在访问网址的基础上同时输出信息包与密匙,回头观察’textarea‘文件每个歌曲信息都包含R_SO_4_+歌曲id的信息,经过多次试错,确定这是包含了评论信息的网址,将得到的信息与get?csrf_token=’的网址结合得到https://music.163.com/weapi/v1/resource/comments/+歌曲id,我们就可以爬取网易云的评论信息,最后整理爬取到的数据,随机抽出5个连续的数据来实现数据可视化,建立回归方程,保存数据。
主要技术难点:在于网易云页面的嵌套结构,不能直接通过访问网址获取数据,需要解密信息。
三、主题页面的结构特征分析(10 分
1从该页面分析大致分为两个方面,我们所需要的信息主要位于右边,打开源代码是在tbody标签下<li><a标签下找到歌曲id,歌手,歌名

2Htmls页面解析
可以从<div id='toplist' class='g-bd3 g-bd3-1 f-cb''>中获取所需的信息,每首歌就在tr id的标签中
3节点(标签)查找方法与遍历方法
在<textarea下我们很容易发现歌手在artist的列表中,歌曲id与歌曲名字在alia的列表中,评论信息在alias的表中commentThreaId里,find()遍历文档,以txt方式输出

四、网络爬虫程序设计
1数据爬取
1 1 import numpy as np 2 2 import pandas as pd 3 3 import requests 4 4 from bs4 import BeautifulSoup 5 5 import re 6 6 import json 7 7 import csv 8 8 import seaborn as sns 9 9 import random 10 10 import matplotlib.pyplot as plt 11 11 from sklearn.linear_model import LinearRegression 12 12 import sklearn 13 13 #数据爬取与采集 14 14 headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'} 15 15 url='https://music.163.com/discover/toplist?id=3778678' 16 16 #获取网页页面数据 17 17 18 18 response=requests.get(url=url,headers=headers,timeout=60) 19 19 #发送请求到网站,请求时间为60秒,超过60秒出现异常 20 20 response.raise_for_status() 21 21 #异常捕捉 22 22 response.encoding='utf-8' 23 23 #设置编码标准 24 24 html=response.text 25 25 soup = BeautifulSoup(html,'lxml') 26 26 textarea =soup.find('textarea').text 27 27 #解析页面 28 28 contents = json.loads(str(textarea)) 29 29 #将字符串转为字典 30 30 31 31 32 32 w=1 33 33 lst=[] 34 34 #建立空表 35 35 for i in range(len(contents)): 36 36 singer=[] 37 37 singer=contents[i].get('artists')[0].get('name') 38 38 #歌手名字 39 39 40 40 name=[] 41 41 name=contents[i].get('name') 42 42 #歌曲名字 43 43 id={} 44 44 id=str(contents[i].get('commentThreadId')) 45 45 #歌曲id 46 46 rank=[] 47 47 rank=str(w) 48 48 #排名 49 49 w+=1 50 50 url="https://music.163.com/weapi/v1/resource/comments/"+id 51 51 #获取网页页面数据 52 52 53 53 data={'params': 'h2KS/Y5IWQDGBwP67egpLFFeNoo6Xmlyy7Qsu53K99IHVdhUEWjtMHc5w1IqTrwFHZwmmRVnftWc7IDgKsOhAB3gvGJ6AHiXEccVCD3Yl+8kI2gfG+431wjxnaCr0Gn5QXH37F1QVhfmVoL3N+JVFhKJZe1ICuUJr2T2ahMQnjKS2N2quhSC78pKia3ZUNdIw4gJvTOMafItddvEO+ynq8QmypkEkBIuw+sMnFgQ6BD0u8m+suBm0SnxawTF1qKvMyYxIHG+Mjz/Yw2sqhkxeydjomnVEY+xV4ykHiSJN9Y=', 54 54 'encSecKey':'37810937d3b5e1293bf10bdb4ebe70862abb9dc1fa83ca243bd2b2a33870be4d67a1cec6b8cc97aae836f7fe898c7b37b70e282b24c09f138eb9d38ce4123e49a9fcc5d9dc4616d4d6d4b1a5bd37270481a23258c99cb993b0123757f81e4838465867a4033ebc9b9c5bb524e1cc84c10e6c5feef3a2e428a6a965d39a0813d7' 55 55 56 56 } 57 57 #获取评论的信息 58 58 response=requests.post(url=url,headers=headers,data=data,timeout=60) 59 59 #发送请求到网站,请求时间为60秒,超过60秒出现异常 60 60 response.raise_for_status() 61 61 #异常捕捉 62 62 response.encoding='utf-8' 63 63 comment_count=[] 64 64 html=response.text 65 65 comment=json.loads(html) 66 66 comment_count=comment['total'] 67 67 #获取评论 68 68 lst.append([rank,name,singer,comment_count]) 69 69 #将获取的数据加入表中 70 70 df = pd.DataFrame(lst,columns=['排名','歌名','歌手','评论数']) 71 71 #以DataFrame的方式存储表 72 72 data=r'hot_song.csv' 73 73 74 74 df.to_csv(data) 75 75 #保存文件
2数据处理
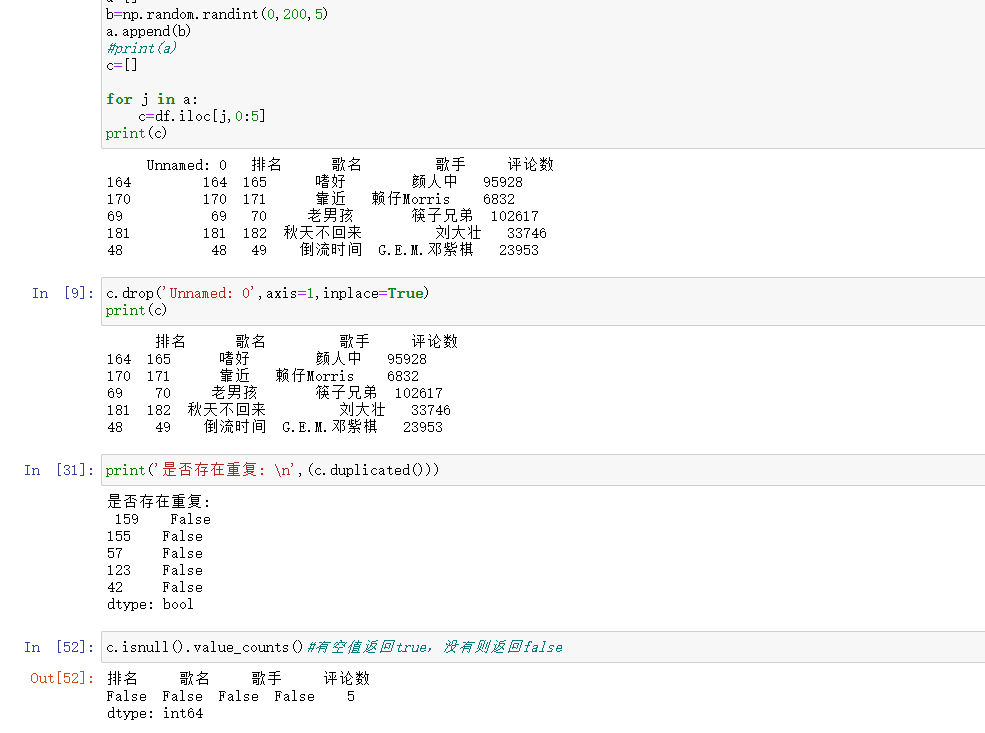
1 1 df=pd.read_csv('hot_song.csv') 2 2 77 77 #读取文件 3 3 78 78 a=[] 4 4 79 79 b=np.random.randint(0,200,5) 5 5 80 80 a.append(b) 6 6 81 81
7 7 82 82 c=[] 8 8 83 83 9 9 84 84 for j in a: 10 10 85 85 c=df.iloc[j,0:5] 11 11 86 86 #读取数据后创造列表a,c,设置b输出随机5个数放进列表a,将j放进a中循环,确定随机五个数的位置 12 12 87 87 c.drop('Unnamed: 0',axis=1,inplace=True) 13 13 88 88 #删除无效列 14 14 89 89 print(c) 15 15 90 90 print('是否存在重复: \n',(c.duplicated())) 16 16 91 91 #有空值返回true,没有则返回false 17 19 94 94 c.isnull().value_counts() 18 20 95 95 #有空值返回true,没有则返回false
3数据可视化
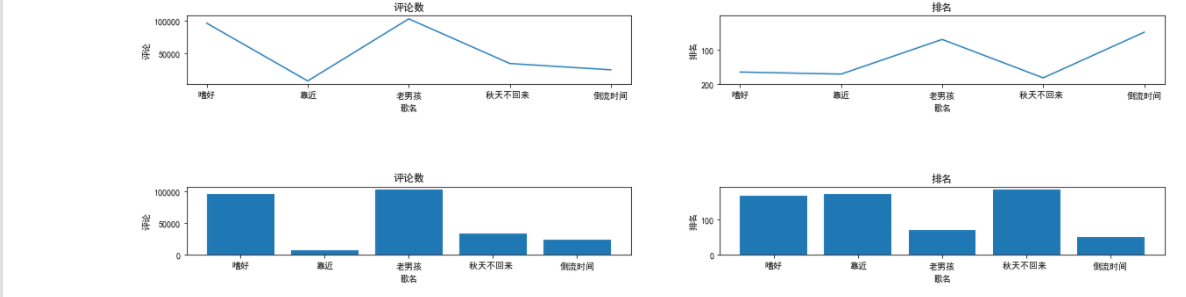
1 plt.rcParams['font.sans-serif']=['SimHei'] 2 #读取汉字 3 plt.rcParams['axes.unicode_minus']=False 4 5 x1=c['歌名'] 6 y1=c['评论数'] 7 x2=c['歌名'] 8 y2=c['排名'] 9 #输入变量 10 plt.figure(figsize=(20,5)) 11 #创建figure对象,宽20英寸宽高5英寸 12 #绘制子图一 13 plt.subplot(1,2,1) 14 #绘制在2×2区域的第一个位置 15 plt.plot(x1,y1) 16 #绘制曲线图 17 plt.ylabel("评论") 18 #命名Y轴 19 plt.xlabel('歌名') 20 #命名X轴 21 #绘制子图二 22 plt.subplot(1,2,2) 23 plt.ylim(200,1) 24 #规定Y轴的范围 25 plt.ylabel("排名") 26 plt.xlabel('歌名') 27 plt.plot(x2,y2) 28 #绘制子图三 29 plt.subplot(2,2,3) 30 plt.subplots_adjust(hspace=1.5) 31 #设置子图上下的距离 32 plt.title('评论数') 33 plt.bar(x1,y1) 34 #绘制柱形图 35 plt.ylabel("评论") 36 plt.xlabel('歌名') 37 #绘制子图四 38 plt.subplot(2,2,4) 39 plt.subplots_adjust(hspace=1.5) 40 plt.title('排名') 41 plt.bar(x2,y2) 42 plt.ylabel("排名") 43 plt.xlabel('歌名') 44 plt.show()
4回归方程
1 #回归方程 2 3 predict_model=LinearRegression() 4 x=c[['评论数']] 5 predict_model.fit(x,c['排名']) 6 print('斜率:',format(predict_model.coef_)) 7 print('截距:',format(predict_model.intercept_)) 8 def f(x): 9 return float(predict_model.coef_)*x+predict_model.intercept_ 10 print(f'线下回归方程是:y={float(predict_model.coef_)}*x+{predict_model.intercept_}') 11 #散点图 12 import seaborn as sns 13 plt.scatter(c['排名'],c['评论数'])

5数据持久化
1 data=r'随机抽取连续的五首歌曲.csv' 2 c.to_csv(data) 3 #保存为csv文件

全部代码
1 import numpy as np 2 2 import pandas as pd 3 3 import requests 4 4 from bs4 import BeautifulSoup 5 5 import re 6 6 import json 7 7 import csv 8 8 import seaborn as sns 9 9 import random 10 10 import matplotlib.pyplot as plt 11 11 from sklearn.linear_model import LinearRegression 12 12 import sklearn 13 13 #数据爬取与采集 14 14 headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'} 15 15 url='https://music.163.com/discover/toplist?id=3778678' 16 16 #获取网页页面数据 17 17 18 18 response=requests.get(url=url,headers=headers,timeout=60) 19 19 #发送请求到网站,请求时间为60秒,超过60秒出现异常 20 20 response.raise_for_status() 21 21 #异常捕捉 22 22 response.encoding='utf-8' 23 23 #设置编码标准 24 24 html=response.text 25 25 soup = BeautifulSoup(html,'lxml') 26 26 textarea =soup.find('textarea').text 27 27 #解析页面 28 28 contents = json.loads(str(textarea)) 29 29 #将字符串转为字典 30 30 31 31 32 32 w=1 33 33 lst=[] 34 34 #建立空表 35 35 for i in range(len(contents)): 36 36 singer=[] 37 37 singer=contents[i].get('artists')[0].get('name') 38 38 #歌手名字 39 39 40 40 name=[] 41 41 name=contents[i].get('name') 42 42 #歌曲名字 43 43 id={} 44 44 id=str(contents[i].get('commentThreadId')) 45 45 #歌曲id 46 46 rank=[] 47 47 rank=str(w) 48 48 #排名 49 49 w+=1 50 50 url="https://music.163.com/weapi/v1/resource/comments/"+id 51 51 #获取网页页面数据 52 52 53 53 data={'params': 'h2KS/Y5IWQDGBwP67egpLFFeNoo6Xmlyy7Qsu53K99IHVdhUEWjtMHc5w1IqTrwFHZwmmRVnftWc7IDgKsOhAB3gvGJ6AHiXEccVCD3Yl+8kI2gfG+431wjxnaCr0Gn5QXH37F1QVhfmVoL3N+JVFhKJZe1ICuUJr2T2ahMQnjKS2N2quhSC78pKia3ZUNdIw4gJvTOMafItddvEO+ynq8QmypkEkBIuw+sMnFgQ6BD0u8m+suBm0SnxawTF1qKvMyYxIHG+Mjz/Yw2sqhkxeydjomnVEY+xV4ykHiSJN9Y=', 54 54 'encSecKey':'37810937d3b5e1293bf10bdb4ebe70862abb9dc1fa83ca243bd2b2a33870be4d67a1cec6b8cc97aae836f7fe898c7b37b70e282b24c09f138eb9d38ce4123e49a9fcc5d9dc4616d4d6d4b1a5bd37270481a23258c99cb993b0123757f81e4838465867a4033ebc9b9c5bb524e1cc84c10e6c5feef3a2e428a6a965d39a0813d7' 55 55 56 56 } 57 57 #获取评论的信息 58 58 response=requests.post(url=url,headers=headers,data=data,timeout=60) 59 59 #发送请求到网站,请求时间为60秒,超过60秒出现异常 60 60 response.raise_for_status() 61 61 #异常捕捉 62 62 response.encoding='utf-8' 63 63 comment_count=[] 64 64 html=response.text 65 65 comment=json.loads(html) 66 66 comment_count=comment['total'] 67 67 #获取评论 68 68 lst.append([rank,name,singer,comment_count]) 69 69 #将获取的数据加入表中 70 70 df = pd.DataFrame(lst,columns=['排名','歌名','歌手','评论数']) 71 71 #以DataFrame的方式存储表 72 72 data=r'hot_song.csv' 73 73 74 74 df.to_csv(data) 75 75 #数据处理 76 76 df=pd.read_csv('hot_song.csv') 77 77 #读取文件 78 78 a=[] 79 79 b=np.random.randint(0,200,5) 80 80 a.append(b) 81 81 82 82 c=[] 83 83 84 84 for j in a: 85 85 c=df.iloc[j,0:5] 86 86 #读取数据后创造列表a,c,设置b输出随机5个数放进列表a,将j放进a中循环,确定随机五个数的位置 87 87 c.drop('Unnamed: 0',axis=1,inplace=True) 88 88 #删除无效列 89 89 print(c) 90 90 print('是否存在重复: \n',(c.duplicated())) 91 91 #有空值返回true,没有则返回false 92 92 print('是否有空值:\n',(df.duplicated())) 93 93 #有空值返回true,没有则返回false 94 94 c.isnull().value_counts() 95 95 #有空值返回true,没有则返回false 96 96 #数据可视化 97 97 plt.rcParams['font.sans-serif']=['SimHei'] 98 98 #读取汉字 99 99 plt.rcParams['axes.unicode_minus']=False 100 100 101 101 x1=c['歌名'] 102 102 y1=c['评论数'] 103 103 x2=c['歌名'] 104 104 y2=c['排名'] 105 105 #输入变量 106 106 plt.figure(figsize=(20,5)) 107 107 #创建figure对象,宽20英寸宽高5英寸 108 108 #绘制子图一 109 109 plt.subplot(1,2,1) 110 110 #绘制在2×2区域的第一个位置 111 111 plt.plot(x1,y1) 112 112 #绘制曲线图 113 113 plt.ylabel("评论") 114 114 #命名Y轴 115 115 plt.xlabel('歌名') 116 116 #命名X轴 117 117 #绘制子图二 118 118 plt.subplot(1,2,2) 119 119 plt.ylim(200,1) 120 120 #规定Y轴的范围 121 121 plt.ylabel("排名") 122 122 plt.xlabel('歌名') 123 123 plt.plot(x2,y2) 124 124 #绘制子图三 125 125 plt.subplot(2,2,3) 126 126 plt.subplots_adjust(hspace=1.5) 127 127 #设置子图上下的距离 128 128 plt.title('评论数') 129 129 plt.bar(x1,y1) 130 130 #绘制柱形图 131 131 plt.ylabel("评论") 132 132 plt.xlabel('歌名') 133 133 #绘制子图四 134 134 plt.subplot(2,2,4) 135 135 plt.subplots_adjust(hspace=1.5) 136 136 plt.title('排名') 137 137 plt.bar(x2,y2) 138 138 plt.ylabel("排名") 139 139 plt.xlabel('歌名') 140 140 plt.show() 141 141 #回归方程 142 142 predict_model=LinearRegression() 143 143 #建立模型 144 144 x=c[['评论数']] 145 145 predict_model.fit(x,c['排名']) 146 146 #现在评论数和排名两个特征变量,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 147 147 print('斜率:',format(predict_model.coef_)) 148 148 print('截距:',format(predict_model.intercept_)) 149 149 #训练模型 150 150 def f(x): 151 151 return float(predict_model.coef_)*x+predict_model.intercept_ 152 152 print(f'线下回归方程是:y={float(predict_model.coef_)}*x+{predict_model.intercept_}') 153 153 #判断相关性 154 154 #散点图 155 155 156 156 plt.scatter(c['排名'],c['评论数']) 157 157 #绘制散点图 158 158 #数据持久化 159 159 data=r'随机抽取连续的五首歌曲.csv' 160 160 c.to_csv(data) 161 161 #保存为csv文件
五、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
评论的数量与排名直接相关联,同期的热歌之间排名则由评论数量决定,达到预期目标,但数据并不准确。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
在完成此设计的过程,我学到了很多,无论是网页的解析还是整体的思路都得到了很大的改善,尤其是学会了耐心,在完成设计的这段时间,代码报错,越改越错已是家常便饭,让我逐渐从开始的焦虑到坦然接受显示,通过各种途径去修改代码,而且在设计过程中我也参考了网上的一些教程,从中发现了自己很多的缺漏,并且给了我一些全新的思路。由于我设计经验不足,在初始制定爬取计划并不完善,比如我忽略了时间这个特殊变量,不是同一时期的热歌评论数与排名关联并不大,一些经典老歌虽然排名没有新出的热歌排名高,但评论数量远远高于新出的热歌,所以可以增加爬取时间节点来改进代码,抽取同一时间的随机热歌,保证数据的准确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号