pytest参数化 ids 描述为中文时控制台显示unicode 编码
一、背景
在pytest.mark.parametrize参数时,使用id或ids描述用例时,控制台会以unicode 编码,这是pytest框架编码问题导致,只需要重新编码即可。
二、问题实列
从截图可以看出编码为unicode 编码
import random
import pytest
def login(username, password):
'''登录'''
return {"code": 200, "msg": "success!"}
# 测试数据
datas = [
({"username": "xyz1", "password": "123456"}, "success!"),
({"username": "xyz2", "password": "123456"}, "fail!"),
({"username": "xyz3", "password": "123456"}, "success!"),
]
class TestMyCode:
@pytest.mark.parametrize("input,expected", datas, ids=[
"输入正确账号,密码,登录成功",
"输入错误账号,密码,登录失败",
"输入正确账号,密码,登录成功",
])
def test_login(self, input, expected):
"""测试登录用例"""
result = login(input["username"], input["password"])
assert result["msg"] == expected
@pytest.mark.parametrize("expected", [
pytest.param(1, id="用例 1"),
pytest.param(2, id="用例 2"),
pytest.param(3, id="用例 3")
])
def test_parametrize(self, expected):
"""
测试用例的ID用来描述测试用例简洁概括的文字,
可以让人快速理解测试用例的基本意图
"""
print("自动搜索test开头的测试函数")
assert random.randrange(10) >= expected
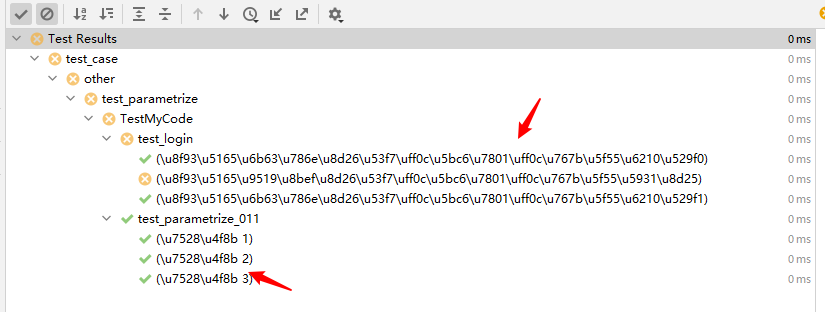
三、重新编码
在项目中写个 conftest.py 文件,加以下hook方法pytest_collection_modifyitems
def pytest_collection_modifyitems(session, config, items):
"""用例描述为中文时修改unicode编码"""
items.reverse() #修改用例执行顺序
for item in items:
item.name = item.name.encode("utf-8").decode("unicode_escape")
print(item.nodeid)
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
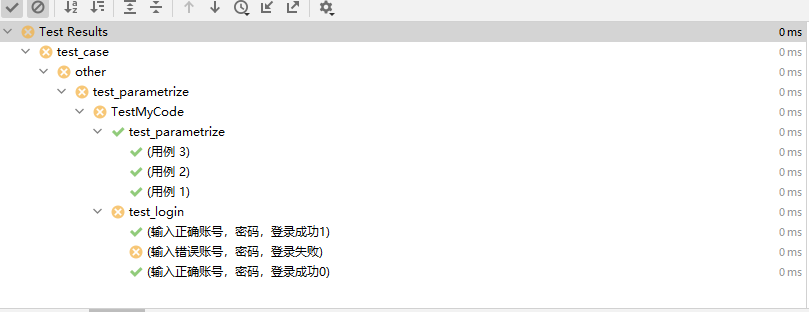
所以,在hook方法pytest_collection_modifyitems中不仅可以修改编码,还可以调整用例执行顺序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号