

突击训练第一季(一)消息队列
1.你在系统里面用过消息队列吗?那你说一下你们在项目中是怎么用消息队列的?那你们为什么要用消息队列啊?
先说一下消息队列的常见使用场景吧,其实场景有很多,但是比较核心的有3个:解耦,异步,消峰
1.1 解耦:
A系统发送个数据到BCD三个系统,接口调用发送,那如果E系统也要这个数据呢?那如果C系统现在不需要了呢?现在A系统有要发送第二种数据了呢?A系统负责人濒临奔溃中。。。A系统要时时刻刻考虑BCDE四个系统如果挂了咋办?我要不要重发?我要不要吧消息存起来?头发都白了啊。。。
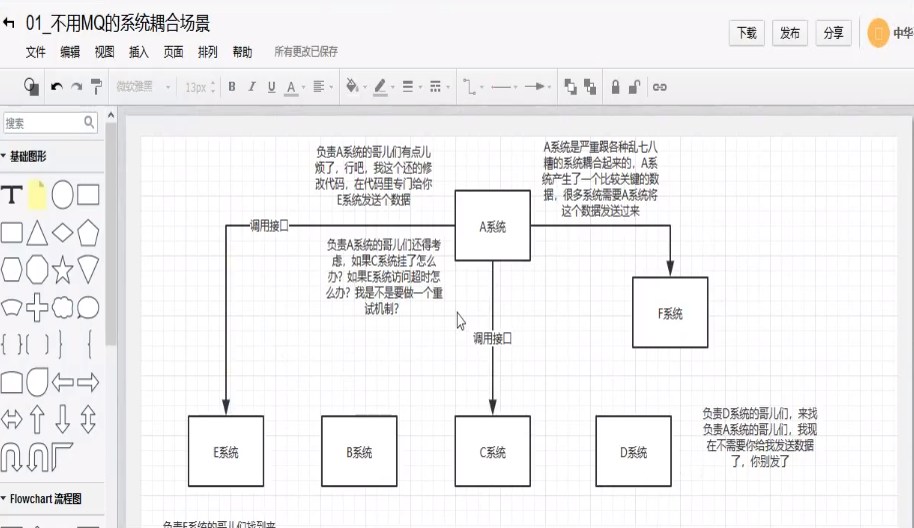
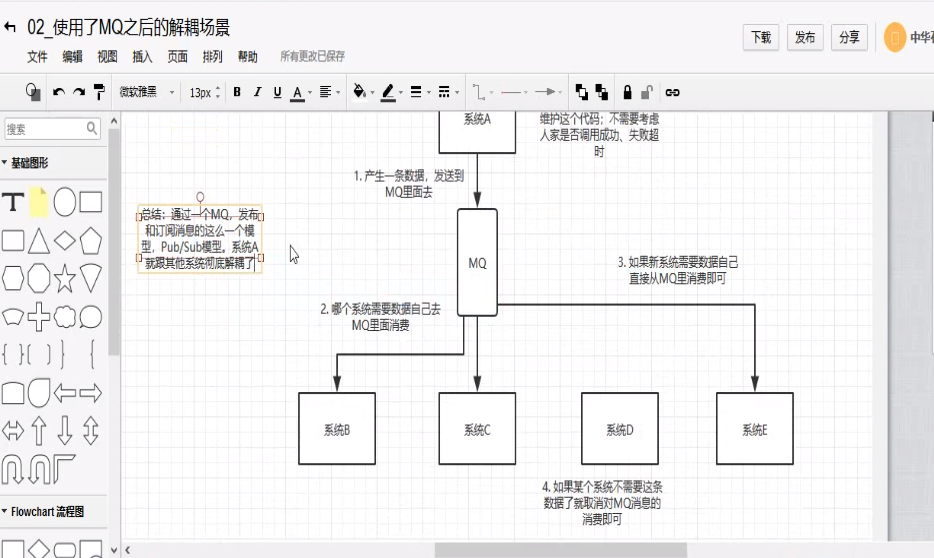
面试技巧:你需要去考虑一下,你负责的系统中是否有类似的场景,就是一个系统或者要给模块,调用了多个系统或者模块,相互之间的调用很复杂,维护起来很麻烦。电视其实这个调用是不需要直接同步调用的接口的,如果用MQ给他异步化解耦,也是可以的,你就需要去考虑再你的项目里,是不是可以运用这个MQ去进行系统的解耦。
1.2 异步:
A系统接收一个请求,需要再自己本地写库,还需要再BCD三个系统写库,自己本地写库要3ms,BCD三个系统分别写库要300ms,450ms,200ms。最终请求总延时是3+300+450+200=953ms,接近1s,那用户感觉搞个什么东西,慢死了慢死了哦
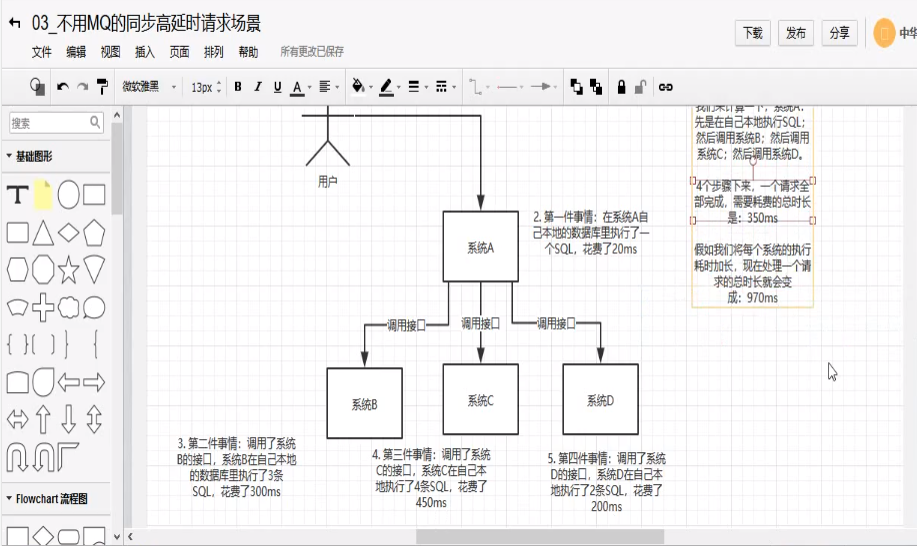
ps:一般互联网类的企业,对用户的直接的操作,一般要求是每个请求都必须再200ms以内完成,对用户几乎是无感知的。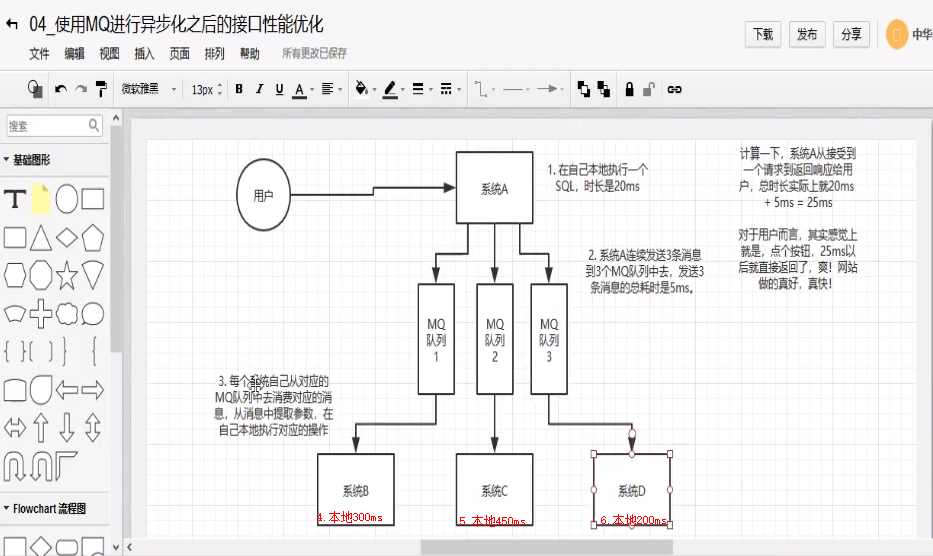
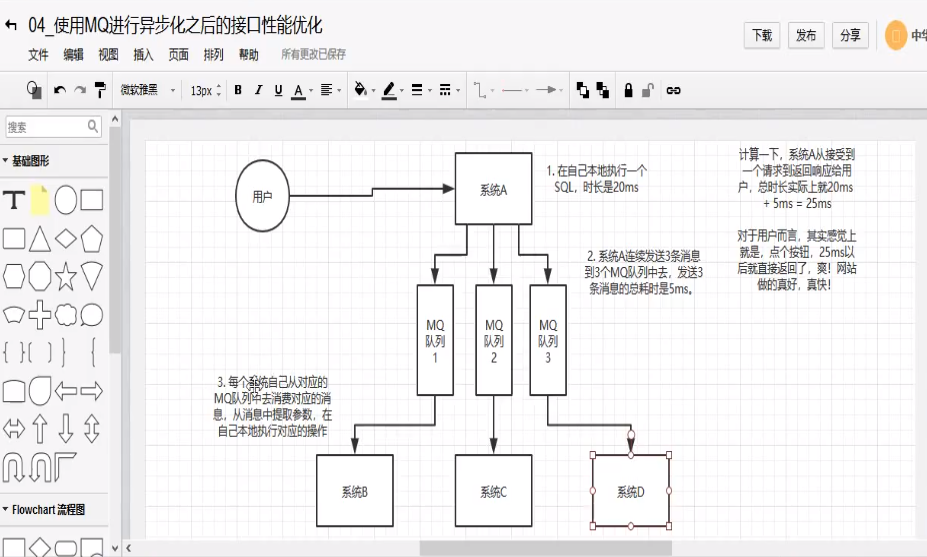
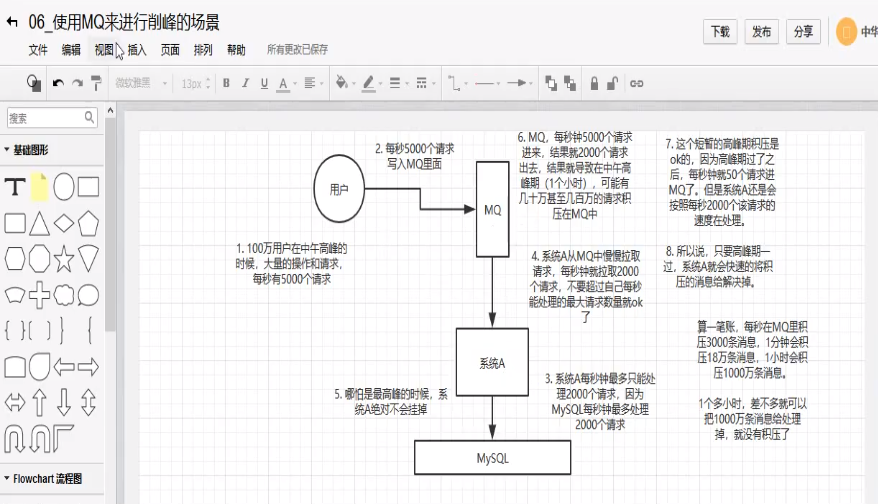
1.3 消峰:
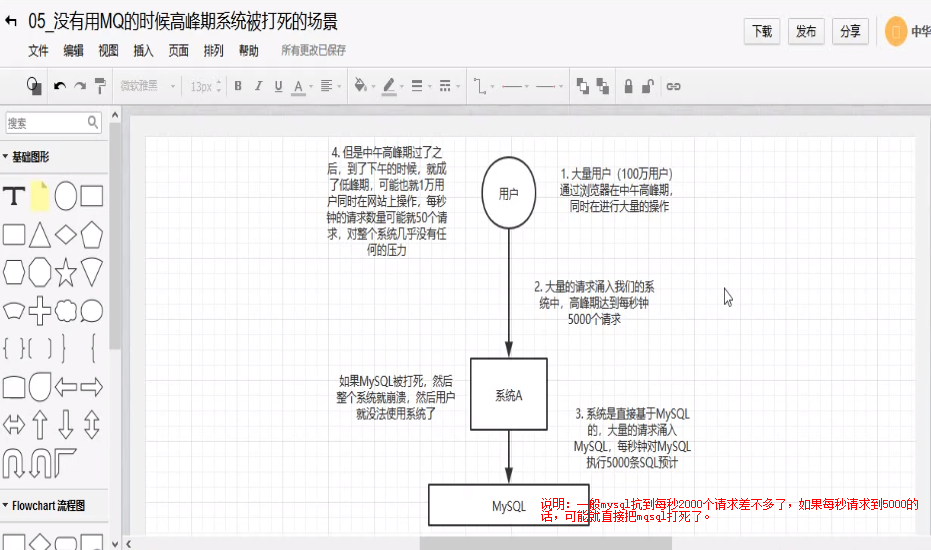
每天0点到11点,A系统风平浪静,每秒并发请求数量就100个。结构每一次一到11点--1点,每秒并发请求数量突然会暴增长到1万条。但是系统最大的处理能力就只能是每秒钟处理1000个请求啊。。。尴尬了,系统会死球的。。
2.那你说说用消息队列都有什么优点和缺点?
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦,异步,削峰
缺点?显而易见
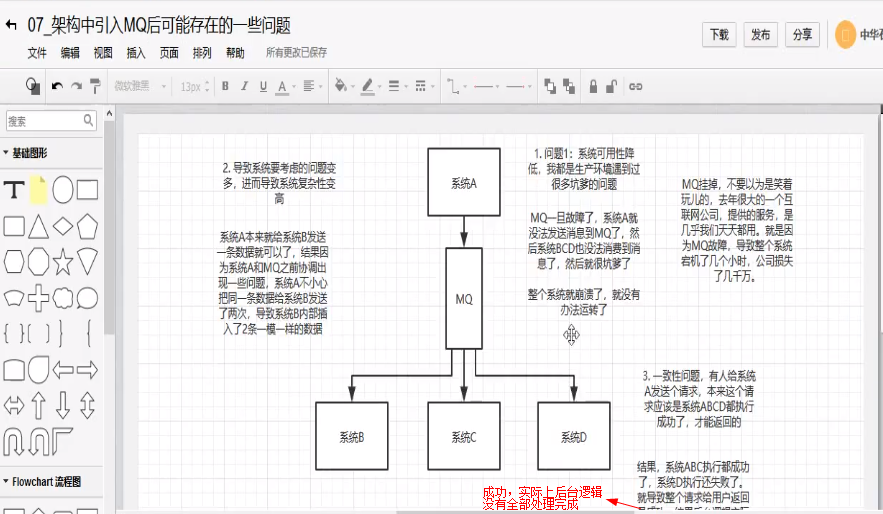
(1) 系统可用性降低:
系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,ABCD四个系统正常运行,现在加入了一个MQ进来,万一MQ挂了咋办?MQ挂了,整套系统就奔溃了。
(2) 系统复杂性提高:
加入了MQ进来,怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?等一系统问题需要处理。
(3) 一致性问题:
A系统处理完了直接返回成功了,人都以为你这个请求成功了;但问题是,要是BCD系统,某两个成功了,一个失败了,咋办?最后导致的就是数据不一致了。
3. kafka,activemq,rabbitmq,rocketmq都有什么优点和缺点啊?
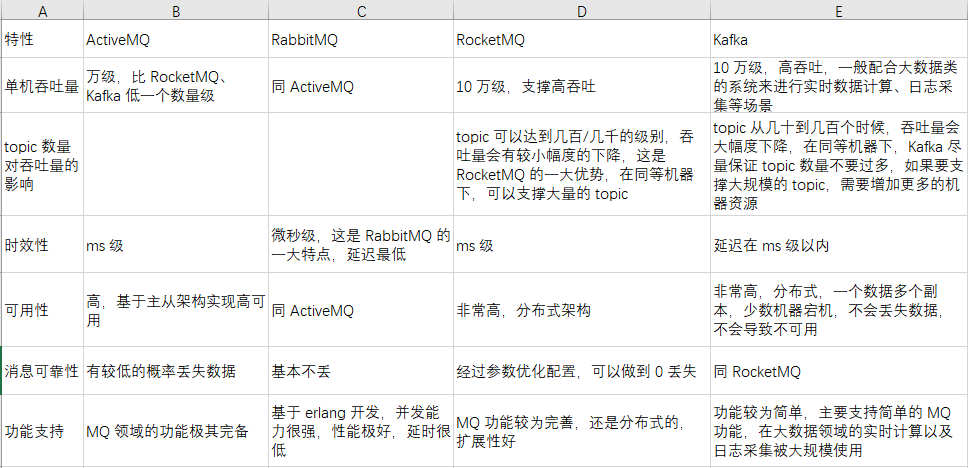
综上,各种对比之后,有如下建议:
一般的业务系统要引入 MQ,最早大家都用 ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了;
后来大家开始用 RabbitMQ,但是确实 erlang 语言阻止了大量的 Java 工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也高;
不过现在确实越来越多的公司,会去用 RocketMQ,确实很不错(阿里出品),但社区可能有突然黄掉的风险,对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃的开源社区,绝对不会黄。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
4. 那你们是如果保证消息队列的高可用啊?
4.1 rabbitMQ的高可用
rabbitmq是比较有代表性的,因为是基于主从做高可用性的,我们就以他为例子:
rabbitmq有三种模式:单机模式,普通集群模式,镜像集群模式
(1) 单机模式:
就是demo级别的,一般就是本地启动随便玩玩。
(2) 普通集群模式:
意思就是在多台机器上启动多个rabbitmq示例,每个机器启动一个。但是你创建的queue,只会放到一个rabbitmq实例上,但每个实例都同步queue的元数据。在你消费的时候,实际上如果连接到另一个实例,那么那个实例会从queue所在实例上拉取数据过来。这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费每次随机连接一个实例,然后拉取数据,要么固定连接那个queue所在的实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放queue的实例宕机了,会导致接下来其它实例就无法从那个实例拉取,如果你开启了消息持久化,让rabbitmq落地存储消息的话,消息不一定会丢,得等到这个实例恢复了,然后才可以继续从queue拉取数据。
所以这个事情就比较尴尬了,这就没有什么所谓的高可用性可言了,该方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个queue的读写操作。
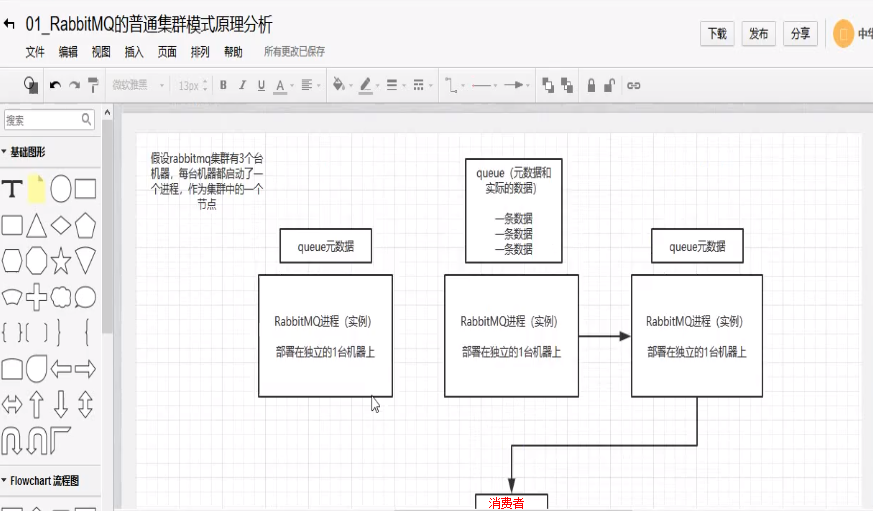
缺点:
- 可能会再rabbit集群内部产生大量的数据传输。
- 可用性几乎没有保障,如果queue所在的节点宕机了,就导致那个queue的数据会丢失,从而无法消费。
(3) 镜像集群模式:
这种模式,才是所谓的rabbitmq的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息同步到多个实例的queue里面。这样的话,好处在于,你任何一个机器宕机了,没事儿,别的机器都可以用。
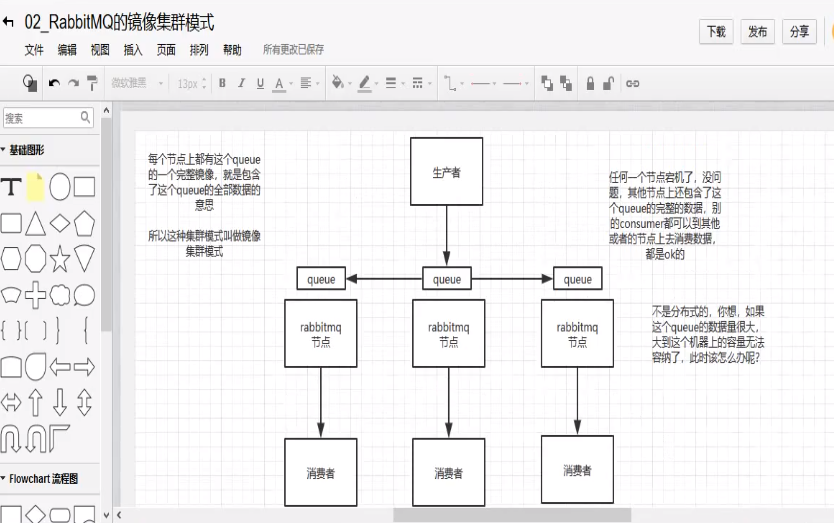
缺点:
- 第一,这个性能开销大了点,消息同步所有机器,导致网络带宽压力和消耗很重。
- 第二,这么玩,就没有扩展性可言了,如果某个queue负载很重,你得加机器,新增的机器也包含这个queue的所有数据,并没有办法线性扩展你的queue。
那么怎么开启这个镜像集群模式呢?我这里简单说一下,rabbitmq有个很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候可以要求数据同步到所有节点,也可以要求就同步到指定数量的节点,然后你再次创建queue的时候,应用这个策略,就会自动将数据同步到其它节点上去了。
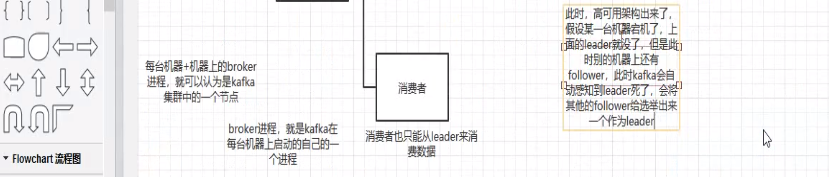
4.2 kafka的高可用
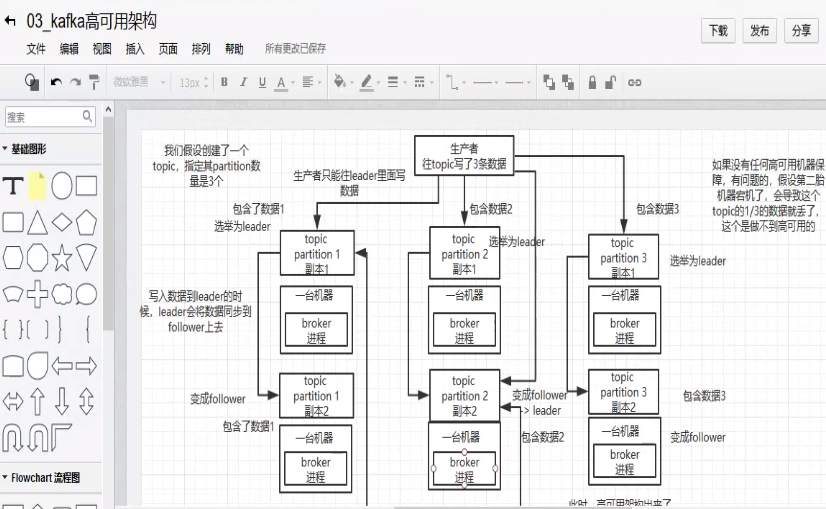
kafka一个最基本的架构认识:多个broker组成,每个broker是一个节点;你创建一个topic,这个topic可以划分多个partition,每个partition可以存在于不通的broker上,每个partition就放一部分数据。
这就是天然的分布式消息队列,就是说一个topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。
实际上rabbitmq之类的,并不是分布式消息队列,他就是传统的消息队列,只不过提供了一些集群,HA的机制而已,因为不论怎么玩,rabbitmq一个queue的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个queue的完整数据。
kafka 0.8以前是没有HA机制的,就是任何一个broker宕机了,那个broker上的partition就废了,没法写也没法读,没有什么高可用可言。
kafka 0.8以后,提供了HA机制,就是replica副本机制,每个partition的数据都会同步到其它机器上,形成自己的多个replica。然后所有replica会选举一个leader出来,那么生产和消费都跟这个leader打交道,其它replica就是follower。写的时候leader会负责把数据同步到所有follower上去,读的时候就直接读leader上数据即可。只能读写leader?很简单,要是你可以随意读写每个follower,那么就要care数据一致性的问题,系统复杂度太高,很容易出问题。kafka会均匀的将一个partition的所有replica分布再不同的机器上,这样才可以提高容错性。
这么搞,就有所谓的高可用性了,因为如果某个broker宕机了,没事儿,那个broker上面的partition在其他机器上都副本的,如果这个上面有某个partition的leader,那么此时会重新选举一个新的leader处理啊,大家继续读写那个新的leader即可。这就有所谓的高可用性了。
写数据的时候,生产者就写leader,然后leader将数据落地写入本地磁盘,接着其它follower自己主动从leader来pull数据。一旦所有follower同步好数据了,就会发送ack给leader,leader收到所有的ack之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从leader去读,但是只有一个消息已经被所有follower都同步成功返回ack的时候,这个消息才会被消费者读到。
5. 如何保证消息不被重复消费啊(如何保证消费的时候是幂(mi)等性)?
碰到着急的情况,直接kill进程了,再重启。导致comsumer有些消息处理了,有些消息没来的及处理(提交)。重启后,少数消息会再次消费。
结合业务来思考:
(1)比如拿数据要写库,先根据主键查一下,如果数据有了,就别插入了,直接更新。
(2)比如写的redis,那就没问题了,因为每次都是set,本就是具有幂等性的。
(3)上面两个都不是,可以让生产者发送每条数据的时候,里面加一个和全局的id,类似订单id之类的东西,然后你这里消费到了后,先根据这个id去查询下,之前是否消费过?如果没有消费过,你就处理。如果消费过了你就别处理了。
(4)基于数据库的唯一性检查。
6. 如何保证消息的可靠性传输啊(如何处理消息丢失的问题)?
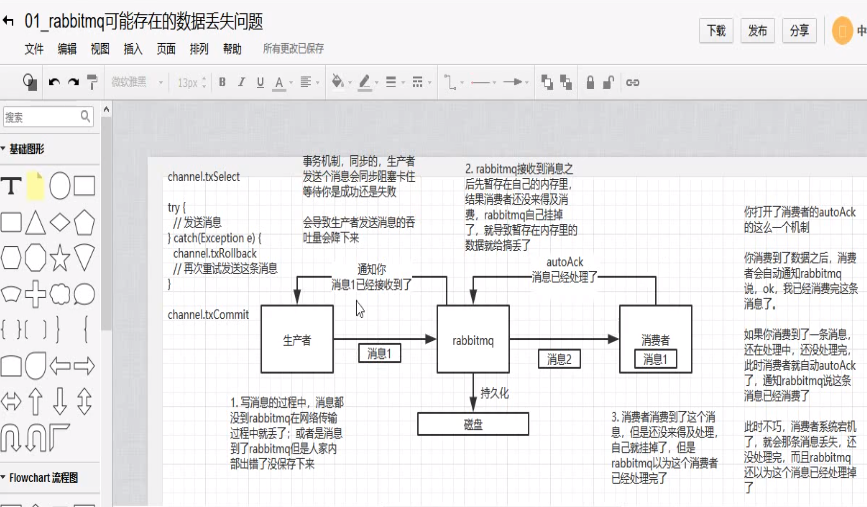
(1)生产者丢了数据
生产者将数据发送到rabbitmq的时候,可能数据就再半路给搞丢了,因为网络啥的问题,都有可能。
此时可以选择用rabbitmq提供的事务功能,就是生产者发送数据之前开启rabbitmq事务(channel.txSelect),然后发送消息,如果消息没有成功被rabbitmq接收到,那么生产者会收到异常报错,此时就可以回滚事务(channel.txRollback),然后重试发送消息;如果收到了消息,那么就可以提交事务(channel.txCommit)。但是问题是,rabbitmq事务机制一搞,基本上吞吐量就会下来,因为太消耗性能了
所以一般来说,如果你要确保说写rabbitmq的消息别丢,可以开启confirm模式,在生产者confirm模式开启后,你每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq中,rabbitmq会给你回传一个ack消息,告诉你说这个消息ok了。如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。
(2)rabbitmq弄丢了数据
就是rabbitmq自己弄丢了数据,这个你必须开启rabbitmq的持久化,就是消息写入之后会持久化到磁盘,哪怕是rabbitmq自己挂了,恢复之后会自动读取之前存储的数据。一般数据不会丢失。除非极其罕见的是,rabbitmq还没持久化,自己就挂掉了,可能导致少量数据会丢失的,但是这个概率很小。
设置持久化有两个步骤,第一是创建queue的时候将其设置为持久化的这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里的数据;第二个是发送消息的时候将消息的deliveryMode设置为2,就是将消息设置持久化的,此时rabbitmq就会将消息持久化到磁盘上去。必须同时设置这两个持久化才行。rabbitmq哪怕挂了,再次重启,也会从磁盘上重启恢复queue,恢复这个queue里的数据。
而且持久化可以跟生产者那边的confirm机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者ack了,所以哪怕是在持久化到磁盘之前,rabbitmq挂了,数据丢失了,生产者收不到ack,你也是可以自己重发的。
(3)消费端丢失数据
rabbitmq如果丢失了数据,主要是因为你消费的时候,刚消费到,你还没处理,结果进程挂了,比如重启了,那么就尴尬了,rabbitmq认为你都消费了,这数据就丢了。
这时候得用rabbitmq提供的ack机制 ,简单来说,就是你关闭rabbitmq自动ack,可以通过一个api来调用就行,然后每次在你自己代码里确保处理完的时候,在程序里ack一次,这样的话,如果你还没处理完,不久没有ack了?那rabbitmq就认为你还没处理完,这个时候rabbitmq会把这个消费分配给别的consumer去处理,消息是不会丢的。

7.那如何保证消息的顺序性?
8.如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号