

Transformer的原理及实现
transformer是谷歌2017年发表的 attention is all you need 中提到的seq2seq模型,我们常用的Bert和GPT等都是基于transformer衍生的。本文主要参考了wmathor大佬的Transformer 详解和Transformer 的 PyTorch 实现两篇文章。其中第一篇已经详细说明了transformer的原理,本文主要结合代码的实现及自己的理解对代码进一步说明。全部代码见我的GitHub库
-
此外,还有一些问题便于理解:见此
数据预处理
数据集及词表
在数据预处理方面为了降低代码阅读的难度,下面的代码手动输入了两队德语-->英语的句子,以及对应的编码。为了划分句子,有S、E、P三个标志符号,每个部分的具体作用都在代码中进行了注释
'''
@author xyzhrrr
@time 2021/2/3
'''
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
'''
数据预处理
并没有用什么大型的数据集,而是手动输入了两对德语→英语的句子,
还有每个字的索引也是手动硬编码上去的,主要是为了降低代码阅读难度,
要更多关注模型实现的部分
S: Symbol that shows starting of decoding input
E: Symbol that shows starting of decoding output
P: 如果当前批量数据大小短于时间步骤,将填充空白序列的符号
'''
sentences = [
# encoder输入 #decoder输入 #decoder输出
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
#填充应该是0,因为是翻译所以两个语言有两个词表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola' : 5}
#源词表长度,这里直接填序号了,实际中应该使用词表查询
src_vocab_size=len(src_vocab)#输入长度,one-hot长度
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, 'S': 6, 'E': 7, '.': 8}
#目标词表序号
idx2word={i: w for i,w in enumerate(tgt_vocab)}
#序号转换成此的表
tgt_vocab_size=len(tgt_vocab)#输出的one-hot长度
src_len=5 #encoder输入的最大句长
tgt_le=6#decoder输入和输出的最大句长
'''
生成张量及数据集处理类实现
下面两个函数分别生数据张量生成以及数据集处理类,其中第二个直接继承自torch的实现。
-
对于setences数据我们知道每一行对应一个德语和英语的对应句子中队,行数即是本次的batchsize的大小。对其进行划分并按词表编码,就可以得到encoder输入,decoder的输入、decoder的输入,这里可以参考下图:
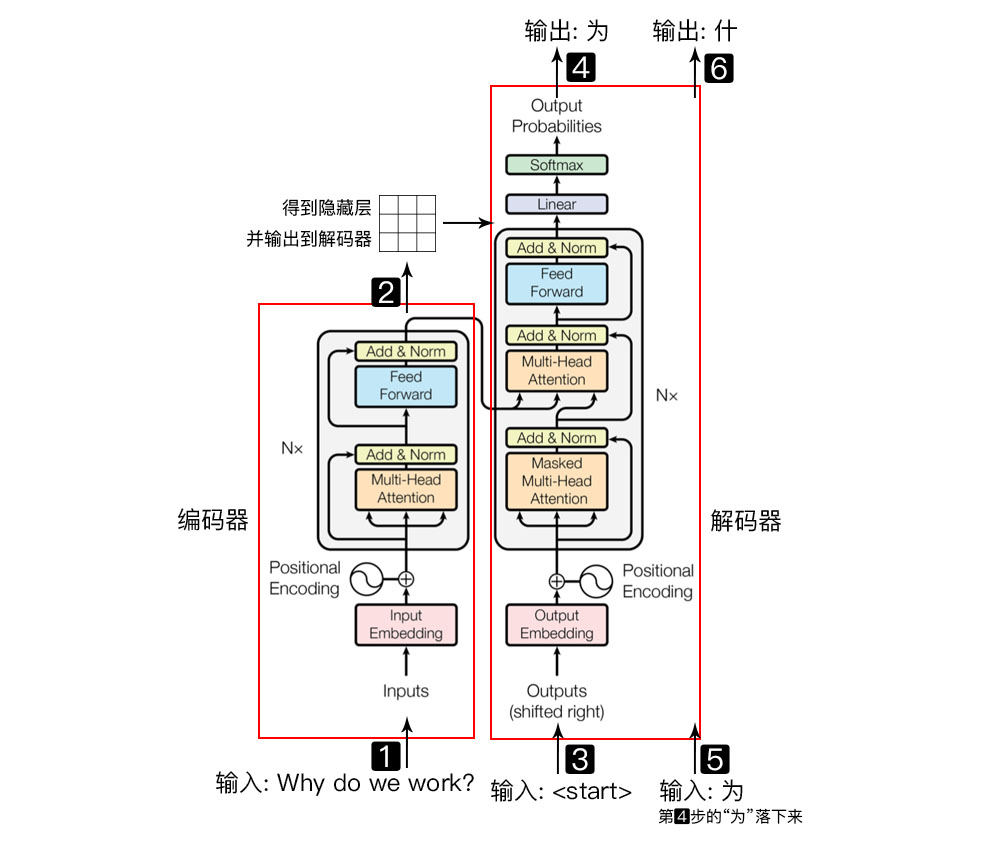
上图是Transformer 模型主要分为两大部分,分别是 Encoder 和 Decoder。Encoder 负责把输入(语言序列)隐射成隐藏层(下图中第 2 步用九宫格代表的部分),然后解码器再把隐藏层映射为自然语言序列。例如下图机器翻译的例子(Decoder 输出的时候,是通过 N 层 Decoder Layer 才输出一个 token,并不是通过一层 Decoder Layer 就输出一个 token,上图只给出了一层的layer示意图)。而在训练时encoder_input和decoder_input都是为了训练模型去学习数据信息及对照关系,而decoder_output则是用于与实际的预测输出对比的真实数据,它会将与模型通过学习两个input后decoder输出的部分进行损失函数计算来修正模型。 -
对于class MyDataSet(),继承自Data.Dataset,是为了讲转化为张量的数据整合成一个数据集便于后续进行数据的加载和处理。最后采用Data.DataLoader对数据集进行加载,这里三个参数分别为选择的数据集、minibatch的大小,是否打乱数据集。
'''
@:param sentenses 数据集
@:returns 数据的张量
默认的数据是floattensor类型,我们需要整形,所以用longtensor
'''
def make_data(sentenses):
enc_inputs,dec_inputs,dec_outputs=[],[],[]
for i in range(len(sentenses)):
#split()以空格为分隔符,即除掉空格
enc_input=[[src_vocab[n] for n in sentenses[i][0].split()]]
#读取输入数据,并转换为序号表示,加入inputs后:[[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input=[[tgt_vocab[n]for n in sentenses[i][1].split()]]
#[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
# [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
#在列表末尾一次性追加另一个序列中的多个值
return torch.LongTensor(enc_inputs),torch.LongTensor(dec_inputs),torch.LongTensor(dec_outputs)
enc_inputs,dec_inputs,dec_outputs=make_data(sentences)
# 获取数据张量
'''
数据处理类
'''
class MyDataSet(Data.Dataset):
def __init__(self,enc_inputs,dec_inputs,dec_outputs):
self.enc_inputs=enc_inputs
self.dec_inputs=dec_inputs
self.dec_outputs=dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
#返回行数,即数据集大小
def __getitem__(self, item):
return self.enc_inputs[item],self.dec_inputs[item],self.dec_outputs[item]
#返回对应数据的各项内容
#加载数据集
loader=Data.DataLoader(dataset=MyDataSet(enc_inputs, dec_inputs, dec_outputs),
batch_size=2, #批处理大小,一次处理多少数据
shuffle=True)
一些参数
下面变量代表的含义依次是
- 字嵌入 & 位置嵌入的维度,这俩值是相同的,因此用一个变量就行了
- FeedForward 层隐藏神经元个数
- Q、K、V 向量的维度,其中 Q 与 K 的维度必须相等,V 的维度没有限制,不过为了方便起见,我都设为 64
- Encoder 和 Decoder 的个数
- 多头注意力中 head 的数量
'''
Transformer Parameters
'''
d_model=512 #embedding size词嵌入大小
d_ff=2048 # FeedForward dimension,全连接层维度
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder and Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
position encoding
由于 Transformer 模型没有循环神经网络的迭代操作,所以我们必须提供每个字的位置信息给 Transformer,这样它才能识别出语言中的顺序关系
现在定义一个位置嵌入的概念,也就是 Positional Encoding,位置嵌入的维度为 [max_sequence_length, embedding_dimension], 位置嵌入的维度与词向量的维度是相同的,都是 embedding_dimension。max_sequence_length 属于超参数,指的是限定每个句子最长由多少个词构成
-
注意,我们一般以字为单位训练 Transformer 模型。首先初始化字编码的大小为 [vocab_size, embedding_dimension],vocab_size 为字库中所有字的数量,embedding_dimension 为字向量的维度,对应到 PyTorch 中,其实就是 nn.Embedding(vocab_size, embedding_dimension)
-
论文中使用了 sin 和 cos 函数的线性变换来提供给模型位置信息,需要注意的是所谓的2i和2i+1只是用来表示奇和偶,实际在代码中都是用2i表示只不过从0和1开始的区别:
- 位置函数的具体理解可以参考这篇文章Transformer 中的 Positional Encoding,简单来说通过控制sin函数的周期性来体现出位置的变化,如下图随着纵向观察,可见随着 embedding_dimension序号增大,位置嵌入函数的周期变化越来越平缓
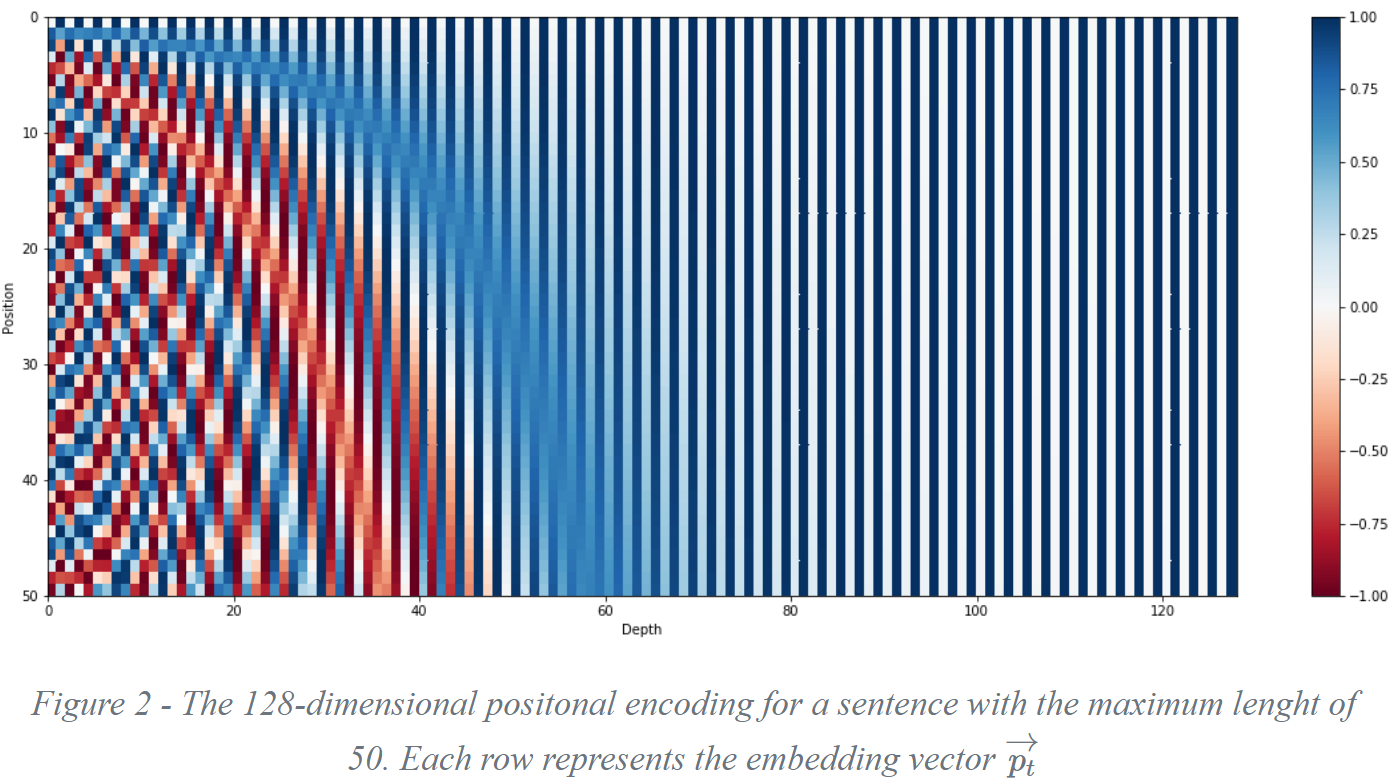
t时刻嵌某个词位置嵌入的向量如下,这里为2i是因为分了奇和偶如下,具体的见前面的参考博客:
'''
位置编码
'''
class PositionEncoding(nn.Module):
def __init__(self,d_model,dropout=0.1,max_len=5000):
super(PositionEncoding,self).__init__()
self.droupout=nn.Dropout(p=dropout)
pe=torch.zeros(max_len,d_model)#初始化位置嵌入position_embedding
position =torch.arange(0,max_len,dtype=torch.float).unsqueeze(1)
#创建位置张量,unsquuze增加一个维度,最终生成
# tensor([[0.],[1.],[2.], [3.], [4.]....]),维度为(max_len,1)
diV_term=torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000.0)/d_model))
#这里可以看笔记
pe[:,0::2]=torch.sin(position*diV_term)
pe[:,1::2]=torch.cos(position*diV_term)#从1开始,间隔为2
pe=pe.unsqueeze(0).transpose(0,1)
#增加一个行维度并且进行转置,以一维到二维为例,[[, , , , ,]],->[[],[],[],[]...],
# unsqueeze后维度为(1,max_len,d_model),然后将前两个维度转置,即(max_len,1,d_model),相当于一个max—len(句长)个大小为(1,d_model)的位置编码
self.register_buffer('pe',pe)
#像模型中添加缓冲,名字为pe,这通常用于注册不应被视为模型参数的缓冲区,即表明pe是模型的一部分而不是参数,
# https://pytorch.org/docs/stable/generated/torch.nn.Module.html
def forward(self,x):
'''
x: [seq_len, batch_size, d_model]
x是上下文嵌入,输入这种形式就是为了后续与pe相加
'''
x=x+self.pe[:x.size(0),:]
#size(0)就是seq_len,将位置嵌入加入到上下文嵌入中,这里用seq_len是因为二者(max_len)长度不一定相同,如过比较短就只计算seq_len长度的,防止维度改变
return self.droupout(x)
- 针对第12行的代码可以写出它的数学形式,经过转换与位置公式的结果相同如下。
- 最后,实际的到的pe位置嵌入向量,每一行代表一个字的位置编码,不同行的区别在于字的位置position(0~maxlen)的不同,而就一行来看,每一列实际上就是随位置嵌入维度下标变化的情况,可以结合彩图集pe的式子进行理解。
Pad Mask
需要注意的是在本文的代码中如果值为 src_len 或者 tgt_len 的,则一定会写清楚,但是有些函数或者类,Encoder 和 Decoder 都有可能调用,因此就不能确定究竟是 src_len 还是 tgt_len,对于不确定的,会记作 seq_len。而对于为何需要进行mask,如下:

'''
针对句子不够长,加了 pad,因此需要对 pad 进行 mask
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len in seq_q and seq_len in seq_k maybe not equal
由于在 Encoder 和 Decoder 中都需要进行 mask 操作,因此就无法确定这个函数的参数中 seq_len 的值,
如果是在 Encoder 中调用的,seq_len 就等于 src_len;
如果是在 Decoder 中调用的,seq_len 就有可能等于 src_len,也有可能等于 tgt_len(因为 Decoder 有两次 mask)
返回的mask用于计算attention时,消除填充的0的影响,可见博客
'''
def get_attn_pad_mask(seq_q,seq_k):
'''
这个函数最核心的一句代码是 seq_k.data.eq(0),
这句的作用是返回一个大小和 seq_k 一样的 tensor,只
不过里面的值只有 True 和 False。
如果 seq_k 某个位置的值等于 0,那么对应位置就是 True,否则即为 False。
举个例子,输入为 seq_data = [1, 2, 3, 4, 0],seq_data.data.eq(0) 就会返回 [False, False, False, False, True]
'''
batch_size,len_q=seq_q.size()
batch_size,len_k=seq_k.size()
# eq(zero) is PAD token
pad_attn_mask=seq_k.data.eq(0).unsqueeze(1)
# [batch_size, 1, len_k], True is masked
return pad_attn_mask.expand(batch_size, len_q, len_k)
# [batch_size, len_q, len_k]
#维度是这样的,因为掩码用在softmax之前,那他的维度就是Q*k.T的维度
- 这里只是先判断力哪些是掩码,是掩码就标True,便于后续操作。并且选择K进行判断是因为softmax的计算是
Subsequence Mask
Subsequence Mask 只有 Decoder 会用到,主要作用是屏蔽未来时刻单词的信息。

'''
Subsequence Mask 只有 Decoder 会用到,
主要作用是屏蔽未来时刻单词的信息。首先通过 np.ones() 生成一个全 1 的方阵,
然后通过 np.triu() 生成一个上三角矩阵,
'''
def get_attn_subsequence_mask(seq):
'''
seq: [batch_size, tgt_len]
'''
attn_shape=[seq.size(0),seq.size(1),seq.size(1)]
subsequence_mask=np.triu(np.ones(attn_shape),k=1)
#形成上三角矩阵,其中k=1就是对角线位置向上移一个对角线,可看原博客
subsequence_mask=torch.from_numpy(subsequence_mask).byte()
#转换为tensor,byte就是大小为8bite的int
return subsequence_mask
# [batch_size, tgt_len, tgt_len]
ScaledDotProductAttention 计算上下文向量
结合下面的图,也可以参考这里的动图

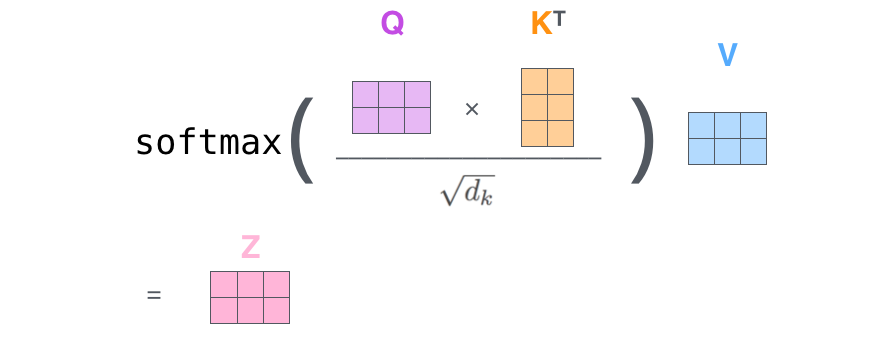
'''
计算上下文向量
这里要做的是,通过 Q 和 K 计算出 scores,
然后将 scores 和 V 相乘,得到每个单词的 context vector
'''
class ScaleDotProductAttention(nn.Module):
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
def forward(self,Q,K,V,attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
如果len_v不等于len_k则后续无法计算context
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores=torch.matmul(Q,K.transpose(-1,-2))/np.sqrt(d_k)
# scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask,-1e9)
#masked_fill_()函数可以将attn_mask中为1(True,也就是填充0的部分)的位置填充为-1e9
#相当于对填0的地方加上一个极小值以消除在计算attention时softmax时的影响。
attn=nn.Softmax(dim=-1)(scores)
#对行进行softmax,每一行其实就是一个字的注意力机制,可以看博客
context=torch.matmul(attn,V)
# [batch_size, n_heads, len_q, d_v]
return context,attn
- 需要注意每一行即一个数据集代表一个句子的计算,而我们计算softmax是按照最后一个维度也就相当于[q_len,k_len]的最后一个维度,即按照列之间进行计算,那么每一行(这里指的是q_Len的)就代表一个字。但是对更细节的比如为什么选择用seq_k检测是否有掩码
MultiHeadAttention 多头注意力机制
完整代码中一定会有三处地方调用 MultiHeadAttention(),Encoder Layer 调用一次,传入的 input_Q、input_K、input_V 全部都是 encoder_inputs;Decoder Layer 中两次调用,第一次传入的全是 decoder_inputs,第二次传入的分别是 decoder_outputs,encoder_outputs,encoder_outputs.

- 其实际的作用就是讲输入的三个部分进行集权计算并计算自注意力,最后然后输出结果。也一=因此会调用前面的生成掩码以及计算上下文向量
- 从结构图中可以看到多头注意力实际上后面还跟着一个残差和LayerNorm归一化操作,这里也一并实现
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q=nn.Linear(d_model,d_k*n_heads,bias=False)
#输入维度为embedding维度,输出维度为Q(=K的维度)的维度*头数,
# bias为False就是不要学习偏差,只更新权重即可(计算的就是权重)
self.W_K=nn.Linear(d_model,d_k*n_heads,bias=False)
self.W_V=nn.Linear(d_model,d_v*n_heads,bias=False)
self.fc=nn.Linear(n_heads*d_v,d_model,bias=False)
#通过一个全连接层将维度转为embedding维度好判断预测结果
def forward(self,input_Q,input_K,input_V,attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual,batch_size=input_Q,input_Q.size(0)
#residual,剩余的,用于后续残差计算
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q=self.W_Q(input_Q).view(batch_size,-1,n_heads,d_k).transpose(1,2)
# Q: [batch_size, n_heads, len_q, d_k],-1就是在求长度
#其实self.W_Q就是一个线性层,输入的时input_Q,然后对输出进行变形,
# 这也是linear的特点,即只需要最后一个满足维度就可以即[batch_size,size]中的size
K=self.W_K(input_K).view(batch_size,-1,n_heads,d_k).transpose(1,2)
# K: [batch_size, n_heads, len_k, d_k]
V=self.W_V(input_V).view(batch_size,-1,n_heads,d_v).transpose(1,2)
# V: [batch_size, n_heads, len_v(=len_k), d_v]
'''
我们知道为了能够计算上下文context我们需要len_v==len_k,这就要求d_v=d_k
所以实际上Q、K、V的维度都是相同的
我猜测这里仅将Q、K一起表示是为了便于管理参与加权计算的和不参与的。
'''
attn_mask=attn_mask.unsqueeze(1).repeat(1,n_heads,1,1)
# attn_mask : [batch_size, n_heads, seq_len, seq_len]
#根据生成attn_mask的函数生成的大小应该为# [batch_size, len_q, len_k]
#所以显示增加了一个1个列的维度变为[batch_size, 1,len_q, len_k]在通过repeat变为上面结果
context,attn=ScaleDotProductAttention()(Q,K,V,attn_mask)
context=context.transpose(1,2).reshape(batch_size,-1,n_heads*d_v)
# [batch_size, n_heads, len_q, d_v]->[batch_size, len_q, n_heads * d_v],为了最后一个维度符合全连接层的输入
output=self.fc(context)# [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output+residual), attn
- 最后进行残差运算以及通过LayerNorm把神经网络中隐藏层归一为标准正态分布,也就是独立同分布以起到加快训练速度,加速收敛的作用
- 残差连接实际上是为了防止防止梯度消失,帮助深层网络训练
FeedForward Layer 前馈连接层
就是做两次线性变换,残差连接后再跟一个 Layer Norm,需要注意,每个 Encoder Block 中的 FeedForward 层权重都是共享的
- 前馈连接层的作用如下:

class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc=nn.Sequential(
nn.Linear(d_model,d_ff,bias=False),
nn.ReLU(),
nn.Linear(d_ff,d_model,bias=False)
) #torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。
#先映射到高维在回到低维以学习更多的信息
def forward(self,inputs):
'''
inputs: [batch_size, seq_len, d_model]
'''
residual=inputs
outputs=self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(outputs+residual)
# [batch_size, seq_len, d_model]
Encoder Layer
我们按照下图的结构讲所有部件进行串联就得到了encoder layer,灰框内就是layer。
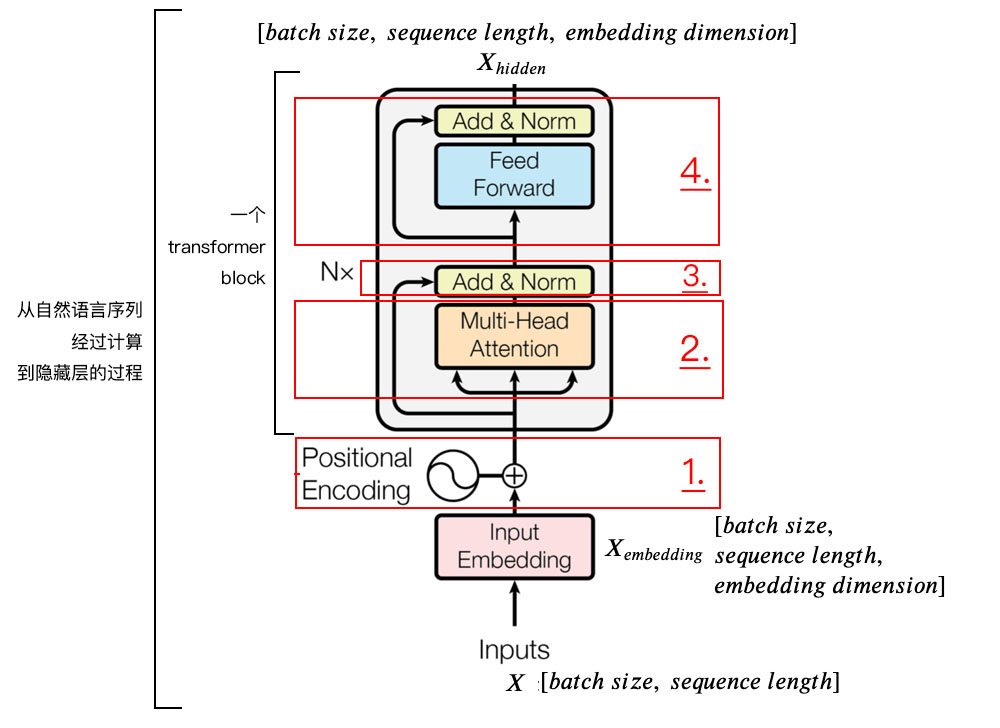
'''
encoder layer
就是将上述组件拼起来
'''
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn=MultiHeadAttention()#多头注意力层
self.pos_ffn=PoswiseFeedForwardNet()#前馈层,注意残差以及归一化已经在各自层内实现
def forward(self,enc_inouts,enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
nc_self_attn_mask: [batch_size, src_len, src_len]
'''
enc_outputs,attn=self.enc_self_attn(enc_inouts,enc_inouts,enc_inouts,enc_self_attn_mask)
#三个inputs对应了input_Q\K\V.attn其实就是softmax后没有乘以V之前的值。
enc_outputs=self.pos_ffn(enc_outputs)# enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
Encoder
一个encoder往往有多层encodelayer ,我们使用nn.ModuleList() 里面的参数是列表,列表里面存了 n_layers 个 Encoder Layer,这里我们设定n_layers为8
'''
Encode实现,即将多个encoderlayer套起来
使用 nn.ModuleList() 里面的参数是列表,列表里面存了 n_layers 个 Encoder Layer
由于我们控制好了 Encoder Layer 的输入和输出维度相同(最后一个维度都变味了embedding维度大小),
所以可以直接用个 for 循环以嵌套的方式,
将上一次 Encoder Layer 的输出作为下一次 Encoder Layer 的输入
'''
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb=nn.Embedding(src_vocab_size,d_model)
#src_vocab_size实际上就是输入词表大小,也就是用one-hot表示的长度,d_model是embedding长度
self.pos_emb=PositionEncoding(d_model)
self.layers=nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self,enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
enc_outputs=self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
enc_outputs=self.pos_emb(enc_outputs.transpose(0,1)).transpose(0,1)
# [batch_size, src_len, d_model],这样改变维度是为了与pe维度匹配(可以看实现部分的注释)
enc_self_attn_mask=get_attn_pad_mask(enc_inputs,enc_inputs)
# [batch_size, src_len, src_len]
enc_self_attns=[]
'''
可以看见所有encoder block都是用的一个mask
此外,每个 Encoder Block 中的 FeedForward 层权重都是共享的,虽然我没看出来咋共享的
'''
for layer in self.layers:
enc_outputs,enc_self_attn=layer(enc_outputs,enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs,enc_self_attns
Decoder Layer
在 Decoder Layer 中会调用两次 MultiHeadAttention,第一次是计算 Decoder Input 的 self-attention,得到输出 dec_outputs。然后将 dec_outputs 作为生成 Q 的元素,enc_outputs 作为生成 K 和 V 的元素,再调用一次 MultiHeadAttention,得到的是 Encoder 和 Decoder Layer 之间的 context vector。最后将 dec_outptus 做一次维度变换,然后返回.
因为需要来自encoder的输入,所以按照下图讲部件组装好就好,同样灰框内就是layer:
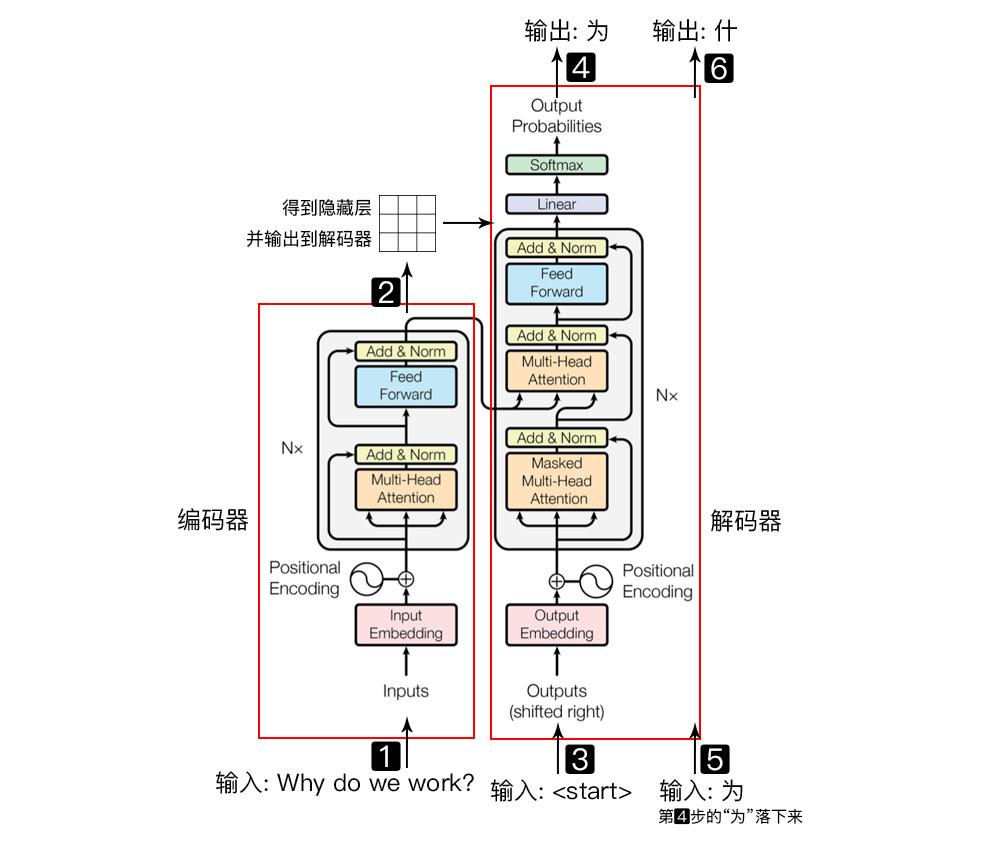
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn=MultiHeadAttention()
self.dec_enc_attn=MultiHeadAttention()
self.pos_ffn=PoswiseFeedForwardNet()
def forward(self,dec_inputs,enc_outputs,dec_self_attn_mask,dec_enc_attn_mask):
'''
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
'''
dec_outputs,dec_self_attn=self.dec_self_attn(dec_inputs,dec_inputs,dec_inputs,dec_self_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs,dec_enc_attn=self.dec_enc_attn(dec_outputs,enc_outputs,enc_outputs,dec_enc_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs=self.pos_ffn(dec_outputs)# [batch_size, tgt_len, d_model]
return dec_outputs,dec_self_attn,dec_enc_attn
Decoder
同样按照上图组装,需要注意的是decoder的输入是需要将当前时刻后的数据mask掉的,并且最还需要再一次的归一化和softmax求得最后的翻译结果,但是由于在进行计算损失函数时nn.CrossEntropyLoss () 里面算了softmax,所以transformer中最后的softmax就省略了。
'''
Decoder
'''
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb=nn.Embedding(tgt_vocab_size,d_model)
self.pos_emb=PositionEncoding(d_model)
self.layers=nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self,dec_inputs,enc_inputs,enc_outputs):
'''
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model]
'''
dec_outputs=self.tgt_emb(dec_inputs)#[batch_size, tgt_len, d_model]
dec_outputs=self.pos_emb(dec_outputs.transpose(0,1)).transpose(0,1).cuda()
# [batch_size, tgt_len, tgt_len]
'''
Decoder 中不仅要把 "pad"mask 掉,还要 mask 未来时刻的信息,
因此就有了下面这三行代码,其中 torch.gt(a, value) 的意思是,
将 相加后的mask中各个位置上的元素和 0 比较,若大于 0,则该位置取 1,否则取 0
'''
dec_self_attn_pad_mask=get_attn_pad_mask(dec_inputs,dec_inputs).cuda()
# [batch_size, tgt_len, tgt_len],这是获取用于计算self-attention的mask
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda()
# [batch_size, tgt_len, tgt_len],这是用于屏蔽未来时刻单词的信息的mask
dec_self_attn_mask=torch.gt((dec_self_attn_pad_mask+dec_self_attn_subsequence_mask),0).cuda()
# [batch_size, tgt_len, tgt_len]
#torch.gt(a,b)函数比较a中元素大于(这里是严格大于)b中对应元素,大于则为1,不大于则为0,
# 这里a为Tensor,b可以为与a的size相同的Tensor或常数。
dec_enc_attn_mask=get_attn_pad_mask(dec_inputs,enc_inputs)
# [batc_size, tgt_len, src_len],我想可能是因为第二个部分有encoder和第一个decoder两个的输出,所以需要考虑两个的输入mask
dec_self_attns,dec_enc_attns=[],[]
for layer in self.layers:
'''
dec_outputs: [batch_size, tgt_len, d_model],
dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len],
dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
'''
dec_outputs,dec_self_attn,dec_enc_attn=layer(dec_outputs,enc_outputs,dec_self_attn_mask,dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs,dec_self_attns,dec_enc_attns
Transformer
我们按照transformer的整体结构图将decoder和encoder连接起来,要注意其中信息的传递,如下图
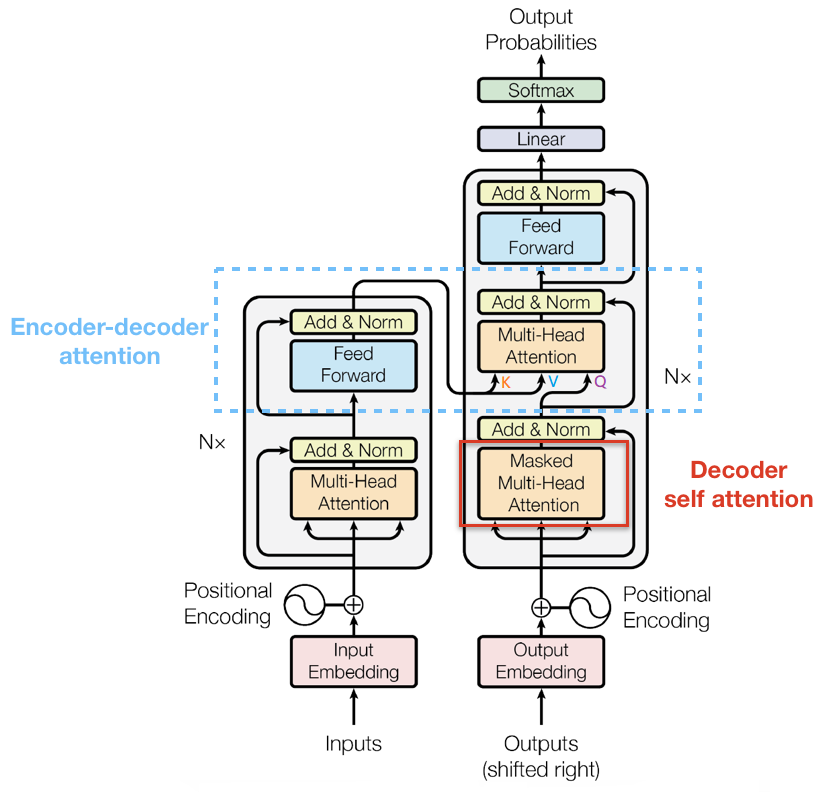
- 最后返回 dec_logits 的维度是 [batch_size * tgt_len, tgt_vocab_size],可以理解为,一个句子,这个句子有 batch_size*tgt_len 个单词,每个单词有 tgt_vocab_size 种情况,取概率最大者
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder=Encoder().cuda()
self.decoder=Decoder().cuda()
self.projection=nn.Linear(d_model,tgt_vocab_size,bias=False).cuda()
def forward(self,enc_inputs,dec_inputs):
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
'''
enc_outputs,enc_self_attn=self.encoder(enc_inputs)
# enc_outputs: [batch_size, src_len, d_model],
# enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
dec_outputs,dec_self_attns,dec_enc_attns=self.decoder(dec_inputs,enc_inputs,enc_outputs)
# dec_outpus: [batch_size, tgt_len, d_model],
# dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len],
# dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_logits=self.projection(dec_outputs)
# dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1,dec_logits.size(-1)), enc_self_attn,dec_self_attns,dec_enc_attns
模型 & 损失函数 & 优化器
这里的损失函数里面我设置了一个参数 ignore_index=0,因为 "pad" 这个单词的索引为 0,这样设置以后,就不会计算 "pad" 的损失(因为本来 "pad" 也没有意义,不需要计算),关于这个参数更详细的说明,可以看这篇文章的最下面,稍微提了一下
model=Transformer().cuda()
criterion=nn.CrossEntropyLoss(ignore_index=0)
# nn.CrossEntropyLoss () 里面算了softmax,所以transformer中最后的softmax就省略了。
#因为 "pad" 这个单词的索引为 0,这样设置以后,就不会计算 "pad" 的损失(因为本来 "pad" 也没有意义,不需要计算)
optimizer=optim.SGD(model.parameters(),lr=1e-3,momentum=0.99)
# –动量系数
训练
训练阶段与传统的训练并没有很大的差异,需要注意的时zaidecoder部分也有输入。
for epoch in range(1000):
for enc_inputs,dec_inputs,dec_outputs in loader:
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
'''
enc_inputs,dec_inputs,dec_outputs=enc_inputs.cuda(),dec_inputs.cuda(),dec_outputs.cuda()
outputs,enc_self_attns,dec_self_attns,dec_enc_attns=model(enc_inputs,dec_inputs)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
loss=criterion(outputs,dec_outputs.view(-1))
#dec_outputs变成大小batch_size * tgt_len的一维的结构。并不是变成行向量
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()#梯度清零
loss.backward()#反向传播计算梯度
optimizer.step()#梯度清零
测试
这里应为最后的输出是一个句子,所以用到了贪心搜索,简单来说在知道第一个词的情况下选出第二个词的前几名的概率,比如选出三个较大的后,在对这三个依次预测第三个词并同样保持概率最高的三个,以此类推。
def greedy_decoder(model,enc_input,start_symbol):
'''
为简单起见,当 K=1 时,贪心解码器是波束搜索。
这对于推理是必要的,因为我们不知道目标序列输入。
因此,我们尝试逐字生成目标输入,然后将其输入到transformer中。
:param start_symbol:开始符号。 在这个例子中,它是“S”,
最后返回了一个经过多次decoder计算出来的一个初步的句子,
并且可以看到,在这里的decoder和seq2seq的思想一个不断把前面预测出的结果进行输入
'''
enc_outputs,enc_self_attns=model.encoder(enc_input)
dec_input=torch.zeros(1,0).type_as(enc_input.data)
terminal=False
next_symbol=start_symbol
while not terminal: #若terminal为假
dec_input=torch.cat([dec_input.detach(),torch.tensor([[next_symbol]],dtype=enc_input.dtype).cuda()], -1)
#detach是将某个node变成不需要梯度的Varibale。因此当反向传播经过这个node时,梯度就不会从这个node往前面传播。
#因为是预测时期,所以这里没有反向传播所以应该没有梯度积累
#不断地将next_symbol加入dec_input,知道结尾,开始时也加入了S,-1是指以最后一维维度为基准
dec_outputs,_,_=model.decoder(dec_input,enc_input,enc_outputs)
projected=model.projection(dec_outputs)#最后的预测结果,为啥也没有softmax啊
# projected:[batch_size, tgt_len, tgt_vocab_size]
prob=projected.squeeze(0).max(dim=-1,keepdim=False)[1]
#首先去掉第一个维,然后求最后一个维度的最大值,不保留维度,即把所有的结果存在一行中,然后选取下标为1的
next_word=prob.data[-1]
next_symbol=next_word
if next_symbol==tgt_vocab["."]:#这表示到了一个句子的末尾,此时dec_input已经存了一个句子的结果。
terminal=True
print(next_word)
return dec_input
- 最后就是一些传统的操作。
enc_inputs,_,_=next(iter(loader))
enc_inputs = enc_inputs.cuda()
for i in range(len(enc_inputs)):
greedy_dec_input=greedy_decoder(model,enc_inputs[i].view(1,-1),start_symbol=tgt_vocab["S"])
#enc_inputs[i]每次输入的是一个句子,并变成一行,n列的矩阵(n,就是句子长度)
predict,_,_,_=model(enc_inputs[i].view(1,-1),greedy_dec_input)#又预测了一遍
predict=predict.data.max(1,keepdim=True)[1]
print(enc_inputs[i],'->',[idx2word[n.item()]for n in predict.squeeze()])
一些疑问
- 预测阶段的各个维度和模型原来的维度的关系
- 以及为什么在损失函数里使用了softmax可以抵消模型里的呢,那再最后预测的是否不用加上么
- 总之,只是作为参考,一般直接调用已经写好的框架即可,这里仅供学习使用。
本文来自博客园,作者:xingye_z,转载请注明原文链接:https://www.cnblogs.com/xyzhrrr/p/15853855.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号