
《GPU-Accelerated Atari Emulation for Reinforcement Learning》大batch size的并行采样可以提高计算效率,减少训练的收敛时间


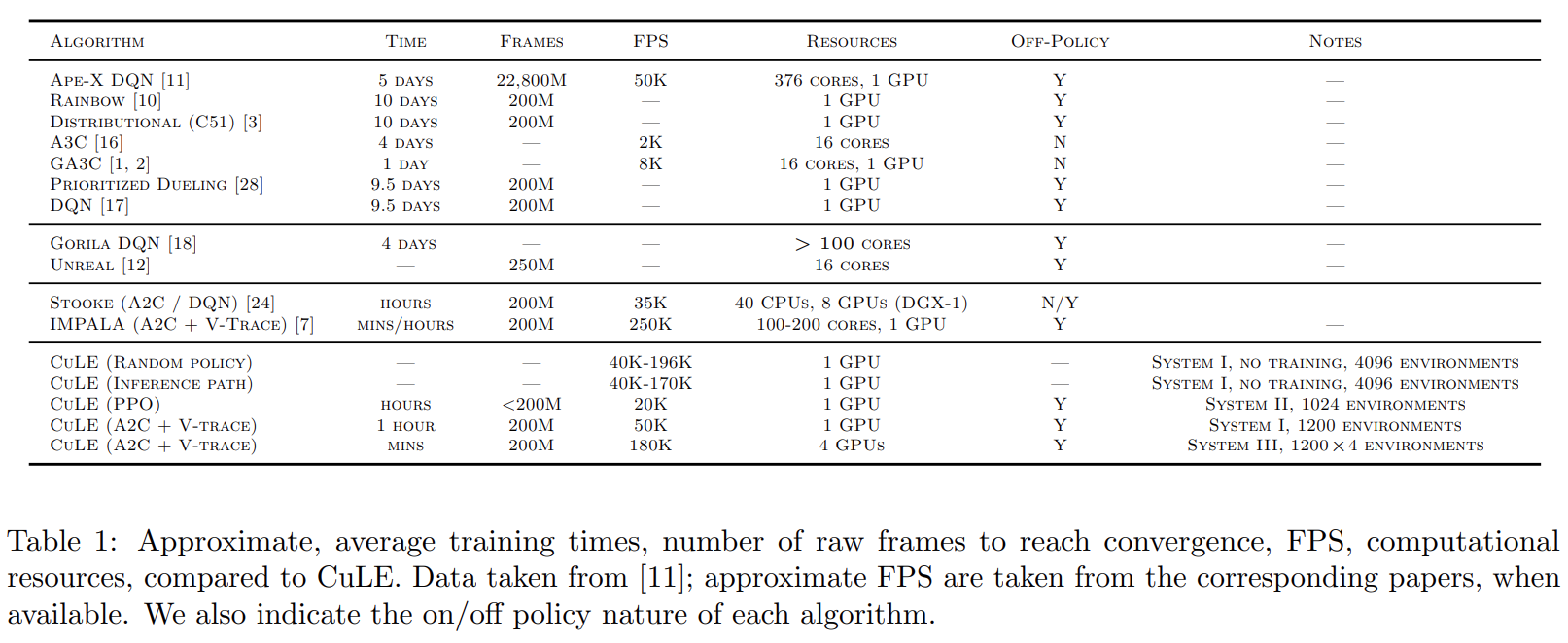
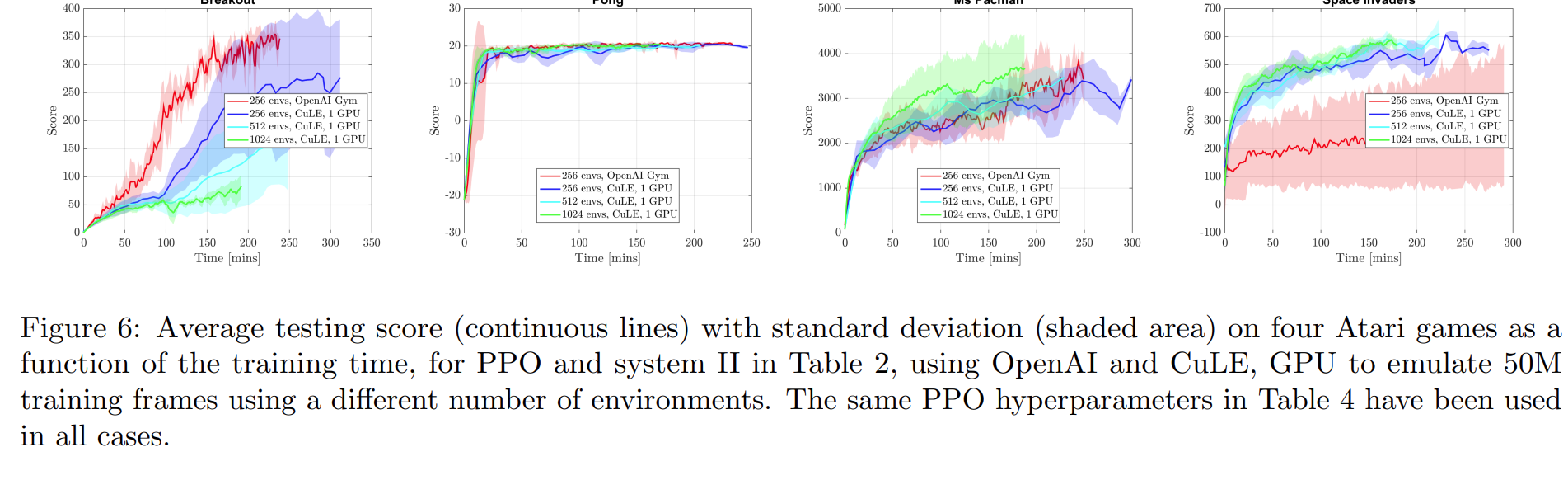
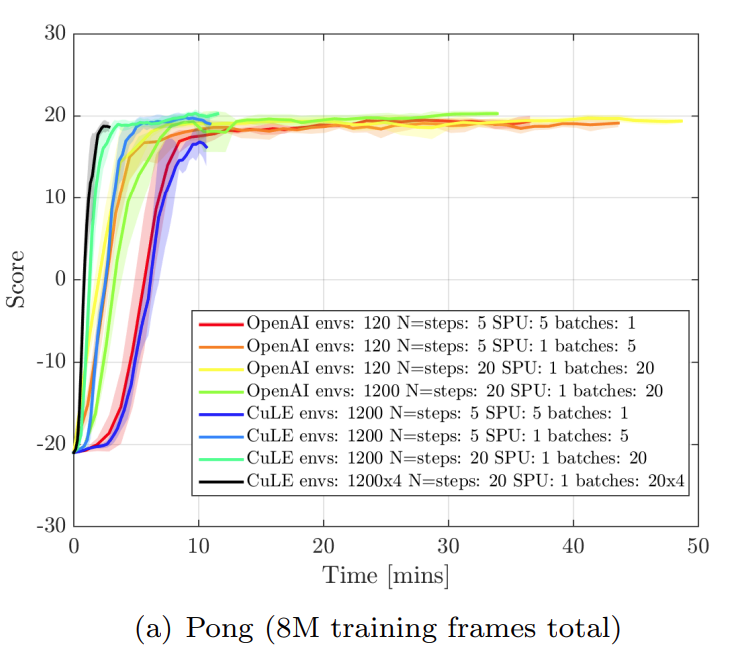
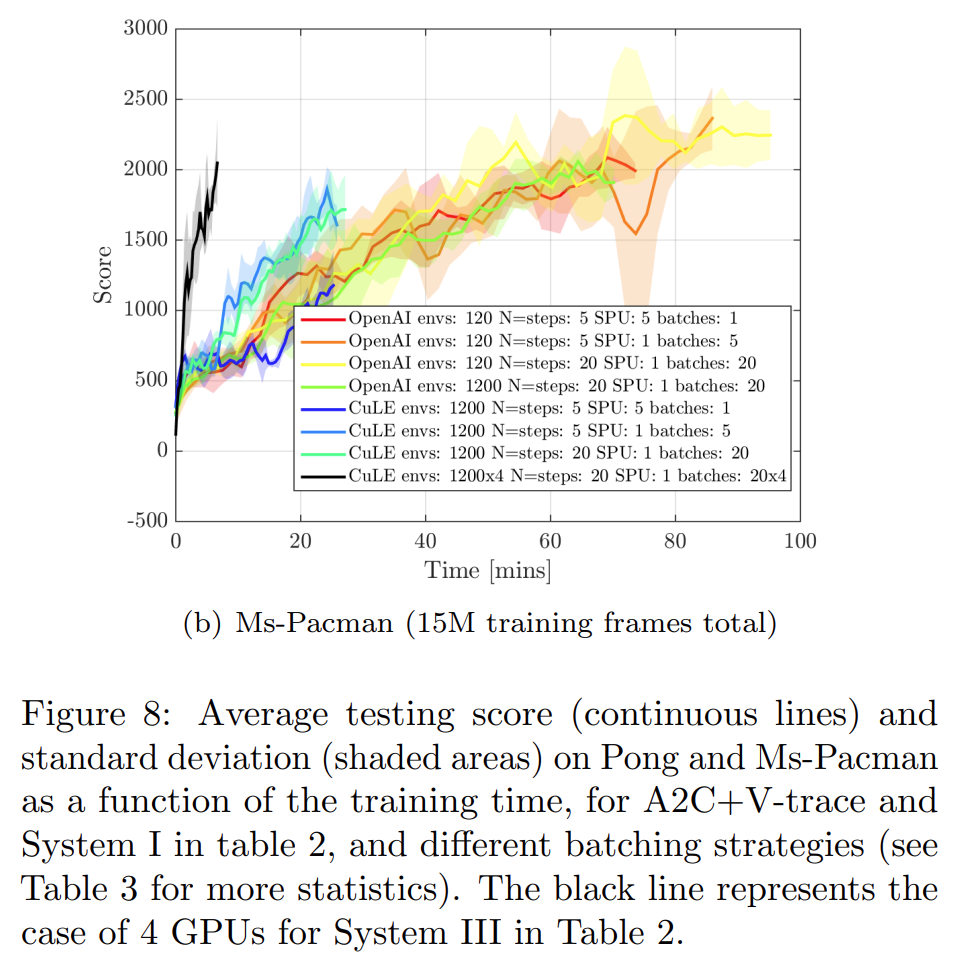
并行化采样的RL对什么样的RL算法性能提升显著,对什么样的RL算法性能提升不显著?原论文中认为对于性能提升提升不显著的RL算法如何补救(寻找更好的超参,寻找更好的网络架构,还是如何?)
对 PPO 和 A2C+Vtrace 的方法并不显著,对A2C方法显著,可以较大程度提高收敛速度,提高算法性能。论文里面认为使用更好的超参可以提高大batch size采样不敏感的RL算法得到收敛性(更少的时间内收敛)和性能提升。
有下面结论:
-
增加batch size确实可以提高算法收敛性及性能,但是并不是一味增加batch size即可,比如1024个环境并行采样的效果不一定就比2048个环境并行采样的效果差。
-
如何选择并行采样过程中的样本的batch size是一个有难度的事情。
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2025-08-22 08:00 Angry_Panda 阅读(22) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号