深度神经网络训练过程中的观测值 —— param norm, loss, grad norm


在深度神经网络训练过程中,观测param norm、loss和grad norm具有关键意义,三者共同反映了模型训练的动态状态,并为调参提供了重要依据。以下是具体分析:
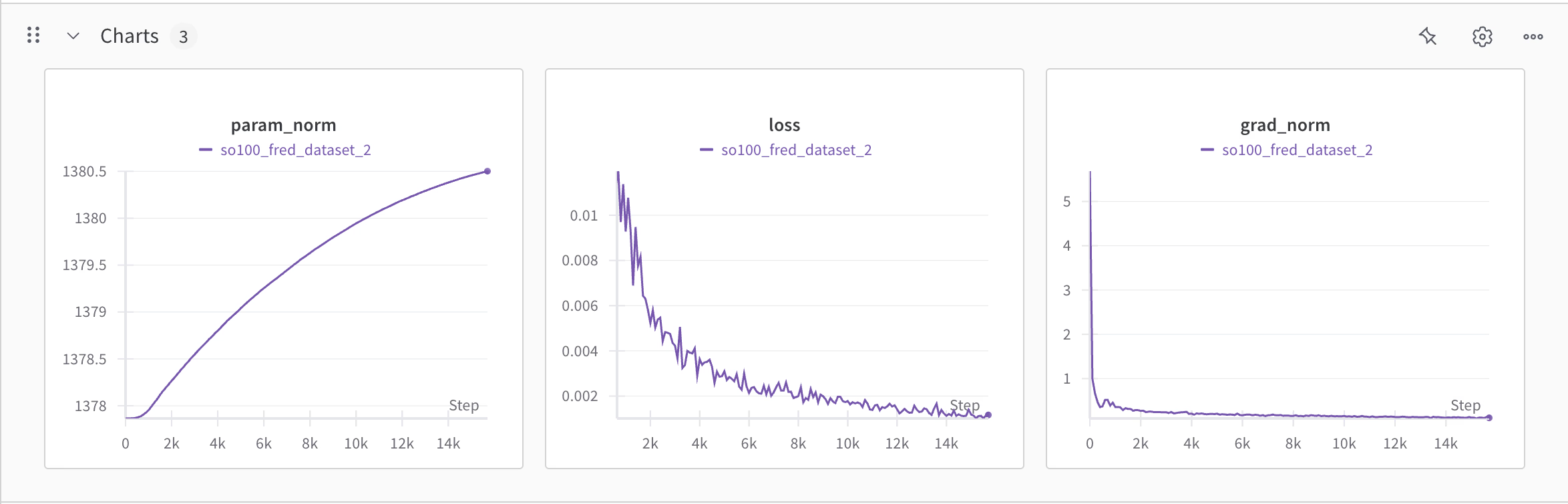
一、Param Norm(参数范数)
定义与作用:参数范数衡量模型权重的整体幅度。较高的参数值可能暗示模型复杂度高,存在过拟合风险;而过低的参数可能导致欠拟合8。
监控意义:
正则化效果评估:权重衰减(Weight Decay)通过惩罚较大的参数值来控制模型的复杂度,监控param norm可验证正则化是否有效18。
归一化的辅助作用:如LayerNorm或BatchNorm通过标准化中间层输入分布,间接影响参数更新的稳定性,避免参数值剧烈波动511。
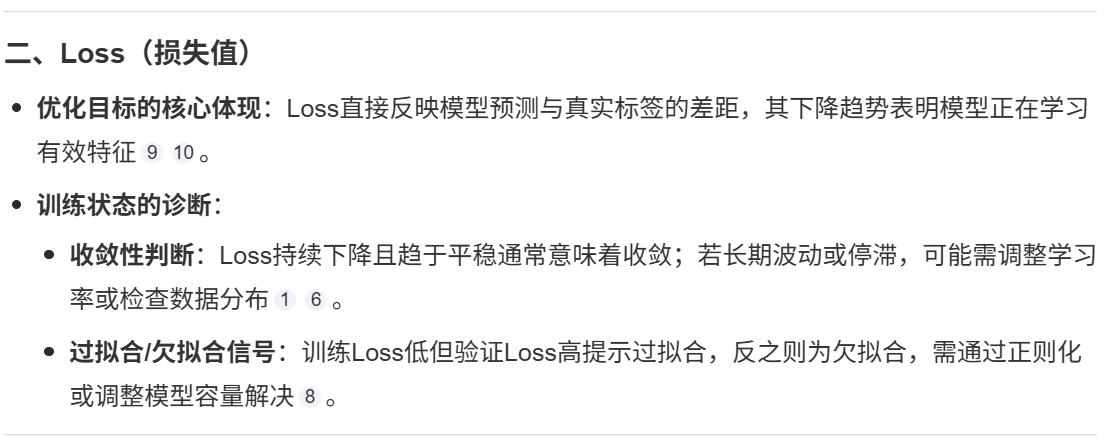
二、Loss(损失值)
优化目标的核心体现:Loss直接反映模型预测与真实标签的差距,其下降趋势表明模型正在学习有效特征910。
训练状态的诊断:
收敛性判断:Loss持续下降且趋于平稳通常意味着收敛;若长期波动或停滞,可能需调整学习率或检查数据分布16。
过拟合/欠拟合信号:训练Loss低但验证Loss高提示过拟合,反之则为欠拟合,需通过正则化或调整模型容量解决8。
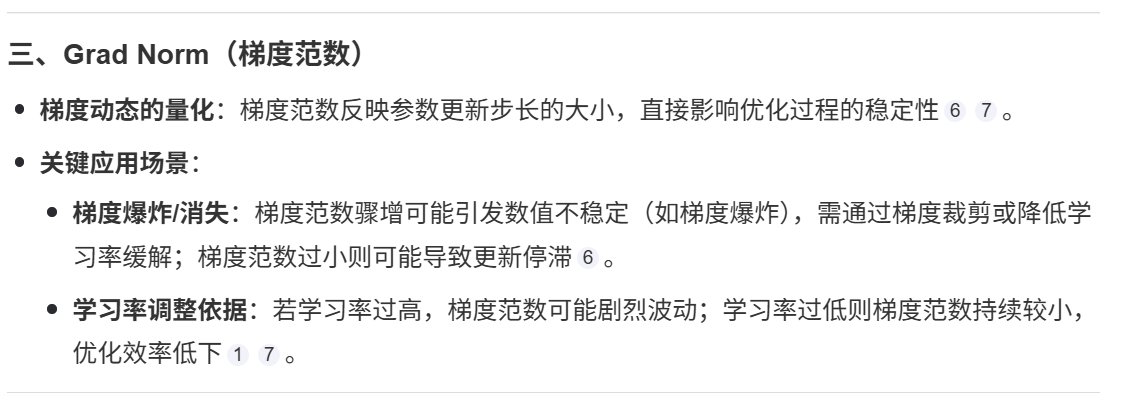
三、Grad Norm(梯度范数)
梯度动态的量化:梯度范数反映参数更新步长的大小,直接影响优化过程的稳定性67。
关键应用场景:
梯度爆炸/消失:梯度范数骤增可能引发数值不稳定(如梯度爆炸),需通过梯度裁剪或降低学习率缓解;梯度范数过小则可能导致更新停滞6。
学习率调整依据:若学习率过高,梯度范数可能剧烈波动;学习率过低则梯度范数持续较小,优化效率低下17。
四、三者的关联与协同作用
Loss与Grad Norm的联动:
Loss波动大且Grad Norm高时,可能需减小学习率或增大批量大小以平滑梯度估计12。
Loss下降缓慢但Grad Norm稳定,可尝试适当增大学习率或引入更复杂的优化策略4。
Param Norm与泛化能力:
Param Norm持续增长但验证Loss上升,需增强正则化(如增大权重衰减系数)或采用Dropout18。
归一化技术的全局影响:
使用BatchNorm等层后,Param Norm和Grad Norm的波动通常减小,训练过程更稳定,但需注意归一化参数(如γ、β)的更新情况511。
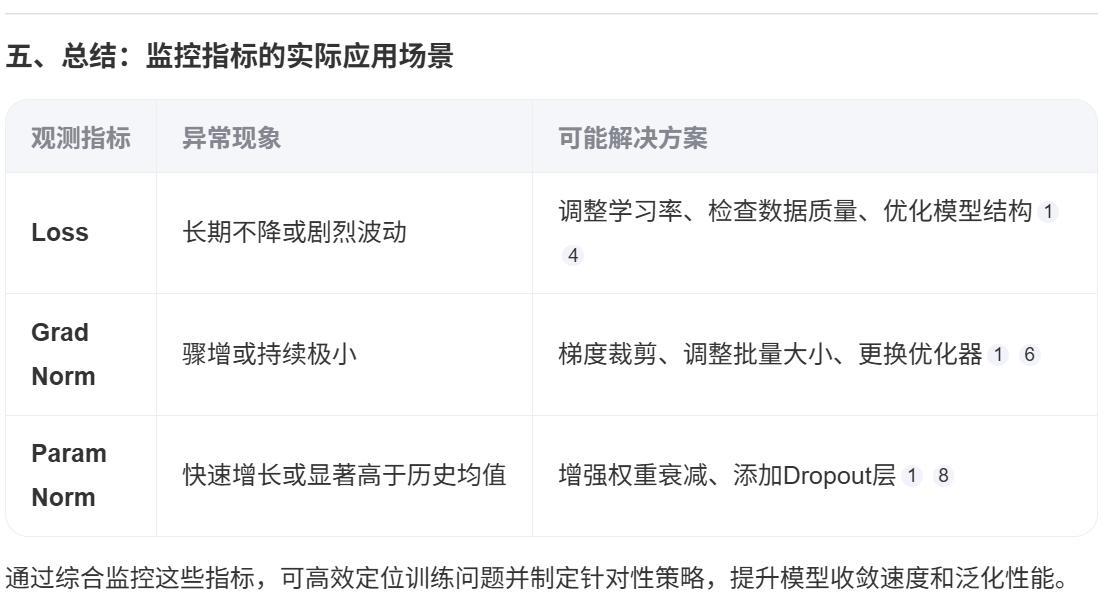
五、总结:监控指标的实际应用场景
观测指标 异常现象 可能解决方案
Loss 长期不降或剧烈波动 调整学习率、检查数据质量、优化模型结构14
Grad Norm 骤增或持续极小 梯度裁剪、调整批量大小、更换优化器16
Param Norm 快速增长或显著高于历史均值 增强权重衰减、添加Dropout层18
通过综合监控这些指标,可高效定位训练问题并制定针对性策略,提升模型收敛速度和泛化性能。
相关:

posted on 2025-05-28 11:18 Angry_Panda 阅读(2136) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号