
元强化学习算法(Meta-RL)—— MAML —— MAML-TRPO算法,实现细节:multi-gradient steps 多步梯度更新应该是在training阶段还是在testing阶段,更或者是同时在training阶段和testing阶段同时进行
相关:
https://github.com/tristandeleu/pytorch-maml-rl/issues/46
在MAML的原始论文中只是提到了mutli-gradient steps这个操作,但是并没有给出太详细的描述,然后给出了一个multi-gradient steps操作在 2d-navigation task 实验中的性能曲线图,如下:
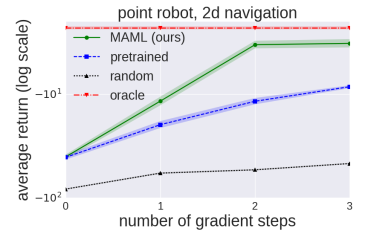
( 见:https://github.com/tristandeleu/pytorch-maml-rl/issues/46 )
有网友复现后提出了一个问题,那就是这个网友使用了 num_steps=5 的方式在training阶段和testing阶段,然后出现了不同的性能表现,如下图:
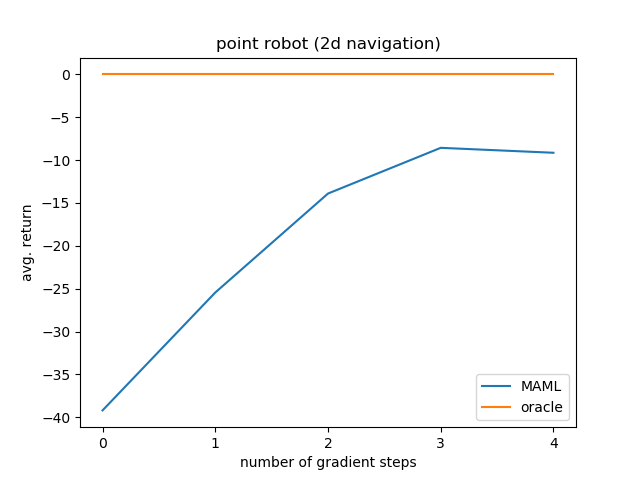
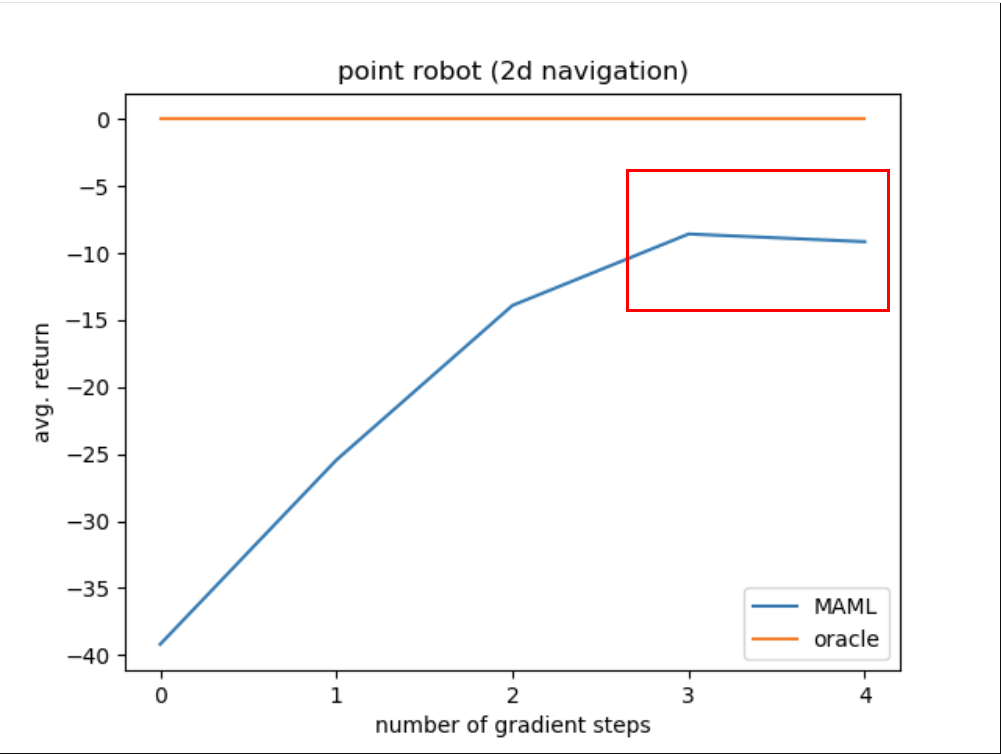
可以看到,在原始论文MAML-TRPO中使用multi-gradient step方式训练后在测试时在one gradient step训练后的性能表现的reward为 -10,而网友的复现却是 -25,可以说其中有着巨大的差距,这也就出现了一个疑问或者说是问题,那就是在MAML-TRPO的原始论文中是否是在training阶段和testing阶段同时进行multi-gradient steps,还是说只是在testing阶段进行了multi-gradient steps而没有在training阶段进行multi-gradient steps?(因为在testing阶段是必然要使用multi-gradient steps的,因此只存在在training阶段是否使用multi-gradient steps这种情况)
为此该网友尝试在training阶段不使用multi-gradient steps,而是使用 one gradient step 方式在training阶段,然后只是在testing阶段使用multi-gradient steps进行测试,这时在testing 阶段one gradient step训练后的性能表现的reward为 -10,此时的表现和MAML-TRPO原始论文中的性能表现一致。
为此吧主的回复:

该回复肯定了原始论文中的实现是在training阶段只进行one gradient step,具体:
In all reinforcement learning experiments, the MAML policy was trained using a single gradient step with α = 0.1.
multiple gradient steps 只能在testing阶段进行,而在training阶段只能进行one gradient step方式的训练。
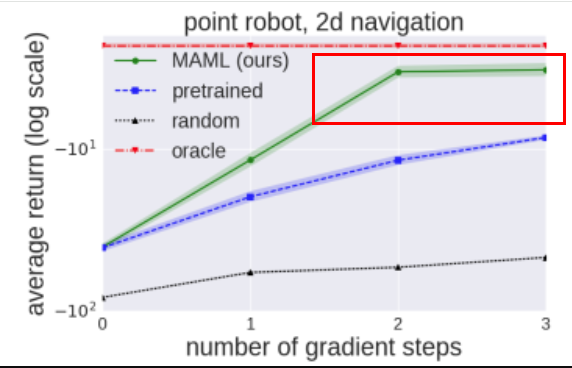
而且,最为需要注意的是,如果再testing阶段进行multiple gradient steps 时使用过多的steps,比如这里的num_steps=5,那么在step为3或者为4时测试的性能会出现一定的下降,这种有些类似于over-fitting的过拟合。
如下图均有这种现象:
posted on 2025-04-14 14:54 Angry_Panda 阅读(62) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号