

Deep Learning —— 异步优化器 —— RMSpropAsync —— 异步RMSprop
看到了一个概念,叫做异步更新优化器,也就是使用异步的方式实现deep learning中的参数优化的method,这个概念比较新奇,虽然看到的异步更新神经网络的代码比较多,但是很少见到有人单独把异步优化器这个概念单独提出来,大部分实现异步更新的算法中都是对各个线程加锁以实现异步更新神经网络参数的。
那么这种单独的异步优化器(RMSpropAsync)和加Lock锁的异步更新参数的方法有什么不同呢?
看了一下其实没啥不同的,可以说基本就是一个东西,只不过实现方法不同而已。我们现在所使用的优化器除了SGD(随机梯度下降)方法外都是要保存之前计算梯度下降的过程结果的,这个过程结果也叫做“二阶动量部分”,使用异步优化器(RMSpropAsync)方法则是在不同线程进行梯度更新时从全局中取出这个之前的计算结果,保存在自己的线程中,因此每个线程在更新时都会单独从全局中取出并保存一份过程结果,并在线程内进行计算并得到更新后的神经网络参数,但是要注意,由于异步优化器(RMSpropAsync)一般不采用加锁的方法,因此在更新“二阶动量部分”和神经网络参数部分已经可能与其他线程发生竞争,因此如果不加锁异步优化器(RMSpropAsync)是不能完全保证线程安全的。
可以说,不加锁的异步优化器(RMSpropAsync)只能一定程度上减少线程竞争带来的不同步问题,但是根据一些网上的资料显示,该种方式其最大优点时加快异步优化器的运算,也就是说提速才是该方法的主要目的。
============================================
不过也有些代码实现对异步优化器(RMSpropAsync)采用了一些微小的差异改变,如:
代码地址:
https://github.com/chainer/chainerrl/blob/master/chainerrl/optimizers/rmsprop_async.py
异步优化器(RMSpropAsync)代码:
def init_state(self, param): xp = cuda.get_array_module(param.array) with cuda.get_device_from_array(param.array): self.state['ms'] = xp.zeros_like(param.array) def update_core_cpu(self, param): grad = param.grad if grad is None: return hp = self.hyperparam ms = self.state['ms'] ms *= hp.alpha ms += (1 - hp.alpha) * grad * grad param.array -= hp.lr * grad / numpy.sqrt(ms + hp.eps) def update_core_gpu(self, param): grad = param.grad if grad is None: return cuda.elementwise( 'T grad, T lr, T alpha, T eps', 'T param, T ms', '''ms = alpha * ms + (1 - alpha) * grad * grad; param -= lr * grad / sqrt(ms + eps);''', 'rmsprop')(grad, self.hyperparam.lr, self.hyperparam.alpha, self.hyperparam.eps, param.array, self.state['ms'])
优化器(RMSpropAsync)代码:
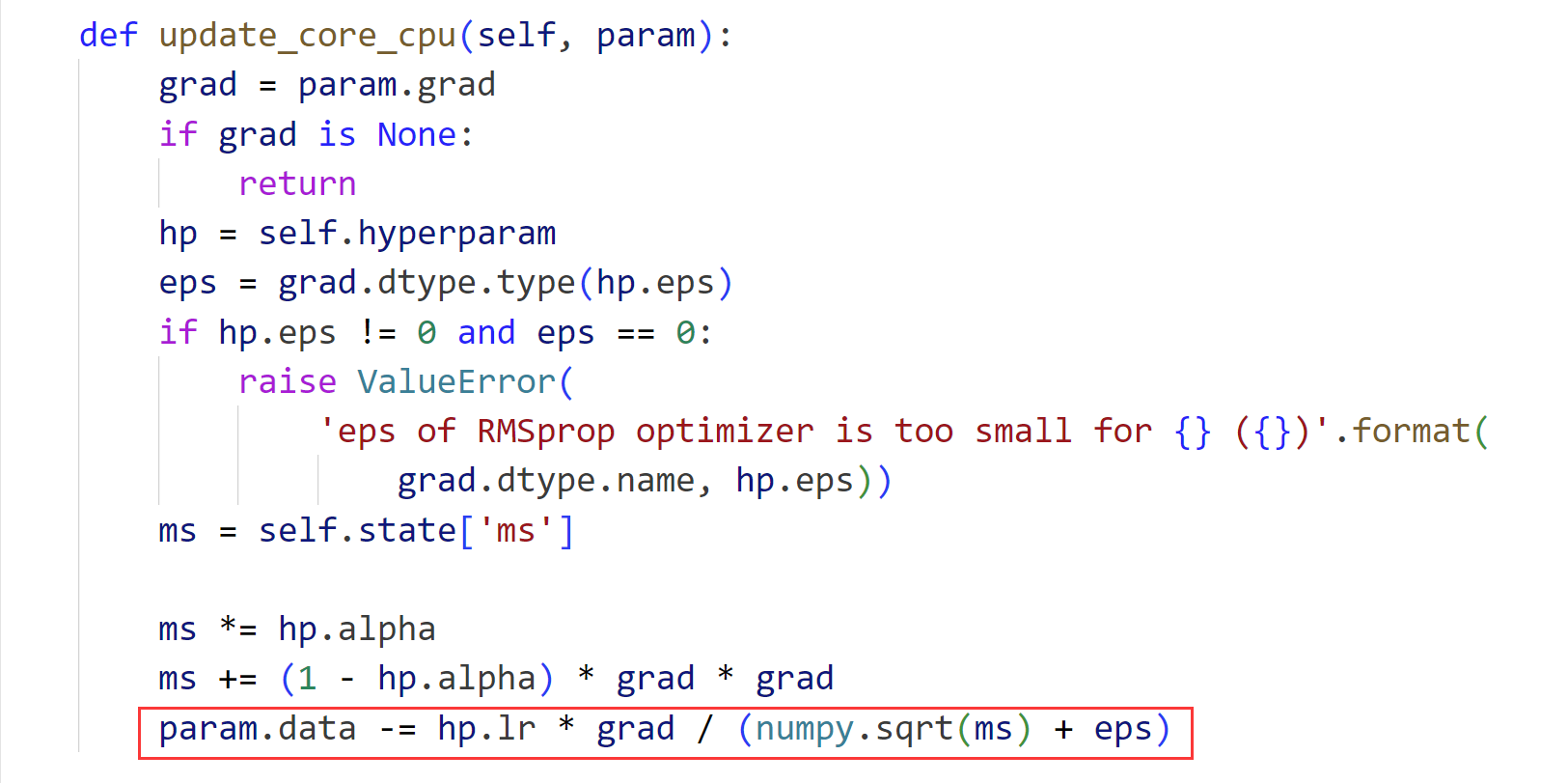
----------------------------------------------------------------------
可以看到在这个框架下所实现的差别是epsilon变量是否在开方运算内:
================================================
附注:


posted on 2023-10-14 11:07 Angry_Panda 阅读(81) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号