大连人工智能计算平台——华为昇腾AI平台——高性能计算HPC——如何在MPI中支持multiprocessing和fork操作——如何在HPC平台上使用pytorch——是否可以通过调度器的提交参数绕过HPC的计费系统
本文要讨论的就是如何在MPI中支持multiprocessing和fork操作,但是这个问题同时也是如何在HPC平台如何使用pytorch的问题,可以说这两个问题其实是同一个问题,而这个问题的解决过程中又产生了另一个问题,你就是是否可以通过调度器的提交参数绕过HPC的计费系统?
2023-08-28 00:09
=============================================
<br/>
<br/>
2015年1月21日 14:32
好长时间之前的一个blog了,今天突然重新看到,于是决定给补上。
<br/>
先了解一下超算系统是如何计费的:






<br/>




<br/>
<br/>
其实本文的这个问题之所以会别提出,是因为我发现华为的超算的多瑙调度器不会和其他的超算调度器那样为一个进程指定使用几个CPU核心,那么假设华为的超算是因为不会对运行的进程对CPU核心的调度有限制,那么我在调度器中提交使用一个进程,然后我在这个进程中fork出128个进程,如果这128个fork出的进程不被限制CPU核心(也就是说不会被指定运行的CPU核心),那么我们是不是只用交一个CPU机时的钱就使用了128个超算的机时呢,如果这样可行,那么我们是不是就一定程度上绕过了华为的超算的计费系统呢。
<br/>
<br/>




华为的 多瑙调度器(Huawei Daonuo Scheduler)是华为在高性能计算(HPC)领域使用的资源调度和管理系统,它支持多种计算任务的调度,包括传统的 MPI 作业和现代的分布式计算任务。
关于您提出的问题,多瑙调度器 提交的 MPI 任务在进程中 fork() 子进程后,是否会在额外的 CPU 上运行,主要取决于以下几个因素:
1. MPI 任务与子进程的 CPU 亲和性
- MPI (Message Passing Interface) 是一种用于并行计算的通信协议,通常通过多进程并行计算来提升计算效率。MPI 任务在启动时,通常会由调度器分配固定的 CPU 核心,并且每个进程会绑定到一个特定的核心上。
- 当你在 MPI 程序中调用
fork()创建子进程时,默认情况下,这些新创建的子进程并不会自动绑定到额外的 CPU 核心上。它们通常继承父进程的 CPU 亲和性,可能会继续在与父进程相同的 CPU 核心上运行,除非有额外的设置。
2. CPU 亲和性管理
- 子进程 CPU 亲和性:当你在 MPI 程序中
fork()新进程时,通常需要明确指定子进程运行在哪些 CPU 核心上。这可以通过以下几种方式实现:- 手动设置 CPU 亲和性:在
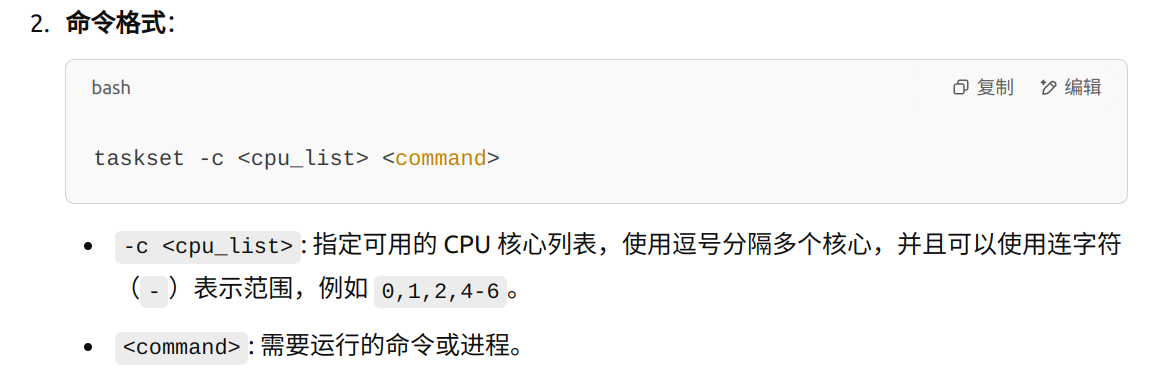
fork()后,使用taskset或类似的机制,手动设置子进程的 CPU 亲和性,确保它能够在额外的 CPU 核心上运行。 - MPI 的进程绑定策略:一些 MPI 实现(如 OpenMPI、Intel MPI 等)允许在启动时配置进程绑定策略。如果你希望每个进程及其子进程运行在不同的 CPU 上,可以在提交 MPI 作业时配置进程的 CPU 绑定策略。
- 手动设置 CPU 亲和性:在
3. 多瑙调度器的资源分配策略
- 资源分配与 CPU 核心的绑定:多瑙调度器在调度作业时,会根据作业的资源需求分配一定的 CPU 核心和内存资源。MPI 作业的每个进程在启动时会被绑定到指定的核心上。因此,若你通过 MPI 启动了多个进程,这些进程将根据调度器分配的 CPU 核心运行。
- 如果在作业中调用了
fork()创建新的子进程,这些子进程默认会继承父进程的 CPU 亲和性设置。除非你手动调整,否则它们可能会运行在与父进程相同的 CPU 核心上,而不会自动扩展到其他核心上。
4. 如何确保子进程运行在额外的 CPU 上
- 修改进程亲和性:可以通过在代码中手动设置 CPU 亲和性来确保
fork()创建的子进程运行在额外的 CPU 上。例如,在子进程中调用taskset或sched_setaffinity等系统调用,明确指定子进程运行的 CPU 核心。 - MPI 配置选项:某些 MPI 实现(如 OpenMPI)提供了进程绑定(Process Binding)的配置选项,可以在运行时通过配置文件或命令行参数指定进程和线程的绑定策略,以确保进程及其子进程运行在指定的 CPU 核心上。
例如,在 OpenMPI 中,可以使用 --bind-to 选项来设置进程绑定策略:
总结
- 如果你在 多瑙调度器 中提交一个 MPI 作业,并且在进程中通过
fork()创建子进程,这些子进程默认会继承父进程的 CPU 亲和性,即它们通常会运行在与父进程相同的 CPU 核心上。 - 为了让子进程运行在额外的 CPU 核心上,你需要在程序中或在提交作业时手动设置 CPU 亲和性,确保子进程能够分配到新的核心。你可以使用
taskset或类似工具手动控制子进程的 CPU 亲和性,或者在 MPI 配置中设置合适的进程绑定策略。
++++++++++++++++++++++++++++++++++++++++++++++++++
可以这么说,华为的这个超算调度器和其他的调度器还是有些不一样的,华为的这个调度器估计是自用的,所以这个调度器在计费上搞的就像有各种漏洞和bug一样,因为其他的超算调度器都会默认设置MPI进程的亲和性,比如固定锁死启动的进程在某个CPU核心上,但是华为的调度器却不会,因此这就出现了本文title的这个问题,不过像本文title中的那种搞法貌似可以钻漏洞,其实效果不一定好,必然一个主机是128个CPU核心,你申请的时候写的配置是一个CPU核心,于是调度器把你的这个进程分配到一个其中127个核心已经分配给其他计算任务的这么一个主机,然后你在这个唯一空闲并分配给你的主机CPU内核上使用本文前面的这种钻漏洞的方法fork并运行128个CPU子进程,这时其实你并没有赚到啥便宜,因为你的这128个子进程是和另外用户的127个进程在竞争这128个CPU核心,最后反而导致你的计算时间被拖长;这种情况在你申请更多的CPU核心并且分布在不同主机上的时候情况更加加剧,比如你申请32个进程运行在32个主机上,然后每个主机申请一个CPU核心,但是你使用这个方法在每个主机上运行128个进程,而每个主机上的其他127个CPU核心其实已经分配给其他计算任务,这样的话你完成计算任务的时间会是你计划的2倍时间,虽然这样依然可以给你省掉大笔的费用,但是你的目标运行时间却处于在一种极为无法预测的状态。
再比如在华为的调度器中我们可以申请独占一个主机,比如只在这个主机上申请一个CPU核心,这样这个主机的其他127个CPU核心都被空闲,但是实际这个调度器在计费是依然是按照一个CPU核心的价格来计费的,这样就搞的占了127倍的便宜似的:

您说:
ChatGPT 说:
但是即使使用这种方法可以使fork出的子进程不和父进程在一个CPU核心上,那么会不会就一定可以逃避计费系统呢,这也是不一定的:
超算系统的计费方式通常是基于资源的使用量、时间和计算能力来计算费用。具体的计费方法会根据不同的超算中心、提供的服务以及所使用的计算资源的种类有所不同。以下是常见的超算系统计费模式:
1. 按计算时间计费
- 计算时间是最常见的计费方式,用户根据所使用的计算时间来支付费用。这通常是基于每小时或者每分钟的使用时间。
- 超算系统会监控用户作业的运行时间,从作业启动到结束,根据所占用的CPU核心数和作业的持续时间来计算费用。
示例:如果一个用户运行了一个使用100个CPU核心的作业,运行时间为10小时,那么用户将按100核心 × 10小时来计费。
2. 按资源使用量计费
超算系统可以基于计算资源的使用量(如CPU核心、GPU、内存、存储等)来计费。
- CPU/GPU核数:根据使用的计算节点数、核心数或GPU数量来计费。不同种类的资源(例如,传统CPU与高性能GPU)可能有不同的计费标准。
- 内存使用:有些超算系统还会根据作业请求的内存量来计算费用。如果作业的内存需求较大,费用可能会更高。
- 存储使用:如果作业需要大量的存储空间,超算系统会根据存储的占用量进行计费。
3. 按作业类型计费
有些超算系统根据作业的类型来进行计费,不同类型的作业可能会有不同的计费标准。
- 普通作业与优先作业:用户可以选择普通作业或优先作业,优先作业可能会有更高的费用,且可能会获得更多的资源。
- 交互式作业与批处理作业:交互式作业可能会比批处理作业更贵,因为交互式作业通常需要占用更多的计算资源和持续的操作。
4. 按作业优先级计费
- 超算系统常常提供不同的优先级。优先级较高的作业(例如VIP用户、科研项目或长期合作伙伴)可能会获得更高的资源优先级和更快的排队时间,通常需要支付更高的费用。
- 低优先级的作业可能需要等待更长时间,但其费用通常较低。
5. 按节点类型计费
- 高性能计算集群中的不同节点(例如具有高速网络、专用GPU的节点)通常会有不同的计费标准。
- 标准节点与高性能节点的收费可能有所不同,后者通常会更贵,因为它们提供更强的计算能力。
6. 按预留资源计费
- 预留资源模式允许用户提前预定特定数量的计算资源(如CPU核心、GPU、内存等)并确保在指定时间内使用这些资源。预留资源通常较为昂贵,但可以避免在高峰时段排队等候。
7. 积分制或信用制计费
- 一些超算中心采用积分制或信用制的计费方式,用户通过预存积分或信用额度来支付资源使用费用。
- 在这种模式下,用户可以根据自己的需求购买相应的积分或信用额度,然后通过积分/信用来支付相应的资源使用。
8. 免费配额与超额费用
- 许多超算中心会为研究人员或合作项目提供一定的免费配额,用户可以在一定的限制内使用超算资源而不需要支付费用。
- 超过免费配额的部分则会按照超额费用进行计费。
9. 按作业复杂度和算法要求计费
- 如果作业涉及特殊的计算需求,如使用某些高性能算法、大规模并行计算或深度学习等,系统可能会按照作业的复杂度、计算需求和负载来进行计费。
10. 按网络带宽使用计费
- 如果用户需要大量的网络带宽(如进行大规模数据传输),超算中心也可能会基于带宽使用量来计费。特别是涉及跨数据中心或高性能网络的作业,带宽费用可能会占很大比例。
总结:
超算系统的计费通常是根据所使用的计算资源(如CPU核心数、GPU、内存、存储、网络带宽等)以及使用时间来计算的。具体的计费方式和标准因超算中心的不同而有所差异。用户可以根据自己的需求选择合适的资源,合理规划使用方式,以降低计算成本。
如果超算的计费系统确实是根据提交的任务申请来计费的,那么这种方法确实可以在一定程度上逃避计费,不过如果计费系统是实时监测的那种,那么也无法逃避计费,不过考虑到超算计费系统的设计的可行性,估计还是根据提交申请的要求来进行计费的,因此还是大概率的可以通过该方式逃避计费,不过也像上面说到的那种,使用该种方式同时也逃避了调度器的正确的计算资源的分配,最终是否可以加速计算任务的完成或者加速效果如何都是不确定的,这需要看你调度到的主机上是否有其他的任务运行。
PS:
本文只是在技术原理上来讨论华为的多瑙调度器是否可以存在逃避调度器监测的一种技术可能性,同时也是对华为调度器是否健全性的一种思考。
相关:
https://support.huawei.com/enterprise/zh/doc/EDOC1100347973/138f4ded#ZH-CN_TOPIC_0000001501584061
https://support.huawei.com/hedex/hdx.do?docid=EDOC1100385995&lang=zh&idPath=23710424|251364417|9856629|262279633|253585671
https://support.huawei.com/hedex/hdx.do?docid=EDOC1100385995&tocURL=resources%2Fhedex-homepage.html
=============================================
posted on 2023-08-28 00:09 Angry_Panda 阅读(276) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号