

multi-GPU环境下的batch normalization需要特殊实现吗?
3年前曾经写过关于分布式环境下batch normalization是否需要特殊实现的讨论:
batch normalization的multi-GPU版本该怎么实现? 【Tensorflow 分布式PS/Worker模式下异步更新的情况】
==============================================
当时我给出的观点就是在多卡环境下batch normalization使用每个step内的各显卡batch上的相关值进行同步的话会和单卡情况取得相似的结果,因此我给出的结论就是多卡情况下是没有必要针对batch normalization算子开发什么高深的替代版本,你不论是同步更新还是异步更新的情况下对每个显卡上运行得到的batch normalization算子中的参数进行同样的update就可以了,因为从我之前做的仿真使用中可以看出不论是单机情况还是多卡同/异步更新情况下都是对batch normalization算子中参数的估计,而这几种方法之间的差别其实不大,可以说极为相近,也正是如此在几年前我就得出了没有必要为多卡/分布式环境下设计特殊的batch normalization算子,不管是同步更新还是异步更新同时对batch normalization算子中的参数进行同样操作就和单卡情况下不会有太大的差距。几年前得到这个结论的时候只是考个人推断和仿真实验获得的,并没有在实际的代码上跑过,当时主要的原因就是省时、省力,同时也是对但是网上的各种针对多卡/分布式环境下开发出的特殊batch normalization算子的一种反对意见,最近看到一篇可以佐证我观点的文章这里给出相关链接并摘录出部分内容:
https://zhuanlan.zhihu.com/p/402198819
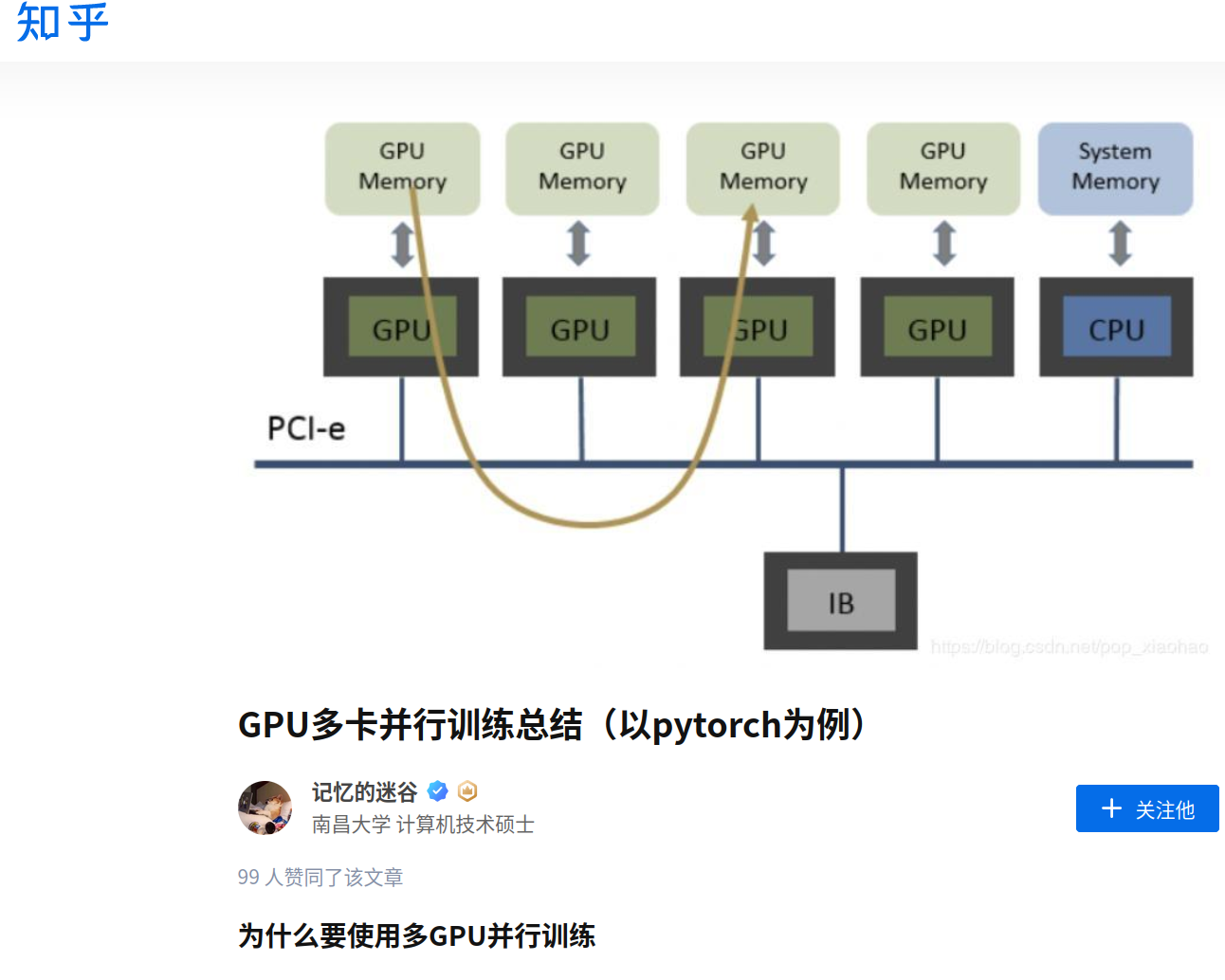
=========================================
在上面的那个文章中给出了讨论和实验:
-------------------------------------------------
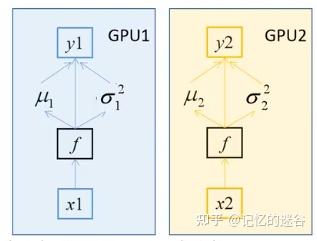
假设batch_size=2,每个GPU计算的均值和方差都针对这两个样本而言的。而BN的特性是:batch_size越大,均值和方差越接近与整个数据集的均值和方差,效果越好。使用多块GPU时,会计算每个BN层在所有设备上输入的均值和方差。如果GPU1和GPU2都分别得到两个特征层,那么两块GPU一共计算2 4 个特征层的均值和方差,可以认为batch_size=4。注意:如果不用同步BN,而是每个设备计算自己的批次数据的均值方差,效果与单GPU一致,仅仅能提升训练速度;如果使用同步BN,效果会有一定提升,但是会损失一部分并行速度。
BN如何在不同设备之间同步?
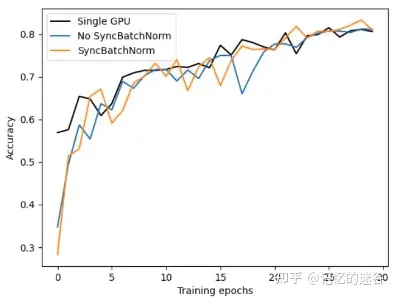
下图为单GPU、以及是否使用同步BN训练的三种情况,可以看到使用同步BN(橙线)比不使用同步BN(蓝线)总体效果要好一些,不过训练时间也会更长。使用单GPU(黑线)和不使用同步BN的效果是差不多的。
-------------------------------------------------
我三年前的文章指出多卡/分布式情况下使用同步或异步的方式更新batch normalization算子中的参数会和单卡情况下的性能相似,而上面的这篇文章也同样验证了这个观点;甚至从上面的这个文章中可以看到多卡情况下同步更新batch normalization算子中的参数往往会得到更好的效果,当然这个性能相差的也不是十分的明显。
这里我甚至有个新的观点,那就是多卡情况下即使不对batch normalization算子在训练过程中更新(同步、异步更新都包括),而是在训练结束后再进行取均值的更新方式也不会有太大的性能差距,总结的来说就是我个人认为多卡/分布式环境下batch normalization算子的参数的计算使用下面三种方式都和单卡情况下相差不大:
1. 训练过程中同步更新batch normalization算子参数;
2. 训练过程中异步更新batch normalization算子参数;
3. 训练结束后再更新batch normalization算子参数;
不过这三种方式即使相差不大也必然虽然一个谁优谁劣的问题,而这个回答确实是难以给出的,因为这个定论需要对不同的数据集和任务进行计算,大量的获取各种情况下的最终性能指标才可以有个定论,不过这里也给出我的个人建议,那就是:
对性能要求较为严格的情况下建议使用第一种方式,即训练过程中同步更新batch normalization算子参数;而对性能要求的容忍度较大的情况下可以考虑使用第三种方式,也就是训练结束后再更新batch normalization算子;而对于第二种方式,也就是训练过程中异步更新batch normalization算子其实是要单独分析的,因为pytorch是本身不支持异步更新的,当然你可以自己来进行实现(官方只给了同步更新的code),而TensorFlow由于并不是像pytorch使用MPI而是使用自己公司的protobuffer因此可以完美的支持异步更新(异步更新需要考虑如何处理不同时延下的更新策略,需要单独设计分布式算法来决定何时合并参数何时抛弃参数),所以对于异步更新batch normalization算子参数的方式并不是很建议。
=========================================
posted on 2023-07-27 17:14 Angry_Panda 阅读(101) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号