
python爬虫入(cai)门(keng)总结(一)
【请各位大佬不要吐槽本人的碎碎念,以下是作为一个本科低年级学生,在疯狂踩坑之后写下的一点小总(bei)结(wang),以便不时之需
同时也方便一下和我同样是小白的朋友们,就不需要到处查,到处踩坑,到处自闭了】
【以下文档基于本人win10,Python版本3.6.8,不同操作系统,不同python版本会有出入,请读者慎重!】
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
新手安装python IDE

好在还是个前端小白,有一点点的小技巧
复制一下浏览器访问吧
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
好了,接下来我就默认你已经装好了pycharm,你以为你就开始愉快的开始爬虫学习了?
恭喜你,你的踩坑之旅才刚刚开始!
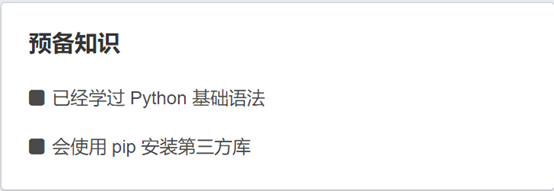
这是教程给出的预备知识,我觉得其实语法什么的,只要是有过编程基础的,不管c,vb,c++,java什么的,基本对着python的代码就能看懂,什么看不懂就去百度什么好了,这都不是问题。
我们重点来讲pip第三方库的安装。
对于pip,你下一个高版本一点的python就会自带,我们就图方便不去踩坑了。
装第三方库的话我举例requests_html,就输入命令
pip install requests_html
,然后坐吃等死就行了,没什么技术含量。
装好了requests_html,我们兴致勃勃地拿了一段代码,打算见证奇迹。例如:
from requests_html import HTMLSession session = HTMLSession() r = session.get('https://movie.douban.com/subject/1292052/') print(r.text)
右键,run!完美!(以上是你的想象)
现实是:pycharm给了你无法引入第三方库地报错!awsl!我们不是已经装好了requests_html吗!
https://blog.csdn.net/qq_38223945/article/details/81485445 请阅读此篇教程,配置你的python路径。虽然这篇的作者是mac系统,但丝毫不影响win用户的意会。
终于!我们大功告成!第一个爬虫程序√
入门了?不,踩坑刚刚开始。
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
关于新手入门的爬虫教程我这边有一个推荐
https://www.python123.io/index/tutorials/web_crawler_intro 基本马上可以上手
但有个痛点就是,你看完这篇教程以后局限性还是有点大的。
但!但!但!无敌完美适合你有个项目里面改一个小细节要用爬虫,一个下午的时间搞出来就完事了。深入研究还是另谋高就!
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
我们用python其实多半是依赖第三方库,你很快就会发想pip下库特别慢,而且容易报ReadTimeoutError。
下面就是一种解决方案:
Pip安装ReadTimeoutError报错

(图片似乎看不太清,没事不是重点【ReadTimeoutError】)
一般情况下PIP出现ReadTimeoutError都是因为被GFW给墙了,所以一般遇到这种问题,我们可以选择国内的镜像来解决问题。
【在Windows下:
C:\Users\Administrator\下新建pip文件夹,在创建pip.ini文件,拷贝下面代码进去,保存。
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
】
本人在装matplotlib的时候亲测有用,但在apscheduler上似乎翻车了?但是但是但是!!!(重要的事情说三遍!)本人不服气一模一样的命令又执行了一遍,然后又可以了?
好叭软件的是玄学,如果大家遇到这个问题就多试几次叭~
原文:https://blog.csdn.net/abcabc77777/article/details/53456453
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
现在我们假如说要爬一个有很多页的书店网页里面的全部书名,可能在爬到三四页、七八页的时候就会有如下报错
pyppeteer.errors.NetworkError: Protocol Error (Runtime.callFunctionOn): Session closed. Most likely the page has been closed.
https://github.com/miyakogi/pyppeteer/pull/160/files(解决方法)
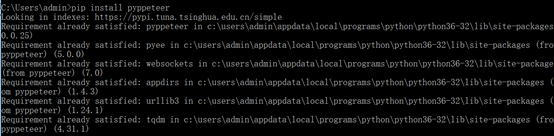
如果找不到connection.py的话(我全局搜索就没搜出来QAQ),就去cmd(假装安装一次pyppeteer),就能看到你之前安装的路径了,如下图所示
https://blog.csdn.net/weixin_39198406/article/details/86719814
别人整理出来的pyppeteer报错与解决方案汇总)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号