逆向分析--以buuctf的一道Re为例
一、题目来源:buuctf-Reverse (刮开有奖)
二、复盘分析(思路参考这篇博客:(https://blog.csdn.net/afanzcf/article/details/119682630))
1.源文件下载下来,打开exe:

没有什么有用的信息
2.放进exeinfope.exe查看一下文件的属性:
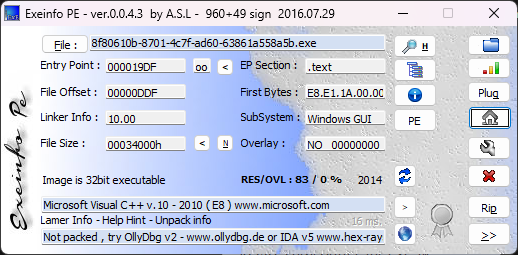
显示是一个32位无壳的exe程序
3.用32位的IDA Por来进行分析:
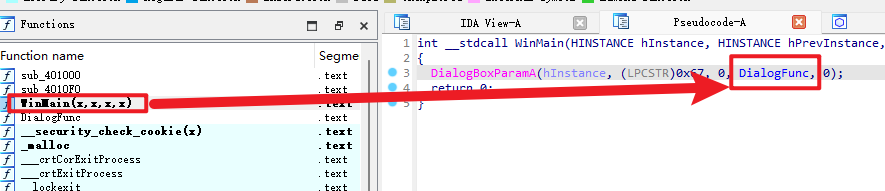
(1)这里可以直接找到main函数然后点击进行,也可以用shift+f12进行字符串的搜索来找关键的字符信息:
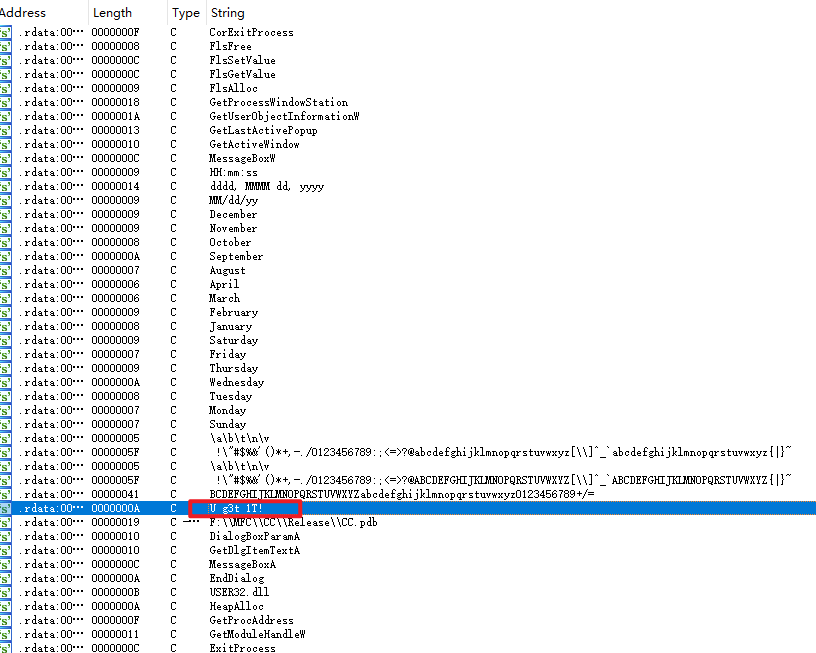
这里有个敏感信息:U g3t 1T!,也就是you get it!然后双击跟进去看一下
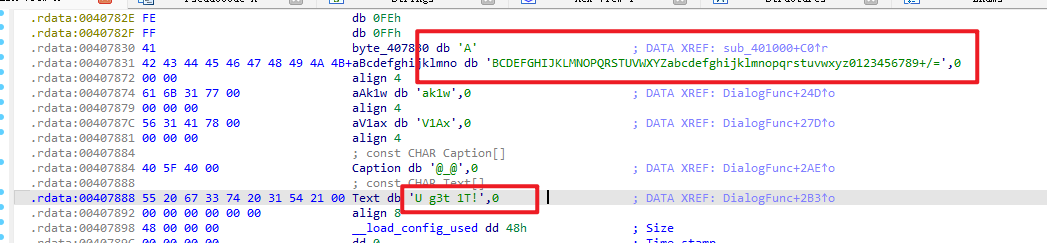
还发现一段字母表
(2)用ctrl+x来交叉引用,找它的源地方:
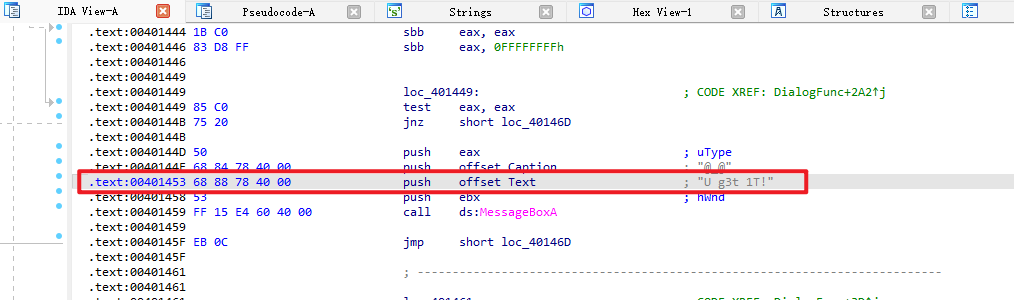
(3)F5反汇编成C语言:
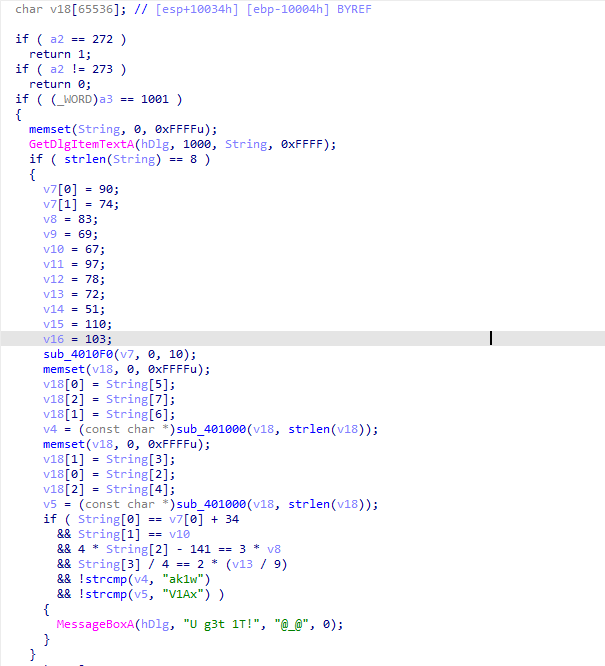
(4)分析加密函数:
第1段:
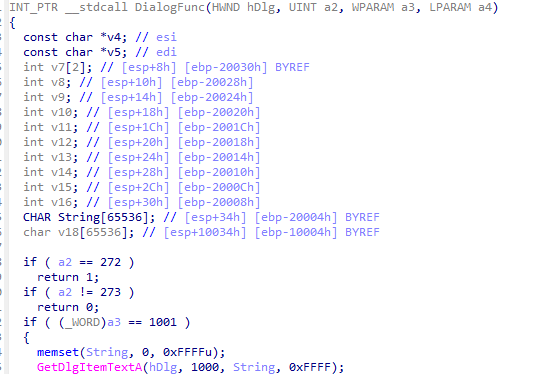
这里是是进行函数的初始化,申请足够的地址空间,memset初始化函数
第2段:
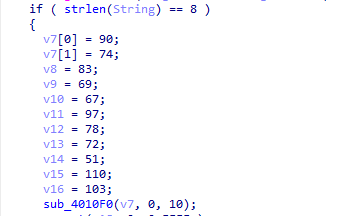
这里是进行字符串的长度判断,当我们输入的字符串长度为8时就继续下面的操作,也就说明输入的flag字符串的长度为8,下面定义了一段存储变量v7-v16,sub_4010F0((int)v7, 0, 10) 对从 v7 开始的数组进行排序,从索引0到10,通过sub_4010F0函数来对这一串数组进行加密,将这一串数组转换为字符串的形式为:
ZJSECaNH3ng //一共11个字符
第3段sub_4010F0加密函数:

这里通过指针的形式来将这11个字符串进行加密转换,将其转换成 C语言的形式,看一下它的加密效果:
#include <stdio.h>
int sub_4010F0(char* a1, int a2, int a3)
{
int result; // eax
int i; // esi
int v5; // ecx
int v6; // edx
result = a3;
for ( i = a2; i <= a3; a2 = i )
{
v5 = i;
v6 = i[a1];
if ( a2 < result && i < result )
{
do
{
if ( v6 > a1[result])
{
if ( i >= result )
break;
++i;
a1[v5] = a1[result];
if ( i >= result )
break;
while ( a1[i] <= v6 )
{
if ( ++i >= result )
goto LABEL_13;
}
if ( i >= result )
break;
v5 = i;
a1[result] = a1[i];
}
--result;
}
while ( i < result );
}
LABEL_13:
a1[result] = v6 ;
sub_4010F0(a1, a2, i - 1);
result = a3;
++i;
}
return result;
}
int main()
{
char str[] = "ZJSECaNH3ng";
sub_4010F0(str,0,10);
printf("%s", str);
return 0;
}
在这里将伪C代码转换为C语言代码可能会有疑惑,在伪代码中,有a1+ 4 x i,a1+4 X result,这样的字符,但是在C语言代码中,却没有了,后面参考了一下网上的博客和deepseek才知道:int是占四个字节,所以需要x4,是char型的话就不需要,因为在伪C代码中它传入的数组是数字型int型所以需要x4,但是我们在写C语言代码时传入的是字符串是char型所以就不需要x4。
了解到了一个数组寻址公式:
计算机会给每一个内存单元分配一个地址,计算机通过地址来访问内存中的数据,当计算机需要随机访问数组中的某一个元素时,它首先会通过下面的寻址公式,计算出该元素存储的内存地址:
a[i]_address = base_address + i * data_type_size
其中data_type_size表示数组中每一个元素的大小,在举例中,数组中存储的是int类型数据,所以data_type_size就为4个字节。
从这里,我们知道a1+4*i,也就是a1[i],a1+4 * result,也就是a1[result]
将伪代码的寻址方式改为数组寻址,然后将(_DWORD) 删掉,因为这是汇编的表示,所以伪代码变成了C语言代码。
运行这段加密的C语言代码:

得到:
3CEHJNSZagn
加密前后数组变化(发现只是进行了一下从小到大的一个排序):
加密前:90 74 83 69 67 97 78 72 51 110 103 //ZJSECaNH3ng
加密后:51 67 69 72 74 78 83 90 97 103 110 //3CEHJNSZagn
第4段 base64加密:
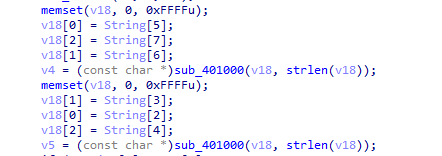
这里看到v4、v5 = sub_401000,跟进去看一下这个函数:

这里可以看到:
- 第一次处理输入字符串
String的索引5、6、7的字符(即第6、7、8个字符)。 - 第二次处理索引2、3、4的字符(即第3、4、5个字符)。
看一下byte_407830:

byte_407830是一个全局数组,包含标准的Base64编码字符。通常顺序为:A-Z、a-z、0-9、+、/。但具体内容需要查看实际内存地址0x407830来确定。从代码上下文推断,它符合标准Base64编码。
这里就可以推测,这里v4,和v5分别是字符串索引5,6,7和2,3,4经过base64加密后的结果
第5段if条件判断:

这里可以知道v4和v5base64加密后的字符为v4=ak1w,v5=V1Ax,进行base64解密:
ak1w ===> jMp
V1Ax ===> WP1
最后逐一分析每一条判断:
第一句:String[0] == v7[0] + 34,这里的v7[0],就是上面11个字符的第一个字符,通过升序排序后,v7[0]由一开始的Z变成了v7[0] = 3,3的ASCII码是51,51 + 34 = 85,85的ASCII码对应的是大写的 U,得到flag第一个字符。
第二句:String[1] == v10,v10在之前没加密的时候是67排在第5五位,加密排序后变成了74,3CEHJNSZagn,可以看到,加密之后的第五位是 J,得到flag第二个字符。
第三句:4 * String[2] - 141 == 3 * v8,v8在没加密之前,是排第三位,排序加密后可以看到排在第三位是E,E的ASCII码是69,所以3*69 + 141 / 4 = 87 ,87的ASCII为W,得到flag第三个字符。
第四句:String[3] / 4 == 2 * (v13 / 9),看到v13没加密之前排到数第四位,排序加密后可以看到排在第四位是Z,Z的ASCII是90,所以2(90/9)4 = 80 ,80的ASCII为P,得到flag第四个字符。
后面四个字符,就是base64加密的那几个,可以看到第三第四字符已经是WP了,说明,WP1在前,jMp在后。
最后将他们拼接在一起,得到,UJWP1jMp。
用flag{}为:
flag{UJWP1jMp}
三、总结
在伪C代码转C语言代码还是要非常仔细的阅读伪C代码,知道了计算机数组选址公式,发现伪C中的x4如果复制到C语言中就是两中加密结果了,还有要对base64加密有很敏锐的直觉,看到base64的编码表就要想到base64。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号