

OO第三单元 JML 规格单元总结
一、JML总体认知
JML(Java Modeling Language),Java 建模语言,是将程序设计中不严谨、有二义性的自然语言,用严谨、无二义性的数学语言进行表述的手段之一。这种严谨语言的使用,可大大提高代码安全性,降低因不同开发者间交流时的 “理解偏差” 导致程序故障的可能性。概括地说,其使用场景及效果可分为
1. 准确地在设计好的架构上进行细节实现——由规格到代码
你是个很强的架构师,你希望团队中的人能明白你想让他们做什么不做什么,你可以用 JML 。
在程序上层架构设计时,设计者只需要考虑各模块的工作环境(前置条件),需要承担的职责与可提供给使用者的功能(后置条件),以及不同操作会造成的影响(副作用),而不干涉职责与功能的具体实现方式。在不关心具体实现时写明各类与方法的 JML 规格,可在没有将程序从头到尾生产出来之前,就得到一个 “正确的骨架 ”,之后的工作就是代码填充,将各部分进行实现。这时,正因为设计者已经为各模块写出了清楚明确的规格要求,实现方才能够处理好各种情况下的正常行为。只要严格按照给定的规格做事,那么 100 个人写出来的程序,对外可见的效果几乎别无二致,而不会一人一个样的乱七八糟。同时,设计与实现相分离,利于使上层设计者保持头脑清醒,也使软件开发有法可依。
2. 准确地告诉使用者我的使用条件、行为如何——由代码到规格
你是个很强的库作者,你希望使用者能明白你的 API 何时能用何时不能用,用了会怎样,你可以用 JML 。
在写好一个实现特定功能的模块并暴露公共接口后,可能会有很多使用者都想用你的 “轮子”。从你已经写好的实现代码出发,用 JML 清楚严谨地声明你的代码什么时候才能用(前置条件),用了能干啥(后置条件),另外会把什么内容改变掉(副作用),这样使用者就能不看你的源码而掌握你的行为,保证自己的程序和你提供的工具结合使用而不出错。
3. 为测试程序的编写提供参考——由实现到测试
你是个很聪明的测试人员,你想看看别人的代码是否正确,你可以参考 JML。
在 JML 书写正确的前提下,如果一段代码完全提供了与 JML 描述相一致的服务,那可以说它基本是正确的。因此,JML 驱动测试对代码行为正确性的评判有着直接意义,黑盒测试时尤为明显(因为不可见内部代码,JML 几乎成了唯一依照准测)。编写对 JML 描述中的各种异常情况、各种正常情况的应对方法、各情况下的副作用进行针对测试的代码或样例,将会比简单的随机质量高得多。
4. 用数学逻辑进行推理证明——形式化
你有强大的数学功底,想要严格纯粹地证明程序的正确性,你可以使用 JML。
通过测试样例,是无法肯定地说程序是 100% 正确的,因为再多的测试样例,也覆盖不了无穷多的具体场景。只是随着高质量测试的增多,程序的可靠性在趋近于 100%。但有的时候,99% 和 100% 之间有着不可忽略的质的鸿沟。JML 提供了一个符号体系,将计算机程序与逻辑公理系统形成同构。证明程序 100% 正确的任务,因此转化成了公理系统中的逻辑推论——而这也正是数学这一形式科学所擅长的工作。这种映射,被称作 “形式化方法”。而只有通过形式化方法,才可以严谨地说,软件 100% 正确。
总的来说,JML 的本质意义是提供了一套无二义的规约。只要编程过程恪守契约精神 ,这套规约就能在以上等方面体现出惊人且关键的巨大作用。
二、容器特点与选择偏向
Java 的官方 JDK 提供给我们丰富的容器对象,用以在不同需求下有效组织、存储数据。在分析容器类的特点时,从头到尾地通读源码,是最准确、可靠且有助于能力培养的。但为了提纲挈领抓住关键,本文主要采用另一种可靠且便捷的了解容器的方法——看说明书看官方文档,仅在某些情况下补充源码辅助说明。
1. 容器框架图
Collection接口
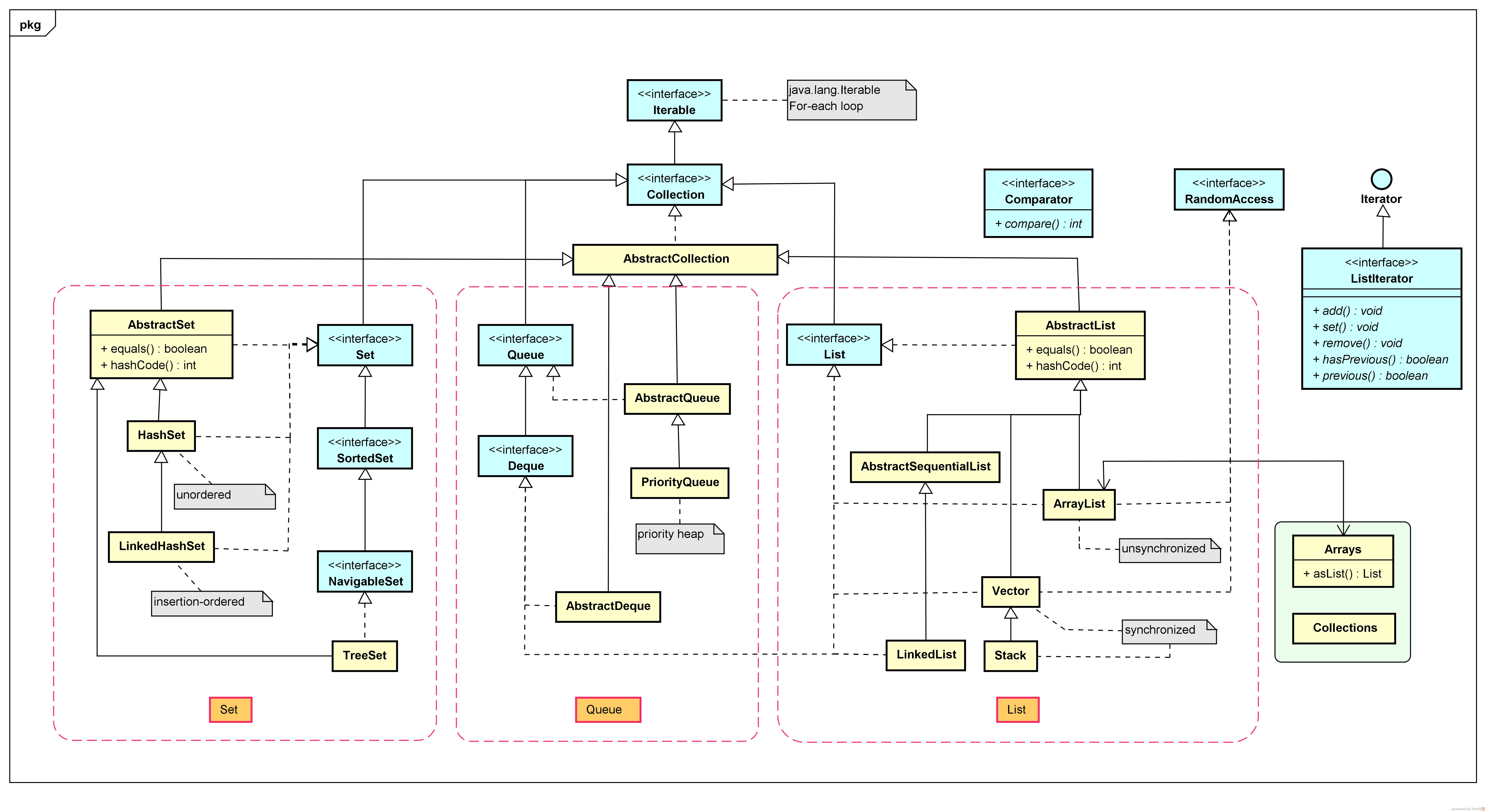
Map接口
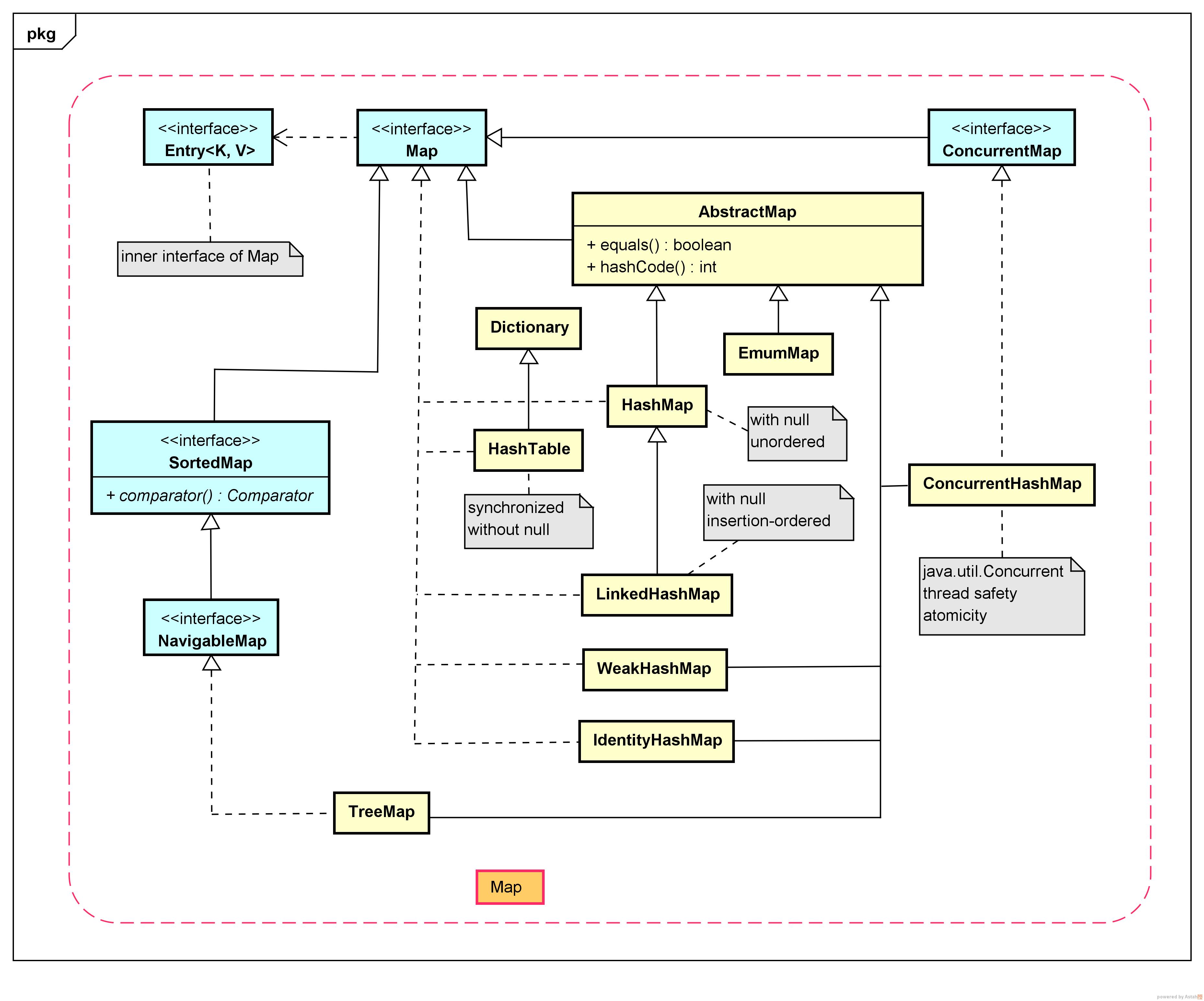
2.常用容器分析
-
ArrayList
Resizable-array implementation of the
Listinterface. Implements all optional list operations, and permits all elements, includingnull. In addition to implementing theListinterface, this class provides methods to manipulate the size of the array that is used internally to store the list. (This class is roughly equivalent toVector, except that it is unsynchronized.)The
size,isEmpty,get,set,iterator, andlistIteratoroperations run in constant time. Theaddoperation runs in amortized constant time, that is, adding n elements requires O(n) time. All of the other operations run in linear time (roughly speaking). The constant factor is low compared to that for theLinkedListimplementation.......
可简单理解为可变长数组。存储其中的数据有序,可重复,可为 null ,支持随机访问。返回大小、判断非空、按索引查找或写值,均为 O(1) 复杂度;向随机位置插入或删除元素,由于涉及到此索引之后的值前后移动的问题,故为 O(n) 复杂度;其他的操作也大致为线性复杂度 O(n) 。
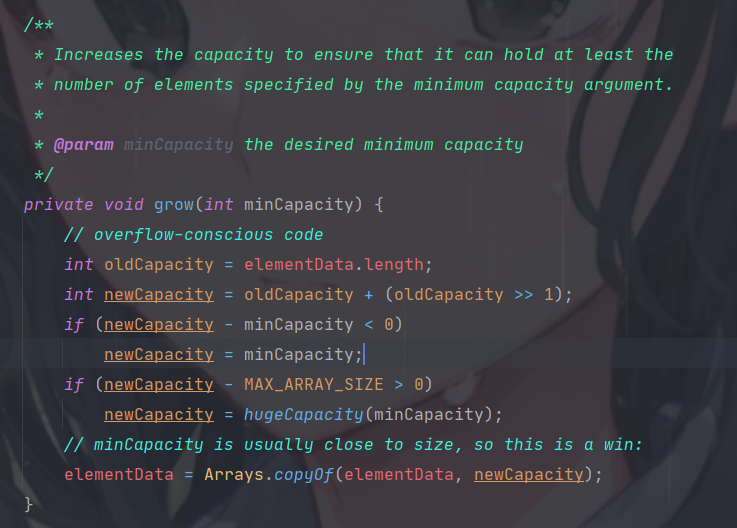
其可变长的实现方法为,每次申请定长的数组,并动态地更改数组实例。当发生添加操作时,容器需要的最小数据量比当前容量大时,默认将容量进行扩容至原有容量的 1.5 倍。若新容量仍不够容纳所有数据,则一次性将容量设置为所需数据量。之后,将原数组中的值拷贝到新的更大的数组中,并返回至新数据的添加(此时可保证容纳得下)。ArrayList 默认的初始容量为 10 。若对具体问题中的 ArrayList 容量有一个预估值,可在其实例化时,将初始容量作为参数传入构造器,以减少数组动态修正的次数,提高效率。源码 (java.util.ArrayList) 见下
![]()
![]()
另外,需要注意的是,ArrayList 是异步容器,在多线程环境下需要使用线程安全的 synchronizedList 类,即
List list = Collections.synchronizedList(new ArrayList(...)); -
HashMap
Hash table based implementation of the
Mapinterface. This implementation provides all of the optional map operations, and permitsnullvalues and thenullkey. (TheHashMapclass is roughly equivalent toHashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.This implementation provides constant-time performance for the basic operations (
getandput), assuming the hash function disperses the elements properly among the buckets. Iteration over collection views requires time proportional to the "capacity" of theHashMapinstance (the number of buckets) plus its size (the number of key-value mappings). Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important. 是基于 Map 接口实现的哈希表,其为无序结构,不保证容器中元素顺序与其加入顺序的关系,甚至不保证运行过程中,当前时刻元素顺序和下一时刻元素顺序相同(由于动态重哈希的存在)。如果哈希算法足够好(即冲突的可能性比较小,各元素都大概率分配到不同的桶 (bucket) 中。一般地,默认的哈希方法可视为较理想),则对于读写操作 get 和 put 都是常数复杂度 O(1) 。而对于迭代遍历操作的性能,则与其容量(即桶数)和数据量(即存储的键值对数量)有关。
同样地,HashMap 为异步容器,多线程时可使用 synchronizedMap 如下
Map map = Collections.synchronizedMap(new HashMap(...)); 另外,影响其运行时性能的主要因素还有动态导致的重哈希问题(rehash)。
An instance of
HashMaphas two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the
HashMapclass, includinggetandput). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.If many mappings are to be stored in a
HashMapinstance, creating it with a sufficiently large capacity will allow the mappings to be stored more efficiently than letting it perform automatic rehashing as needed to grow the table. Note that using many keys with the samehashCode()is a sure way to slow down performance of any hash table. To ameliorate impact, when keys areComparable, this class may use comparison order among keys to help break ties.名词解释:
-
bucket(桶):哈希函数值域中的元素。若 k1 和 k2 经哈希映射到同一个值 b1,则将二者以链表等形式组织起来,存放在 b1 处。可形象地将 b1 看作一个桶,k1 和 k2 都被装进了这个桶里。
-
capacity(容量):key 通过哈希函数允许映射到的值的数量,即哈希函数值集合的基数,亦即 “桶数”。
-
size(数据量):HashMap 中存储的键值对数量。
-
loadFactor(装载因子):size / capacity,用于表征哈希表“满 ” 的程度。实际上,由于同一个桶中的数据用链相连,本身就是动态长度的数据结构,似乎不会像定长数组一样有 “满” 的问题。但是,随着数据量的增多,若 capacity 固定不变,HashMap 的结构将趋于链表化,其键值对访问效率越来越差,失去了 Map 映射的原始意义!所以,为使 HashMap 始终有哈希散列带来的高速读写性能,我们希望冲突越少越好,故每当 HashMap 快满了时(即 loadFactor 到达某个预设值时),就要进行重哈希(rehash),将 capacity 扩充至原先的 2 倍。默认的 loadFactor 值为 0.75。
当我们知道将会向 HashMap 添加很多键值对时,可以将初始容量设置为 “预估最大键值对数 / loadFactor(default = 0.75) " 作为参数传入构造器。这样,几乎可以保证添加过程中不会发生调整 HashMap 的重哈希操作,进而提高性能。但要注意的是,将 capacity 设置得太大,会影响迭代遍历的效率。(所以,各种程度上来说,loadFactor 的取值也是一个经典的 tradeoff )
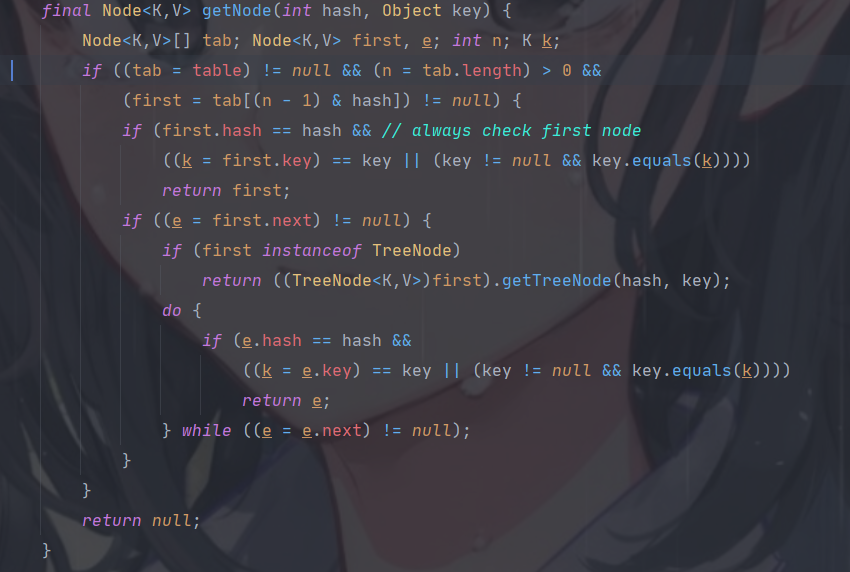
值得一提的是,由于其哈希机制,方法 containsKey 的复杂度为近似常数级 O(1) 。源码见下
![]()
![]()
可见,直接由 hash 值,从table 数组中取到了 Key 对应节点。当该节点不是想要的节点时,从桶中查找。由于桶中元素很少,故该步遍历达不到 O(n) 的复杂度(事实上,若用树结构存储,甚至是达不到 O(logn) ,即还要快),因此 containsKey 复杂度为近似 O(1) 。
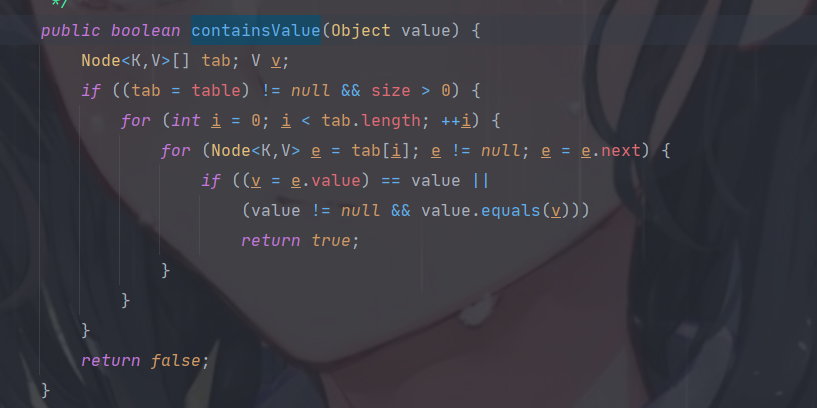
而相对应的 containsValue 方法,则是普通的遍历比较,复杂度 O(n) 。见下
![]()
所以,用 containsKey() 尽可能地替代 containsValue() ,往往能换来更好的性能。
-
-
HashSet
This class implements the
Setinterface, backed by a hash table (actually aHashMapinstance). It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will remain constant over time. This class permits thenullelement.This class offers constant time performance for the basic operations (
add,remove,containsandsize), assuming the hash function disperses the elements properly among the buckets. Iterating over this set requires time proportional to the sum of theHashSetinstance's size (the number of elements) plus the "capacity" of the backingHashMapinstance (the number of buckets). Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important. 一个简单的无序集合,实际上使用了 HashMap 进行实现,从而满足了 ”无序,不可重复“ 的设计要求。另外,有着与 Hashmap 相同的性能注意事项。同样,异步导致线程不安全,用
Set s = Collections.synchronizedSet(new HashSet(...));做同步处理。 -
LinkedList
Doubly-linked list implementation of the
ListandDequeinterfaces. Implements all optional list operations, and permits all elements (includingnull).All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end, whichever is closer to the specified index.
其实就是封装好了各种操作的双向链表。拥有头尾节点的指针,在按索引访问时,按照遍历距离短的准测,选择从头节点或是尾节点进行遍历。增删代价小,访问代价大。随机访问时,要进行遍历。虽然增删只要勾链,无需移动元素位置,但在随机位置插入,首先要获得该位置的表节点,故往往增删伴随着访问。因此,一般情况下,增删的优势体现得不够明显,但在特定数据结构中,会发挥其作用——如队列或双端栈,在表首进行增删时,LinkedList 有着比 ArrayList 更卓越的性能(O(1) is better than O(n) when add or remove in Deque)。


3.总结
- ArrayList:维护元素添加顺序,允许重复,用索引随机访问需求大,不期望增删。
- HashMap:不关心元素顺序,每个元素有唯一的 Key 相对应,且一个 Key 只可对应一个 Value(即 Key 不允许重复)。用键值对映射的方式,高速随机访问,允许频繁增删。
- HashSet:简单的数学意义的 ”集合“,需遍历查找。
- LinkedList:维护元素添加顺序,不支持随机访问,需遍历取元素,但在增删元素方面,有着高于ArrayList 的效率,在队首增删时尤为明显。
三、关键实现策略 (内含性能分析,图模型与维护等主要内容)
本单元的三次作业,要求我们阅读接口中写明的 JML ,实现出有性能保证的契合规格的具体类。在此过程中,严谨地阅读 JML 是必须的,但要注意的是,规格中所用数据结构以及描述方式只是表示期望功能,与实现策略没有任何关联!具体来说,规格中很轻易就会出现两层循环,但若是我们的代码实现策略也按照两层循环写,O(n2) 的复杂度是不被接受的。我们要做的是设计出符合规格的性能尽可能好的算法(万万不可照抄规格来做实现)。
由于迭代性,以下分析直接从最终作业(第三次)入手。
-
数据抽象的具体实现
- Network:
- Person[] people --> HashMap<Integer, Person> allPerson ,其中 Key 为 person.id
- Group[] groups --> HashMap<Integer, Group> allGroup,其中 Key 为 group.id
- Message[] messages --> HashHap<Integer, Message> allMessage,其中 Key 为message.id
- int[] emojiIdList; int[] emojiHeatList; --> HashMap<Integer, Integer> allEmojiHeat,其中 Key 为所有的 emoji.id,Value 为各 emoji 对应的 heat。
- Group:
- int id --> int id
- Person[] people --> ArrayList<Person> personList
- Person:
- Person[] acquaintance; int[] value; --> HashMap<Integer, Integer> acquaintance,其中 Key 为相邻的 person.id ,Value 为该人与本人之间联系的 value 值。
- Message[] messages --> LinkedList<Message> messages。由于对一个人接收到的 message 的需求为 “新元素加到队首”,故此处使用 LinkedList 容器,以获得最好的性能。
- Network:
-
关键设计分析
-
Network.isCircle() && Network.queryBlockSum() ——假并查集 :
由于有查询两点是否连通 (isCircle),以及所有非连通向量的个数 (queryBlockSum) 的需求,我的考虑过程为
Ver.1
isCircle: 像 JML 那样,从点 person1 出发,用 DFS 进行图的深度优先遍历,若找到 person2 ,则返回 true,否则 false。复杂度 O(n) 。
queryBlockSum: 对点集中未标记过的点进行遍历,对取到的点进行 DFS ,并把所有遍历到的点进行标记。复杂度 O(n)。
优点:适用性强,支持删边。
缺点:复杂度偏高,且重复查询时,会导致重复计算,浪费资源。若引入缓存机制,逻辑复杂度变高,容易出错,且不一定更好。
Ver.2
给各点加一个 “特征数” 属性,表示所在的连通分量编号。若两点特征数相同,则连通;否则不连通。而不同特征数的个数,即为连通分量个数。
优点:两个查询操作达到了 O(1) 复杂度。
缺点:当在两不连通的分量上加边时,需将某分量上的所有节点特征值进行改写。该过程同样需要 O(n) 的复杂度。且统计不同特征数个数时,仍然需要遍历 O(n) 。另外,删边时引入问题——怎样的删边,会使连通变为不连通?难以判断。
Ver.3 (final)
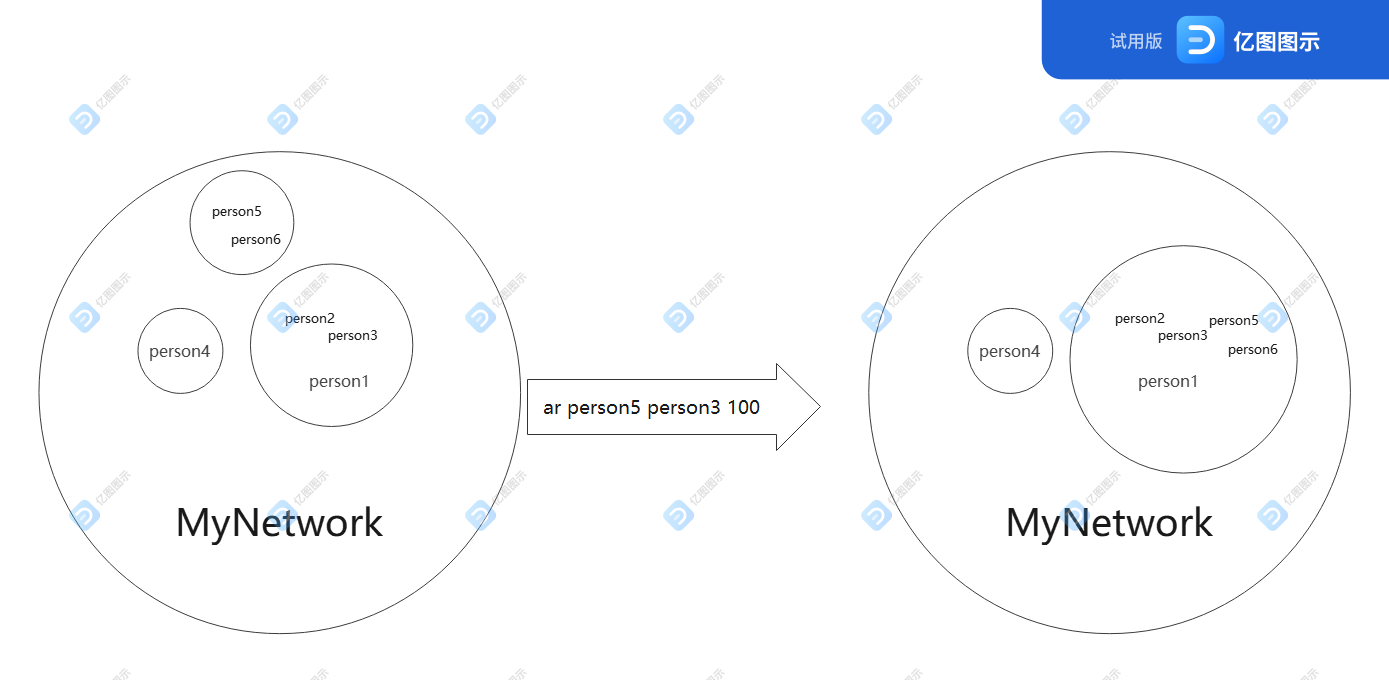
既然特征数难以维护,那么不妨让问题更加直观一点——思考问题更加图形化一点。
我们在判断是否连通,以及不连通分量的个数时,实际上只关心是否连通,而不关心如何连通。也就是说,我们的需求不包括连通情况的具体细节,采用忽略细节的数据存储方式,可以更简单地完成需求。
![]()
如上图,我们只需要维护一些集合,保证集合中的元素与且只与本集合中的元素连通即可。当加点(ap)时,为该点创建一个只含有其自己的集合;当加边(ar)时,判断两点是否在一个集合中,若不是,则将两集合合并成一个即可。这样,isCircle 复杂度近似 O(n),queryBlockSum 复杂度为 O(1) 常数。且不得不说的是,这种实现方式十分好写 。(写此总结时才得知,我所采用的方法只做了一半的工作,使用完整的并查集算法,可将 isCircle() 也实现 O(1) 的常数复杂度,性能更好。)
以上算法的代码体现为容器 ArrayList<HashSet<Integer>> blockList,List的各项为各集合,一个集合内的元素为各点的 id (person.id) 。
相关代码(各方法体内与该设计有关的部分):
- addPerson():为新人创建自己的集合。
- addRelation():若将两集合连通,则合并为一个集合。
- isCircle():若二者在一个集合中,返回 true。
- queryBlockSum():返回 blockList 的大小,即集合个数。
-
Group.getValueSum() 等——动态维护总值 。
求年龄的均值和方差,每查询一次就遍历一次是不理智的,Value 同样。我们将求和工作分摊到每一次组中添加或删除操作上。Age 和 Value 的本质区别在于,增删点(person),影响 ageSum;增删边(relation),影响 valueSum。
相关代码(各方法体内与该设计有关的部分):
-
addRelation():若二者在同 一个组里,则将改组的 valueSum 加上新关系的 value。
-
addToGroup():考虑点:将新人的 age 加到该组的 ageSum 中。
考虑边:新人与 ta 的熟人中在该组中的那些人的 value,加入到该组的 valueSum 中。
-
delFromgroup():考虑点:将该人的 age 从该组的 ageSum 中减去。
考虑边:新人与 ta 的熟人中在该组中的那些人的 value,从该组的 valueSum 中减去。
-
-
sendIndirectMessage() ——堆实现的 Dijkstra单源最短路 。
标准的 Dijkstra 算法——将候选边用优先队列存储,每次选出队列中权值最小的边 (w, u, v) ,若将 U 和 V-U 集合连通,则记录到 v 的最短路径长度,并把 v 加入集合 U;否则扔掉,选下一条边。直到找到至所求点的最短路径,返回。
注意,关于优先队列,我们使用 JDK 提供的 PriorityQueue 容器,将实现了 Comparable 接口的表示边信息的自建类作为队中元素。该容器通过堆排序实现,故自带堆优化效果,性能理想。
相关代码(各方法体内与该设计有关的部分):
- sendIndirectMessage() :调用寻找最短路的算法主体 shortestPathValue()。
- shortestPathValue():Dijkstra 的主体部分。
- updateCandidates():更新候选边队列的工具函数。
-
-
其他部分
没什么要特别说明的,根据 JML 描述和抽象数据的实际组织方式,可轻松得到低复杂度实现。
四、测试相关
1. 本地自测
实际上,勉强算是存在一些工具包支持对 JML 进行语法检查(如 OpenJML 等),但使用体验一般(指配环境失败了,一直报一个没见过的类重定义的错,最后也没解决掉),于是放弃了对 JML 语法的正确性检查,只是将其视为有特殊含义的注释部分,而非可编译内容。另外,JMLUnit 工具可以基于 JML 生成一些针对性的测试样例,但据了解,也只是对一些边界值、null 等情况下的输入作判定,只有有限的参考价值。因此,我的测试没有采用基于偏冷门的 JML 解析工具,而是使用了老师墙裂推荐的主流工具——Junit。
Junit 在测试类中,通过一些置于方法前的注解,区分各方法体在测试周期中的运行时期。其功能见下表
| 注解 | 被修饰的方法 |
|---|---|
| @Test | 测试方法,是该测试类所需执行的测试点之一。可在其后规定期望的异常类型,运行最大时长等。 |
| @Before | 在每个测试方法执行前被调用,一般用于执行测试环境的初始化工作。 |
| @After | 在每个测试方法执行后被调用,一般用于将该测试带来的影响重置掉。 |
| @BeforeClass | static 方法,会在所有测试方法执行之前被调用且仅被调用一次,即该测试类执行的第一段代码。用于测试类的初始化。 |
| @AfterClass | static 方法,会在所有测试方法执行之后被调用且仅被调用一次,即该测试类执行的最后一段代码。 |
| @Ignore | 被修饰的方法会被此次测试忽略掉,即跳过该测试点而不执行。 |
| @RunWith | 规定执行测试的运行器。 |
在测试方法中,通过将调用待测方法得到的结果,和我们的预期结果进行断言,决定测试点通过与否。为此,Junit 在 Assert 类中提供给我们一系列的 assert 方法如下
| assert API | 功能 |
|---|---|
| assertNull(Object object) | 检查对象为空 |
| assertNotNull(Object object) | 检查对象不为空 |
| assertEquals(long expected, long actual) | 检查两个 long 型变量值相等 |
| assertFalse(boolean condition) | 检查条件为假 |
| assertTrue(boolean condition) | 检查条件为真 |
| assertSame(Object expected, Object actual) | 检查两个引用指向同一个对象 |
| assertNotSame(Object expected, Object actual) | 检查两个引用指向不同对象 |
当上述断言检查失败时,表示该测试方法执行失败,程序在此情况下出现 bug。
本地使用 Junit,对各个单独类中的单独方法体编写若干测试方法,进行测试(即单元测试)。测试代码设计过程中,注意参照方法规格的描述,对各类行为正确性进行判定。依照 JML 规格充分测试后,基本可以保证程序的正确执行。
以下简单列举部分对 MyNetwork.java 类的测试代码,进行简要说明。
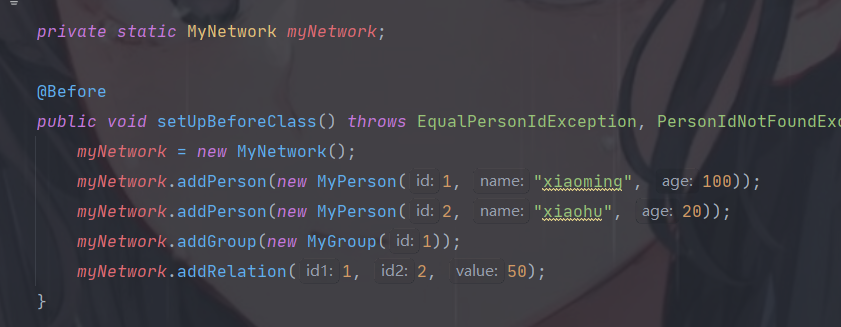
我们在每次测试开始之前,都将初始情况设置为有边的两个人和一个组,从而消除各测试方法之间的影响,使其均可视作独立存在。
-
针对异常的测试(以 minf 为例)
![]()
-
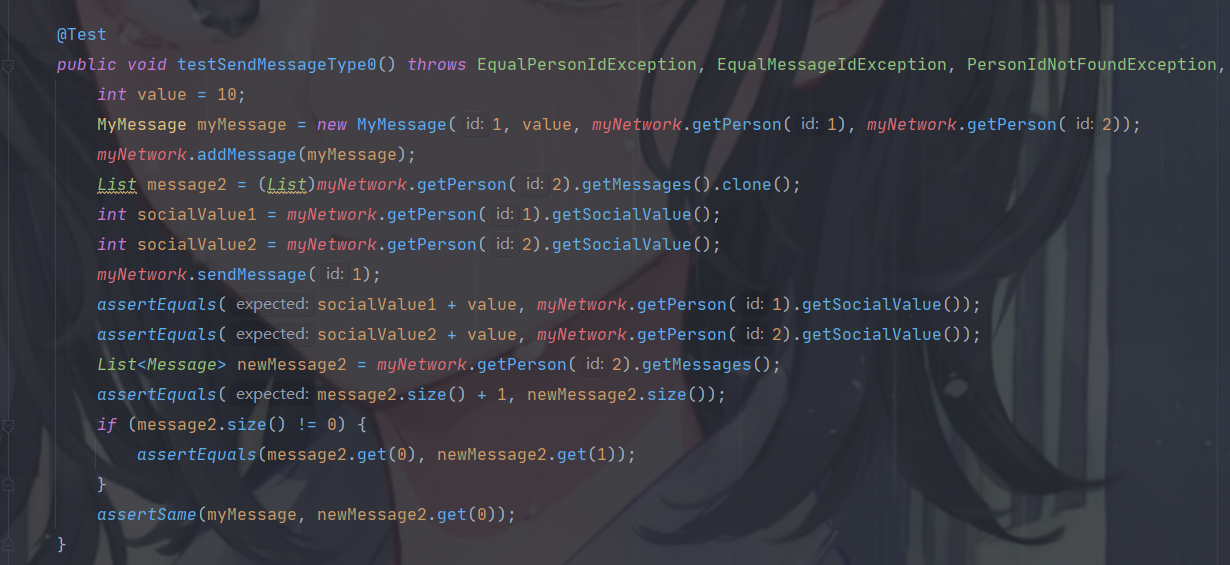
针对 type == 0 的 Message 的 send 操作
![]()
-
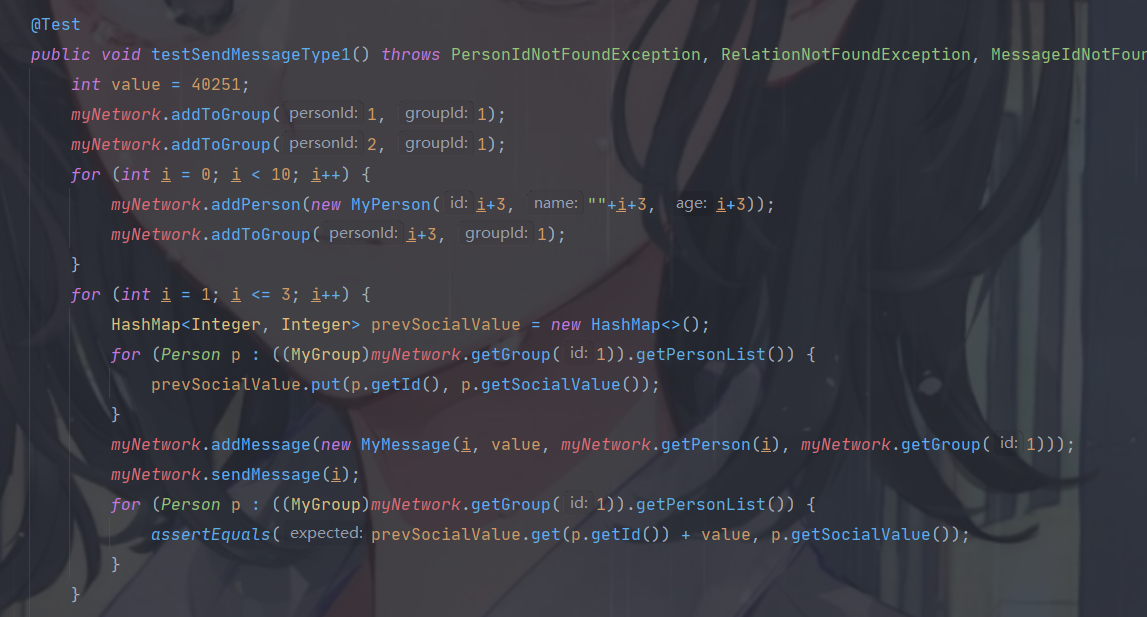
针对 type == 1 的 Message 的 send 操作
![]()
-
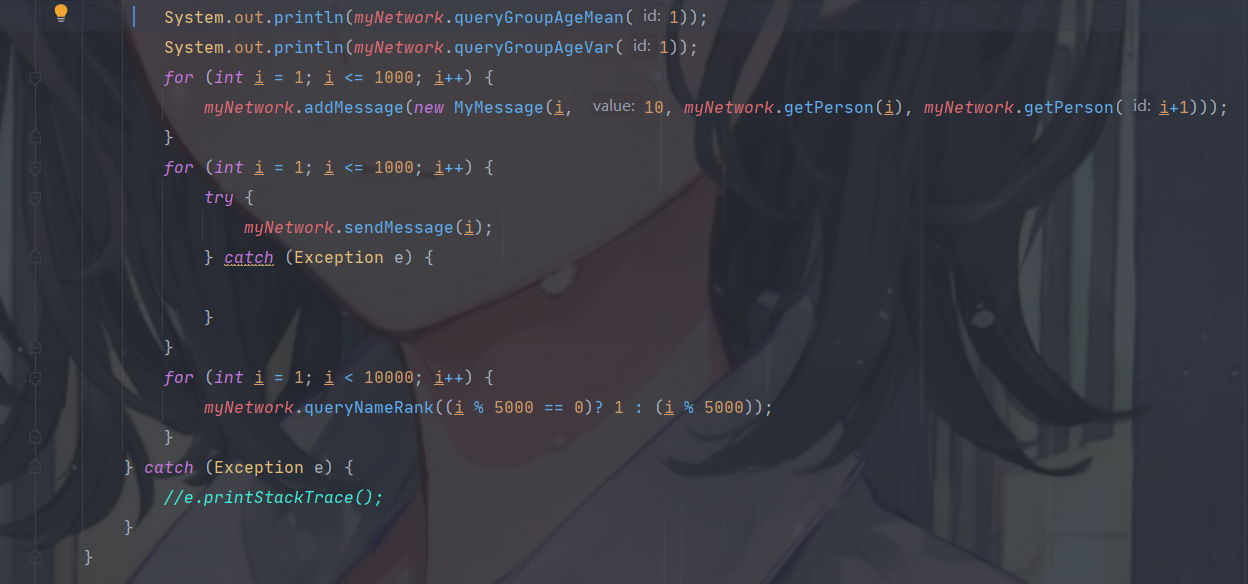
针对运行时的大量复杂指令加压测试
![]()
![]()


以上方法进行测试,结果如下
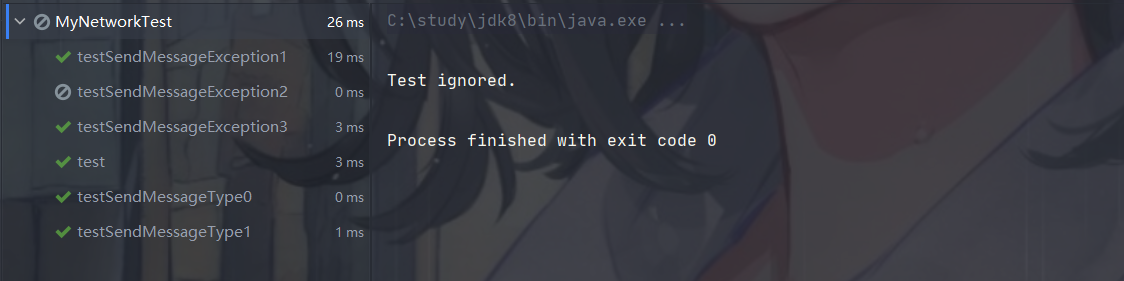
全部通过,可初步说明程序的正确性。
2. 房间互测
采用 python 针对性构造大量复杂加边、查询 age,value,sendIndirectMessage 等复杂指令序列,并比对程序输出。可惜的是,没测出 bug 来hhhhh。
五、心得体会
快乐 OO 终于来到!~ 开心学知识的同时又没有很难,这是最舒服的感觉——当然,前两单元的高强度打基础大概也是必须要经历的阶段吧。本单元的后两次作业我一刀没 hack 出来,不过在强测互测中也没有挨刀,安安稳稳躺过来的感觉真好。可以发现,本单元的性能部分(cpu 运行时间)是作为门槛设置在测试点中,而非 “性能分” 的部分。这样,没留心注意性能的同学不一定能拿满分,另一方面又不至于让同学们为了高一点点性能分拼死拼活,是不错的体验。
我在本单元的另外一个收获,是集体的力量。我们都是求学者,同学间互帮互助共同探讨,是最好的学习氛围。感谢 xrx 找到我第二次作业的诸多小粗心,感谢 zy 关于改规格的提醒,也感谢愿意用我的代码跑对拍的兄弟萌。一批人共同进步是美妙的,我能在这一批人中,是幸运的。希望在之后的学习中,我们能继续共同进步!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号