

面向对象第一单元总结
第一次作业
一、题目需求概括
最初步的多项式求导,仅支持常数与幂函数的乘积作为项,且保证输入无格式错误。
二、工程规模
-
类层次分析
- 类图
![]()
-
关键类分析
第一次作业比较简单,故只构建三个类,即可完成要求。
-
Main
主类,只负责最顶层的数据交互——从输入读取字符串,将扫描器传给 Ploynomial 进行匹配生成表达式,进行求导操作后输出结果。
-
Polynomial
多项式类,负责用含负向先行断言的正则表达式(即匹配前面不是乘号或加减号的加减号)对多项式进行项拆分,并把每一项传给Term类,生成各项的信息,并存储于一个以幂次为key的Map中。
-
Term
正则匹配常数因子和指数,并在匹配过程中进行合并维护。一项只需要这两个属性,即可完全承载其信息。
-
-
复杂度分析
- 整体代码量
![]()
主函数做到了小巧简单,两个实现功能类代码量比较均衡,但其实可以让各组成部分再“独立”一些。面向对象体现得不太明显。
-
类复杂度
初次做OO度量分析,以下列出指标全称及含义
-
圈复杂度:测试程序中的每一线性独立路径,所需的测试用例个数即为程序的圈复杂度。用来衡量一个模块判定结构的复杂程度,其数量上表现为独立路径的条数,也可理解为覆盖所有的可能情况最少使用的测试用例个数。可近似理解为与 if && while && for && case && catch && and && or 等判定路径数目正相关。圈复杂度越高,说明程序逻辑越复杂,潜在的错误风险越高。另外,测试驱动开发模式中,倾向于编写圈复杂度低的代码(圈复杂度高时,程序将变得难以维护)。(一份材料)
-
OCavg: average Operation Complexity (the Average Cyclomatic Complexity of the non-abstract methods in each class),平均圈复杂度
-
OCmax: maximum Operation Complexity (the Maximum Cyclomatic Complexity of the non-abstract methods in each class),最大圈复杂度
-
WMC: Weighted Method Complexity (the total cyclomatic complexity of the methods in each class),总圈复杂度
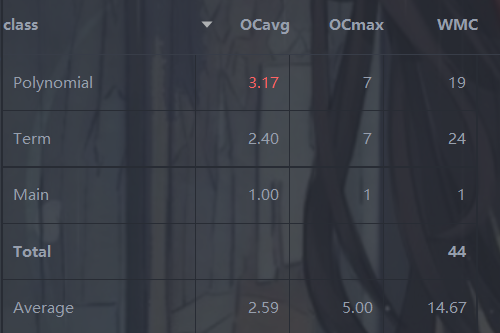
![]()
多项式类,平均圈复杂度爆红,主要在于输出求导结果时,对于幂次是否为零,以及当前是否为正项开头,进行了太多的 if。
-
-
方法复杂度
初次做OO度量分析,以下列出指标全称及含义
-
CogC: Cognitive Complexity,认知复杂度,是与圈复杂度有相似使用目的,但又独创了另一套计算模型的度量指标。圈复杂度适合描述代码的可测性,但有时不能很好地表征代码的可维护性。这里的认知复杂度,就是为了表征代码的易理解性而产生的。其基本计算方式如下
- 忽略简写:把多句代码缩写为一句可读的代码,不改变理解难度;
- 对线性的代码逻辑中,出现一个打断逻辑的东西(if & for & while & switch & catch & break & 递归 等非线性控制流),难度+1;
- 当打断逻辑的是一个嵌套时(多层循环,多层 if 等),难度+1;
认知复杂度越小,往往代表着代码越容易读懂,从而可维护性更好。(一份材料)
-
ev(G): Essential Cyclomatic Complexity,基本复杂度,用于衡量程序非结构化程度的指标。计算方法为:将圈复杂度图中结构化的部分简化为一个点,计算新图的圈复杂度,所得即为基本复杂度(故一定 ev(G) <= v(G) )。基本复杂度越接近圈复杂度,说明代码结构化越差,越难以理解,维护难度越大。(一份英文材料,有详细的说明和公式化计算方法,看不懂但是好像很厉害,洋文高手请)
-
iv(G): Design Complexity,设计复杂度,用于衡量代码调用其他方法的程度的指标。计算方法为:将圈复杂度图中移除不包含调用子模块的循环或判定后,新图的圈复杂度(故一定 iv(G) <= v(G) )。设计复杂度越高,说明模块间耦合性越强,导致模块难以隔离、维护和复用。
-
v(G): Cyclomatic Complexity,圈复杂度,见上”类复杂度“部分,不再细说。
![]()
![]()
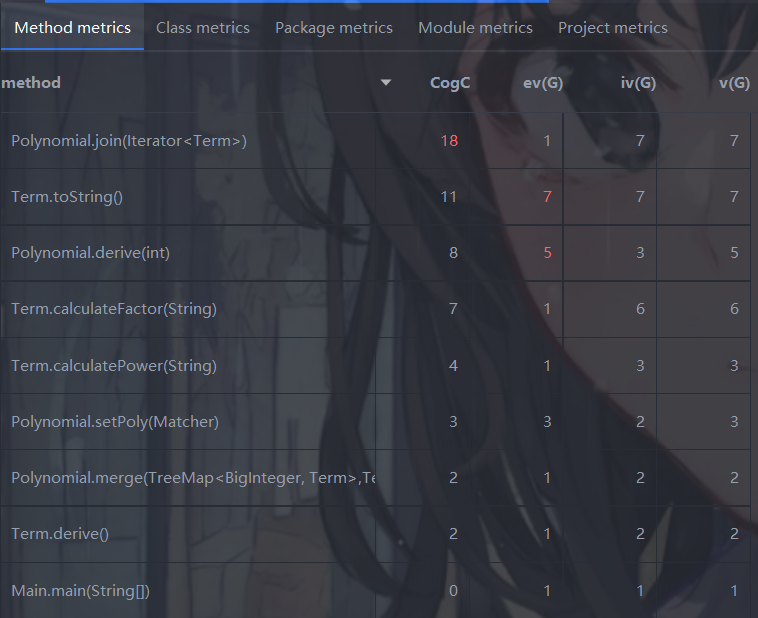
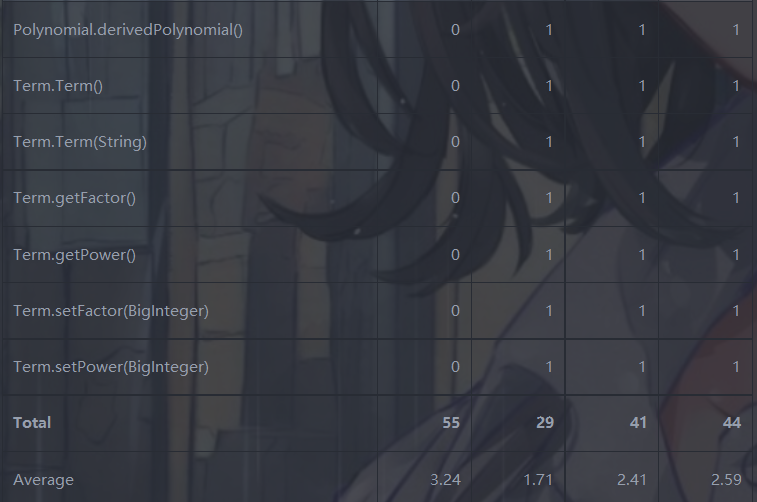
可见,多项式类的拼接输出字符串方法 .join() 认知复杂度爆红,原因同上,对于项的系数的所有判断都放在了一起,包括 ”为零时不操作;为正时提前添加 “+”,否则。。。。“,导致 while 内的局部 if 过多。
另外,项类的 .toString()方法也有较高的CogC,原因为:一个局部模块内,集中判定了 “(幂次为0 || 幂次为1 || 幂次其他) && (系数为0 || 系数1 || 系数为-1 || 系数其他)“ 的所有种基本事件,if else 过多且确实,可读性差&&感觉很容易出问题。
以上两处,是面向过程的常规操作(当然,大抵也是不好的),但放在面向对象的情况下,显然与 “各模块只做尽量简单的事情” 的思想不符,有待改进。
对于ev,Term.toString()上已说明,而Polynomial.derive()实际代码并不复杂,怀疑可能是在几个 if 条件判断时,反复调用了Term的get方法,导致模块间看起来总在耦合。
-


三、bug相关
我
本次作业,虽然面向对象一塌糊涂,但好在情况比较简单,状态很有限,强测、互测safe。
他
一个小点,就是当项很多时,有的同学会 StackOverFlow,可能是处理得比较复杂?
第二次作业
一、题目需求概括
在 hw1 的基础上,增加带幂次的正弦、余弦函数,且支持使用括号的表达式作为乘法因子。这就导致了一个问题——第一次作业的以加减号拆分项不再适用(或者也可以适用,只是要加入括号层次判断)。第一次作业中,在生成一个项时,统一地找到了系数和指数,是因为只此两个变量就可以表示一个项的全部信息,但这次作业显然是不适用的——一个项,可以有更多的因子类型,且由于多项式因子的存在,我们不可能用定长的变量个数表示全部信息——我们需要更加面向对象了。
二、重构
以指导书中的 hint 为重构模板,构建一系列因子类、组合类,以及静态的正则表达式类、工厂类。在处理输入时,通过符号替换的方法,使每个相邻的加减号都被合并为一个。由输入串生成对象时,采用类似状态机的想法,因子[常数因子,幂函数因子,三角因子, "(" ]与组合连接符[*+-]交替匹配,每匹配到一次,将输入串的头部裁掉,进入下一次匹配。当匹配结束(串长为0或匹配到 ")" ),返回当前的多项式。
以上为主要重构内容。
三、工程规模
-
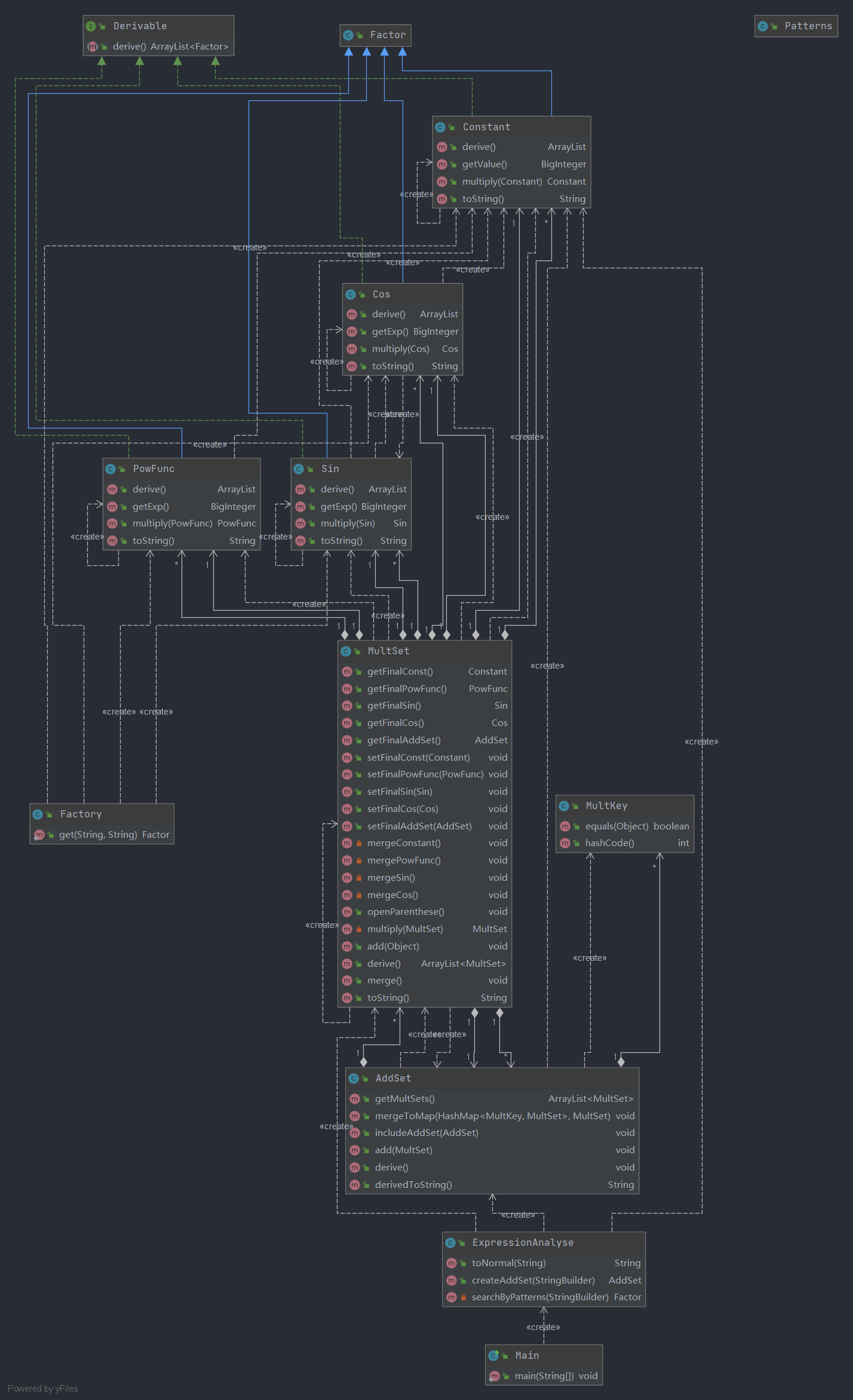
类层次分析
-
类图
![]()
-
关键类分析
-
ExpressionAnalyse
对字符串进行预处理,并控制生成表达式的分析器。
-
toNormal:预处理加减符号,删除空格。
-
createAddSet:进行因子与组合连接符的交替匹配,是生成多项式的顶层方法。当匹配到括号时,传入删除括号后的当前字符串,对此方法递归调用。当连接符为*时,将已得因子加入当前乘法组合;当为 +or- 时,将当前乘法组合加入加法组合。
-
searchByPatterns:匹配一个因子,并将其返回。
-
-
AddSet
加法组合类,用一个 Map<MultKey, MultSet>容器存放其中的乘法组合,另一个存放求导后的结果(是不好的,一个多项式对象同求导操作的耦合性强,应该把求导结果与其本身独立开来,用另一个类或容器统一管理)。
- mergeToMap:向指定的 Map 中加入MultSet,同时进行合并同类项。(似乎设置为 private 更好)
- includeAddSet:接受 AddSet 为参数,将传入的 AddSet 的全部 MultSet 加入到此对象当中。
- add:对外提供的添加 MultSet 方法。
- derive:对此对象求导,将 MultSet 结果依次加入到另一个容器 derivedMap 中。
- derivedToString:将此对象的 derivedMap 中的对象转换成输出字符串。
-
MultSet
乘法组合类,所有因子的最终结果各由一个对应类型的对象存储,中间计算过程各由一个类型的 Map 存储。(这个存储代价似乎是没必要的)
- mergeXX:加入对应类型因子的私有方法,以更新此对象的因子的方式进行添加(多项式采取拆括号的策略)。
- add:对外的添加方法,调用各种 merge 。
- derive:由于每个因子加入乘法组合时,都进行了拆括号,故一个乘法组合只用常数、幂函数、正余弦函数四个对象来表示最终信息。这里采用硬求导的方式,没有建立乘法求导规则,即硬编码,对四种类型的因子乘积返回求导结果。(不好,可扩展性差,hw3 时被改写)
-
MultKey
用幂函数、正余弦函数的指数共同组成 key,当三者对应相等时,两 MultSet 的 key 才相等。
-
Factory
工厂类,传入要被实例化的对象类型(String参数1),以及该对象的生成信息(String参数2)。(生成信息,采取传入匹配到的字符串的方法,意味着在对象构造时,需要对字符串进行硬编码索引剪切(如幂函数的指数从索引为3处开始),在已知各因子固定格式长度时可用,但易读性、灵活性、可维护性均很差。可改进为传入各捕获组的方法)
-
-
-
复杂度分析
-
整体代码量
![]()
代码量主要集中在 MultSet(乘法组合) 和 ExpressionAnalyse(解析表达式)类。MultSet 中,有的成员和方法定位不明,其存在减小了一丢丢逻辑复杂度,但导致代码啰嗦臃肿,也增加了不必要的内存占用,应当对其进行优化。(事实上,hw3中也如此做了)
-
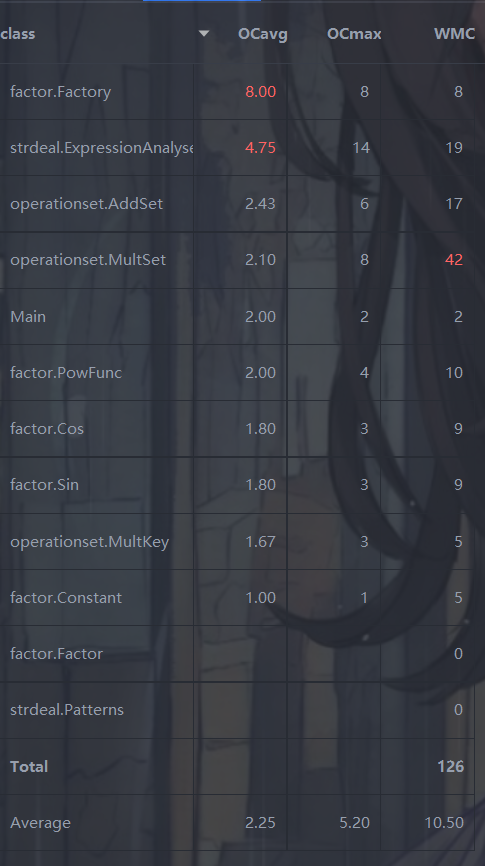
类复杂度
![]()
-
Fatory类的平均圈复杂度爆红,因其只有一个方法,见下。
-
ExpressionAnalyse类,复杂度主要在于在解析字符串的方法,见下。
-
-
方法复杂度
![]()
。。。。。。。。。。。
![]()
-
ExpressionAnalyse.createAddSet():全方面爆表,也就是说:可读性差、模块化差、耦合度高、可测试性差。该方法使用了大量的 if 进行状态判断,是编码时没有事先想明白整个流程,debug 时东添西补的体现,逻辑现得混乱。(事实上,最后确实在这部分出了问题!)另外,只将匹配因子的部分单独抽出为私有方法,逻辑层次不够清晰。可以考虑把更多的过程抽象、封装起来。
(啊太丑了,丑不忍看!) -
MultSet.toString():调用了各因子的 toString 方法,大概是不可避免的,应该问题不大。
-
Factory.get():基本复杂度高,模块化差。该方法用 if 进行了所有类型因子的判断。另外,这里实例化一个对象时,对于对象内部的各属性也进行了判断。这是不好的,是耦合的,是因子构造器不够内聚的体现。工厂应该只负责生特定类型的对象,而构造对象的具体方法,并非 Factory 负责的内容,应内聚到具体对象的构造器中。应使用更改或重载构造器的方法,进行内聚、解耦。
-
-
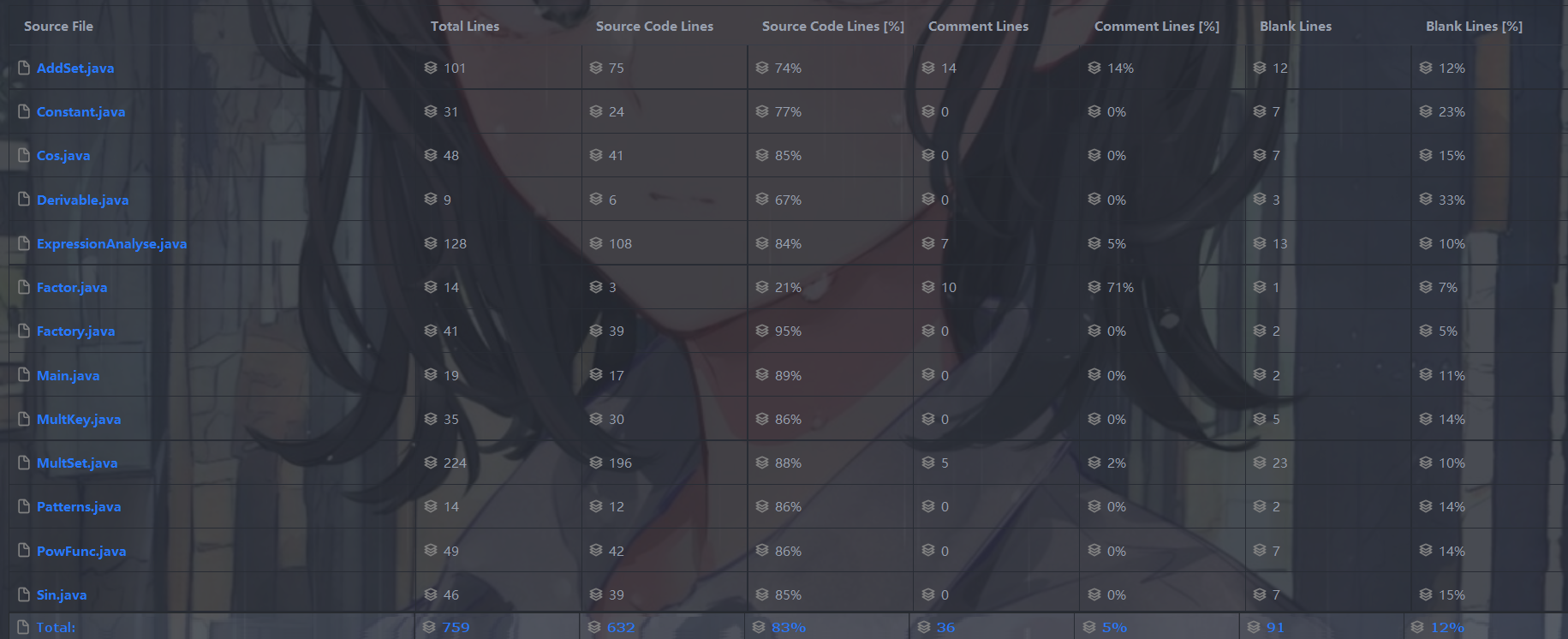


四、bug相关
我
唉,问题超大。。。。。只是因为在交之前少看了你一眼,从此我强测互测直接爆炸。
强测挂六个,互测挂两个,全部都是一个 bug,以下为错误分析。
错误原因
在扫描输入串,进行对象实例化时,我用逐项扫描、实时剪切输入串的方式进行匹配。有两种组合类型——加集合(AddSet)和乘集合(MultSet),加集合中的元素之间用加号连接,乘集合用乘号。每当检测到一个因子时,将其加入当前 MultSet ;每当检测到分隔 MultSet 之间的加号时,将当前 MultSet 加入当前AddSet,并令 MultSet 引用一个新创建的对象,其初值为1,此即为BUG所在!!!
这样的考虑,相当于在每个加法前,默认始终匹配到一个常数因子1,但事实未必如此。当加法出现在表达式串的非起始位置时,由于保证输入格式的正确性,则检测到加法时,MultSet一定已加入匹配到的至少一个因子,结果正确。但当加法出现在表达式串的开头时,出现了bug。
考虑 input = x*(+x),显然正确求导结果为 2*x ,但以我所构造的输入扫描方法来看,+x 的正号被识别成一个加法,之前的 MultSet 被加入加集合,而其默认初值为1——此式被解析成了 x*(1+x),实则为 x*(0+x) !!经过对所有错误数据的覆盖检验,得到结论——确实全是此原因。
修改内容
- 将每次开始匹配表达式串之前,当前 MultSet 的初始值设置为 null 而非 new MultSet() 。这样,在第一项为加法时,若 MultSet非 null,则加入 AddSet;否则,不进行操作。当匹配到因子时,首先判断当前 MultSet 有无对象;若无,说明此次为初次匹配,new 一个新的 MultSet,并装入当前匹配到的因子。
- 上述修改后,创建 AddSet 的方法体65行,过长。继而,调整其内容,将匹配因子的部分单独封装成 private 方法,以匹配到的因子为返回值,若为 null,则匹配失败。
细心的小伙伴已经发现,我这改bug属于东添西补型,导致该模块的复杂度直线上升,虽能解决问题但属于自暴自弃型。hw3已对此进行修改。
另外,可以发现,bug出现的位置,正是整个工程圈复杂度最高、模块化最差、认知复杂度最高的地方。这佐证了OO复杂度度量指标,对于衡量代码质量的重要程度。减小复杂度,让逻辑清晰、层次分明,是学习面向对象编程的一大目标。
他
两种测试数据,其一为没什么特点的长表达式,有同学求导结果错误,大概是同我一般的愚蠢错误;其二为大量括号嵌套,有几位同学 CPU 运行时超出,大概是解析过于复杂。
第三次作业
一、题目需求概括
在 hw2 的基础上,加入格式判断,以及三角函数的因子嵌套。
二、工程规模
-
类层次分析
-
类图
![]()
-
关键类分析
-
Factory
- cloneFactor:debug 时增加,进行因子深拷贝的方法。
-
FormatException
检查型异常(CheckedException),格式错误时抛出,在程序顶层方法 Main.main 中进行 catch。
-
PreFormatChecker
新增,对输入串进行部分合法性判定,以及空格预处理的类。
- preCheck:对外提供的格式检查方法,调用四个私有的格式检查方法,返回预处理后的字符串(或抛出异常)。
- emptyCheck:若为空串,抛出异常。
- blankCheckAndReplace:检查所有空格的合法性,抛出异常或返回删除空格的字符串。
- manyAddCheck:相邻加减号合法性检查方法。因后续进行 “三合一” 替换操作,故需在替换前检查四个加号相连(替换后可能被判定为合法,如 ++--3 * x)、两个加号相连(替换后可能被判定为合法,如 x ** ++3)。
- parentheseCheck:括号检查方法,若左右括号不成对,则抛出异常。
-
AddSet
改变成员属性结构,只用一个 Map<MultKey, MultSet> 存储加法组合中的乘法组合,同 hw2 相比耦合性低。
-
MultKey
由于这次没有拆括号(拆括号结果会偏长,且通用性不好),故将多项式因子加入 key 的相等判断中。另外,一个乘法组合的三角函数也是可变长个,故判断依据不只是 hw2 中的指数,而是三角函数本身。这意味着需要重写三角函数、多项式的equals、hashcode方法。
-
MultSet
- derive:主要迭代内容之一。由于一项的组成相比 hw2 变得十分复杂,可有复数的不同三角函数、多项式因子,故硬编码行不通,改用实现乘法求导法则的方法。具体为对所有因子进行两层循环,内层和外层是一个因子时,对其求导;否则,加入因子本身。每次外层循环结束,向返回列表加入当前乘法组合。
-
Sin / Cos
新增成员 (Factor) member,表示三角函数内的因子。
-
-
-
复杂度分析
-
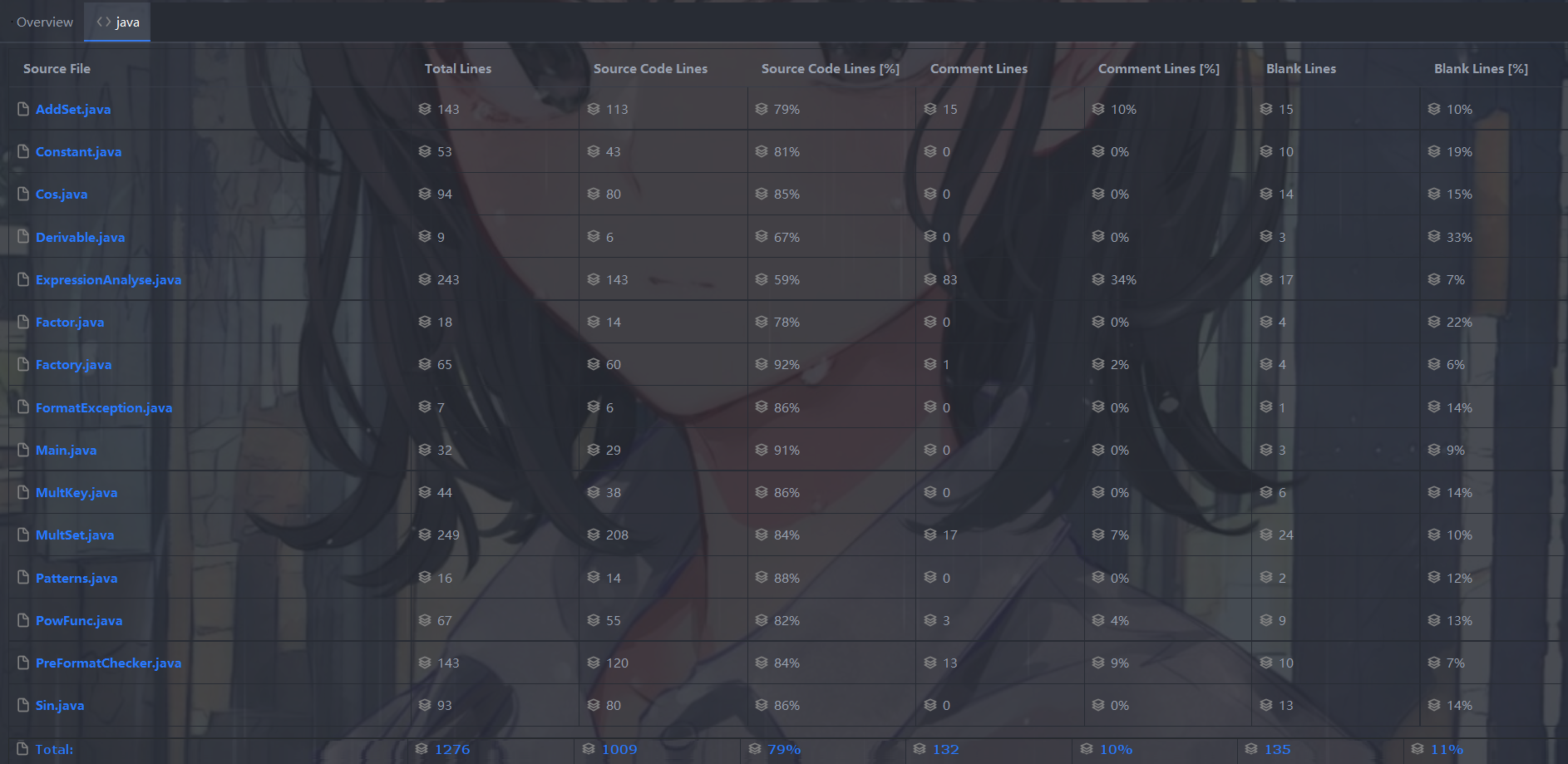
整体代码量
![]()
还算蛮均匀,不过感觉可以更简洁,很多粗糙的操作是不美观的。
-
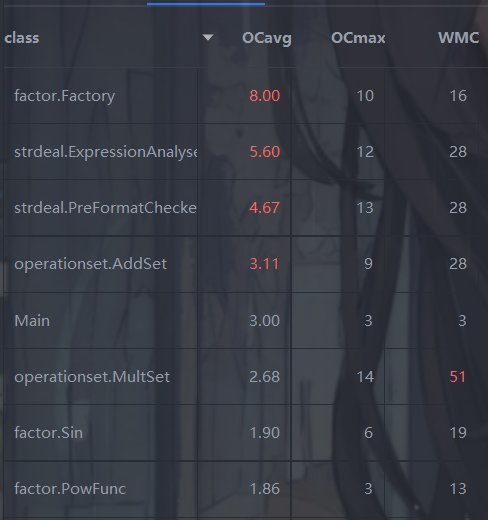
类复杂度
![]()
![]()
-
Factory类爆红原因同 hw2。
-
ExpressionAnalyse类爆红,可能是在解析表达式时,一个方法做了太多的事,抽象层次不好,导致模块化差、耦合性高。
-
PreFormatChecker类,由于对空格、符号的合法与否的判断,需要结合其前、后的若干字符,确定当前所处的位置,进而得到合法与否的结论。为此,不得不进行很多复杂繁琐的 if 条件判断。或许可以有更好的检查策略?
-
AddSet类,由于进行 a + (b + c) => a + b + c 的优化,导致条件分支有些繁琐,分析见下。
-
-
方法复杂度
![]()
![]()
。。。。。。。。。
![]()
整体来看,还是蛮糟糕的 (^_^)
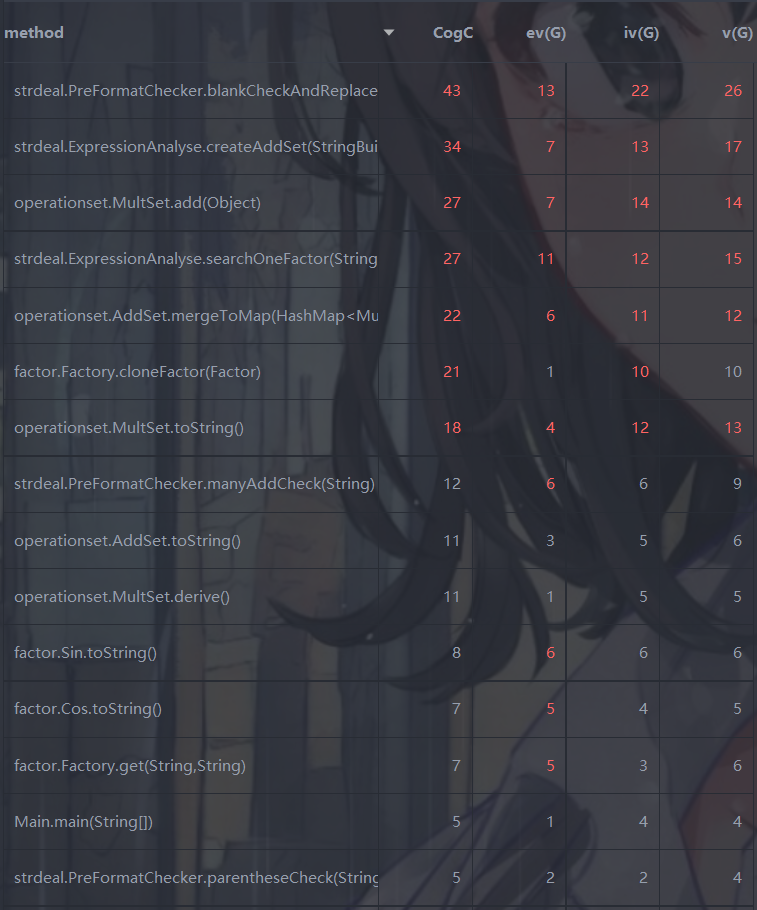
- PreFormatChecker.blankCheckAndReplace():像前文说的那样,对空格所处位置的判断,需要大量且复杂的 if ,这就导致了认知复杂度爆表,经本人实测,确实有点难看懂自己写的代码在干些什么。(神奇的是,确实在这里出了不少零零碎碎的小问题!)可以考虑,对不同情况的非法格式分别单独写成私有方法,再以本方法为上层调用,或者干脆直接为空格检查单独开一个类,封装起来一系列的操作,只对外暴露一个简单的接口。这样可以提高易读性,使逻辑清晰,减少错误的可能。(同类中的 manyAddCheck 方法也存在同质的问题)
- ExpressionAnalyse.createAddSet():同 hw2。
- MultSet.add():相比于 hw2 增加了 a * (b * c) => a * b * c 的优化,故在加入对象为 AddSet 类时,额外判断其 MultSet 数量,当为0或1时,把每个因子为参,调用相应的 merge 方法。可能是因为在两层 if 内,同时含有三个 for 循环(分别遍历 Sin、Cos、AddSet 类的因子),导致方法各种复杂度直线上升。(但其实没想到指标会增加这么多,感觉逻辑还算清晰,没啥改的必要。。。)
- ExpressionAnalyse.searchOneFactor():三角函数支持复合,也就意味着在匹配一个因子时,hw2 中的三角正则串不再适用。该类中,实际上实现了三角函数的复合内容 member 的设置,以及正则匹配幂次并设置在三角函数对象中,即完整的三角函数匹配机制。这是不好的、耦合的、欠缺模块化的,应当实现只调用一个方法,就能得到完整的三角函数,即将其实现细节聚合在一个方法里。这样的逻辑混乱,直接体现在了 OO 度量指标的爆表。
- AddSet.mergeToMap():增加 a + (b + c) => a + b + c 的优化,其伴随的大量 if 使得逻辑复杂度上升。把优化实现的细节嵌进了一个添加元素的方法,这是耦合的、功能不切合的、应当被写成独立模块的。
- Factory.cloneFactor():深拷贝方法,在修复阶段新增。其认知复杂度高,原因在于对传入的对象类型进行判断,并在此处集中实现各类型的深拷贝。这是临时补救的措施,是不可复用的。深拷贝的正确做法为,令每一个 Factor 子对象,实现Cloneable 接口,在各自的 clone 方法中实现自身的深拷贝。
- MultSet.toString():边化简,边拼接输出串,导致 if 偏多。(其他因子、组合的 toString 方法类似)
-

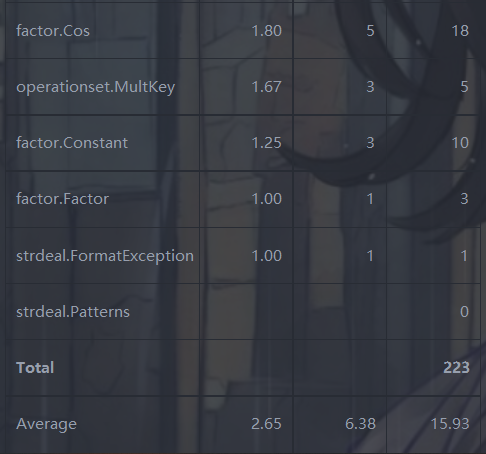


三、bug相关
我
出大问题。。。。。强测挂5个,互测挂3个。分析见下
前言
此次作业问题较大,由于工程复杂性的上升,暴露出了自身的很多问题,集中体现在了完成时的困难、类之间耦合关系的混乱,以及bug频出。共计四处非同质bug,三处为细节考虑不周,一处为面向对象知识点的关键性、严重性错误。下文进行分别阐述。
1. x**2 作为三角函数嵌套中的因子简化输出时
-
问题产生:由作业一延续来的提高性能的方式之一,是将 x**2 拆成 x*x ,我没有思考这样的化简在这次作业中可能会带来的新的问题——当x**2 作为三角函数的嵌套因子出现时是合法的,但拆成 x*x 之后,其本质从一个幂函数,变成了两个幂函数的乘积,不再符合三角嵌套中“一个因子”的限制,故变成非法输出。
-
修复方式:舍弃此种化简方式,以保证输出合法性。
-
启发:在引入新的规则时,一定要思考,这样的 “新规则” 对我们过往的设计,有怎样的影响——对旧程序新增了怎样的限制,或者对旧程序要求了怎样的扩展。
2. 三个加号连续出现时
-
问题产生:理解错了题目介绍,误以为三个加号只能在每个表达式的第一项出现 ,实则不然。只因为形式化表述有点搞不明白,就以自己对文字描述的意会理解了。。。。文字描述说 ”在第一项之前,可以带一个正号或负号“ ,想当然的认为只有第一项可以有三个加号。。。。是我自己的问题,课上老师也讲到了形式化验证的重要性。
-
修复方式:注释掉了三个加号的正确性判定——原程序在此处对三个加号的出现位置做了限定,而这种限定是不应该的,删去即可。
-
启发:写程序搞代码,切记严谨、严谨、再严谨!引 dalao 的话,”要有敬畏心“!另外,尽量降低各个方法的认知复杂度,进行进一层次的抽象,会减少错误发生!
3. 空格出现在首尾时的判定
-
问题产生:
emmmmm.....这个问题。。。我也不知道怎么产生的。。。。写的时候在灵魂出窍?我奇怪的程序,使得当空格出现在表达式首尾时,不进行替换且直接终止匹配空格,以 “无格式错误的不含空格的” 理想状态返回。但实际上,得到的字符串必有空格(因为匹配之后没有替换。。。),所以在分析生成对象时,抛出格式错误。总之就是十分没道理的代码。。。也没有足够地测试,所以一直没发现。。。。强测数据大概也是没想到会有这么愚蠢的问题,也没测到。。。好在被互测同学慧眼识到。感恩。。。是不是我梦游时敲的代码。。。 -
修复方式:当匹配到开头位置的空格,替换并continue,以防循环体后面的代码访问空格前的字符越界;当匹配到末尾位置的空格,替换并break,以防循环体后面的代码访问空格后的字符越界。
-
启发:当一个方法做的事情太多,深度大或者广度大时,这个方法可能就危险了。要把独立的部分单写出来,以降低逻辑复杂度,从而降低出错概率。(还有,敲代码保持头脑清醒!)
4. 严重恶性 bug :共享对象的修改
-
问题产生:
-
原理分析
首先,对比 C 与 Java 中,数据类型的差异。C中的变量,声明时即获得实体,进行 a = b 的赋值操作时,也是将 b 的值传递给 a 存储起来。共享变量的情况,只发生在全局变量(Java中类似静态变量),或是指向同一个内存空间的不同指针之间。但是 Java 不同。由于没有 “指针” 的概念,而是用 “引用” 类型,就会导致程序中藏着很多潜在的 “指针” ,共享同一块对象实体——引用类型值传递。传统的 C 的思想为,定义一个新的变量 a,将已有变量 b 的值传递进去,对 a 进行运算操作,不会改变 b 的值。但 Java 中,若 a 与 b 均为引用变量,仅通过 a = b 的话,修改 a 会同时改变 b 的信息——因为他们分明就在操作同一块实体!这通常是我们所不希望的,所以要在引用类型赋值时,想好是否有共享对象的问题。否则,就算把很多引用传来传去,最终可能也都在对一个东西下手。如有必要,多写 clone 进行深拷贝!另,有时不是一个简单的 new 出新对象就万事大吉了,因为对象的成员可能也含有对象,......
-
具体问题
这里,我在乘法组合求导时,两层遍历组合中的因子。当外层与内层索引相同时,加入该因子的求导;否则,加入该因子本身——此即为问题所在!我传到返回值中的对象,并非一份克隆,而是乘法组合中一个因子本身。这也就导致,后续乘法求导之后,得到的加法组合进行合并时,会改变原有的乘法组合因子的信息!
以输入 x*(9+x*(1+x)) 为例,在解析表达式 9+x*(1+x) 时,对 x*(1+x)进行求导,得到加法组合中,有元素 x 和 (1+x)。在合并化简时,会将 (1+x) 更改为 (1+2*x),而这里的 (1+x) 对象,正是原表达式 9+x*(1+x) 中的 (1+x) 。。。。于是,对一个在构造之后不应被改变的乘法组合,在求导后的合并生成的加法组合操作时,被进行了非法、对于 “乘法组合” 对象来讲不合逻辑的更改。这也导致了最终结果的错误。
-
-
修复方式:
工厂中新增 cloneFactor 方法,实现对传入因子的深拷贝,返回拷贝得到的克隆体。在乘法求导时,加入原因子的深拷贝,而非原因子本身。
-
启发:
抛弃C语言中 “新变量即新实体” 的固有观念,在传递对象时,思考要不要进行拷贝,在类中勤写深拷贝方法。
他
查到一处错误,即 cos(x*x) 类的输出格式错误。
写在最后
一些理性的话
第一单元的磨练,让我渐渐地从面向过程式思维,向初步的面向对象过渡。高内聚低耦合、封装后对外提供接口、用指标评价代码质量、为复用性 & 可扩展性着想、注意引用传值与深拷贝,还有一切皆对象,这些都是我学到的重要经验。第二周的周四,我想了一晚上什么叫做 “给加法、乘法建立类” ,运算还能成一个类?动词怎么成类?我苦想很久,才终于捅破脑袋里那层纸。对于任何东西(甚至不是东西,而是抽象的某种存在),只要有组成内容,有相关的操作,有同其他东西的联系,就值得我们思考是否要为它建立一个类。希望这是我跨入面向对象世界的一个门槛吧。以后,要在 “写聪明的代码” 的观念下,提高 “写简单的代码” 的地位,即降低认知复杂度,勤写备注,让代码清晰、易懂。
另外,测试永远不是附加项,而是保证程序正确性的必要一环。写出一个程序,只走了50% ,测得尽量完备而不出错,才算走过了90%。(剩下10%留给天灾人祸以及各种不可抗力)这是我对编程认知上最大的收获。
一些感性的话
第一单元大溃败。现在看来其实也没有很难,但当时写过中测,仿佛就是莫大的解脱。两次都是,周五艰难写完后就再也不管,仿佛那程序不测就不会出错。就连测评机也是,简单试了试发现有点麻烦就没有继续做,只搞了个比对输出与正确答案的小程序。聪明人的懒,是做最少的事达到最好的效果,我的懒好像是逃避问题掩耳盗铃。这直接导致了我浪费掉大量宝贵的测试时间,最终下场就是 hw2 因为一处并不很难发现的错误,强测分直接6开头;hw3 因为各种遗漏掉的小判断点和疏忽了的各种小bug,强测分刚刚7开头。实验也是,简单到仁慈的小题,我竟然因为 case 忘记写 break 而拒绝了这份仁慈。。。。
这一单元,暴露出的最大的问题是我的态度。过少的实践,过多的自信。这个人明明那么的普通,却又那么的自信。。。。。
技术上——将复杂逻辑进行模块化提取,让每个方法都有单一的目的、做尽量简单的事情。考虑情况要充分,理解题目要彻底。多测试,初写成而未经测试的“生”代码是亲戚家的熊孩子,是不可靠的。
态度上——对自己的代码,要以怀疑为基调:对各种可能出错的情况,相信它必定出错(跑一下发现没错,那多开心),即使过了中测,也要相信绝对还有问题。毕竟根据老师的统计,强测全过也极有可能被 hack。保持谨慎、保持好奇、保持敬畏。
以上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号