

函数:
1、函数格式:
def 函数名(): // 括号里面可以传参数
"注释内容"
代码块
ruturn 返回值 // 返回值可以是数字,字符串,列表,字典,元组,等等
2、使用函数的好处:
(1)减少代码重用
(2)保持一致性,容易维护
(3)具有可扩展性
3、函数参数:
(1)形参:不占用物理内存空间,而且只在函数内部有。
(2)实参:可以是多种数据类型,必须有固定的一个值,方便赋值给形参
def test(x,y): //定义函数的时候括号里写的就是形参
n = test(3,5) //执行函数时要赋值给形参所传的参数是实参
print(n)
(3)位置参数:实参的值要和形参的值一一对应上,少一个或多一个则报错
def test(x,y,p):
print(x)
print(y)
print(p)
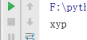
test('xyy','xyp','xyyp')
结果:
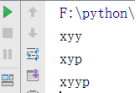
(4)关键字参数:则不需要像位置参数那也一一对应,值够就行
def test(x,y,p):
print(x)
print(y)
print(p)
test(y='xyy',x='xyp',p='xyyp') // 顺序无关紧要,值不能多不能少
结果:

(5)默认参数:定义函数时默认指定的形参,但是是可以输出的
def test(x,y,p=111): // 定义了默认参数是p=111
print(x)
print(y)
print(p)
test(x=1,y=11) //执行时不给p传参数
结果:
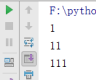
def test(x,y,p=111):
print(x)
print(y)
print(p)
test(x=1,y=11,p=222) //形参p不变的情况下,给p传一个实参
结果:
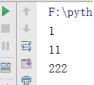
(6)参数组:*args 表示列表, **kwargs 表示字典
方法一:
def test(x,*args,**kwargs):
x
args
kwargs
return x,args,kwargs
n = test(1,"xyy","xyyp","xyp",k1=1,k2=2,k3=3) // 第一个参数1表示位置参数,传给x,"xyy","xyyp","xyp"表示传一个列表给args,k1=1,k2=2,k3=3表示传一个字典给kwargs
print(n)
结果:

方法二:
def test(x,*args,**kwargs):
print(x)
print(args)
print(kwargs)
test(1,"xyy","xyyp","xyp",k1=1,k2=2,k3=3)
结果:

方法三:
def test(x,*args,**kwargs):
print(x)
print(args)
print(kwargs)
test(1,*["xyy","xyyp","xyp"],**{'k1':1,'k2':2,'k3':3})
结果:

4、全局变量和局部变量:
(1)全局变量:在编辑器里面定义的变量,且变量名开头没有缩进的变量叫全局变量。
例如:

(2)局部变量:在函数里面定义的变量,且只对单个函数体有用的变量叫局部变量。
例如:

(3)global关键字:
①、当函数体内没有global关键字时,且有局部变量,则优先读取局部变量,没有局部变量则读取全局变量,并且不能对局部变量进行赋值。
②、但是对于可变类型,可以对内部元素进行操作,比如:追加或删除。
③、当函数体内有global关键字时,变量本质上还是全局变量,而且可以读取并赋值。
PS:代码书写过程中,建议全局变量名要大写,局部变量名要小写
(4)nonlocal关键字:
①、调用上以及函数的局部变量
5、递归:
在函数内部,可以调用其他函数,如果一个函数在内部调用自身本身,这个函数就是递归函数。
特点:
(1)、必须有一个明确的结束条件。
(2)、每次进入更深一层递归时,问题规模相比上一次递归都相应减少。
(3)、递归效率不高,递归层次过多会导致栈溢出。
6、作用域:
def ccx(): //定义函数
name = "xyy"//定义函数体
def cjk(): //嵌套函数
name = "xyp" //定义嵌套的函数的函数体
def ml(): //嵌套第三层函数
print(name) //第三层函数体
return ml //返回值
return cjk //返回值
重点:函数的执行
n = ccx()(1)第一次执行函数的第一层函数体,则会通过return返回一个返回值是第二层函数的内存地址
x = n() (2)由于第一层函数的返回值是第二次函数的内存地址,加上()就能执行第二层函数,并且会返回一个值,是第三层函数的内存地址
x() (3)通过第二层函数的返回的第三层函数的内存地址加上()执行第 三层函数,返回值就是上一层函数的定义的变量值
结果就是:
7、匿名函数:
关键字:lambda
格式:
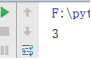
fun = lambda x:x+1
print(fun(2)
结果:
lambda :关键字,匿名函数的开头必须有
x :函数的形参
x+1:函数体,相当于普通函数的return返回值
fun:就相当于取函数的一个返回值,可以是任何字符
print(fun(2)) :print输出函数的最终值,fun(2)给函数传一个实参
8、函数式编程:
(1)、map函数:
例如:
num = [1,2,3,4,5,6,7] // 定义一个变量
n = map(lambda x:x+1,num) // 用map函数调用匿名函数(或自定义函数)和变量,且对变量里面的每一个值都操作一遍
print(list(n)) //返回值转换成列表并输出
(2)、filter函数
例如:
test = ["tom_sb","jony_sb","lucy_sb","xyyp"]
n = filter(lambda x:x.startswith('x'),test) //filter取布尔值,为True 的则输出
print(list(n))
(3)、reduce函数:
例如:
from functools import reduce //导入函数模块
li = [1,2,3,4,5,100]
n = reduce(lambda x,y:x+y,li) //相当于把列表里面的字符相加得结果,要操作的对象可以是列表,元组,集合等等这样的类型
print(n)
9、内置函数:
abs() 取一个数字的绝对值,可以是负数和正数,绝对值为正数
print(abs(-10))
结果:

all() 判断一个类型的布尔值,空为False,不空为True
print(all('x'))
print(all(['']))
结果:

any() 和all想反,有一个为真的则为True,都为假则为False
print(any('xyy'))
print(any(''))
结果:
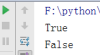
bin() 把一个十进制数转换成二进制数
print(bin(10)) //插入一个整形
结果:
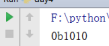
hex() 把一个10进制转换成16进制
print(hex(10)) //插入一个整形
结果:

oct() 把一个十进制数转换成8进制
print(oct(10)) //插入一个整形
结果:
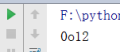
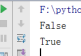
bool() 判断一个元素的布尔值
print(bool(0)) //c插入一个为false的值
print(bool(1)) //插入一个为True的值
结果:
bytes() 将一个字符串进行编码,用什么类型编码的就怎么解码
print(bytes('你好',encoding='utf8').decode('utf8')) //utf8编码解码
print(bytes('你好',encoding='gbk').decode('gbk')) //gbk编码解码
print(bytes('你好',encoding='gbk').decode('utf8')) //gbk编码,utf8解码
结果:

chr() 判断一个数字代表的ascii码是什么
print(chr(87))
print(chr(109))
print(chr(43))
结果:
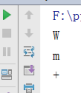
ord() 和chr想反,判断字符在ascii码中的位置
print(ord('y'))
print(ord('+'))
print(ord("p"))
结果:

dir() 查看一个内置函数都有什么功能
print(dir(dir)) //查看它本身有什么功能
结果:

divmod() 一个数除以一个数得商和余数
print(divmod(57,4)) // 54/7结果是商和余数
结果:

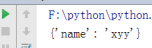
eval() (1)将一个字符串中的内容提取出来
test = "{'name':'xyy'}" //定义一个字典形式的字符串
print(eval(test))
结果:
(2)将一个计算表达式进行计算
print(eval('100+200*(40/8)-200')) // 传一个算法表达式
结果:

hash() 将一个元素转换成一个固定长度的hash值
print(hash('xyy')) //一个可hash的值
结果:

help() 查看一个内置函数的帮助和使用方法
print(help(hash))
结果:

globals() 打印全局变量
name = "xyy" //定义一个全局变量
def test():
print(globals()) //打印全局变量
test() //执行函数
结果:

locals() 打印局部变量
def test():
name = ['xyp','xyy'] //定义一个局部变量
print(locals())
test()
结果:

pow() 取两个整数的幂和幂的余数
print(pow(4,2)) // 计算这两个数的几次方
print(pow(3,6,5)) // 计算次方并取余数
结果:
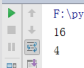
sum() 取整数序列类型的和
num = [1,2,3,4,5,6]
print(sum(num))
结果:
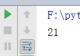
max() 打印一个数据类型中的最大值
int_l = [1,2,5,9,10] //定义一个数字列表
print(max(int_l))
结果:

min() 打印一个数据类型的最小值
int_l = [1,2,5,9,10]
print(min(int_l))
结果:

zip() 拉链的形式使前后元素值相互对应
print(list(zip(('name','age'),('xyy',19))))
结果:

max和zip结合使用:
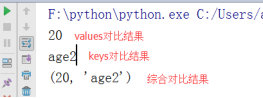
test = {'age1':19,'age2':20} // 定义一个字典
print(max(test.values())) //比较values值
print(max(test.keys())) // 比较keys值
print(max(zip(test.values(),test.keys()))) //结合比较
结果:
终极结合:
people = [
{'name':'xyp','age':1000},
{'name':'wpq','age':10000},
{'name':'xyy',"age":99}
]
print(max(people,key=lambda test:test['age']))
结果:

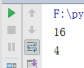
pow() 取两个整数的幂和幂的余数
print(pow(4,2)) // 计算这两个数的几次方
print(pow(3,6,5)) // 计算次方并取余数
结果:
10、闭包函数
例:
from urllib.request import urlopen #加载urlopen模块
def f(url): #定义函数
def f1(): #嵌套函数
c = urlopen(url).read()
print(c)
return f1 #返回值取嵌套函数的内存地址
n = f('http://www.baidu.com')
n()
闭包函数:内部函数包含对外部作用域而不是对全局作用域的名字的引用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号