1.为什么学习Python?
2.通过什么途径学习的Python?
3.Python和Java、PHP、C、C#、C++等其他语言的对比?
4.简述解释型和编译型编程语?
解释 -- 运行时必需用解释器把程序一行一行执行, 运行比较慢, 因为是运行时才把程序解析并执行. 优点是移植性, 不同的机器只要有解释器就可以运行相同的程序 编译 -- 先把程序转成 CPU 跟操作系统认识的机械码, 执行程序就是直接执行机械码, 所以速度比较快, 但因为是机械码 (加上一些操作系统的 loader 所要的信息), 不同的 CPU 与操作系统并不能运行编译后的程序
5.Python解释器种类以及特点?

#CPython:CPython是使用最广且被的Python解释器 当我们从Python官方网站下载并安装好Python 2.7后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。 #IPython IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。 CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。 #PyPy PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。 绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。 #Jython Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。 #IronPython IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
6.位和字节的关系?
8位等于1个字节
7.b、B、KB、MB、GB 的关系
8b=1B 1024B=1KB 1024KB=1MB 1024MB=1GB
8.请至少列举5个 PEP8 规范(越多越好)
 View Code
View Code
一 代码编排
缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。
每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
二 文档编排
模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。
不要在一句import中多个库,比如import os, sys不推荐。
如果采用from XX import XX引用库,可以省略‘module.’,都是可能出现命名冲突,这时就要采用import XX。
三 空格的使用
总体原则,避免不必要的空格。
各种右括号前不要加空格。
逗号、冒号、分号前不要加空格。
函数的左括号前不要加空格。如Func(1)。
序列的左括号前不要加空格。如list[2]。
操作符左右各加一个空格,不要为了对齐增加空格。
函数默认参数使用的赋值符左右省略空格。
不要将多句语句写在同一行,尽管使用‘;’允许。
if/for/while语句中,即使执行语句只有一句,也必须另起一行。
四 注释
总体原则,错误的注释不如没有注释。所以当一段代码发生变化时,第一件事就是要修改注释!
注释必须使用英文,最好是完整的句子,首字母大写,句后要有结束符,结束符后跟两个空格,开始下一句。如果是短语,可以省略结束符。
块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔。比如:
# Description : Module config.
#
# Input : None
#
# Output : None
行注释,在一句代码后加注释。比如:x = x + 1 # Increment x
但是这种方式尽量少使用。
避免无谓的注释。
五 文档描述
为所有的共有模块、函数、类、方法写docstrings;非共有的没有必要,但是可以写注释(在def的下一行)。
如果docstring要换行,参考如下例子,详见PEP 257
"""Return a foobang
Optional plotz says to frobnicate the bizbaz first.
"""
六 命名规范
总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。
尽量单独使用小写字母‘l’,大写字母‘O’等容易混淆的字母。
模块命名尽量短小,使用全部小写的方式,可以使用下划线。
包命名尽量短小,使用全部小写的方式,不可以使用下划线。
类的命名使用CapWords的方式,模块内部使用的类采用_CapWords的方式。
异常命名使用CapWords+Error后缀的方式。
全局变量尽量只在模块内有效,类似C语言中的static。实现方法有两种,一是__all__机制;二是前缀一个下划线。
函数命名使用全部小写的方式,可以使用下划线。
常量命名使用全部大写的方式,可以使用下划线。
类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线。
类的属性有3种作用域public、non-public和subclass API,可以理解成C++中的public、private、protected,non-public属性前,前缀一条下划线。
类的属性若与关键字名字冲突,后缀一下划线,尽量不要使用缩略等其他方式。
为避免与子类属性命名冲突,在类的一些属性前,前缀两条下划线。比如:类Foo中声明__a,访问时,只能通过Foo._Foo__a,避免歧义。如果子类也叫Foo,那就无能为力了。
类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。
七 编码建议
编码中考虑到其他python实现的效率等问题,比如运算符‘+’在CPython(Python)中效率很高,都是Jython中却非常低,所以应该采用.join()的方式。
尽可能使用‘is’‘is not’取代‘==’,比如if x is not None 要优于if x。
使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自Exception。
异常中不要使用裸露的except,except后跟具体的exceptions。
异常中try的代码尽可能少。比如:
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)
要优于
try:
# Too broad!
return handle_value(collection[key])
except KeyError:
# Will also catch KeyError raised by handle_value()
return key_not_found(key)
使用startswith() and endswith()代替切片进行序列前缀或后缀的检查。比如:
Yes: if foo.startswith('bar'):优于
No: if foo[:3] == 'bar':
使用isinstance()比较对象的类型。比如
Yes: if isinstance(obj, int): 优于
No: if type(obj) is type(1):
判断序列空或不空,有如下规则
Yes: if not seq:
if seq:
优于
No: if len(seq)
if not len(seq)
字符串不要以空格收尾。
二进制数据判断使用 if boolvalue的方式。
9.通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011”
十进制转换成二进制:v = 18
八进制转换成十进制:v = “011”
十进制转换成八进制:v = 30
十六进制转换成十进制:v = “0x12”
十进制转换成十六进制:v = 87
v1 = "0b1111011" print(int(v1, 2)) # 123 v2 = 18 print(bin(v2)) # 0b10010 v3 = "011" print(int(v3, 8)) # 9 v4 = 30 print(oct(v4)) # 0o36 v5 = "0x12" print(int(v5, 16)) # 18 v6 = 87 print(hex(v6)) # 0x57
10.请编写一个函数实现将IP地址转换成一个整数
如 10.3.9.12 转换规则为: 10 00001010 3 00000011 9 00001001 12 00001100 再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
ip = "10.3.9.12"
def exchange(ip):
ip_list = ip.split(".")
bin_num = "".join([str(bin(int(i))) for i in ip_list])
bin_num = bin_num.replace("0b", "0000")
print(bin_num)
return int(bin_num, 2)
print(exchange(ip))
11.python递归的最大层数?
998
12.求结果:
v1 = 1 or 3 # 1 v2 = 1 and 3 # 3 v3 = 0 and 2 and 1 # 0 v4 = 0 and 2 or 1 # 1 v5 = 0 and 2 or 1 or 4 # 1 v6 = 0 or Flase and 1 # False
13.ascii、unicode、utf-8、gbk 区别?
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号 ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符 ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了 为了满足中文和英文,中国人定制了GBK GBK:2Bytes代表一个中文字符,1Bytes表示一个英文字符 为了满足其他国家,各个国家纷纷定制了自己的编码 日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里 能够兼容万国字符 与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码 这就是unicode(定长), 统一用2Bytes代表一个字符, 虽然2**16-1=65535,但unicode却可以存放100w+个字符,因为unicode存放了与其他编码的映射关系,准确地说unicode并不是一种严格意义上的字符编码表 很明显对于通篇都是英文的文本来说,unicode的式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的) 于是产生了UTF-8(可变长,全称Unicode Transformation Format),对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存 总结:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性
14.字节码和机器码的区别?
机器码(machine code),学名机器语言指令,有时也被称为原生码(Native Code),是电脑的CPU可直接解读的数据。 字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
15.三元运算规则以及应用场景?
三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值
a = 1 b = 2 c = a if a > 1 else b # 如果a大于1的话,c=a,否则c=b
16.用一行代码实现数值交换:
a = 1
b = 2
a,b = b,a
17.Python3和Python2中 int 和 long的区别?
python3去除了long类型,现在只有一种整型——int,但它的行为就像python2版本的long
18.xrange和range的区别?
在python2中: range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长,生成一个序列 >>> range(5) [0, 1, 2, 3, 4] >>> range(1,5) [1, 2, 3, 4] >>> range(0,6,2) [0, 2, 4] xrange用法与range完全相同,所不同的是生成的不是一个数组,而是一个生成器。 >>> xrange(5) xrange(5) >>> list(xrange(5)) [0, 1, 2, 3, 4] >>> xrange(1,5) xrange(1, 5) >>> list(xrange(1,5)) [1, 2, 3, 4] >>> xrange(0,6,2) xrange(0, 6, 2) >>> list(xrange(0,6,2)) [0, 2, 4] 由上面的示例可以知道:要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间,这两个基本上都是在循环的时候用。 在 Python 3 中,range() 是像 xrange() 那样实现,xrange()被抛弃
19.文件操作时:xreadlines和readlines的区别?
20.列举布尔值为False的常见值?
0,空字典,空字符串,空列表
21.字符串、列表、元组、字典每个常用的5个方法?
字符串
print(name.capitalize()) # 把字符串的第一个字符大写
print(name.isspace()) # 是否包含空格
print(name.replace('Li', '')) # 替换操作
print(name.split('m')) # 分割操作,打印: ["I'a", ' LiChengGuan']
print(name.strip()) # 去掉字符串的左右空格
print(name.find('Li')) # 查找,打印 5,即返回开始的索引值,否则返回-1
print(name.index('Li')) # 查找,打印 5,即返回开始的索引值,没有则抛异常
列表
s = [1, 2, 3, 4]
s1 = [5, 6, 7, 8]
s.extend(s1) # 在列表末尾扩展另一个列表
s.append('测试拼接') # 列表末尾添加新的元素
s.insert(0, '测试拼接') # 指定位置插入元素
s.pop(0) # 指定位置删除,默认删除最后一个
s.remove(3) # 移除列表中某个值的第一个匹配项,没有会抛异常
s.clear() # 清空
s.reverse() # 反向列表中元素
字典
print(dic.keys()) # 输出所有键
print(dic.values()) # 输出所有值
dic.pop('code') # 删除 code 键
dic.clear() # 清空
del dic # 删除
22.lambda表达式格式以及应用场景?
简单来说,编程中提到的 lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数,lambda是一个表达式
23.pass的作用?
pass是空语句,是为了保持程序结构的完整性。pass 不做任何事情,一般用做占位语句
24.*arg和**kwarg作用
这是一种特殊的语法,在函数定义中使用*args和kwargs传递可变长参数. *args用作传递非命名键值可变长参数(位置参数),如列表元祖; kwargs用作传递键值可变长参数,如字典.
25.is和==的区别
is 比较的是两个实例对象是不是完全相同,它们是不是同一个对象,占用的内存地址是否相同。莱布尼茨说过:“世界上没有两片完全相同的叶子”,这个is正是这样的比较,比较是不是同一片叶子(即比较的id是否相同,这id类似于人的身份证标识)。 == 比较的是两个对象的内容是否相等,即内存地址可以不一样,内容一样就可以了。这里比较的并非是同一片叶子,可能叶子的种类或者脉络相同就可以了。默认会调用对象的 __eq__()方法
26.简述Python的深浅拷贝以及应用场景?
Python采用基于值得内存管理模式,赋值语句的执行过程是:首先把等号右侧标识的表达式计算出来,然后在内存中找一个位置把值存放进去,最后创建变量并指向这个内存地址。Python中的变量并不直接存储值,而是存储了值的内存地址或者引用 简单地说,浅拷贝只拷贝一层(如果有嵌套),深拷贝拷贝所有层
27.Python垃圾回收机制?
28.Python的可变类型和不可变类型?
不可变类型 : 基础类型字符串,数字,布尔值,字节.另外还有一个元组 可变类型 : 数据结构列表,字典,集合
29.求结果:
v = dict.fromkeys(['k1','k2'],[])
v[‘k1’].append(666)
print(v)
v[‘k1’] = 777
print(v)
{'k1': [666], 'k2': [666]}
{'k1': 777, 'k2': [666]}
30.求结果: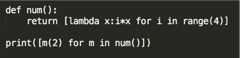
[6,6,6,6]
31.列举常见的内置函数?
enumertae:枚举,返回索引与值的元组 zip:拉链函数,接收多个可迭代对象,将对象相同索引位置放在一个元组中,返回一个迭代器,返回迭代器中元素个数由最短的可迭代对象决定 filter:过滤函数,接收一个函数和一个可迭代对象,生成一个迭代器.将可迭代对象的每一个元素带入函数中,如果返回结果为True,则把元素添加入迭代器中 map:处理函数,接收一个函数和一个可迭代对象,生成一个迭代器,将可迭代对象的每一个元素带入函数中,把返回值添加入迭代器中 callble:判断参数是不是可调用的 dir:查看内置属性和方法的字符串 super:根据__mro__属性去查找方法 isinstance:判断一个对象是不是这个类实例化出来的 iscubclass:判断一个类是不是另一个类的子类,也可以判断两个类是不是相同的类 property:在类中定义一个可控属性
32.filter、map、reduce的作用?
functools.reduce reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算, from functools import reduce reduce(lambda x,y: x+y, [1, 2, 3]) # 6 reduce(lambda x, y: x+y, [1,2,3], 9) # 15
33.一行代码实现9*9乘法表
34.如何安装第三方模块?以及用过哪些第三方模块?
pip 安装 下载源码包 先执行 python setup.py build 然后执行 python setup.py install
35.至少列举8个常用模块都有那些?
36.re的match和search区别?
match # 从头开始匹配 search # 匹配第一个
37.什么是正则的贪婪匹配?
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result1 = re.match('^He.*(\d+).*Demo$', content) # 贪婪匹配,尽可能多的匹配
result2 = re.match('^He.*?(\d+).*Demo$', content) # 非贪婪匹配,尽可能少的匹配
print(result1.group(1)) # 7
print(result2.group(1)) # 1234567
38.求结果: a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
a是一个列表 b是一个生成器
39.求结果: a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
1,2,False,True
40.def func(a,b=[]) 这种写法有什么坑?
函数定义时生成默认b的列表,而不是每次调用时生成一个空列表
41.如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
a = '1,2,3'.split(',')
print(a)
42.如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
[int(i) for i in ['1','2','3']]
43.比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
a,b没有区别其中元素都是数字,c中元素是元祖
44.如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
a = [i*i for i in range(1,11)]
45.一行代码实现删除列表中重复的值 ?
转为集合
46.如何在函数中设置一个全局变量 ?
global关键字
47.logging模块的作用?以及应用场景?
logging用来记录日志 可以自定制日志的格式、级别及输出形式
48.请用代码简答实现stack 。
Stack():创建一个新的空栈 push(item):添加一个新的元素 item到栈顶 pop():弹出栈顶元素 peek():返回栈顶元素,且不从栈中删除 is_empty():判断栈是否为空 size():返回栈的元素个数 class Stack: def __init__(self): self.items=[] def is_empty(self): return self.items==[] def push(self,item): self.items.append(item) def pop(self): return self.items.pop() def peek(self): return self.items[len(self.items)-1] def size(self): return len(self.items)
49.常用字符串格式化哪几种?
%占位符以及format方法
50.简述 生成器、迭代器、可迭代对象 以及应用场景?
生成器 : 自己实现的迭代器 迭代器 : 调用next()方法,从中取值,或抛出一个异常.也有__iter__方法 可迭代对象 : 拥有__iter__方法,返回一个迭代器 应用场景 : 处理大量数据时逐个取值
51.用Python实现一个二分查找的函数。
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def search(zhi,li,start=0,end=None):
end = len(li) if end is None else end
zj = (end - start) // 2+start
if start<=end:
if zhi>li[zj]:
return search(3,li,start=zj+1,end=end)
elif zhi<li[zj]:
return search(3,li,start=start,end=zj-1)
else:
return zj
return '找不到这个值'
print(search(8,li)
52.谈谈你对闭包的理解?
内部函数包含了对外部函数变量的引用
53.os和sys模块的作用?
os : 系统相关 sys : 解释器相关
54.如何生成一个随机数?
random.randint()
55.如何使用python删除一个文件?
os.remove()
56.谈谈你对面向对象的理解?
57.Python面向对象中的继承有什么特点?
58.面向对象深度优先和广度优先是什么?
执行方法的查找顺序 在经典类中,是深度优先,先把一条线查完(栈,) 在新式类中,广度优先(顺着一条线查,如果还有别的路可以查到一个类,这条路就终止了,换一条线查) python3中都是新式类,在python中如果你创建了一个类,并且该类没有继承任意类,那么他就是一个经典类
59.面向对象中super的作用?
按照mro的顺序去查找并调用父类的方法
60.是否使用过functools中的函数?其作用是什么?
经常使用他的装饰器修复的函数functool.wraps,还有偏函数functools.partial
61.列举面向对象中带爽下划线的特殊方法,如:__new__、__init__
__str__ : __call__ : __getattr__ : __setattr__ : __enter__ : __exit__ : __getitem__ : __setitem__ : __iter__ :
62.如何判断是函数还是方法?
print(isinstance(obj.func, FunctionType)) # False print(isinstance(obj.func, MethodType)) # True
63.静态方法和类方法区别?
静态方法 : 相当于在类作用域下的普通函数,不进行与类或实例相关的操作 类方法 : 由类调用,进行与类有关的操作
64.列举面向对象中的特殊成员以及应用场景
65.1、2、3、4、5 能组成多少个互不相同且无重复的三位数
66.什么是反射?以及应用场景?
利用字符串获取对象的属性或方法,WEB框架的CBV,配置文件获取类
67.metaclass作用?以及应用场景?
metaclass是类的产生类,而并非继承类 通过它来控制类的产生,以及类实例化的操作 wtform中实例化自定义form类时执行了其元类的__call__方法
68.用尽量多的方法实现单例模式。
69.装饰器的写法以及应用场景。
70.异常处理写法以及如何主动跑出异常(应用场景)
try:
执行语句
except 异常类型:
触发异常后执行的语句
else:
没有触发异常执行的语句
findlly:
有没有异常都执行的语句
# 主动抛出异常
raise 异常类实例
71.什么是面向对象的mro
方法查找的顺序
72.isinstance作用以及应用场景?
用于判断一个对象是否是一个类或者其子类的实例。
73.写代码并实现:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would
have exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1]
for i in range(len(_list)):
for j in range(i,len(_list)):
if _list[i]+_list[j] ==9:
return i,j
74.json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
字符串、列表、字典、数字、布尔值、None
自定义cls类
class MyEncoder(json.JSONEncoder):
def default(self, o): # o是数据类型
if isinstance(o,datetime.datetime):
return o.strftime('%Y-%m-%d')
else:
return super(MyEncoder,self).default(o)
75.json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
dumps时指定ensure_ascii=False
76.什么是断言?应用场景?
断言条件为真时代码继续执行,否则抛出异常,这个异常通常不会去捕获他.我们设置一个断言目的就是要求必须实现某个条件
77.有用过with statement吗?它的好处是什么?
文件操作时使用过. with语句下代码完成后调用求值语句返回对象的__exit__方法,可以实现一些操作,比如关闭文件
78.使用代码实现查看列举目录下的所有文件。
# 递归的方式
def print_directory_contents(sPath):
import os
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath, sChild)
if os.path.isdir(sChildPath):
print_directory_contents(sChildPath)
else:
print(sChildPath)
79.简述 yield和yield from关键字。
yield : 生成器函数关键字 yield from : 相当于for i in obj : yield i
第二部分 网络编程和并发(34题)
80.简述 OSI 七层协议。
开放式系统互联参考模型,从逻辑上将网络划分为7层,它从低到高分别是:物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。 ISO制定的OSI参考模型的过于庞大、复杂招致了许多批评。与此对照,由技术人员自己开发的TCP/IP协议栈获得了更为广泛的应用
81.什么是C/S和B/S架构?
c/s : 客户端/服务端 b/s : 浏览器/服务端
82.简述 三次握手、四次挥手的流程。
# 三次握手 客户端 : 发出请求 服务端 : 收到请求并相应 # 说明服务端可以收到客户端的请求 客户端 : 收到响应创建连接# 说明客户端可以收到服务端的请求 # 四次挥手 任意一方: 发出断开连接请求 另一方 : 收到响应,并回复 另一方 : 发出断开连接请求 任意一方: 收到响应,断开连接
83.什么是arp协议?
arp协议就是ip地址转换为MAC地址的协议
84.TCP和UDP的区别?
TCP : 通信前创建连接 UDP : 通信前不需创建连接
85.什么是局域网和广域网?
86.为何基于tcp协议的通信比基于udp协议的通信更可靠?
TCP通信前创建连接,确保了连接两方能够接收到数据
87.什么是socket?简述基于tcp协议的套接字通信流程。
socket位于应用层与传输层之间,实现了两个相同主机或不同主机进程间的互相通信
# 服务端
创建TCP套接字对象
绑定ip端口
开始监听请求
接收发送数据
# 客户端
创建TCP套接字对象
连接指定IP端口
接收发送数据
88.什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象?
TCP是流式传送的 也就是连接建立后可以一直不停的发送 并没有明确的边界定义.
发送端-接收端都存在这一个缓冲区
由接收方造成的粘包
当接收方不能及时接收缓冲区的包,造成多个包接收就产生了粘包
客户端发送一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次
遗留的数据
由传输方造成的粘包
tcp协议中会使用Nagle算法来优化数据。发送时间间隔短,数据量小的包会一起发送,造成粘包
89.IO多路复用的作用?
监听多个soket的状态变化
90.什么是防火墙以及作用?
它是一种位于内部网络与外部网络之间的网络安全系统。一项信息安全的防护系统,依照特定的规则,允许或是限制传输的数据通过。 防火可以使企业内部局域网(LAN)网络与Internet之间或者与其他外部网络互相隔离、限制网络互访用来保护内部网络。
91.select、poll、epoll 模型的区别?
selete : 有最大连接数 遍历 支持win poll : 无最大连接数 遍历 支持win epoll : 无最大连接数 事件通知 不支持win
92.简述 进程、线程、协程的区别 以及应用场景?
# 进程 一个任务,进程之间内存隔离,一个进程修改数据不会影响其他进程(创建变量,修改变量值) # 线程 线程位于进程内 一个进程内至少有一个线程,线程之间资源共享.一个线程修改数据其他进程也会受影响所以有了锁的概念 # 协程 代码级别的保存状态+切换 多线程,协程用于IO密集型,如socket,爬虫,web,抢占cpu资源 多进程用于计算密集型,如金融分析,利用多核优势
93.GIL锁是什么鬼?
Cpython解释器的一把锁,同一时间只允许一个进程中的一个线程执行
94.Python中如何使用线程池和进程池?
95.threading.local的作用?
创建一个对象,每个线程为该对象设置值数据都是隔离的
96.进程之间如何进行通信?
中间介质 socket : 直接通信
97.什么是并发和并行?
并发 : 看上去是在同时工作,实际上是cpu一直在切换着工作 并行 : 利用多核同时工作多个任务
98.进程锁和线程锁的作用?
进程锁 : 防止进程同时操作一套文件系统 线程锁 : 防止多个线程同时修改进程内数据
99.解释什么是异步非阻塞?
# 非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程 #异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果。当该异步功能完成后, # 通过状态、通知或回调来通知调用者。
100.路由器和交换机的区别?
路由器 : 连接外部网络,有接入外部的线 交换机 : 连接内部网络,没有接入外部的线
101.什么是域名解析?
我们在浏览器上输入网站域名时,会去请求DNS服务器获取该域名对应的IP地址,再去访问改地址
102.如何修改本地hosts文件?
win : C:\Windows\System32\drivers\etc\hosts linux : /etc/hosts 按格式修改即可
103.生产者消费者模型应用场景及优势?
生产者与消费者模式是通过一个容器来解决生产者与消费者的强耦合关系,生产者与消费者之间不直接进行通讯, 而是利用阻塞队列来进行通讯,生产者生成数据后直接丢给阻塞队列,消费者需要数据则从阻塞队列获取,实际应 用中,生产者与消费者模式则主要解决生产者与消费者生产与消费的速率不一致的问题,达到平衡生产者与消费者 的处理能力,而阻塞队列则相当于缓冲区。 # 应用场景 由一个线程生成订单,并将其放入队列中.由多个线程去处理 # 优势 平衡生产者与消费者的处理能力
104.什么是cdn?
CDN的全称是Content Delivery Network,即内容分发网络。 其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。 通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根 据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近 的服务节点上。 其目的是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
105.LVS是什么及作用?
LVS的英文全称是Linux Virtual Server,即Linux虚拟服务器 LVS主要用于多服务器的负载均衡。它工作在网络层,可以实现高性能,高可用的服务器集群技术。它廉价,可把 许多低性能的服务器组合在一起形成一个超级服务器。它易用,配置非常简单,且有多种负载均衡的方法。它稳定 可靠,即使在集群的服务器中某台服务器无法正常工作,也不影响整体效果。另外可扩展性也非常好
106.Nginx是什么及作用?
107.keepalived是什么及作用?
108.haproxy是什么以及作用?
109.什么是负载均衡?
110.什么是rpc及应用场景?
111.简述 asynio模块的作用和应用场景。
112.简述 gevent模块的作用和应用场景。
113.twisted框架的使用和应用?
第三部分 数据库和缓存(46题)
114.列举常见的关系型数据库和非关系型都有那些?
115.MySQL常见数据库引擎及比较?
116.简述数据三大范式?
117.什么是事务?MySQL如何支持事务?
118.简述数据库设计中一对多和多对多的应用场景?
119.如何基于数据库实现商城商品计数器?
常见SQL(必备)
详见武沛齐博客:https://www.cnblogs.com/wupeiqi/articles/5729934.html
120.简述触发器、函数、视图、存储过程?
121.MySQL索引种类
122.索引在什么情况下遵循最左前缀的规则?
123.主键和外键的区别?
124.MySQL常见的函数?
125.列举 创建索引但是无法命中索引的8种情况。
126.如何开启慢日志查询?
127.数据库导入导出命令(结构+数据)?
128.数据库优化方案?
129.char和varchar的区别?
130.简述MySQL的执行计划?
131.在对name做了唯一索引前提下,简述以下区别:
select * from tb where name = ‘Oldboy-Wupeiqi’
select * from tb where name = ‘Oldboy-Wupeiqi’ limit 1
132.1000w条数据,使用limit offset 分页时,为什么越往后翻越慢?如何解决?
133.什么是索引合并?
134.什么是覆盖索引?
135.简述数据库读写分离?
136.简述数据库分库分表?(水平、垂直)
137.redis和memcached比较?
138.redis中数据库默认是多少个db 及作用?
139.python操作redis的模块?
140.如果redis中的某个列表中的数据量非常大,如果实现循环显示每一个值?
141.redis如何实现主从复制?以及数据同步机制?
142.redis中的sentinel的作用?
143.如何实现redis集群?
144.redis中默认有多少个哈希槽?
简述redis的有哪几种持久化策略及比较?
列举redis支持的过期策略。
MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中都是热点数据?
写代码,基于redis的列表实现 先进先出、后进先出队列、优先级队列。
如何基于redis实现消息队列?
如何基于redis实现发布和订阅?以及发布订阅和消息队列的区别?
什么是codis及作用?
什么是twemproxy及作用?
写代码实现redis事务操作。
redis中的watch的命令的作用?
基于redis如何实现商城商品数量计数器?
简述redis分布式锁和redlock的实现机制。
什么是一致性哈希?Python中是否有相应模块?
如何高效的找到redis中所有以oldboy开头的key?
第四部分 前端、框架和其他(155题)
谈谈你对http协议的认识。
谈谈你对websocket协议的认识。
什么是magic string ?
如何创建响应式布局?
你曾经使用过哪些前端框架?
什么是ajax请求?并使用jQuery和XMLHttpRequest对象实现一个ajax请求。
如何在前端实现轮训?
如何在前端实现长轮训?
vuex的作用?
vue中的路由的拦截器的作用?
axios的作用?
列举vue的常见指令。
简述jsonp及实现原理?
是什么cors ?
列举Http请求中常见的请求方式?
列举Http请求中的状态码?
列举Http请求中常见的请求头?
看图写结果:
看图写结果:
看图写结果:
看图写结果:
看图写结果:
看图写结果:
django、flask、tornado框架的比较?
什么是wsgi?
django请求的生命周期?
列举django的内置组件?
列举django中间件的5个方法?以及django中间件的应用场景?
简述什么是FBV和CBV?
django的request对象是在什么时候创建的?
如何给CBV的程序添加装饰器?
列举django orm 中所有的方法(QuerySet对象的所有方法)
only和defer的区别?
select_related和prefetch_related的区别?
filter和exclude的区别?
列举django orm中三种能写sql语句的方法。
django orm 中如何设置读写分离?
F和Q的作用?
values和values_list的区别?
如何使用django orm批量创建数据?
django的Form和ModeForm的作用?
django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新。
django的Model中的ForeignKey字段中的on_delete参数有什么作用?
django中csrf的实现机制?
django如何实现websocket?
基于django使用ajax发送post请求时,都可以使用哪种方法携带csrf token?
django中如何实现orm表中添加数据时创建一条日志记录。
django缓存如何设置?
django的缓存能使用redis吗?如果可以的话,如何配置?
django路由系统中name的作用?
django的模板中filter和simple_tag的区别?
django-debug-toolbar的作用?
django中如何实现单元测试?
解释orm中 db first 和 code first的含义?
django中如何根据数据库表生成model中的类?
使用orm和原生sql的优缺点?
简述MVC和MTV
django的contenttype组件的作用?
谈谈你对restfull 规范的认识?
接口的幂等性是什么意思?
什么是RPC?
Http和Https的区别?
为什么要使用django rest framework框架?
django rest framework框架中都有那些组件?
django rest framework框架中的视图都可以继承哪些类?
简述 django rest framework框架的认证流程。
django rest framework如何实现的用户访问频率控制?
Flask框架的优势?
Flask框架依赖组件?
Flask蓝图的作用?
列举使用过的Flask第三方组件?
简述Flask上下文管理流程?
Flask中的g的作用?
Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
为什么要Flask把Local对象中的的值stack 维护成一个列表?
Flask中多app应用是怎么完成?
在Flask中实现WebSocket需要什么组件?
wtforms组件的作用?
Flask框架默认session处理机制?
解释Flask框架中的Local对象和threading.local对象的区别?
Flask中 blinker 是什么?
SQLAlchemy中的 session和scoped_session 的区别?
SQLAlchemy如何执行原生SQL?
ORM的实现原理?
DBUtils模块的作用?
以下SQLAlchemy的字段是否正确?如果不正确请更正:
1
2
3
4
5
6
7
8
9
10
11
fromdatetime importdatetime
fromsqlalchemy.ext.declarative
importdeclarative_base
fromsqlalchemy importColumn, Integer, String, DateTime
Base =declarative_base()
classUserInfo(Base):
__tablename__ ='userinfo'
id=Column(Integer, primary_key=True, autoincrement=True)
name =Column(String(64), unique=True)
ctime =Column(DateTime, default=datetime.now())
SQLAchemy中如何为表设置引擎和字符编码?
SQLAchemy中如何设置联合唯一索引?
简述Tornado框架的特点。
简述Tornado框架中Future对象的作用?
Tornado框架中如何编写WebSocket程序?
Tornado中静态文件是如何处理的? 如: <link href="{{static_url("commons.css")}}" rel="stylesheet" />
Tornado操作MySQL使用的模块?
Tornado操作redis使用的模块?
简述Tornado框架的适用场景?
git常见命令作用:
简述以下git中stash命令作用以及相关其他命令。
git 中 merge 和 rebase命令 的区别。
公司如何基于git做的协同开发?
如何基于git实现代码review?
git如何实现v1.0 、v2.0 等版本的管理?
什么是gitlab?
github和gitlab的区别?
如何为github上牛逼的开源项目贡献代码?
git中 .gitignore文件的作用?
什么是敏捷开发?
简述 jenkins 工具的作用?
公司如何实现代码发布?
简述 RabbitMQ、Kafka、ZeroMQ的区别?
RabbitMQ如何在消费者获取任务后未处理完前就挂掉时,保证数据不丢失?
RabbitMQ如何对消息做持久化?
RabbitMQ如何控制消息被消费的顺序?
以下RabbitMQ的exchange type分别代表什么意思?如:fanout、direct、topic。
简述 celery 是什么以及应用场景?
简述celery运行机制。
celery如何实现定时任务?
简述 celery多任务结构目录?
celery中装饰器 @app.task 和 @shared_task的区别?
简述 requests模块的作用及基本使用?
简述 beautifulsoup模块的作用及基本使用?
简述 seleninu模块的作用及基本使用?
scrapy框架中各组件的工作流程?
在scrapy框架中如何设置代理(两种方法)?
scrapy框架中如何实现大文件的下载?
scrapy中如何实现限速?
scrapy中如何实现暂定爬虫?
scrapy中如何进行自定制命令?
scrapy中如何实现的记录爬虫的深度?
scrapy中的pipelines工作原理?
scrapy的pipelines如何丢弃一个item对象?
简述scrapy中爬虫中间件和下载中间件的作用?
scrapy-redis组件的作用?
scrapy-redis组件中如何实现的任务的去重?
scrapy-redis的调度器如何实现任务的深度优先和广度优先?
简述 vitualenv 及应用场景?
简述 pipreqs 及应用场景?
在Python中使用过什么代码检查工具?
简述 saltstack、ansible、fabric、puppet工具的作用?
B Tree和B+ Tree的区别?
请列举常见排序并通过代码实现任意三种。
请列举常见查找并通过代码实现任意三种。
请列举你熟悉的设计模式?
有没有刷过leetcode?
列举熟悉的的Linux命令。
公司线上服务器是什么系统?
解释 PV、UV 的含义?
解释 QPS的含义?
uwsgi和wsgi的区别?
supervisor的作用?
什么是反向代理?
简述SSH的整个过程。
有问题都去那些找解决方案?
是否有关注什么技术类的公众号?
最近在研究什么新技术?
是否了解过领域驱动模型?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号