

面向对象进阶
类型判断
issubclass
首先,我们先看issubclass() 这个内置函数可以帮我们判断x类是否是y类型的子类。

class Base:
pass
class Foo(Base):
pass
class Bar(Foo):
pass
print(issubclass(Bar, Foo)) # True
print(issubclass(Foo, Bar)) # False
print(issubclass(Bar, Base)) # True
type
然后我们来看type,type在前面的学习期间已经使用过了。type(obj) 表示查看obj是由哪个类创建的。
class Foo:
pass
obj = Foo()
print(obj, type(obj)) # 查看obj的类
isinstance
isinstance也可以判断x是y类型的数据。
class Base:
pass
class Foo(Base):
pass
class Bar(Foo):
pass
print(isinstance(Foo(), Foo)) # True
print(isinstance(Foo(), Base)) # True
print(isinstance(Foo(), Bar)) # False
isinstance可以判断该对象是否是家族体系中的(只能往上判断类)。
反射
为什么需要反射?
首先,我们来看这样一个需求。
从前有一个大牛,写了一堆特别牛B的代码。然后放在一个py文件(模块)中。这个时候你想使用一下大牛写的东西。但是呢,你首先得知道大牛写的这些代码都是干什么用的。那就需要你把大牛写的每一个函数跑一下。
大牛.py
def chi():
print("⼤⽜一顿吃100个螃蟹")
def he():
print("⼤牛一顿喝100瓶可乐")
def la():
print("⼤牛不⽤拉")
def shui():
print("⼤牛⼀次睡一年")
接下来,到你了。你要去一个一个调用。但是在你调用之前,大牛告诉你,他写了哪些方法,那现在就可以这么办了:
while 1:
print('''
作为大牛,我帮你写了
chi
he
la
shui
等功能,你自己看着办吧...
''')
func = input('请输入你要测试的功能:').strip()
if func == 'chi':
daniu.chi()
elif func == 'he':
daniu.he()
elif func == 'la':
daniu.la()
elif func == 'shui':
daniu.shui()
else:
print('大牛就这几个功能,别搞事情!')
这样写是写完了,但是...
如果大牛写了100个功能怎么办,你要写100个if判断吗?太累了吧,现有的知识解决不了这个问题呀,那怎么办?
我们可以使用反射来完成这样的功能,非常简单,我们现在可以获取要执行的功能,只不过我们使用input()函数获取的一个字符串,这个字符串和实际模块中的函数名是一样的。那我们就可以利用这一点,只要通过字符串动态的访问模块中的功能就可以了,反射就是做这个事情的。
什么是反射?
之前我们导入模块都是,先引入模块,然后通过模块去访问否个我们要用的功能,现在呢?我们手动输入要运行的功能,然后拿着这个功能去模块里查找,这就叫反射。
通俗点说就是通过字符串的形式操作对象相关的属性。Python中的一切事物都是对象(都可以使用反射)
我们首先来看一下,在Python中使用反射如何解决上面的问题吧。
import daniu
while 1:
print('''
作为大牛,我帮你写了
chi
he
la
shui
等功能,你自己看着办吧...
''')
func_str = input('请输入你要测试的功能:').strip()
if hasattr(daniu, func_str):
func = getattr(daniu, func_str)
func()
else:
print('大牛就这几个功能,别搞事情!')
上面的代码中用到了如下两个方法:
hasattr(对象, 字符串)是用来判断对象是否有字符串名称对应的这个属性(功能)。
getattr(对象,字符串)是用来获取对象中字符串名称对应的属性(功能)。
因为Python中一切皆对象,所以反射这个特性非常的有用,很多框架中都会用到此特性。
反射应用
接下来,我们先看个简单的例子:
class Person:
country = "China"
def eat(self):
pass
# 类中的内容可以这样动态的进⾏获取
print(getattr(Person, "country"))
print(getattr(Person, "eat")) # 相当于Foo.func 函数
# 对象⼀样可以
obj = Person()
print(getattr(obj, "country"))
print(getattr(obj, "eat")) # 相当于obj.func ⽅法
getattr可以从模块中获取内容,也可以从类中获取内容,也可以从对象中获取内容。又因为在Python中⼀切皆为对象,所以把反射理解为从对象中动态的获取成员。
反射的四个函数
关于反射, 其实⼀共有4个函数:
- hasattr(obj, str) 判断obj中是否包含str成员
- getattr(obj,str) 从obj中获取str成员。
- setattr(obj, str, value) 把obj中的str成员设置成value。这⾥的value可以是值,也可以是函数或者⽅法。
- delattr(obj, str) 把obj中的str成员删除掉。
class Foo:
pass
f = Foo()
print(hasattr(f, 'eat')) # False
setattr(f, 'eat', "123")
print(f.eat) # 被添加了⼀个属性信息
setattr(f, "eat", lambda x: x + 1)
print(f.eat(3)) # 4
print(f.eat) # 此时的eat既不是静态⽅法, 也不是实例⽅法, 更不是类⽅法. 就相当于你在类中写了个self.chi = lambda 是⼀样的
print(f.__dict__) # {'eat': <function <lambda> at 0x1015a2048>}
delattr(f, "eat")
print(hasattr(f, "eat")) # False
注意:以上操作都是在内存中进⾏的,并不会影响你的源代码。
补充importlib
importlib是一个可以根据字符串的模块名实现动态导入模块的库。
举个例子:
目录结构:
├── aaa.py
├── bbb.py
└── mypackage
├── __init__.py
└── xxx.py
使用importlib动态导入模块:
bbb.py
import importlib
func = importlib.import_module('aaa')
print(func)
func.f1()
m = importlib.import_module('mypackage.xxx')
print(m.age)
类的其他成员
列举类中的其他常见成员。
__str__
改变对象的字符串显示。可以理解为使用print函数打印一个对象时,会自动调用对象的__str__方法。
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
# 定义对象的字符串表示
def __str__(self):
return self.name
s1 = Student('张三', 24)
print(s1) # 会调用s1的__str__方法
__repr__
在python解释器环境下,会默认显示对象的repr表示。
>>> class Student:
... def __init__(self, name, age):
... self.name = name
... self.age = age
... def __repr__(self):
... return self.name
...
>>> s1 = Student('张三', 24)
>>> s1
张三
总结:
str函数或者print函数调用的是obj.__str__()
repr函数或者交互式解释器调用的是obj.__repr__()
注意:
如果__str__没有被定义,那么就会使用__repr__来代替输出。
__str__和__repr__方法的返回值都必须是字符串。
__format__

class Student:
def __init__(self, name, age):
self.name = name
self.age = age
# 定义对象的字符串表示
def __str__(self):
return self.name
def __repr__(self):
return self.name
__format_dict = {
'n-a': '{obj.name}-{obj.age}', # 姓名-年龄
'n:a': '{obj.name}:{obj.age}', # 姓名:年龄
'n/a': '{obj.name}/{obj.age}', # 姓名/年龄
}
def __format__(self, format_spec):
"""
:param format_spec: n-a,n:a,n/a
:return:
"""
if not format_spec or format_spec not in self.__format_dict:
format_spec = 'n-a'
fmt = self.__format_dict[format_spec]
return fmt.format(obj=self)
s1 = Student('张三', 24)
ret = format(s1, 'n/a')
print(ret) # 张三/24
__del__
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
class A:
def __del__(self):
print('删除了...')
a = A()
print(a) # <__main__.A object at 0x10164fb00>
del a # 删除了...
print(a) # NameError: name 'a' is not defined
__dict__和__slots__
Python中的类,都会从object里继承一个__dict__属性,这个属性中存放着类的属性和方法对应的键值对。一个类实例化之后,这个类的实例也具有这么一个__dict__属性。但是二者并不相同。
class A:
some = 1
def __init__(self, num):
self.num = num
a = A(10)
print(a.__dict__) # {'num': 10}
a.age = 10
print(a.__dict__) # {'num': 10, 'age': 10}
从上面的例子可以看出来,实例只保存实例的属性和方法,类的属性和方法它是不保存的。正是由于类和实例有__dict__属性,所以类和实例可以在运行过程动态添加属性和方法。
但是由于每实例化一个类都要分配一个__dict__变量,容易浪费内存。因此在Python中有一个内置的__slots__属性。当一个类设置了__slots__属性后,这个类的__dict__属性就不存在了(同理,该类的实例也不存在__dict__属性),如此一来,设置了__slots__属性的类的属性,只能是预先设定好的。
当你定义__slots__后,__slots__就会为实例使用一种更加紧凑的内部表示。实例通过一个很小的固定大小的小型数组来构建的,而不是为每个实例都定义一个__dict__字典,在__slots__中列出的属性名在内部被映射到这个数组的特定索引上。使用__slots__带来的副作用是我们没有办法给实例添加任何新的属性了。
注意:尽管__slots__看起来是个非常有用的特性,但是除非你十分确切的知道要使用它,否则尽量不要使用它。比如定义了__slots__属性的类就不支持多继承。__slots__通常都是作为一种优化工具来使用。--摘自《Python Cookbook》8.4
class A:
__slots__ = ['name', 'age']
a1 = A()
# print(a1.__dict__) # AttributeError: 'A' object has no attribute '__dict__'
a1.name = '张三'
a1.age = 24
# a1.hobby = '吹牛逼' # AttributeError: 'A' object has no attribute 'hobby'
print(a1.__slots__)
注意事项:
__slots__的很多特性都依赖于普通的基于字典的实现。
另外,定义了__slots__后的类不再 支持一些普通类特性了,比如多继承。大多数情况下,你应该只在那些经常被使用到的用作数据结构的类上定义__slots__,比如在程序中需要创建某个类的几百万个实例对象 。
关于__slots__的一个常见误区是它可以作为一个封装工具来防止用户给实例增加新的属性。尽管使用__slots__可以达到这样的目的,但是这个并不是它的初衷。它更多的是用来作为一个内存优化工具。
__item__系列
class Foo:
def __init__(self, name):
self.name = name
def __getitem__(self, item):
print(self.__dict__[item])
def __setitem__(self, key, value):
self.__dict__[key] = value
def __delitem__(self, key):
print('del obj[key]时,执行我')
self.__dict__.pop(key)
def __delattr__(self, item):
print('del obj.key时,执行我')
self.__dict__.pop(item)
f1 = Foo('sb')
print(f1.__dict__)
f1['age'] = 18
f1.hobby = '吹牛逼'
del f1.hobby
del f1['age']
f1['name'] = 'alex'
print(f1.__dict__)
__init__
使用Python写面向对象的代码的时候我们都会习惯性写一个 __init__ 方法,__init__ 方法通常用在初始化一个类实例的时候。例如:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return '<Person: {}({})>'.format(self.name, self.age)
p1 = Person('张三', 24)
print(p1)
上面是__init__最普通的用法了。但是__init__其实不是实例化一个类的时候第一个被调用的方法。当使用 Persion(name, age) 来实例化一个类时,最先被调用的方法其实是 __new__ 方法。
__new__
其实__init__是在类实例被创建之后调用的,它完成的是类实例的初始化操作,而 __new__方法正是创建这个类实例的方法。
class Person:
def __new__(cls, *args, **kwargs):
print('调用__new__,创建类实例')
return super().__new__(Person)
def __init__(self, name, age):
print('调用__init__,初始化实例')
self.name = name
self.age = age
def __str__(self):
return '<Person: {}({})>'.format(self.name, self.age)
p1 = Person('张三', 24)
print(p1)
输出:
调用__new__,创建类实例 调用__init__,初始化实例 <Person: 张三(24)>
__new__方法在类定义中不是必须写的,如果没定义的话默认会调用object.__new__去创建一个对象(因为创建类的时候默认继承的就是object)。
如果我们在类中定义了__new__方法,就是重写了默认的__new__方法,我们可以借此自定义创建对象的行为。
举个例子:
重写类的__new__方法来实现单例模式。
class Singleton:
# 重写__new__方法,实现每一次实例化的时候,返回同一个instance对象
def __new__(cls, *args, **kw):
if not hasattr(cls, '_instance'):
cls._instance = super().__new__(Singleton)
return cls._instance
def __init__(self, name, age):
self.name = name
self.age = age
s1 = Singleton('张三', 24)
s2 = Singleton('李四', 20)
print(s1, s2) # 这两实例都一样
print(s1.name, s2.name)
__call__
__call__ 方法的执行是由对象后加括号触发的,即:对象()。拥有此方法的对象可以像函数一样被调用。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __call__(self, *args, **kwargs):
print('调用对象的__call__方法')
a = Person('张三', 24) # 类Person可调用
a() # 对象a可以调用
注意:
__new__、__init__、__call__等方法都不是必须写的。
__doc__
定义类的描述信息。注意该信息无法被继承。
class A:
"""我是A类的描述信息"""
pass
print(A.__doc__)
__iter__和__next__
之前的课程中讲过,如果一个对象拥有了__iter__和__next__方法,那这个对象就是可迭代对象。
class A:
def __init__(self, start, stop=None):
if not stop:
start, stop = 0, start
self.start = start
self.stop = stop
def __iter__(self):
return self
def __next__(self):
if self.start >= self.stop:
raise StopIteration
n = self.start
self.start += 1
return n
a = A(1, 5)
from collections import Iterator
print(isinstance(a, Iterator))
for i in A(1, 5):
print(i)
for i in A(5):
print(i)
__enter__和__exit__
一个对象如果实现了__enter__和___exit__方法,那么这个对象就支持上下文管理协议,即with语句。
class A:
def __enter__(self):
print('进入with语句块时执行此方法,此方法如果有返回值会赋值给as声明的变量')
def __exit__(self, exc_type, exc_val, exc_tb):
"""
:param exc_type: 异常类型
:param exc_val: 异常值
:param exc_tb: 追溯信息
:return:
"""
print('退出with代码块时执行此方法')
print('1', exc_type)
print('2', exc_val)
print('3', exc_tb)
with A() as f:
print('进入with语句块')
# with语句中代码块出现异常,则with后的代码都无法执行。
# raise AttributeError('sb')
print('嘿嘿嘿')
上下文管理协议适用于那些进入和退出之后自动执行一些代码的场景,比如文件、网络连接、数据库连接或使用锁的编码场景等。
__len__
拥有__len__方法的对象支持len(obj)操作。
class A:
def __init__(self):
self.x = 1
self.y = 2
def __len__(self):
return len(self.__dict__)
a = A()
print(len(a))
__hash__
拥有__hash__方法的对象支持hash(obj)操作。
class A:
def __init__(self):
self.x = 1
self.x = 2
def __hash__(self):
return hash(str(self.x) + str(self.x))
a = A()
print(hash(a))
__eq__
拥有__eq__方法的对象支持相等的比较操作。
class A:
def __init__(self):
self.x = 1
self.y = 2
def __eq__(self,obj):
if self.x == obj.x and self.y == obj.y:
return True
a = A()
b = A()
print(a == b)
类的继承
抽象和继承
抽象是指找出物体之间的共同点,把这些相同的部分抽象成一个划分标准。
比如黑人和白人之间的共同点是都是人。
抽象最主要的作用是划分类别(可以隔离关注点,降低复杂度),看下图:
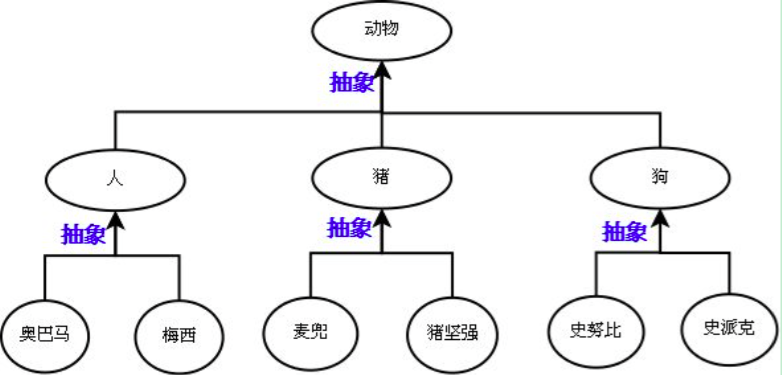
继承
继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构。
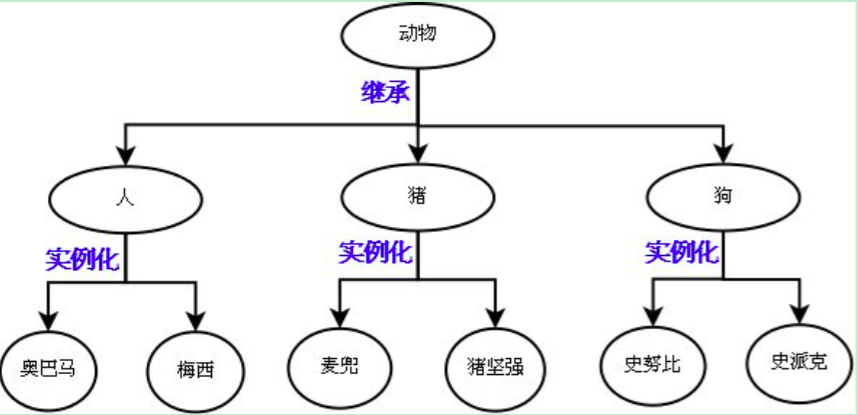
为什么要使用继承?
代码重用
使用继承的一个目的就是实现代码的重用。
在开发程序的过程中,如果我们定义了一个A类,然后又想新实现另外一个B类,但是B类的大部分内容与A类相同时我们就没有必要从头实现一个B类了,这时就可以使用类的继承。
通过继承的方式实现B类,让B类继承A类,B类就会‘遗传’A类的所有属性和方法(除私有成员外),从而实现代码重用。
看代码:
class Animal:
"""
人和狗都是动物,所以创造一个Animal基类
"""
def __init__(self, name, age):
self.name = name # 人和狗都有昵称;
self.age = age # 人和狗都有年龄
def eat(self):
print('{}在吃东西'.format(self.name))
# 创建一个Dog类继承Animal类
class Dog(Animal):
pass
# 创建一个Person类继承Animal类
class Person(Animal):
pass
# 实例化一个人
p1 = Person('张三', 18)
# 实例化一条狗
d1 = Dog('二哈', 5)
p1.eat() # 人能吃东西
d1.eat() # 狗也能吃东西
当然,我们在子类中还可以定义自己子类独有的一些属性和方法。
class Animal:
"""
人和狗都是动物,所以创造一个Animal基类
"""
def __init__(self, name, age):
self.name = name # 人和狗都有昵称;
self.age = age # 人和狗都有年龄
def eat(self):
print('{}在吃东西'.format(self.name))
# 创建一个Dog类继承Animal类
class Dog(Animal):
pass
# 创建一个Person类继承Animal类
class Person(Animal):
# Person类可以自己定义自己独有的方法
def dream(self):
print('{}在做梦...'.format(self.name))
# 实例化一个人
p1 = Person('张三', 18)
# 实例化一条狗
d1 = Dog('二哈', 5)
p1.eat() # 人能吃东西
d1.eat() # 狗也能吃东西
p1.dream() # 人能做梦
当然我们还可以重写父类的方法:
class Animal:
"""
人和狗都是动物,所以创造一个Animal基类
"""
def __init__(self, name, age):
self.name = name # 人和狗都有昵称;
self.age = age # 人和狗都有年龄
def eat(self):
print('{}在吃东西'.format(self.name))
# 创建一个Dog类继承Animal类
class Dog(Animal):
# 重写父类的eat方法,Dog实例以后都使用这个eat方法
def eat(self):
print('吃骨头吃骨头吃骨头')
规范类的行为
我们可以声明一个类,在该类中定义了一些方法名但是并没有实现具体的功能,等子类继承我这个类的时候再去实现方法应该有的功能。
举个例子:
我们要做一个电商网站,在写支付功能的时候,我们的客户可以选择支付宝支付、微信支付、银联支付等各种支付方式。那代码里应该怎么实现这个关系呢?
def check_out(payment, money):
"""
一个结账业务逻辑函数,实现具体的结账功能。
:param payment: 具体的支付方式实例对象
:param money: 需要支付的金额
:return:
"""
payment.pay(money) # 调用具体支付方式对象的pay方法
现在我们要动手实现支付宝支付和微信支付,两名萌萌的程序员就开工了,写出了下面的代码:
程序员A:
class AliPay:
"""支付宝支付"""
def __init__(self):
# 配置支付宝收款账号信息
pass
# 具体的支付方法
def pay(self, money):
print('支付宝支付了{}元'.format(money))
程序员B:
class WeChatPay:
"""微信支付"""
def __init__(self):
# 配置微信支付收款账号信息
pass
# 具体的支付方法
def zhifu(self, money):
print('使用支付宝支付了{}元'.format(money))
此时此刻,我们就会发现,我们确实需要为某些类定义一些统一的规则或约束。
# 定义一个支付的基类
class Payment:
# 规定子类必须实现pay方法,否则调用实例的pay方法时会抛出异常
def pay(self, *args, **kwargs):
raise NotImplementedError
class AliPay(Payment):
"""支付宝支付"""
def __init__(self):
# 配置支付宝收款账号信息
pass
# 实现父类中定义好的支付方法
def pay(self, money):
print('支付宝支付了{}元'.format(money))
class WeChatPay(Payment):
"""微信支付"""
def __init__(self):
# 配置微信支付收款账号信息
pass
# 具体的支付方法
def pay(self, money):
print('使用支付宝支付了{}元'.format(money))
p = WeChatPay()
check_out(p, 200)
Python中为了解决上面的问题,已经给我们提供了一套现成的工具。
from abc import ABCMeta, abstractmethod
class Payment(metaclass=ABCMeta):
# 子类必须实现pay方法,否则实例化子类的时候就会报错
@abstractmethod
def pay(self, money):
pass
class WeChatPay(Payment):
def fuqian(self, money):
print('微信支付了{}元'.format(money))
p = WeChatPay() # 实例化时就报错了
调用父类的方法
我们在子类中想要调用父类的方法,可以使用super()函数来完成。
class A:
def m1(self):
print('A.m1')
class B(A):
def m1(self):
print('B.m1')
super().m1() # 在子类中调用父类中的m1方法
b = B()
b.m1()
super()函数的一种常见用途是调用父类的__init__()方法,以确保父类被正确的初始化了。
class A:
def __init__(self):
self.x = 0
class B(A):
def __init__(self):
# 先调用父类的__init__()方法
super().__init__()
# 执行自己的初始化操作
self.y = 1
b = B()
print(b.x)
print(b.y)
多继承的顺序
Python中支持多继承!所以会存在一个继承顺序的问题。
首先我们来看一个经典的钻石继承问题:
class A:
def __init__(self):
print('进入A类')
print('离开A类')
class B(A):
def __init__(self):
print('进入B类')
super().__init__()
print('离开B类')
class C(A):
def __init__(self):
print('进入C类')
super().__init__()
print('离开C类')
class D(B, C):
def __init__(self):
print('进入D类')
super().__init__()
print('离开D类')
其中,A是父类,B, C 继承自A, D继承自 B和C,它们的继承关系如下:
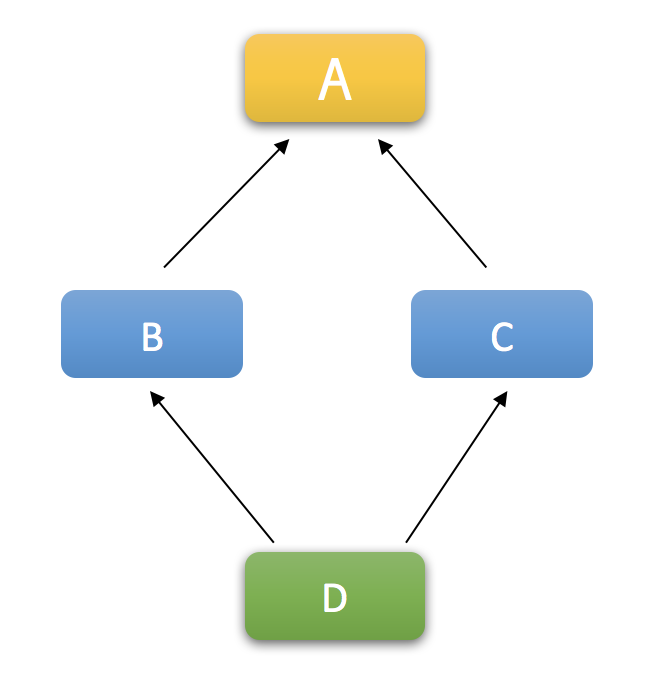
我们看一下实例化D的输出结果:
进入D类 进入B类 进入C类 进入A类 离开A类 离开C类 离开B类 离开D类
你会发现,super()函数并不是简单的调用父类的方法,因为上面的结果显示在“进入B类”之后打印的不是 “进入A类”,而是“进入C类”。
看来super()和父类没什么实质性的关系,那它是按照什么规则来调用方法的呢?
MRO列表
对于我们定义的每一个类,Python会计算出一个方法解析顺序(Method Resolution Order, MRO)列表,它代表了类继承的顺序,我们可以使用下面的方式获得某个类的 MRO 列表:
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
那这个 MRO 列表的顺序是怎么定的呢,它是通过一个 C3 线性化算法来实现的,这里我们就不去深究这个算法了,简单来说,一个类的 MRO 列表就是合并所有父类的 MRO 列表,并遵循以下三条原则:
- 子类永远在父类前面
- 如果有多个父类,会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
super()函数所做的事情就是在MRO列表中找到当前类的下一个类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号