浅谈C++11中的多线程(三)
摘要
本篇文章围绕以下几个问题展开:
- 进程和线程的区别
- 何为并发?C++中如何解决并发问题?C++中多线程的基本操作 浅谈C++11中的多线程(一) - 唯有自己强大 - 博客园 (cnblogs.com)
- 同步互斥原理以及如何处理数据竞争 浅谈C++11中的多线程(二) - 唯有自己强大 - 博客园 (cnblogs.com)
- 条件变量和原子操作
条件变量
一、何为条件变量
在前一篇文章浅谈C++11中的多线程(二) - 唯有自己强大 - 博客园 (cnblogs.com)中解释了线程同步的原理和实现,使用互斥锁解决数据竞争访问问题。我们在使用mutex时,一般都会期望加锁不要阻塞,总是能立刻拿到锁,然后尽快访问数据,用完之后尽快解锁,这样才能不影响并发性和性能。
如果需要等待某个条件的成立,我们就该使用条件变量(condition variable)了,那什么是条件变量呢?
C++11提供了condition_variable类。使用时需要include头文件<condition_variable>。
简单理解来说:如果把变量区看成是一座房子,那么前面两篇频繁用到的mutex可以看成是房门的锁,正常来说是房门常年打开的,锁并用不上。但是有了多线程以后,为了防止多个线程一窝蜂胡乱篡改里面的数据,所以就有了锁的概念。
现在假设每个线程都有一个管理锁的人,叫lock_guard,或者unique_lock,但是一次只能有一个人能够去操作锁(锁上或者是解锁)。一般来说他们是轮流去操作锁。而condition_variable则可以看做是门童,如果没有满足条件,门童就会通知线程的管锁人必须要休眠而不可以操作锁,可是一旦条件满足,他就会唤醒某些线程的管锁人可以去操作锁了。
二,为何要用条件变量
下面给出一个简单的程序示例:一个线程往队列中放入数据,一个线程从队列中提取数据,取数据前需要判断一下队列中确实有数据,由于这个队列是线程间共享的,所以,需要使用互斥锁进行保护,一个线程在往队列添加数据的时候,另一个线程不能取,反之亦然。程序实现代码如下:
//cond_var1.cpp用互斥锁实现一个生产者消费者模型 #include <iostream> #include <deque> #include <thread> #include <mutex> std::deque<int> q; //双端队列标准容器全局变量 std::mutex mu; //互斥锁全局变量 //生产者,往队列放入数据 void function_1() { int count = 10; while (count > 0) { std::unique_lock<std::mutex> locker(mu); q.push_front(count); //数据入队锁保护 locker.unlock(); std::this_thread::sleep_for(std::chrono::seconds(1)); //延时1秒 count--; } } //消费者,从队列提取数据 void function_2() { int data = 0; while ( data != 1) { std::unique_lock<std::mutex> locker(mu); if (!q.empty()) { //判断队列是否为空 data = q.back(); q.pop_back(); //数据出队锁保护 locker.unlock(); std::cout << "t2 got a value from t1: " << data << std::endl; } else { locker.unlock(); } } } int main() { std::thread t1(function_1); std::thread t2(function_2); t1.join(); t2.join(); getchar(); return 0; }
从代码中不难看出:在生产过程中,因每放入一个数据有1秒延时,所以这个生产的过程是很慢的;在消费过程中,存在着一个while循环,只有在接收到表示结束的数据的时候,才会停止,每次循环内部,都是先加锁,判断队列不空,然后就取出一个数,最后解锁。所以说,在1s内,做了很多无用功!这样的话,CPU占用率会很高,可能达到100%(单核)。
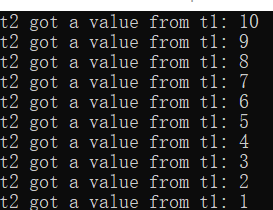
这就引入了条件变量来解决该问题:条件变量使用“通知—唤醒”模型,生产者生产出一个数据后通知消费者使用,消费者在未接到通知前处于休眠状态节约CPU资源;当消费者收到通知后,赶紧从休眠状态被唤醒来处理数据,使用了事件驱动模型,在保证不误事儿的情况下尽可能减少无用功降低对资源的消耗。
三,如何使用条件变量
C++标准库在< condition_variable >中提供了条件变量,借由它,一个线程可以唤醒一个或多个其他等待中的线程。原则上,条件变量的运作如下:
- 你必须同时包含< mutex >和< condition_variable >,并声明一个mutex和一个condition_variable变量;
- 那个通知“条件已满足”的线程(或多个线程之一)必须调用notify_one()或notify_all(),以便条件满足时唤醒处于等待中的一个条件变量;
- 那个等待"条件被满足"的线程必须调用wait(),可以让线程在条件未被满足时陷入休眠状态,当接收到通知时被唤醒去处理相应的任务;
//cond_var2.cpp用条件变量解决轮询间隔难题 #include <iostream> #include <deque> #include <thread> #include <mutex> #include <condition_variable> std::deque<int> q; //双端队列标准容器全局变量 std::mutex mu; //互斥锁全局变量 std::condition_variable cond; //全局条件变量 //生产者,往队列放入数据 void function_1() { int count = 10; while (count > 0) { std::unique_lock<std::mutex> locker(mu); q.push_front(count); //数据入队锁保护 locker.unlock(); cond.notify_one(); // 向一个等待线程发出“条件已满足”的通知 std::this_thread::sleep_for(std::chrono::seconds(1)); //延时1秒 count--; } } //消费者,从队列提取数据 void function_2() { int data = 0; while (data != 1) { std::unique_lock<std::mutex> locker(mu); while (q.empty()) //判断队列是否为空 cond.wait(locker); // 解锁互斥量并陷入休眠以等待通知被唤醒,被唤醒后加锁以保护共享数据 data = q.back(); q.pop_back(); //数据出队锁保护 locker.unlock(); std::cout << "t2 got a value from t1: " << data << std::endl; } } int main() { std::thread t1(function_1); std::thread t2(function_2); t1.join(); t2.join(); getchar(); return 0; }
上面的代码有四个注意事项:
- 在function_2中,在判断队列是否为空的时候,使用的是while(q.empty()),而不是if(q.empty()),因为wait的唤醒可能由于系统的原因被唤醒,这个的时机是不确定的。这个过程也被称作伪唤醒。如果在错误的时候被唤醒了,执行后面的语句就会错误,所以需要再次判断队列是否为空,如果还是为空,就继续wait()阻塞;
- 在管理互斥锁的时候,使用的是std::unique_lock而不是std::lock_guard,而且事实上也不能使用std::lock_guard。这需要先解释下wait()函数所做的事情,可以看到,在wait()函数之前,使用互斥锁保护了,如果wait的时候什么都没做,岂不是一直持有互斥锁?那生产者也会一直卡住,不能够将数据放入队列中了。所以,wait()函数会先调用互斥锁的unlock()函数,然后再将自己睡眠,在被唤醒后,又会继续持有锁,保护后面的队列操作。lock_guard没有lock和unlock接口,而unique_lock提供了,这就是必须使用unique_lock的原因;
- 使用细粒度锁,尽量减小锁的范围,在notify_one()的时候,不需要处于互斥锁的保护范围内,所以在唤醒条件变量之前可以将锁unlock()。
- cv.notify_one()指的是通知其中某一个线程,cv.notify_all()指的是通知全部线程。
下面给出条件变量支持的操作函数表:

值得注意的是:
- 所有通知(notification)都会被自动同步化,所以并发调用notify_one()和notify_all()不会带来麻烦;
- 所有等待某个条件变量(condition variable)的线程都必须使用相同的mutex,当wait()家族的某个成员被调用时该mutex必须被unique_lock锁定,否则会发生不明确的行为;
- wait()函数会执行“解锁互斥量–>陷入休眠等待–>被通知唤醒–>再次锁定互斥量–>检查条件判断式是否为真”几个步骤,这意味着传给wait函数的判断式总是在锁定情况下被调用的,可以安全的处理受互斥量保护的对象;但在"解锁互斥量–>陷入休眠等待"过程之间产生的通知(notification)会被遗失。
原子操作
一、何为原子操作(atomic)
所谓的原子操作,取的就是“原子是最小的、不可分割的最小个体”的意义,它表示在多个线程访问同一个全局资源的时候,能够确保所有其他的线程都不在同一时间内访问相同的资源。也就是他确保了在同一时刻只有唯一的线程对这个资源进行访问。这有点类似互斥对象对共享资源的访问的保护,但是原子操作更加接近底层,因而效率更高。
在新标准C++11,引入了原子操作的概念,并通过这个新的头文件提供了多种原子操作数据类型,例如,atomic_bool,atomic_int等等,如果我们在多个线程中对这些类型的共享资源进行操作,编译器将保证这些操作都是原子性的,也就是说,确保任意时刻只有一个线程对这个资源进行访问,编译器将保证,多个线程访问这个共享资源的正确性。从而避免了锁的使用,提高了效率。
二、atomic高效体现
使用atomic可以避免使用锁,而且更加底层,比mutex效率更高。为了方便使用,c++11为模版函数提供了别名(即原子类型)。

💛我们先来看一个例子:(加锁不使用atomic)
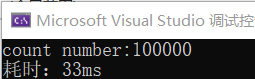
#include <iostream> #include <ctime> #include <mutex> #include <vector> #include <thread> using namespace std; mutex mtx; size_t Count = 0; void threadFun() { for (int i = 0; i < 10000; i++) { // 上锁(防止多个线程同时访问同一资源) unique_lock<mutex> lock(mtx); Count++; } } int main(void) { clock_t start_time = clock(); // 启动多个线程 vector<thread> threads; for (int i = 0; i < 10; i++) threads.push_back(thread(threadFun)); for (auto& thad : threads) thad.join(); // 检测count是否正确 10000*10 = 100000 cout << "count number:" << Count << endl; clock_t end_time = clock(); std::cout << "耗时:" << end_time - start_time << "ms" << std::endl; return 0; }
输出结果:
🧡使用atomic:
#include <iostream> #include <ctime> #include <vector> #include <thread> #include <atomic> using namespace std; atomic<size_t> Count(0);//创建原子类型,将Cout初始化为0 void threadFun() { for (int i = 0; i < 10000; i++) Count++; } int main(void) { clock_t start_time = clock(); // 启动多个线程 vector<thread> threads; for (int i = 0; i < 10; i++) threads.push_back(thread(threadFun)); for (auto& thad : threads) thad.join(); // 检测count是否正确 10000*10 = 100000 cout << "count number:" << Count << endl; clock_t end_time = clock(); cout << "耗时:" << end_time - start_time << "ms" <<endl; return 0; }
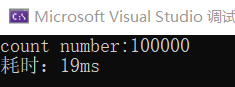
总结:从上面的截图可以发现,第一张图用时33ms,第二张图用时19ms,使用原子操作能提高程序的运行效率。
三,原子操作中的内存访问模型
原子操作保证了对数据的访问只有未开始和已完成两种状态,不会访问到中间状态,但我们访问数据一般是需要特定顺序的,比如想读取写入后的最新数据,原子操作函数是支持控制读写顺序的,即带有一个数据同步内存模型参数std::memory_order,用于对同一时间的读写操作进行排序。C++11定义的6种类型如下:
typedef enum memory_order { memory_order_relaxed, // 不对执行顺序做保证 memory_order_acquire, // 本线程中,所有后续的读操作必须在本条原子操作完成后执行 memory_order_release, // 本线程中,所有之前的写操作完成后才能执行本条原子操作 memory_order_acq_rel, // 同时包含 memory_order_acquire 和 memory_order_release memory_order_consume, // 本线程中,所有后续的有关本原子类型的操作,必须在本条原子操作完成之后执行 memory_order_seq_cst // 全部存取都按顺序执行 } memory_order;
内存访问模型属于比较底层的控制接口,如果对编译原理和CPU指令执行过程不了解的话,容易引入bug。内存模型不是本章重点,这里不再展开介绍,后续的代码都使用默认的顺序一致性模型或比较稳妥的Release-Acquire模型,如果想了解更多,可以参考链接:std::memory_order - cppreference.com
四,使用原子类型实现自旋锁
自旋锁(spinlock)与互斥锁(mutex)类似,在任一时刻最多只能有一个持有者,但如果资源已被占用,互斥锁会让资源申请者进入睡眠状态,而自旋锁不会引起调用者睡眠,会一直循环判断该锁是否成功获取。
自旋锁是专为防止多处理器并发而引入的一种锁,它在内核中大量应用于中断处理等部分。对于多核处理器来说,检测到锁可用与设置锁状态两个动作需要实现为一个原子操作。
标准库还专门提供了一个原子布尔类型std::atomic_flag,不同于所有 std::atomic 的特化,它保证是免锁的,不提供load()与store(val)操作,但提供了test_and_set()与clear()操作:
- test_and_set,如果atomic_flag 对象已经被设置了,就返回True,如果未被设置,就设置之然后返回False(等价于上锁)
- clear,把atomic_flag对象清掉(等价于解锁)
注意这个所谓atomic_flag对象其实就是当前的线程。可用std::atomic_flag实现自旋锁的功能,代码如下:
//atomic2.cpp 使用原子布尔类型实现自旋锁的功能 #include <thread> #include <vector> #include <iostream> #include <atomic> using namespace std; atomic_flag lock = ATOMIC_FLAG_INIT; //初始化原子布尔类型 void f(int n) { for (int cnt = 0; cnt < 10; ++cnt) { while (lock.test_and_set(memory_order_acquire));// 获得锁(自旋) cout << n << " thread Output: " << cnt << '\n'; lock.clear(memory_order_release); // 释放锁 } } int main() { vector<thread> v; //实例化一个元素类型为thread的向量 for (int n = 0; n < 10; ++n) { v.emplace_back(f, n); //以参数(f,n)为初值的元素放到向量末尾,相当于启动新线程f(n) } for (auto& t : v) { //遍历向量v中的元素,基于范围的for循环,auto&自动推导变量类型并引用指针指向的内容 t.join(); //阻塞主线程直至子线程执行完毕 } getchar(); return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号