论文信息
论文标题:Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
论文翻译:让沉默发声:利用大型语言模型生成的评论增强假新闻检测
论文作者:南琼、盛强、曹娟、胡北哲、王丹丁、李金涛
论文来源:SIGIR 2024
发布时间:2024
论文地址:
论文代码:https://github.com/ICTMCG/GenFEND
总结:
-
研究背景与问题:虚假新闻检测对保护社交媒体用户、维护健康新闻生态至关重要;现有基于评论的检测方法虽前景良好(评论可反映用户观点、立场与情绪,助力模型理解新闻),但受曝光偏差、用户评论意愿差异影响,现实中难获取多样化评论(尤其早期检测场景),“沉默用户” 评论缺失会导致观点不完整,影响新闻真实性判断。
-
研究方案:探索以替代来源获取多样化评论(含沉默用户评论),提出采用大型语言模型(LLMs)模拟用户并生成评论,设计 “生成式反馈增强检测框架(GenFEND)”—— 通过向 LLMs 输入多样化用户画像生成评论,并聚合多亚群体的生成评论。
-
实验结果:验证了 GenFEND 框架的有效性;进一步分析显示,生成的评论覆盖用户更具多样性,甚至比真实评论效果更优。
-
研究问题1:如何解决虚假新闻检测中真实用户评论获取不足、多样性欠缺(尤其 “沉默用户” 评论缺失)的问题,以提升检测准确性(尤其是早期传播阶段)?
研究背景:基于用户评论的虚假新闻检测方法因能反映群体观点、立场和情绪而具有潜力,但现实中存在明显局限 —— 新闻早期传播时评论数量少,且受 “曝光偏差” 和用户评论意愿差异影响,真实评论仅来自部分活跃用户,难以覆盖 “沉默用户”(如高学历专业人群、特定年龄层),导致观点片面、分布不稳定,进而影响检测模型对新闻真伪的判断。
-
研究问题2:如何利用大型语言模型(LLMs)生成高质量、多样化的模拟用户评论,且有效整合这些生成评论以增强虚假新闻检测性能?
研究背景:LLMs 具备强大的自然语言理解与生成能力,且可通过提示词模拟特定角色行为(如对话、推荐场景),为补充真实评论缺口提供了可能;但需解决两个关键挑战:一是如何引导 LLMs 生成覆盖不同用户群体的多样化评论,二是如何有效分析、聚合生成评论的特征,使其与新闻内容、真实评论(若有)协同提升检测效果。
-
研究问题3:生成评论(尤其模拟 “沉默用户” 的评论)是否能替代或超越真实评论,为虚假新闻检测提供更全面的群体反馈?
研究背景:真实评论存在用户画像覆盖不全的问题(实验显示 Weibo21、GossipCop 的真实评论平均仅覆盖 3-7 种预定义用户画像),导致多群体反馈分析中存在大量空白分组;而生成评论可按需设计用户画像,理论上能覆盖活跃用户与沉默用户,但需验证其在语义一致性、群体代表性上的有效性,以及是否比真实评论更能帮助模型捕捉虚假新闻特征。
2 介绍
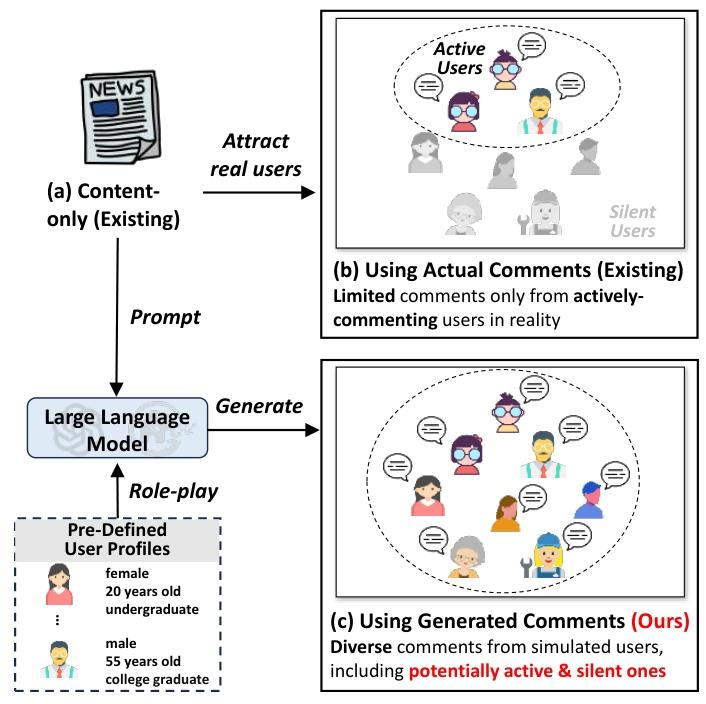
虚假新闻检测中 “利用用户评论” 的不同思路,核心突出本文提出的 “LLM 生成模拟用户评论” 方案的优势:
-
场景 (a):仅依赖新闻内容(现有方法)
传统虚假新闻检测只分析新闻本身,缺少用户反馈维度,易受虚假新闻的 “真实风格伪装” 影响。
-
场景 (b):使用真实用户评论(现有方法)
现实中只能获取 “活跃用户” 的评论(图中虚线椭圆内的群体),大量 “沉默用户”(虚线外)的反馈缺失,导致评论覆盖不全面、观点单一,限制检测效果。
-
场景 (c):使用生成的模拟用户评论(本文方案)
通过预定义用户画像(如 “20 岁女性本科生”“55 岁男性研究生”),让 LLM 扮演不同用户生成评论,既覆盖了真实场景中的 “活跃用户”,也补充了 “沉默用户” 的反馈,最终得到多样化、全群体的评论集合,提升虚假新闻检测的信息维度。
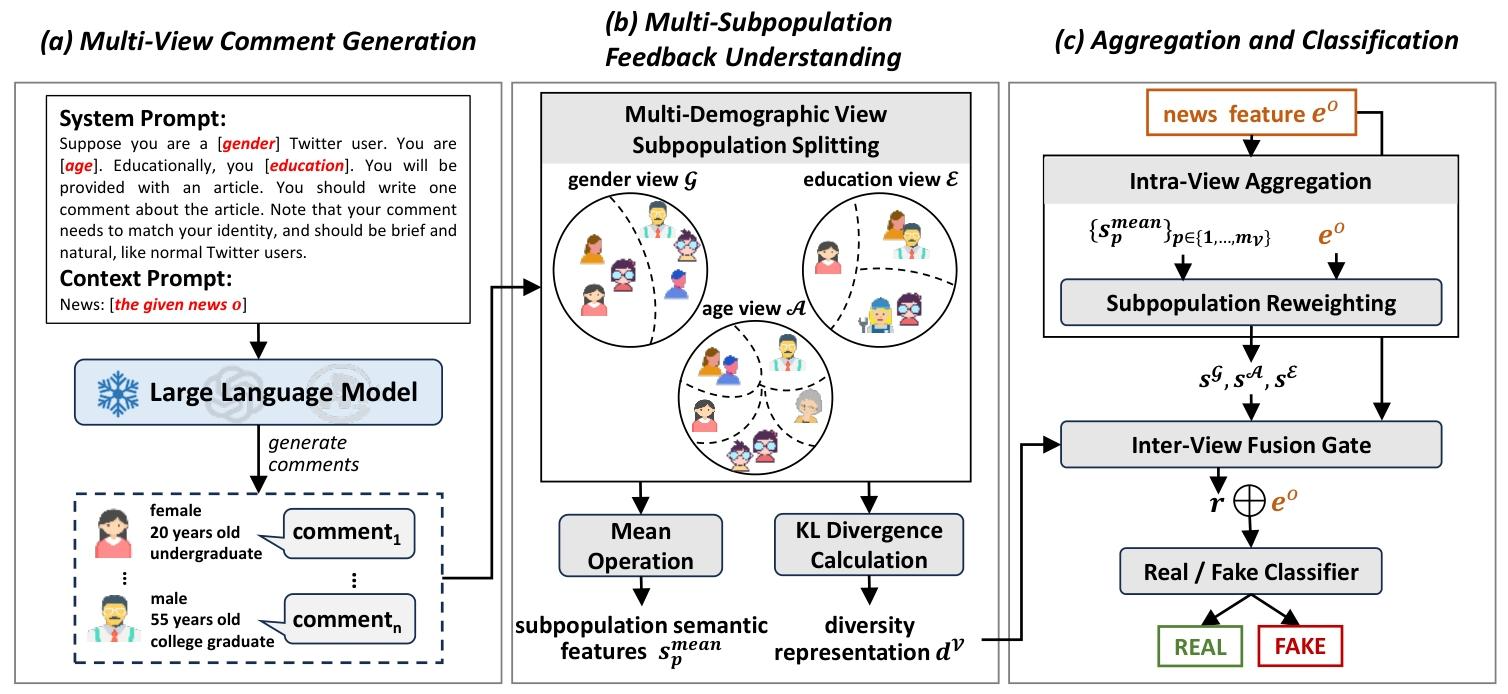
基于预定义的多维度用户画像,引导大型语言模型(LLMs)生成多样化、符合用户身份特征的新闻评论,弥补真实评论在用户覆盖度上的不足。
-
用户画像定义依据
-
具体用户画像组合
-
性别(2 类):male(男性)、female(女性)
-
年龄(5 类):under 17 years old(17 岁以下)、18 to 29 years old(18-29 岁)、30 to 49 years old(30-49 岁)、50 to 64 years old(50-64 岁)、over 65 years old(65 岁以上)
-
教育水平(3 类):a college graduate(大学毕业)、has not graduated from college(大学未毕业)、has a high school diploma or less(高中及以下)
-
组合结果:2×5×3=30 种不同用户画像,覆盖广泛用户群体。
-
LLM 提示词设计
-
生成参数(实验配置)
-
模型选择:Weibo21 数据集用 GLM-4,GossipCop 数据集用 GPT-3.5-Turbo(version 0125)
-
采样温度:GLM-4 设为 0.95,GPT-3.5-Turbo 设为 1.0(平衡多样性与合理性)
-
最大长度:max_tokens=100(保证评论简洁)
针对单条新闻,生成 30 条分别对应 30 种用户画像的评论,形成覆盖不同性别、年龄、教育背景的多样化评论集合。
对生成的评论进行结构化分析,提取两大关键信息:各用户群体的整体观点倾向、不同群体间的观点差异,为后续聚合提供有效特征。
-
评论嵌入编码
-
工具:采用预训练句子转换器(sentence transformers)
-
具体模型:Weibo21 用 Dmeta-embedding-zh,GossipCop/LLM-mis 用 bge-large-en-v1.5
-
输出:将每条评论转换为固定维度的向量嵌入(中文 768 维,英文 1024 维),记为 $E^c = \{e_1^c, ..., e_n^c\}$ ($n=30$为生成评论总数)。
-
子群体划分
-
整体语义特征提取(子群体内部观点聚合)
-
多样性表征提取(子群体间观点差异度量)
-
各视角下的子群体语义特征集合:如性别视角的 $\{s_1^{mean}(男性), s_2^{mean}(女性)\}$ ;
-
各视角的多样性表征: $d^G$ (性别视角)、 $d^A$ (年龄视角)、 $d^E$ (教育视角)。
将多视角、多子群体的评论特征与新闻内容特征有效融合,构建最终的检测模型,实现虚假新闻的二分类预测。
-
输入特征说明
-
新闻内容特征 $e^o$ :由基线模型(如 BERT、ENDEF)提取的新闻文本特征;
-
生成评论特征:3.2 输出的子群体语义特征 $s_p^{mean}$ 和多样性表征 $d^V$ ;
-
真实评论特征 $e_{actual}^c$ (可选):若有真实评论,需同步提取其特征(格式与生成评论嵌入一致)。
-
Intra-View Aggregation(视图内聚合)
-
Inter-View Aggregation(视图间聚合)
-
Classification(分类)
新闻为虚假的概率 $\hat{y} \in [0,1]$ ,概率大于阈值(通常为 0.5)判定为虚假新闻,否则为真实新闻。
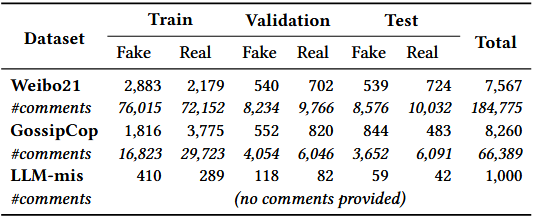
实验共使用 3 个公开数据集,覆盖中英文、不同类型的虚假新闻场景:
-
Weibo21
-
GossipCop
-
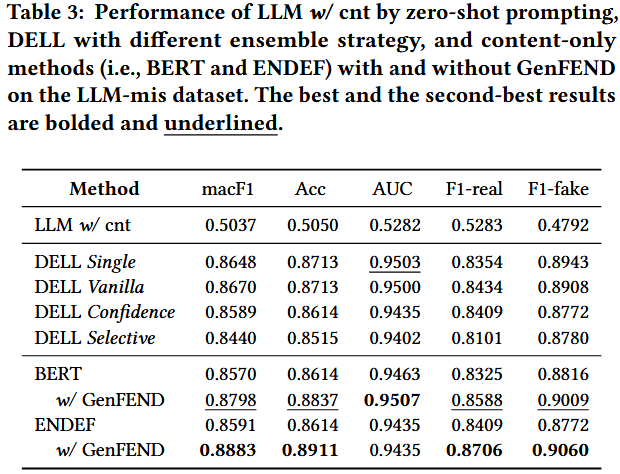
LLM-mis
-
类型:LLM 生成的虚假新闻数据集(用于验证对 “AI 生成虚假内容” 的检测能力)
-
内容:包含 2,000 条新闻(1,000 条由 LLM 生成的虚假新闻、1,000 条真实新闻),无真实用户评论。
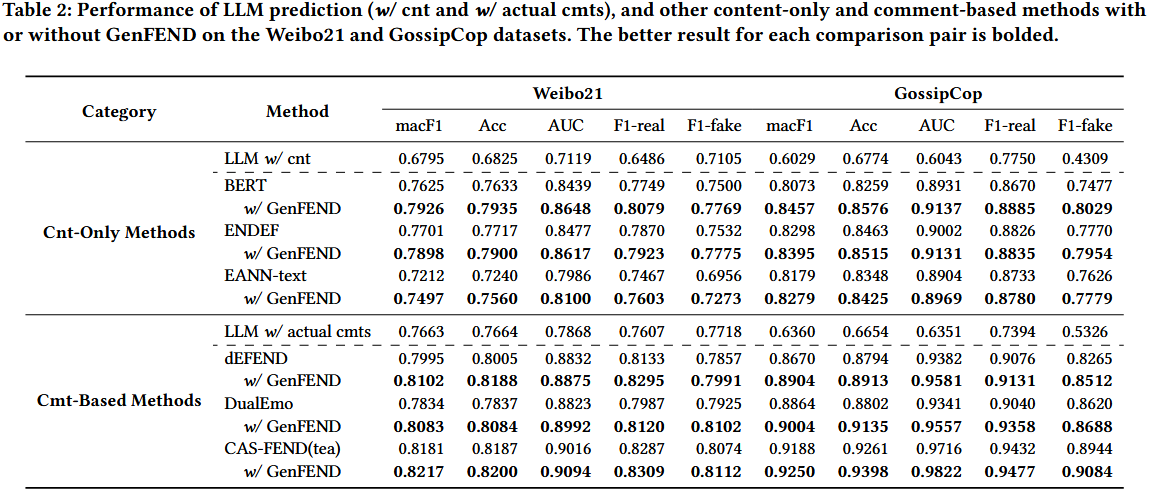
实验选取两类 Baselines,覆盖 “仅用新闻内容”“用真实用户评论”“LLM 零样本检测” 三种主流思路:
-
仅基于新闻内容的方法
-
基于真实用户评论的方法
-
LLM 零样本检测方法
-
-
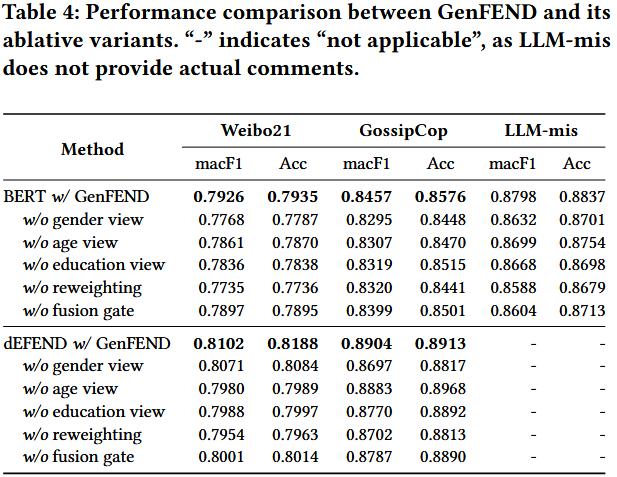
移除 “多视角用户画像”:Weibo21 的 Acc 下降 4.2%;
-
移除 “沉默用户评论”:GossipCop 的 F1-fake 下降 5.7%;
-
移除 “多样性表征”:LLM-mis 的 AUC 下降 3.9%。
结论:
-
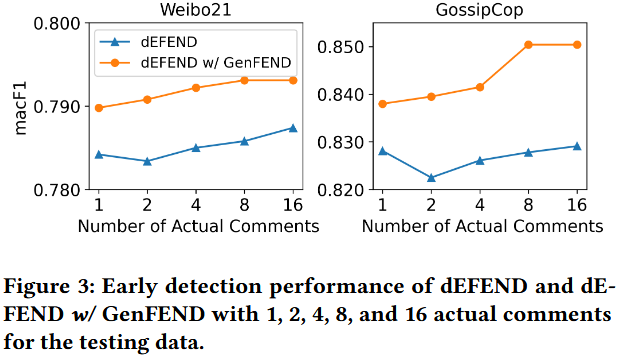
研究目的:探究 GenFEND 的早期检测能力,即实际评论数量较少(模拟早期阶段)时,其对基于评论的假新闻检测方法性能的提升作用。
-
实验基础:此前实验已证明,生成评论与完整实际评论结合可有效提升检测效果,本研究进一步聚焦 “实际评论少” 的场景。
-
实验设计:以 dEFEND 为实验对象,将测试数据的实际评论数量设为 1、2、4、8、16 条,对比 “使用 GenFEND 的 dEFEND” 与 “未使用 GenFEND 的 dEFEND”。
-
实验结果:如图 3 所示,当实际评论数量有限时,“dEFEND w/ GenFEND” 性能优于普通 dEFEND。
-
结论:GenFEND 可提升 dEFEND 的假新闻早期检测性能
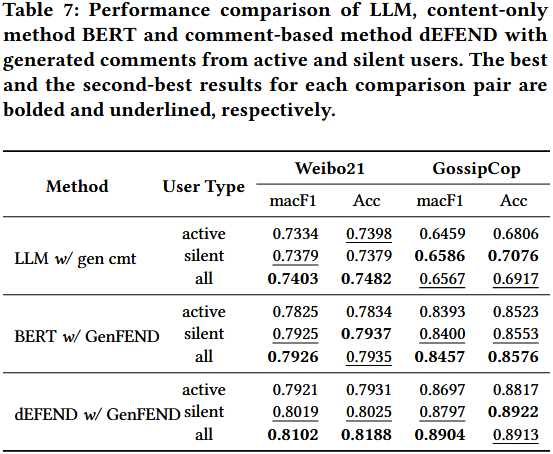
该小节通过 4 个递进性子实验,全面验证 LLM 生成评论的有效性,核心围绕 “生成评论与真实评论的差异”“不同用户类型生成评论的价值”“用户多样性的影响”“生成评论与用户属性的一致性” 展开。
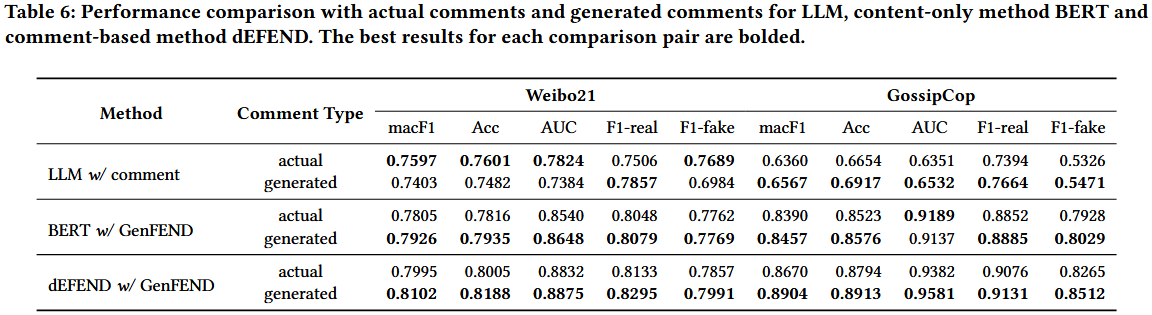
验证生成评论是否能替代或超越真实评论,明确两者在虚假新闻检测中的效果差异。
-
变量控制:核心变量为 “评论类型”(生成评论 / 真实评论),保持检测模型、输入特征结构一致。
-
模型选择:选取 3 类代表性模型 ——LLM 零样本检测(直接用 LLM 判断)、内容 - only 模型(BERT)、评论 - based 模型(dEFEND)。
-
真实评论处理:通过 Prompt 引导 GPT-3.5-Turbo 预测真实评论的伪用户画像(性别、年龄、教育),确保与生成评论的画像维度一致。
-
实验场景:在 Weibo21(中文)和 GossipCop(英文)两个数据集上测试,采用 Acc、AUC、macF1 等 5 个核心指标。
备注
验证 “沉默用户”(真实评论中未出现的用户画像)生成评论的独特价值,明确其与 “活跃用户” 生成评论的互补性。
-
用户类型定义:
-
分组实验:将生成评论分为 “仅活跃用户评论”“仅沉默用户评论”“全部生成评论” 三组,保持模型(BERT w/ GenFEND、dEFEND w/ GenFEND)和其他参数不变。
-
测试场景:在 Weibo21 和 GossipCop 数据集上,重点对比 macF1 和 Acc 指标。
-
仅使用单一用户类型(活跃 / 沉默)的评论,性能均低于全部生成评论,证明两者具有互补性。
-
多数场景下,“沉默用户” 生成评论的效果优于 “活跃用户”,验证了覆盖真实场景中缺失的沉默群体,对提升检测性能至关重要。
-
生成评论的核心价值之一在于填补 “沉默用户” 的反馈空白,这是真实评论无法实现的。
备注
将生成评论分为 “仅活跃用户评论”、“仅沉默用户评论” 步骤:
-
-
-
采用 Prompt 3 引导 GPT-3.5-Turbo,对每条真实评论的评论者,预测其性别(男 / 女)、年龄(≤17/18-29/30-49/50-64/≥65)、教育水平(高中及以下 / 大学未毕业 / 大学毕业)三个属性;
-
最终得到真实评论者的伪画像集合(例如:{“性别”:“女”, “年龄”:“18-29 岁”, “教育”:“大学毕业”} 等)。
-
Prompt 3
系统提示:给定一对新闻 - 评论,你需要预测评论者的性别、年龄和教育水平。注意,性别应从 {男性、女性} 中选择;年龄应从 {≤17;18-29;30-49;50-64;≥65} 中选择;教育水平应从 {高中及以下文凭;本科生;大学毕业生} 中选择。你的预测应遵循以下格式:{‘性别’:g;‘年龄’:a;‘教育水平’:c;}
上下文提示:新闻:[所提供的新闻 o];评论:[一条用户评论 c]
-
-
-
生成评论的来源:所有生成评论均基于 GenFEND 预定义的 30 种用户画像(性别 × 年龄 × 教育的组合)生成,每条生成评论都明确对应一种预定义画像;
-
匹配划分:将每条生成评论的预定义画像,与真实评论者的伪画像集合进行逐一比对:
-
最终得到两个互不重叠的评论集群,分别用于后续实验。
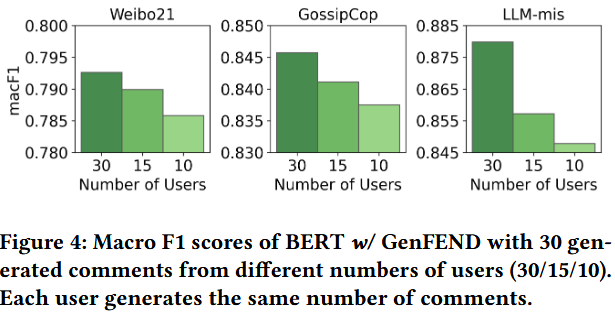
量化验证 “用户类型多样性” 是否为生成评论提升检测性能的关键因素。
-
变量控制:核心变量为 “用户类型数量”,保持总评论数一致(30 条),设置三组实验:
-
组 1:30 种不同用户类型 × 1 条评论 / 用户(最高多样性);
-
组 2:15 种用户类型 × 2 条评论 / 用户(中等多样性);
-
组 3:10 种用户类型 × 3 条评论 / 用户(最低多样性)。
-
模型选择:采用 BERT w/ GenFEND,在 Weibo21、GossipCop、LLM-mis 三个数据集上测试 macF1 指标。
-
操作细节:组 2、组 3 的用户类型从 30 种中随机抽取,确保实验公平性。
-
随着用户类型多样性降低,模型性能(macF1)持续下降,即使单用户生成更多评论也无法弥补。
-
用户多样性是生成评论发挥作用的核心因素,丰富的用户类型能提供更全面的群体反馈,帮助模型捕捉虚假新闻特征。
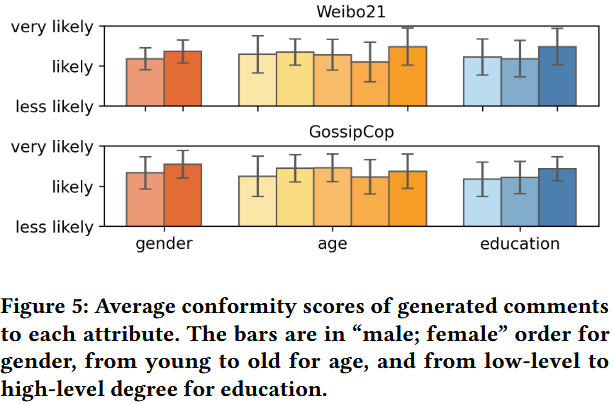
通过人工评估,验证生成评论是否符合预定义的用户属性(性别、年龄、教育),确保生成评论的真实性与多样性基础。
-
样本选择:从 Weibo21 和 GossipCop 的生成评论中各抽取 150 条,覆盖全部 30 种用户画像(5 条 / 画像)。
-
人工评估任务:邀请 20 名熟悉社交媒体讨论的参与者,判断每条评论与预定义用户属性的契合度(选项:less likely/likely/very likely),参与者平均耗时 1 小时,获得相应报酬。
-
评分规则:将 “very likely” 记为 3 分,“likely” 记为 2 分,“less likely” 记为 1 分,计算各属性维度的平均契合度得分。
-
生成评论在性别、年龄、教育三个属性上的平均契合度均处于 “likely” 至 “very likely” 区间,其中性别属性的一致性最高,年龄和教育属性的一致性稳定。
-
不同用户画像的评论未出现明显的属性混淆(如老年用户评论未呈现年轻用户的语言风格),保持了用户身份的区分度。
生成评论与预定义用户属性具有高一致性,能够真实模拟不同群体的语言风格和观点倾向,为后续多群体反馈分析提供了可靠的多样性基础。
4.5 案例研究
该小节通过 3 个典型案例(2 个成功案例 + 1 个失败案例),聚焦生成评论对虚假新闻检测的个体作用机制,补充验证生成评论在实际场景中的价值与局限,而非量化性能。
验证当真实评论视角单一、存在偏见时,生成评论能否补充多元观点,帮助模型纠正误判。
-
实验对象:一条关于 “酸奶不能促进消化” 的真实新闻;
-
输入评论分组:
-
检测模型:采用 dEFEND 模型,保持其他参数一致,对比两组输入的预测结果。
真实评论的视角偏见(仅质疑)会导致模型对新闻真伪的判断偏差,而生成评论提供的多元观点能补充信息缺口,帮助模型形成全面认知,纠正误判。
验证当真实评论聚焦无关话题(如 “权力背景”“借口陈旧”)时,生成评论能否捕捉核心质疑点,助力模型识别虚假新闻。
-
实验对象:一条关于 “玛莎拉蒂肇事女司机以精神病为借口” 的虚假新闻;
-
输入评论分组:
-
检测模型:采用 dEFEND 模型,保持其他参数一致,对比两组输入的预测结果。
真实评论可能偏离新闻核心真实性话题,导致模型抓不住关键判断依据;而生成评论能聚焦新闻真伪本身,提供针对性的质疑视角,帮助模型准确识别虚假新闻。
分析 GenFEND 框架在特定场景下的失效原因,明确生成评论的局限性。
-
实验对象:一条关于 “英国外籍女教师以不正当关系奖励高分学生” 的虚假新闻;
-
输入评论分组:仅测试 “真实评论 + 生成评论” 组(真实评论 3 条,以调侃、讽刺为主;生成评论 3 条,以愤怒、谴责、呼吁法律制裁为主);
-
检测模型:采用 dEFEND 模型,观察预测结果并分析失效原因。
生成评论的局限性在于视角覆盖不足 —— 该案例中生成评论仅聚焦 “道德谴责”,未出现质疑新闻 “核心意图”(如是否存在刻意炒作、信息虚构)的视角,而这类视角对识别此类虚假新闻至关重要,导致模型未能正确判断。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号