SGR——Learning from Shortcut A Shortcut-guided Approach for Graph Rationalization【从捷径中学习:一种基于捷径引导的图合理化方法】
论文信息
论文标题:Learning from Shortcut A Shortcut-guided Approach for Graph Rationalization
论文作者:Linan_Yue , Qi Liu, Ye Liu, Weibo Gao, Chao Song
论文来源:ICLR'2024
发布时间:2024
论文地址:link
论文代码:link
1 研究问题&&研究动机
1.1 研究动机(Research Motivation)
1. 图神经网络的核心价值与痛点
2. 图合理化方法的现状与缺陷
3. 关键发现:捷径特征的易学习性
文献(Arpit et al., 2017; Nam et al., 2020 等)验证:捷径特征比理据特征更易被模型学习—— 模型在训练初期会优先记忆捷径信息以快速拟合训练数据,而非学习输入与标签间的真实因果关系。这一发现为 “主动捕获捷径、并基于捷径区分理据与非理据” 提供了核心依据。
1.2 研究问题(Research Question)
2 捷径引导的图合理化(Hortcut-Guided Graph Rationalization)
2.1 问题定义(Problem Definition)
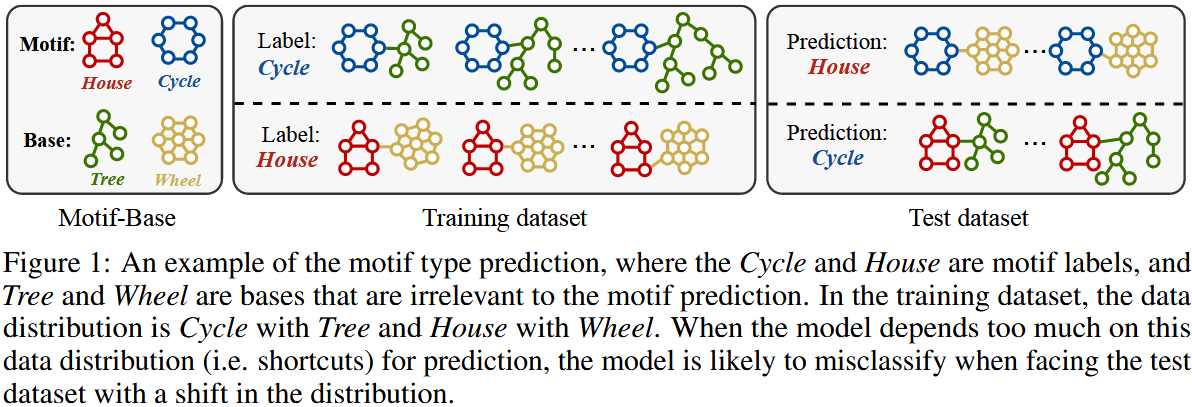
2.2 SGR 架构(Architecture of SGR)
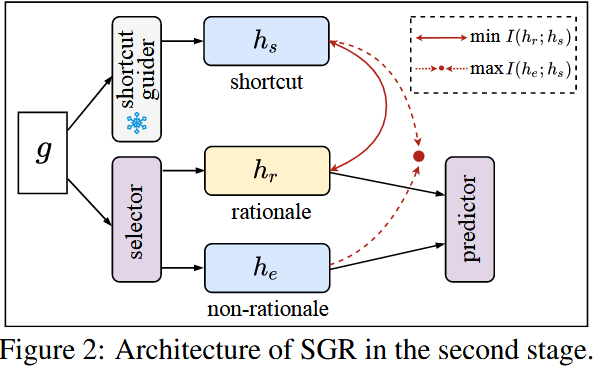
2.2.1 捷径引导器(Shortcut Guider)
2.2.2 选择器(Selector)
2.2.3 基于互信息估计的捷径学习(Learning From Shortcut by MI Estimation)
2.3 训练与推理(Training and Inference)
$\mathcal{L}_{sgr} = \mathcal{L}_r + \mathcal{L}_e + \lambda_{diff}\mathcal{L}_{diff} + \lambda_{shortcut}\mathcal{L}_{shortcut} + \lambda_{sp}\mathcal{L}_{sp}$
3 实验
3.1 数据集(Datasets)
| 数据集类型 | 名称 | 任务场景 | 数据构造与关键设置 | 统计信息(核心指标) |
|---|---|---|---|---|
| 合成数据集 | Spurious-Motif(4 个变体) | Motif 类型预测 | - 每个图含 “motif 子图(理据,如 Cycle/House/Crane)” 和 “base 子图(非理据,如 Tree/Wheel/Ladder)”,标签仅由 motif 决定。
|
- 类别数:3
|
| 真实数据集 | Graph-SST2 | 文本情感分析(图分类) | - 将 SST2 文本转换为图结构,按节点平均度数划分训练 / 测试集(训练集节点度数 > 测试集),构造分布偏移。 | - 类别数:2
|
| 真实数据集 | OGBG(5 个分子数据集) | 分子属性预测 | - 含 MolHIV、MolToxCast、MolBACE、MolBBBP、MolSIDER,默认按 scaffold 拆分数据集(不同拆分的分子结构差异大)。 | - 类别数:2-617(MolToxCast 最多)
|
3.2 对比基线(Baselines)
| 基线类型 | 名称 | 核心特点 | 实现细节 |
|---|---|---|---|
| 经典 GNN(无解释性) | GCN(Kipf & Welling, 2017) | 图卷积网络基础模型,无专门理据提取模块 | 作为基准模型,验证 “图合理化方法” 相对纯预测模型的优势 |
| 经典 GNN(无解释性) | GIN(Xu et al., 2019) | 基于图同构网络,表达能力更强,无专门理据提取模块 | 同上,与 GCN 互补,覆盖不同 GNN 编码器 |
| 图合理化方法(去偏类) | DIR(Wu et al., 2022) | 拆分理据 / 非理据子图,显式将非理据子图作为环境 | 与 SGR 核心思路相近,对比 “显式环境” 与 SGR“捷径引导 + 隐式环境” 的差异 |
| 图合理化方法(去偏类) | DisC(Fan et al., 2022) | 拆分理据 / 非理据,将非理据表征作为环境,选择边作为理据 | 对比 “边理据” 与 SGR “节点理据” 的效果 |
| 图合理化方法(去偏类) | GREA(Liu et al., 2022) | 拆分理据 / 非理据,将非理据表征作为环境,选择节点作为理据 | 与 SGR 理据类型一致,对比 “无捷径引导” 与 “有捷径引导” 的差异 |
| 图合理化方法(去偏类) | CAL(Sui et al., 2022) | 拆分理据 / 非理据,将非理据表征作为环境,选择节点 + 边作为理据 | 对比 “混合理据” 与 SGR “节点理据” 的效果 |
| 图合理化方法(信息瓶颈类) | GSAT(Miao et al., 2022) | 基于信息瓶颈原理,学习稀疏注意力选择理据,不考虑非理据信息 | 验证 “引入非理据 + 捷径信息” 的必要性 |
| 图合理化方法(解纠缠类) | DARE(Yue et al., 2022) | 解纠缠 + MI 最小化提取理据,无专门捷径处理模块 | 对比 “仅 MI 最小化” 与 SGR“MI 双向约束 + 捷径引导” 的差异 |
3.3 实验内容、结果与结论
| 观测维度 | 具体结果 |
|---|---|
| 偏置 / 无偏测试集性能 | - 偏置测试集:GCN/GIN 准确率接近 100%(充分利用捷径); - 无偏测试集:性能显著下降(时准确率仅 35%-38%); - 趋势:越大(捷径越强),偏置测试集性能越高,无偏测试集性能越低。 |
| 训练损失与准确率 | - 偏置数据:训练 2 个 epoch 后损失趋近 0,准确率快速达到高值; - 平衡数据:训练多个 epoch 后损失才收敛,准确率提升缓慢(图 3 (b)(c)、图 8)。 |
| 捷径引导器有效性(MolBACE) | - 训练 1-3 个 epoch:SGR 性能随 epoch 增加而提升(捷径引导器捕获捷径); - 训练 > 3 个 epoch:SGR 性能下降(捷径引导器开始学习理据,偏离目标)。 |
| 数据集类型 | 核心结果 |
|---|---|
| Spurious-Motif(无偏测试集) | - SGR 在所有变体(、Cycle-Tree)中表现最优; - 例如 Cycle-Tree 变体:SGR(GIN backbone)准确率 58.01%,显著高于第二名 DisC(48.82%)。 |
| Graph-SST2 | - SGR(GIN backbone)ACC=83.86%,GCN backbone ACC=83.78%,均优于所有基线(DARE 最高 83.20%)。 |
| OGBG | - 所有 5 个数据集上 SGR 均优于基线; - 代表案例:MolHIV(GIN backbone):SGR ROC-AUC=79.45%,比 GIN(74.47%)提升 4.98%,比 DARE(78.36%)提升 1.09%。 |
| 消融变体 | 性能变化 |
|---|---|
| SGR w/o shortcut | 性能显著下降,与 CAL 等基线接近(验证捷径引导器的核心作用)。 |
| SGR w/o diff | 性能下降(如 MolHIV 下降 0.99%)(验证跨环境稳定性约束的必要性)。 |
| SGR w/o env | 性能优于部分基线,但仍低于原始 SGR(验证 “非理据作为环境” 的有效性)。 |
| 数据集 | 具体结果 |
|---|---|
| Cycle-Tree(House motif 测试例) | - SGR:准确识别 House motif 的核心节点 / 边,未包含 Tree/Wheel 等 base 子图(捷径载体); - 基线(DIR/GSAT/GREA):误将部分 base 子图节点 / 边纳入理据,识别精度较低(图 6)。 |
| Graph-SST2(情感分析) | - 训练集:准确高亮 “quite effective”(正面)、“astonishingly witless”(负面)等情感关键词; - 测试集(OOD):仍能精准识别核心情感词,解释与标签一致(图 9)。 |
3.4 实验总结
相关问题
Q1:本文是如何验证 训练少量 epoch 的 $G_s$ 学习到的是捷径特征?
-
-
验证思路:若$G_s$ 学到的是捷径,则它会呈现 “同分布准、OOD 差” 的恶性偏置行为;若学到的是理据,则会呈现 “跨分布稳定” 的泛化行为。
-
Q2:若数据中捷径特征与理据特征难以通过 “早停策略” 分离(如部分捷径特征学习难度接近理据特征),SGR 的捷径引导器$G_s$会捕获混杂信息,此时该如何调整$G_s$的训练策略(如早停 epoch 数、损失函数)以保证$h_s$的 “纯净捷径属性”?
Q3:在第二阶段优化中,$\mathcal{L}_{shortcut}$(互信息双向约束)与$\mathcal{L}_{sp}$(理据稀疏性约束)可能存在冲突(如过度追求稀疏性导致理据丢失关键信息,或过度剔除捷径导致理据不完整),该如何平衡两者的权重参数或优化逻辑?
Q4:当数据集无显式捷径标注(如多数真实场景),且不同样本的捷径强度差异较大时,SGR 如何自适应调整$G_s$的早停时机与$\mathcal{L}_{shortcut}$的约束强度,确保对不同样本的捷径捕获与理据分离效果一致?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号