Collaborative Evolution: Multi-Round Learning Between Large and Small Language Models for Emergent Fake News Detection
摘要
-
研究背景与问题:社交媒体平台上虚假新闻泛滥,对社会产生显著负面影响;传统基于小型语言模型(SLMs)的深度学习方法需大量监督训练,且难以适应快速变化的环境;大型语言模型(LLMs)虽具备强大零样本能力,但因缺乏相关演示及知识的动态性,无法有效识别虚假新闻。
-
提出的解决方案:构建新型框架 “多轮协作检测(MRCD)”,整合 LLMs 的泛化能力与 SLMs 的专业功能,以兼具两者优势。
-
框架关键设计:
-
包含两阶段检索模块,可筛选相关且最新的演示与知识,强化上下文学习,助力更好地检测新兴新闻事件。
-
设计多轮学习机制,保障检测结果更可靠。
-
-
实验成果:MRCD 在真实世界数据集 Pheme 和 Twitter16 上取得最优(SOTA)结果,相较于仅使用 SLMs,准确率分别提升 7.4% 和 12.8%,有效解决了现有模型的局限性,提升了新兴虚假新闻的检测效果。
方法
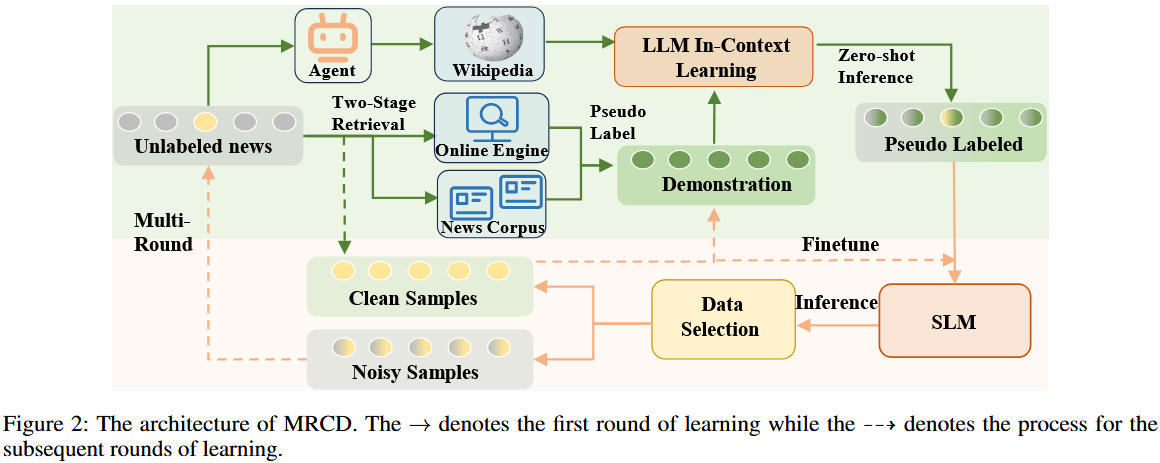
一、小节核心目标
提出多轮协作检测(MRCD)框架,通过LLM 与 SLM 的协同学习、两阶段检索补充信息、数据筛选与多轮迭代优化,解决新兴假新闻检测中 “无标注数据”“分布偏移”“模型泛化不足” 的问题,实现对新兴新闻真实性的精准判断。
二、各子模块详细笔记
一)Two-Stage Retrieval Module(两阶段检索模块)
1. 核心定位
为 LLM 提供 “与新兴新闻强相关的演示样本” 和 “实时事实知识”,弥补 LLM 在零样本场景下 “演示缺失” 和 “知识过时” 的短板,为后续上下文学习和判断提供支撑。
2. Demonstration Retrieval(演示样本检索)
-
传统方法痛点:传统演示样本多从标注训练集中选取,但新兴新闻与历史标注数据分布差异大,导致 LLM 上下文学习效果差;且 LLM 依赖标注演示样本,无标注数据直接使用会降低检测能力,简单赋予 “真实 / 虚假” 标签易引发 “复制效应”(模型模仿标签表面特征而非理解内容真实性)。
-
检索策略:
-
数据源:双来源互补 —— 在线搜索引擎(如必应新闻 API)+ 新闻语料库,避免单一来源导致的数据局限性,确保数据时效性和多样性。
- 筛选算法:采用 BM25 算法,从搜索引擎检索结果($N_w$)和新闻语料库检索结果($N_c$)中,提取与待检测新闻($x$)语义、结构最相似的 Top-K 数据作为候选演示样本($N_k$),公式为 $N_{k}=BM25_{top-k}(x,N_{w}\cup N_{c})$。
-
-
伪标签设计:
-
策略:不直接使用 “real/fake”,而是采用 “语义同义词标签”(如 “reliable/unreliable”“convincing/incredible”),既保持标签语义关联性,又避免 LLM 机械复制标签。
- 演示集构建:为每个候选演示样本($x_i \in N_k$)随机分配同义词伪标签($\hat{y}_i \in \hat{\mathcal{Y}}$),形成最终演示集 $\mathcal{D}=\left\{\left(x_{1}, \hat{y}_{1}\right),\left(x_{2}, \hat{y}_{2}\right), ...,\left(x_{k}, \hat{y}_{k}\right)\right\}$。
-
-
设计目的:确保演示样本与待检测新兴新闻语义一致,同时激活 LLM 对内容的深度理解,而非单纯依赖标签准确性。
3. Knowledge Retrieval(知识检索)
-
核心需求:LLM 参数固定,缺乏新兴新闻相关的动态事实知识,需补充外部知识以辅助理解新闻背景和实体信息。
-
检索流程:
-
实体提取:用 LLM 作为代理,从待检测新闻中提取关键实体(${k_{1}, k_{2}, ..., k_{n}}$)。
-
知识获取:通过维基百科 API 检索关键实体对应的最新事实信息($K={(k_{1}, i_{1}),(k_{2}, i_{2}), ...,(k_{n}, i_{n})}$)。
-
-
输入形式:将检索到的事实知识与新闻内容、演示集拼接后输入 LLM,为 LLM 提供实时、准确的外部知识支撑。
二)Data Selection Module(数据选择模块)
1. 核心功能
对 LLM 和 SLM 的预测结果进行筛选,区分 “高质量干净数据” 和 “低质量噪声数据”,为后续多轮学习提供可靠的训练和演示资源。
2. 筛选流程
-
第一步:双模型预测:
-
LLM 基于演示集($D$)和知识($K$)进行上下文学习,输出预测标签($\hat{y}_1$),公式为 $\hat{y}_1 = \underset{\tilde{y}_1 \in \mathcal{Y}}{\operatorname{argmax}} P(\tilde{y}_1 | \mathcal{D}, \mathcal{K}, x)$;
-
初始化的 SLM 直接对新闻内容($x$)预测,输出标签($\hat{y}_2$)和预测概率($p(\hat{y}_2)$)。
-
-
第二步:数据划分规则(基于置信度和标签一致性):
-
干净数据池(Dclean):满足 “$\hat{y}_1=\hat{y}_2$ 且 $p(\hat{y}_2)≥ω$”($ω$ 为置信度阈值,实验设为 0.8),即双模型预测一致且 SLM 置信度达标,可作为可靠样本。
-
噪声数据池(Dnoisy):满足 “$\hat{y}_1 \neq \hat{y}_2 \text{ or } p(\hat{y}_2) < \omega$”,即预测不一致或置信度不足,需后续迭代优化。
-
-
设计依据:借鉴半监督学习中 “高置信度伪标签可视为真实标签” 的思路,同时结合双模型交叉验证,提升数据质量。
三)Multi-Round Learning(多轮学习模块)
1. 核心逻辑
通过多轮迭代,动态优化模型性能和数据质量,让 LLM 和 SLM 持续适配新兴新闻特征,逐步将噪声数据转化为干净数据。
2. 迭代流程(对应 Algorithm 1)
-
第 1 轮(初始轮):
-
从外部来源(搜索引擎 + 新闻语料库)获取演示集($\mathcal{D}$),通过知识检索获取($\mathcal{K}$)。
-
LLM 和 SLM 分别预测,划分 $D_{clean}$ 和 $D_{noisy}$,轮次 + 1。
-
-
第 2~N 轮(迭代轮):
-
演示集更新:不再依赖外部来源,而是从 $D_{clean}$ 中通过 BM25 算法提取 Top-K 样本作为新演示集
-
$N_{k}'=BM 25_{top-k }\left(x, D_{clean }\right)$)
-
-
SLM 微调:用 $D_{clean}$ 对 SLM 进行微调,提升其对新兴新闻的检测能力。
-
噪声数据重评:对 $D_{noisy}$ 重新进行 LLM+SLM 预测,按规则更新 $D_{clean}$ 和 $D_{noisy}$($D_{clean }^{new }=\{ (x_{i},y_{i})|x_{i}\in D_{noisy } and p\left(\hat {y_{2}}\right)>\omega \} \cup D_{clean }$),轮次 + 1。
-
-
终止条件:达到轮次阈值($N_{th}$,实验设为 3 轮),剩余 $D_{noisy}$ 由微调后的 SLM 直接预测,作为最终标签。
3. 关键设计目的
- 避免过度迭代:轮次过多会导致噪声数据混入 $D_{clean}$,污染训练样本,因此设置轮次阈值。
- 双向优化:$D_{clean}$ 为 LLM 提供更相关的演示样本,为 SLM 提供高质量训练数据;模型性能提升后又能更精准地筛选数据,形成正向循环。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号