论文信息
论文标题:What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning
论文作者:刘威、曾伟豪、何可庆、江勇、何俊贤
论文来源:ICLR 2024
论文地址:link
论文代码:link
Abstract
围绕指令微调(Instruction tuning)展开,核心是探索大语言模型对齐过程中的自动数据选择策略,具体总结如下:
-
背景:指令微调是预训练后让大语言模型适应终端任务和用户偏好的标准技术,研究表明数据工程至关重要,合适的数据只需少量就能实现优异性能,但目前仍缺乏对优质指令微调数据的原则性理解,以及自动高效选择数据的方法。
-
研究内容:
- 深入研究对齐任务的自动数据选择策略,从复杂度、质量、多样性三个维度通过对照研究衡量数据,在此过程中检验现有方法并引入增强数据测量的新技术。
- 提出基于上述测量结果的简单数据样本选择策略。
-
成果:
- 推出 deita(Data-Efficient Instruction Tuning for Alignment 的缩写)系列模型,该系列基于 LLaMA 和 Mistral 模型微调,使用通过所提方法自动选择的数据样本。
- 实证显示,deita 仅用 6K SFT 训练数据样本,性能就优于或与最先进的开源对齐模型相当,数据量比基线模型少 10 倍以上。
- 进一步通过直接偏好优化(DPO)训练后,使用 6K SFT 和 10K DPO 样本的 deita-Mistral-7B + DPO 在 MT-Bench 上得 7.55 分,在 AlpacaEval 上得 90.06%。
-
意义与展望:期望这项工作能提供自动数据选择工具,助力高效的数据对齐,同时发布模型和所选数据集,以便未来研究能更高效地对齐模型。
1 Introduction
指令微调中 “优质数据” 的特征
- 评估维度与假设:从复杂度、质量、多样性三个关键维度定量评估数据样本,假设高效数据集需兼具这三者。
- 评估方法:
- 考察多种数据测量基线并提出新指标,与指令微调后的对齐性能相关性更强。
- 借鉴相关研究,引入 EVOL COMPLEXITY(演化复杂度) 和 EVOL QUALITY(演化质量),通过演化单数据点生成复杂度或质量各异的样本,经 ChatGPT 排序打分后训练预测模型,实现更精细的数据测量;结合基于模型嵌入距离的多样性指标,设计从大数据池中筛选高效数据的简单策略。
- 模型与实验:
- 提出 DEITA 模型家族,基于 LLaMA 和 Mistral 微调,以最大化数据效率。
- 实验显示,DEITA 在 MT - bench、AlpacaEval 和 Open LLM Leaderboard 上表现优于或持平于 Zephyr、Vicuna 等先进模型,且自动筛选的数据样本量少 10 倍以上(如 DEITA - Mistral - 7B 仅用 6K 样本训练,MT - bench 达 7.22,AlpacaEval 达 80.78%;结合 DPO 后,用 6K SFT 和 10K DPO 样本训练,MT - Bench 达 7.55,AlpacaEval 达 90.06%)。
- 成果释放:发布 DEITA 模型检查点及轻量高效的 SFT 数据集,为未来对齐研究提供便利。
2 Methodology
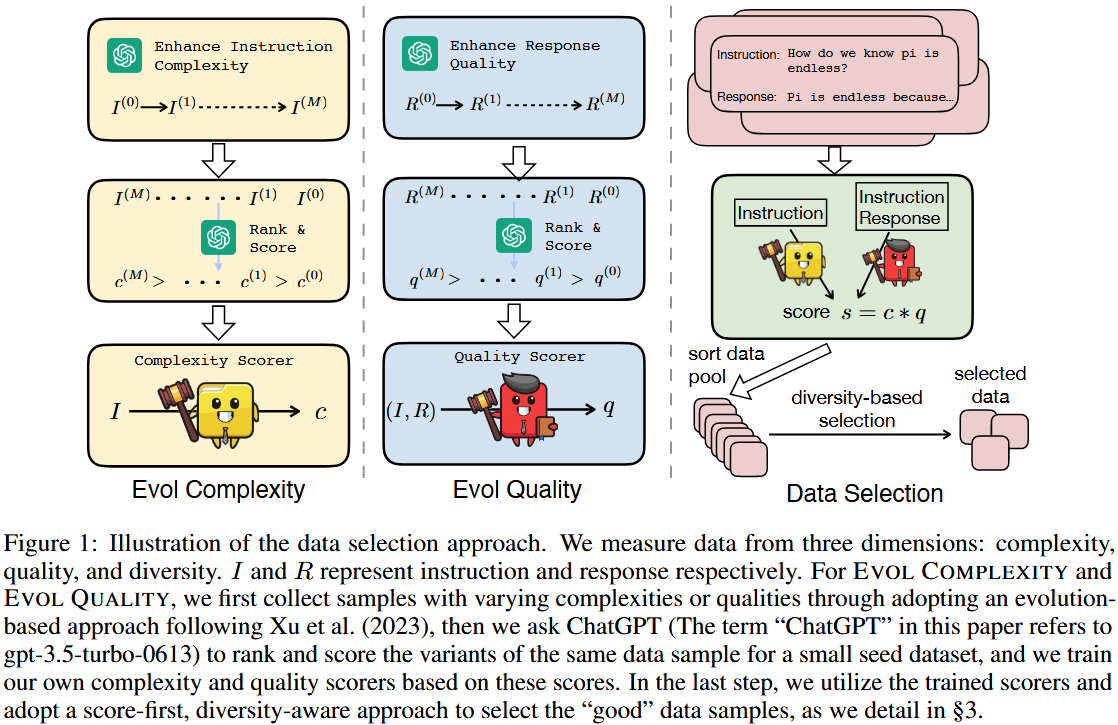
- 复杂度提升(Evol Complexity):通过对指令进行多轮进化 $(I^{(0)}→I^{(1)}……→I^{(M)})$,然后对不同复杂度的指令变体进行排序和评分$(c^{(M)}>……>c^{(1)}>c^{(0)})$,从而训练出复杂度评分器(Complexity Scorer),用于对指令 $I$ 进行复杂度评分 $c$;
- 质量提升(Evol Quality):类似地,对响应进行多轮进化 $(R^{(0)}→R^{(1)}……→R^{(M)})$,再对不同质量的响应变体进行排序和评分 $(q^{(M)}>……>q^{(1)}>q^{(0)})$,训练出质量评分器(Quality Scorer),对指令和响应对 $(I,R)$ 进行质量评分 $q$;
- 数据选择(Data Selection):首先计算每个数据样本的综合得分 $s = c * q$,然后对数据池(sort data pool)中的数据进行基于多样性的选择(diversity-based selection),最终得到所选数据(selected data);
Evol Complexity
-
核心灵感:受 Evol-Instruct(利用 ChatGPT 进化示例以提升复杂度)启发,提出基于进化的复杂度度量方法 EVOL COMPLEXITY。
-
数据基础:收集小规模种子数据集 $D = \{(I_{1}^{(0)}, R_{1}^{(0)}), \cdots, (I_{N}^{(0)}, R_{N}^{(0)})\}$,包含 $N$ 个指令 - 响应对 。
-
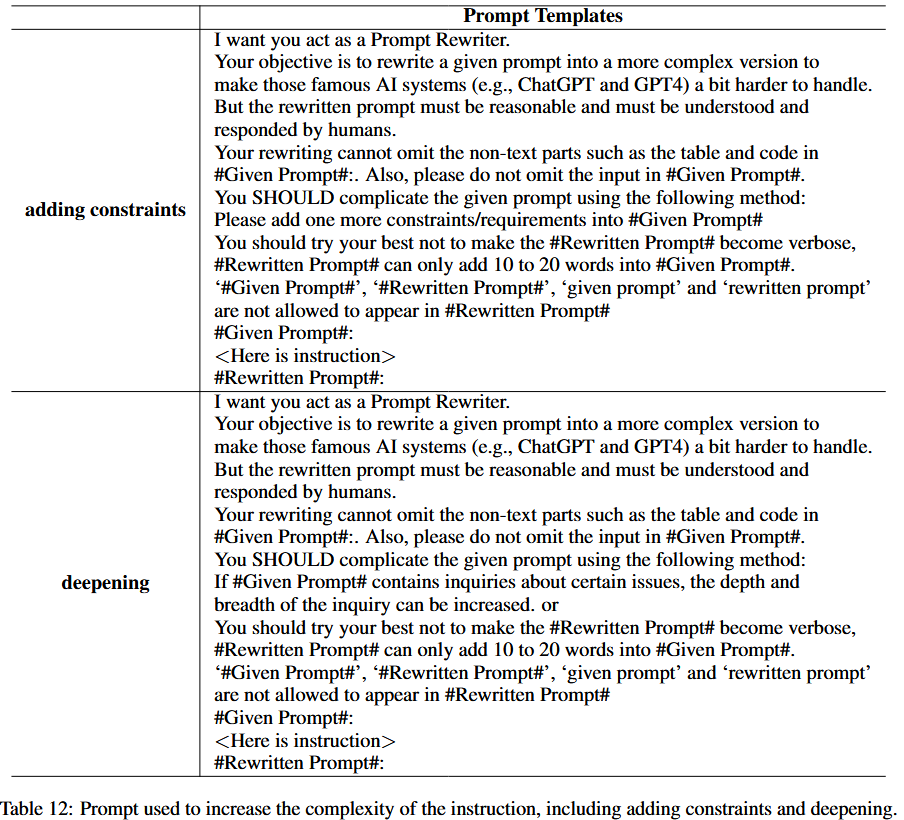
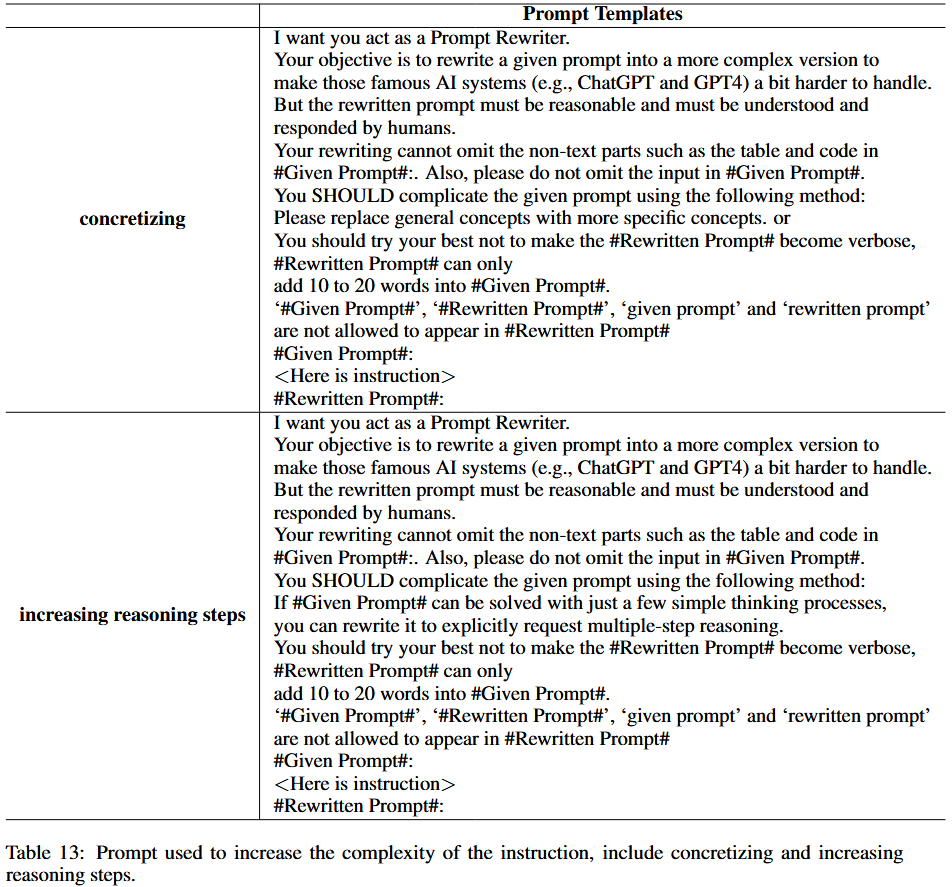
复杂度增强:对每个初始指令对 $(I_{k}^{(0)}, R_{k}^{(0)})$ 中的指令 $I_{k}^{(0)} $ ,采用 Xu 等人(2023)的深度进化提示(附录 E.2),通过添加约束、深化内容、具体化细节、增加推理步骤等方式提升复杂度;经 $M=5$ 次迭代,得到同一指令的 $k=6$ 个不同复杂度变体 $\{I_{k}^{(0)}, \cdots, I_{k}^{(M)}\} $。
-
评分方式:让 ChatGPT 对这 6 个变体进行排序和评分(提示见附录 E.2),获取对应指令的复杂度分数 $c$;与直接评分不同,会在一个提示中提供所有 6 个样本。
复杂度增强的提示模板
EVOL QUALITY
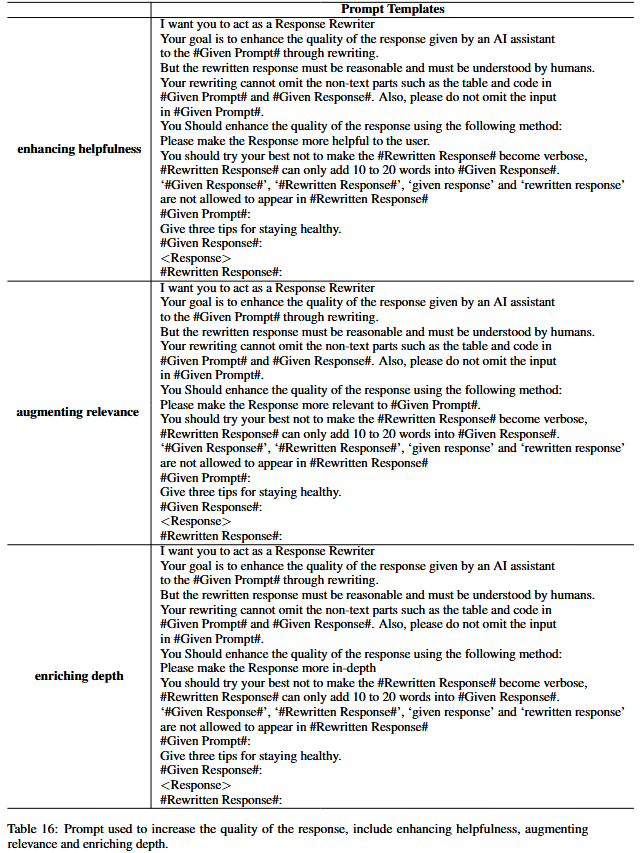
具体来说,对于给定的数据样本 $(I_{k}^{(0)}, R_{k}^{(0)})$,会通过提示ChatGPT以一种进化的方式提升响应 $R_{k}^{(0)}$ 的质量,提升方向主要包括增强有用性、相关性、深度、创造性以及提供更多细节等方面。经过M次迭代(这里M设为5),对于同一个指令 $I_{k}^{(0)}$,会得到一系列不同质量的响应 $\{R_{k}^{(0)}, \cdots, R_{k}^{(M)}\}$。这种方法与之前提到的“EVOL COMPLEXITY”类似,都是借助ChatGPT的能力来生成不同特征的变体,进而用于后续的评分器训练等相关任务。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号