论文信息
论文标题:Rethinking the Instruction Quality: LIFT is What You Need
论文作者:徐扬、姚永强、黄煜凡、祁梦楠、王茂泉、顾斌、尼尔·桑达雷桑
论文来源:arXiv 2023
论文地址:link
论文代码:link
Abstract
- 指令微调依赖数据质量,现有质量改进方法存在缺陷 —— 扩展方法有数据冗余风险,可能损害模型性能;整理方法将模型潜力限制在原始数据集内。
- 为在规避这些缺点的同时超越原始数据质量,提出了 LIFT(大语言模型指令融合迁移)这一新颖通用的范式。
- LIFT 通过策略性拓宽数据分布以涵盖更多高质量子空间,并消除冗余、专注于整体数据子空间中的高质量部分来提升指令质量。
- 实验表明,即便使用 LIFT 选择的有限高质量指令数据,大语言模型仍能在各类任务中保持强劲性能,且超越部分最先进结果,凸显了该范式在指令质量上的显著提升。
1 Introduction
研究人员因关注指令数据集质量,探索出两类提升方法,核心均为数据分布迁移:
- 数据扩展:借助 GPT - 4 等先进大语言模型及合适提示模板,基于原始数据集生成新指令及对应答案,可拓宽数据分布覆盖的子空间,且通常质量更高。
- 数据筛选:依据特定质量评估标准,从原始数据集中精心挑选高质量数据,能使数据分布集中于原始数据集的高质量子集。
当前数据扩展和筛选方法存在局限:扩展易引入冗余,筛选效果依赖原始数据质量,且两者均需特定策略,泛化能力弱。
为此,本文提出新型范式 LIFT(LLM 指令融合迁移),融合扩展与筛选优势:先通过 “数据集分布扩展” 拓宽分布以覆盖更多高质量子空间,再经 “数据集多样性与质量筛选” 消除冗余、聚焦高质量区域,生成少而精的优质多样数据集。
实验表明,基于 LIFT 筛选的少量高质量指令微调开源 LLM,在 NLU 和代码生成任务中表现优异,甚至超过更大数据集训练的模型。
主要贡献:
- 提出高效通用的 LIFT 范式,通过数据分布迁移提升指令数据集质量,克服现有方法的冗余和质量局限。
- 在扩展和筛选阶段均注重多样性与质量,而非仅关注单一阶段。
- 实验证明,LIFT 筛选的少量高质量数据能让 LLM 在多任务中达近 SOTA 或 SOTA 性能,更高效经济。
2 LLM Instruction Fusion Transfer
2.1.1 现有方法分析
- 核心假设:指令质量提升过程中存在数据分布迁移,即从原始数据集向增强后数据集迁移,以增加高质量数据的数量或占比。
- 方法机制:
- 数据扩展:基于原始指令生成高质量指令,扩展原始分布中高质量数据子空间的覆盖范围,增加高质量数据量。
- 数据筛选:通过质量评估指标移除低质量数据,使分布聚焦于高质量数据,提高其占比。
- 方法局限:
- 扩展方法易因原始指令周边存在相似内容,导致最终分布冗余;且低质量指令及其衍生内容仍保留,占比与原始数据集相近。
- 筛选方法从原始数据集中挑选高质量指令,导致高质量指令总数减少;若原始数据集高质量指令少,筛选后数据集质量会大幅下降。
2.1.2 融合扩展与筛选
分析扩展与筛选的数据分布迁移模式后,提出二者融合可有效解决各自局限:扩展拓宽子空间,让筛选能探索原始分布外内容;筛选则从扩展结果中识别重复与低质量数据,使分布更集中精炼。
基于此,提出 LIFT 范式,含两阶段:
- 数据集分布扩展:拓宽分布以覆盖更多多样且高质量的子空间(允许存在重复)。
- 数据集多样性与质量筛选:系统消除冗余和低质量元素,形成密集的最终数据集分布。
两阶段紧密关联,确保数据从原始到最终数据集的平滑迁移。
3 Methodology
- 目标:纳入更多样、高质量的数据,且与原始指令保持一定距离。
- 方法:借鉴 Xu 等人的指令重写方法,设计特定生成规则,引导 GPT-4 作为提示重写器生成多样、复杂的指令。
- 细节:针对指令数据集中自然语言理解(NLU)和代码生成任务的内容差异,为 GPT 提示配置不同设置以提升复杂性(详见附录 A)。
- 流程:迭代 $k$ 轮后,将扩展数据集与原始数据集合并,形成最终扩展数据集。
- 核心目标:剔除原始数据集中重复或低质量指令,保留具有代表性的高质量指令,同时注重多样性与质量。
- 现有多样性筛选方法的局限:常用 k-means、谱聚类等聚类方法,需预先确定聚类数量,过大或过小均会影响代表性选取效果,通用性较差。
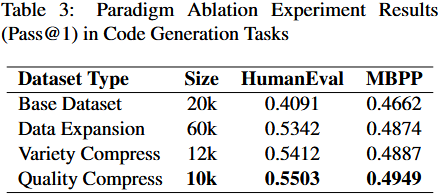
- 本文多样性筛选方法:
- 先用 GPT 生成 1536 维嵌入,再通过协方差矩阵特征值分解降维,选取对应最大 $k$ 个特征值的特征向量。
- 计算降维后特征的行方差(衡量数据在降维空间的差异性),选择行方差前 20%【避免同质化,增加多样性】 的样本构建多样性数据集,无需数据集先验统计知识,适用于各类任务。
- 行方差越大,说明该样本在关键维度上的分布越偏离 “平均水平”,包含的独特信息越多,与其他样本的差异越显著。
- 行方差越小,说明样本更接近数据的 “中心趋势”,特征更平庸,独特性较低。
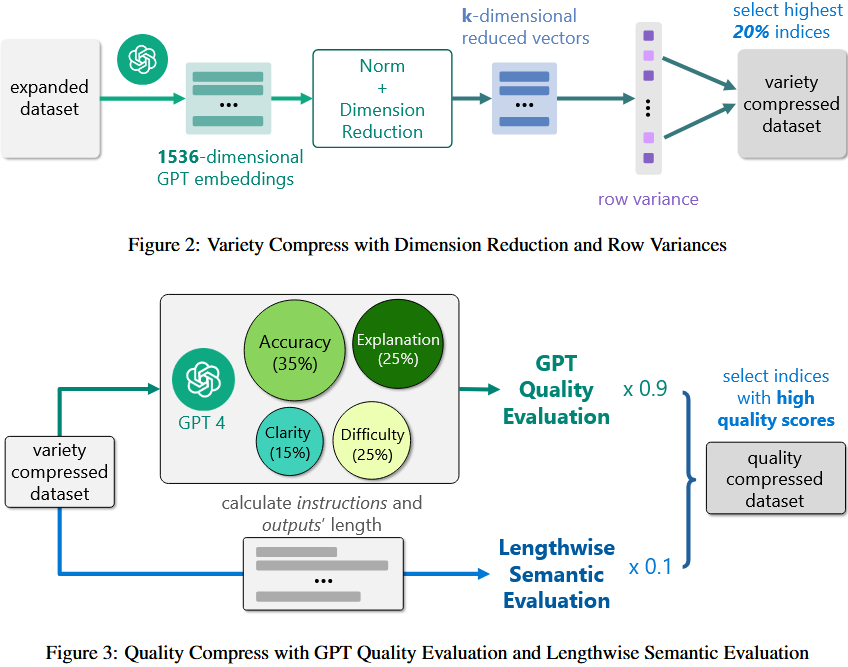
- 质量筛选方法:
- 采用 GPT-4 作为评分器,从准确性、解释性、清晰度、难度 4 个维度评分(权重基于对质量的贡献),并结合指令长度(通过映射函数生成长度语义分)得到最终质量分。
- 为解决 GPT-4 评分趋高问题,要求其提供详细评分理由,并给出低、中、高质量的人工标注示例作为参考,确保分数差异化。
- 选取高质量分的指令组成最终质量筛选数据集,分数分布具有显著区分度。
GPT-4 分数模板
系统消息:
我们想征求您对 AI 助手性能的反馈。助手提供指令和输入(如果有)的输出。
用户提示:
请根据以下标准对指令和输入的响应进行评分。最高分为100分,由4个部分组成:
1.清晰度(15分):根据指令传达问题的有效程度分配分数。高质量、清晰的问题得分更高。
2. 难度(25 分):对指令问题的复杂程度进行评分。难度越高,分数越高。
3. 解释(25 分):评估回复是否包含详细解释以及提供的任何代码。解释越全面,分数越高。
4. 准确性(35 分):根据指令问题解决方案的准确性和正确性对响应进行评分。更高的准确度应该获得更高的分数。
以下是您可以遵循的一些示例和建议:
### 示例 1:
### 指令: {EXAMPLE INSTRUCTION 1}
### 响应: {EXAMPLE OUTPUT 1}
### 示例 1 的分数: {SCORE 1}
### 示例 2:
### 指令: {EXAMPLE INSTRUCTION 2}
### 输入: {EXAMPLE INPUT 2}
### 响应: {EXAMPLE OUTPUT 2}
### 示例 2 的分数: {SCORE 2}
### 示例 3:
### 指令: {EXAMPLE INSTRUCTION 3}
### 响应: {EXAMPLE OUTPUT 3}
### 示例 3 的分数: {SCORE 3}
3 Experiments
NLU Tasks
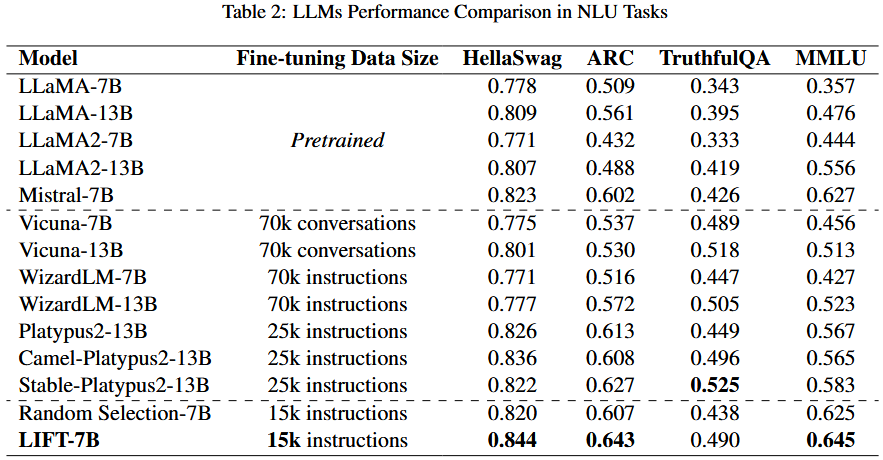
不同数量的数据的实验结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号