论文信息
论文标题:Diversity-oriented Data Augmentation with Large Language Models
论文作者:王在田、张靖晗、张新皓、刘鲲鹏、王鹏飞、周元春
论文来源:ACL 2025
论文地址:link
论文代码:link
Abstract
- 背景与问题:数据增强对提升 NLP 模型的鲁棒性和泛化能力很重要,但现有方法多关注增加样本数量,对样本分布多样性关注不足,可能导致模型过拟合。
- 提出的方案:探究数据增强对数据集多样性的影响后,提出面向多样性的数据增强框架(DoAug)。具体是采用面向多样性的微调方法,将大语言模型训练成多样化释义生成器,再将其应用于选定的信息丰富的样本核心集,将生成的释义与原始数据整合,形成更具多样性的增强数据集。
- 实验结果:在 12 个真实世界文本数据集上的实验显示,微调后的大语言模型增强器在保持标签一致性的同时提高了多样性,增强了下游任务的鲁棒性和性能,平均实现 10.52% 的性能提升,比亚军基线高出三个多百分点。
1 Introduction
训练 NLP 模型的高质量数据集需具备三点:
-
- 规模大:足够样本反映人类语言的多样性和复杂性,助力避免过拟合,提升模型对未见过数据的泛化能力、稳健性和可靠性。
- 一致性:数据与标签的映射准确且一致,为模型提供可靠学习信息,保障任务结果的可重复性和模型预测的可解释性;不一致的数据集会干扰模型,降低其性能。
- 多样性:确保 NLP 模型学习广泛的语言模式(原文未完成此点阐述)。
2 Framework
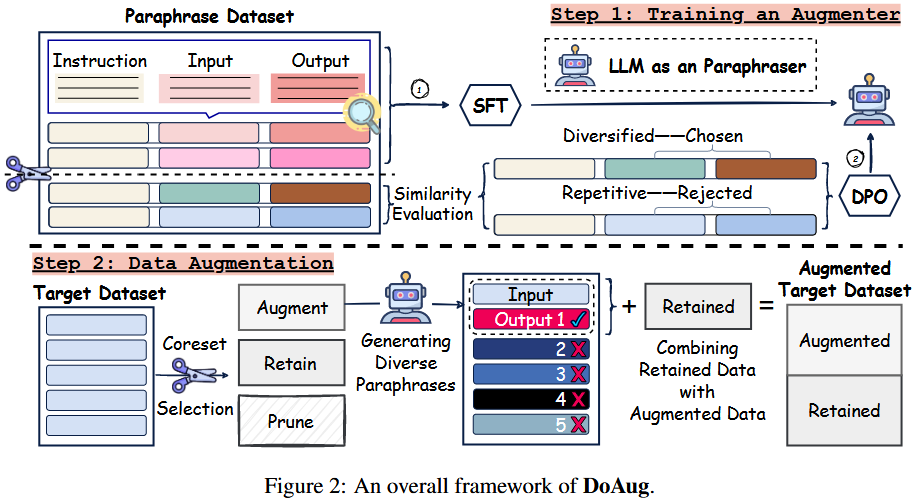
-
监督指令微调(SFT,Supervised Fine-Tuning)
- 目标:让 LLM 学会在保留原始语义的前提下改写句子(即释义功能)。
- 操作:使用释义数据集(如 ChatGPT Paraphrases 数据集)对预训练 LLM 进行微调。训练过程采用参数高效微调技术(PEFT)中的 LoRA 方法,冻结原始模型权重,仅更新低秩适配矩阵,以降低计算成本。
- 输出:初步具备释义能力的 LLM,能够生成与输入句子语义相似但表达方式不同的文本。
-
基于偏好数据的 DPO 微调(Direct Preference Optimization)
- 目标:增强 LLM 生成样本的多样性,避免重复或冗余。
- 偏好数据集构建:从原始释义数据集中采样句子,为每个句子生成 5 个候选释义,通过计算嵌入空间的欧氏距离,筛选出 “最多样”(距离最大)的释义作为 “优选样本”,“最相似”(距离最小)的作为 “劣选样本”,形成偏好数据对($y_w$,$y_l$)。
- DPO 训练:使用上述偏好数据集,通过 DPO 算法优化 LLM 的生成策略,最大化生成 “优选样本” 的概率,最小化生成 “劣选样本” 的概率。该过程无需额外训练奖励模型,直接通过损失函数(公式 6)调整模型参数。
- 输出:具备高多样性生成能力的 LLM 释义器,既能保持语义一致性,又能生成丰富多样的表达方式。
该阶段针对目标数据集筛选高价值样本进行增强,平衡计算成本与增强效果,具体包括:
-
核心样本集(Coreset)选择
- 目标:识别数据集中最具信息量的样本,仅对其进行增强以降低成本。
- 操作:先在数据集上训练下游任务模型,同时收集训练动态与训练后指标。计算 EL2N、熵、方差和 AUM 分数,以此评估样本重要性。运用分数单调选择和以覆盖为中心的选择(CCS)推导核心集。DoAug 通过分层核心集选择操作:修剪低重要性样本,保留中等重要性样本,增强高重要性样本,且仅将高重要性样本作为数据增强的种子。。采用分层选择策略,将样本分为三类:
- Saugment:高重要性样本,作为生成释义的种子;
- Sretain:中等重要性样本,直接保留无需增强;
- Sprune:低重要性样本,被剔除。
- 比例:默认比例为 raugment:rretain:rprune=1:1:1。
-
生成与筛选多样化释义
- 生成:对Saugment中的每个样本,使用训练好的 LLM 释义器生成 K 个候选释义(默认 K=5)。
- 筛选:基于嵌入空间距离,仅保留与原始样本最具多样性的释义,避免冗余。
-
构建最终增强数据集
- 将 Saugment 的原始样本及其筛选后的释义、Sretain的保留样本合并,形成最终的增强数据集 $\tilde{S}$。
算法

3 Experiments
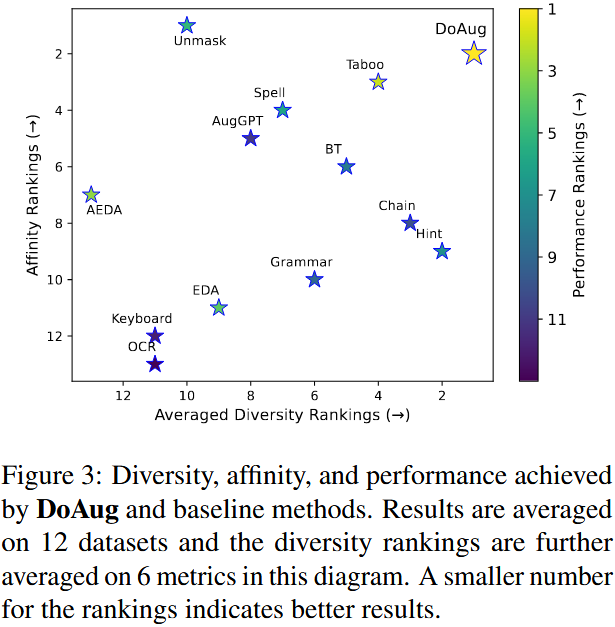
评估维度:包括多样性、亲和性及下游任务性能,分数越高效果越好。
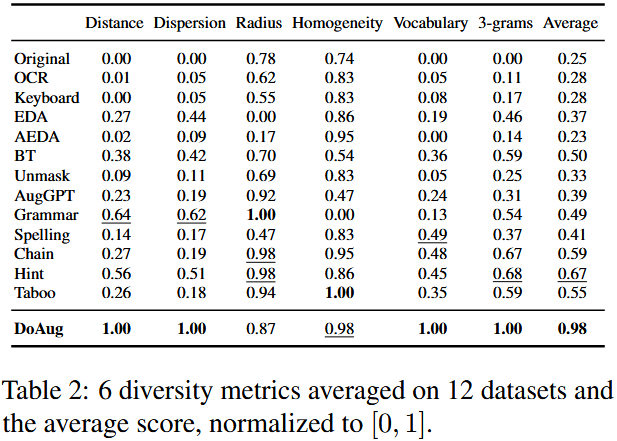
- 多样性评估:
- 样本级潜在多样性:通过嵌入空间的成对欧氏距离和余弦相似度评估(距离、离散度);
- 数据集级潜在多样性:通过所有样本嵌入的覆盖度和均匀性评估(等值线半径、同质性);
- 词汇多样性:通过数据集中不同词语的数量评估(词汇量、独特 3-grams)。
- 亲和性评估:通过嵌入偏差体现增强数据集与原始数据集的连贯性。
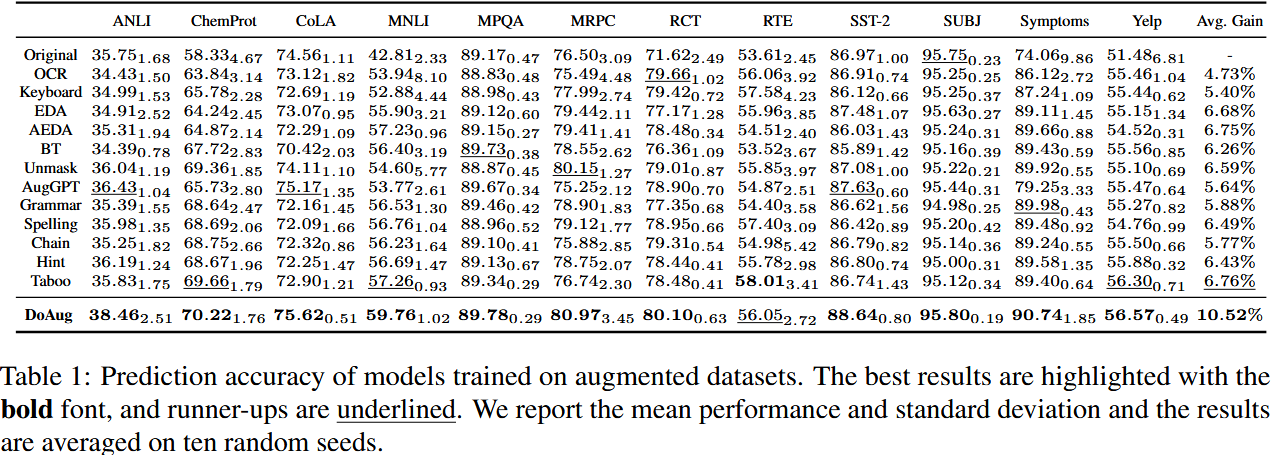
- 下游任务性能评估:在原始和增强数据集上训练带分类头的 BERTbase 模型,以预测准确率衡量性能。
Prediction accuracy
diversity metrics

 浙公网安备 33010602011771号
浙公网安备 33010602011771号