论文信息
论文标题:Data Quality Enhancement on the Basis of Diversity with Large Language Models for Text Classification: Uncovered, Difficult, and Noisy
论文作者:陈立畅、李诗阳、闫军、王浩、卡尔帕·古纳拉特纳、维卡斯·亚达夫、唐政、维贾伊·斯里尼瓦桑、周天翊、黄恒、金红霞
论文来源:ACL 2025
论文地址:link
论文代码:link
Abstract
- 背景:近年来,大型语言模型(LLMs)在文本分类中的应用备受关注,但其实分类准确率尚未普遍超过小型模型。尽管微调能提升 LLMs 的文本分类性能,然而现有基于 LLMs 的数据质量研究难以直接用于解决文本分类问题。
- 方法:为进一步提升 LLMs 在分类任务中的性能,本文提出一种基于 LLMs 的文本分类数据质量增强(DQE)方法。该方法先用贪心算法将数据集分为抽样和未抽样子集,模型经抽样数据集微调后预测未抽样子集结果,将预测错误数据分为未覆盖、难微调、噪声三类;随后从抽样子集中移除噪声数据,与未抽样子集中的未覆盖和难微调数据合并,形成最终数据集。
- 结果:实验结果表明,该方法能有效提升 LLMs 在文本分类任务中的性能,显著提高训练效率,节省近一半的训练时间,且在多个开源分类任务中达到了最先进的性能。
1 Introduction
贡献:
- 提出结合大语言模型与文本相似度技术的新方法,重新定义未覆盖、难微调及噪声数据的分类。
- 开发数据质量增强策略,筛选适用于文本分类的高质量数据集,保留有益的未覆盖和难微调数据,剔除干扰训练的噪声数据,同时保证数据多样性。
- 该方法显著提升大语言模型训练效率,仅用近半数据量即可实现更优微调效果,节省近半训练时间成本。
2 Methodology
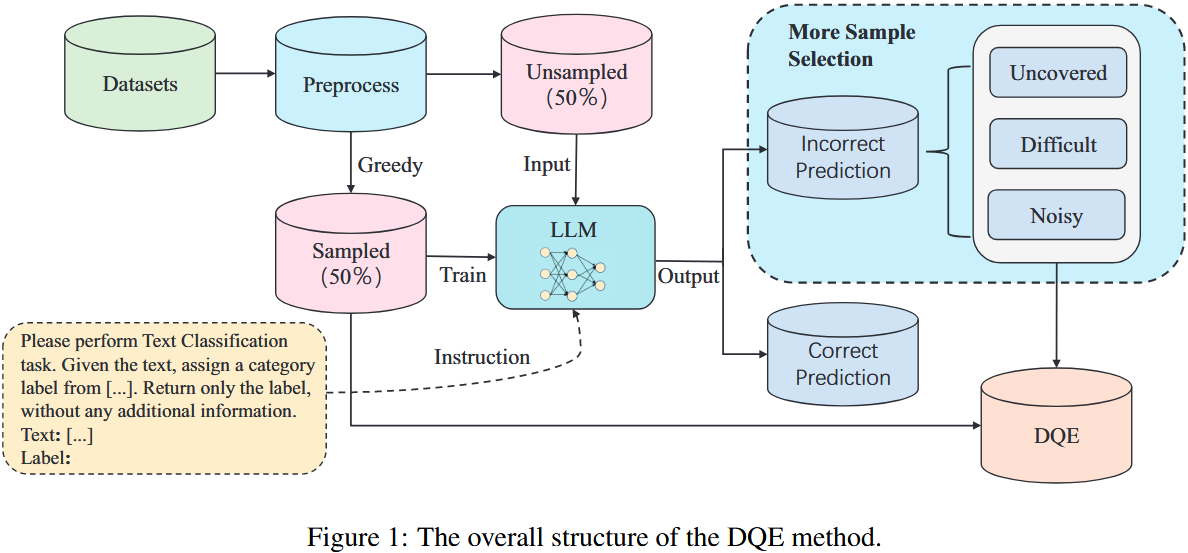
2.1 预处理
数据抽样前需进行简单预处理。
步骤:
-
- 移除缺失值(仅含文本无标签或仅含标签无文本的异常数据,避免干扰模型训练结果)。
- 去除重复数据(其对模型训练意义有限,且影响后续抽样)。
- 识别标签不一致的样本(此类样本会导致模型训练时难以收敛)。
2.2 贪心抽样步骤
预处理后,先用 all-mpnet-base-v21 模型将文本转为含丰富语义信息的向量,便于计算文本间语义距离;再用 K-Center-Greedy 算法从原始数据集中选取一半数据(K 设为预处理后训练集规模的一半),该算法先随机选一样本作为初始向量中心,再迭代选取离当前中心最远的样本加入数据集并更新中心,直至选满 K 个样本。
特点:抽样数据覆盖范围广,能有效保证数据的多样性和代表性。
2.3 更多样本选择
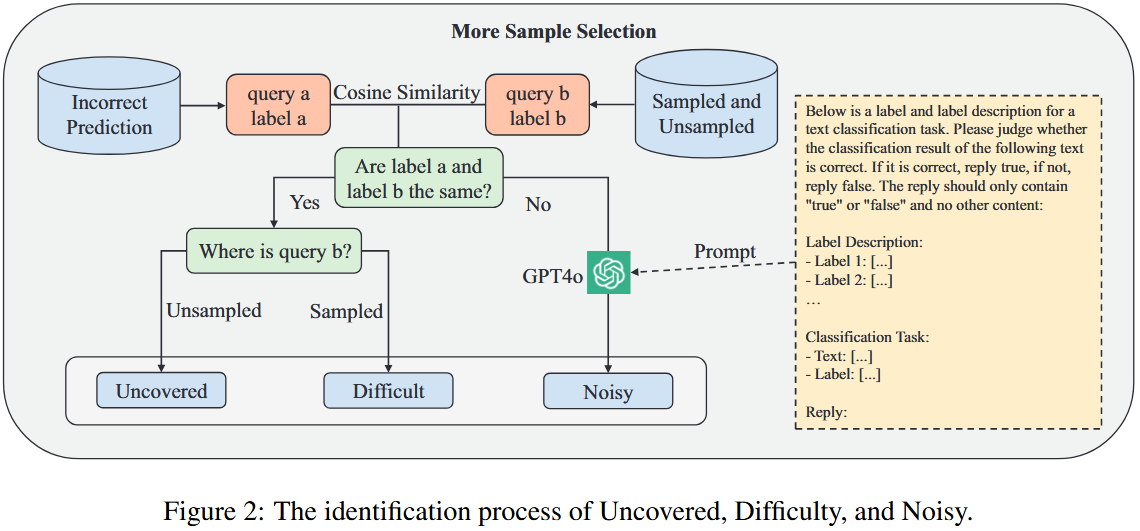
- 目的:在保证数据多样性基础上,筛选对模型训练有益的数据,剔除阻碍训练的数据。
- 背景:纳入未覆盖数据、增加难样本可促进训练,噪声数据(文本分类中标签噪声常见且难避免)会干扰模型收敛、影响性能。
- 具体操作:对未抽样子集中预测错误的数据,通过余弦相似度在全数据集找最相似样本,基于 “高度相似数据通常标签相同” 的原则分为三类:
- 未覆盖:错误样本与最相似样本标签相同,且最相似样本在未抽样子集,表明抽样数据集未覆盖相关特征,将其加入最终训练集。
- 难微调:错误样本与最相似样本标签相同,且最相似样本在抽样数据集,表明模型虽经相关特征训练但预测错误,将其加入最终训练集。
- 噪声:错误样本与最相似样本标签不同,疑似噪声数据;借助 GPT-4o 判断标签,若错误则移除。
3 Experiment
3.1 Datasets
- MR(Pang and Lee, 2005):电影评论二元分类任务,按情感分为正面和负面;含 8530 个训练样本、1066 个测试样本。
- CR(Hu and Liu, 2004):客户评论二元分类任务,按情感分为正面和负面;含 3394 个训练样本、376 个测试样本。
- IMDb(Maas et al., 2011):电影评论二元分类任务,按情感分为正面和负面;含 25000 个训练样本、25000 个测试样本。
- SST-2(Socher et al., 2013):电影评论二元分类任务,按情感分为正面和负面;含 67349 个训练样本、1821 个测试样本。
- SST-5(Socher et al., 2013):电影评论五元分类任务,按情感分为极负面、负面、中性、正面、极正面;含 8544 个训练样本、2210 个测试样本。
- AG News(Zhang et al., 2015):新闻四元分类任务,类别为世界、体育、商业、科技;含 120000 个训练样本、7600 个测试样本。
3.2 Large Language Models
3.3 Implementation Details
- 环境配置:使用多节点多 GPU 服务器环境,含 2 台服务器,每台配备 4 个 L40s GPU(每 GPU 48GB VRAM)。
- 训练策略:采用 DeepSpeed 第二阶段数据并行训练,数据均匀分布以加速训练。
- 微调参数:基于 Swift 框架全参数微调,学习率 1e-5,批次大小 1,通过梯度累积(16 步)提升有效批次;训练轮次依数据集大小动态调整(1-3 轮)。
3.4 Results
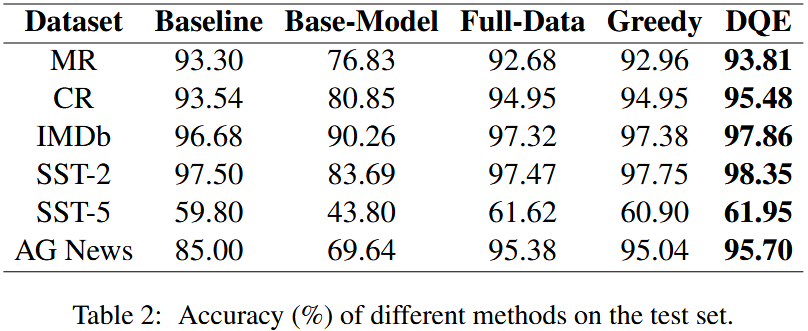
- 数据集规模:Table 1 显示,DQE 采样结果约为 Full-Data 的 50%(SST-2 数据集低于 50%);Greedy 为 Full-Data 的一半,DQE 在其基础上进一步处理数据得到。
- 模型性能:Table 2 以准确率衡量,相同超参数下,DQE 方法在所有任务中表现最佳。全数据微调模型在 4 项任务(CR、IMDb、SST-5、AG News)上超基线,Greedy 在 4 项任务(CR、IMDb、SST-2、AG News)上超基线,未微调的 Base-Model 表现最差。
- 统计显著性:t 检验显示,DQE 与 Full-Data 准确率相近但差异显著,除 CR 数据集(p=0.1575)外,其余多数数据集上 DQE 性能提升具有统计显著性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号