论文信息
论文标题:LIMA: Less Is More for Alignment
论文作者:周春婷、刘鹏飞、徐普新、斯里尼·艾耶、孙娇、毛宇宁、马学哲、阿维亚·埃弗拉特、余萍、余丽丽、苏珊·张、加尔吉·戈什、迈克·刘易斯、卢克·泽特勒莫耶、奥默·利维
论文来源:NeurIPS 2023
论文地址:link
论文代码:link
Abstract
主要围绕大语言模型训练的两个阶段(无监督预训练、大规模指令微调与强化学习)的相对重要性展开,通过训练 LIMA 模型进行验证,具体总结如下:
- 大语言模型训练阶段:分为从原始文本进行无监督预训练(目的是学习通用表征),以及大规模指令微调与强化学习(目的是更好契合终端任务与用户偏好);
- LIMA 模型情况:基于 650 亿参数的 LLaMa 语言模型训练而成,仅用 1000 个精心策划的提示和回复,通过标准监督损失微调,未涉及强化学习或人类偏好建模;
- LIMA 模型表现:
- 能从少数训练示例中学会遵循特定回复格式,可应对规划旅行行程、推测历史演变等复杂查询。
- 对训练数据中未出现的未知任务,往往具有良好泛化能力。
- 在人类评估研究中,43% 的情况下其回复与 GPT-4 相当或更受青睐,与 Bard 相比这一比例达 58%,与经人类反馈训练的 DaVinci003 相比为 65%。
- 结论:大语言模型的几乎所有知识都在预训练阶段习得,有限的指令微调数据即可教会模型生成高质量输出;
1 Introduction
LLM 训练通常包含两步:
- 预训练:模型先在大语料库上进行无监督的预训练,以获得常规的语言理解和生成能力;
- 对齐:使用一些带标签的数据对模型进行微调
-
- 指令微调(Instruction Tuning)
- RLHF(Reinforcement Learning with Human Feedback)
假设:大模型在预训练阶段已习得几乎所有的知识与核心能力,而对齐阶段的作用,则是让模型掌握与用户交互的方式和风格,从而确保其已具备的能力能够被准确、恰当地展现出来。
-
- prompt 设计:形式多样,且模拟真实用户的提问场景与表达习惯;
- response 设计:回答质量高,风格统一采用 “a helpful AI assistant”(乐于助人的 AI 助手)的口吻。
在样本构成上,1000 个样本中 750 个源自三个社区论坛的真实场景提炼,其余 250 个为人工专门创作,以确保数据的多样性与针对性。
-
- Stack Exchange:这是一个按话题细分的社区平台(每个话题对应一个 “exchange”),其中以 Stack Overflow 最为知名。样本选取自 75 个核心 exchange 及 99 个其他 exchange,均为高分内容 —— 仅保留标题作为 prompt,匹配对应的高分回答作为 response。
- wikiHow:作为综合性问答社区,样本通过分层抽样获取:先从 19 个内容类别中随机抽取,再从抽中类别内选取文章,以确保多样性。最终以文章标题为 prompt,正文部分为 response。
- Pushshift Reddit Dataset:聚焦两个子版块的高赞内容:r/AskReddit 的问题被用作测试集 prompt,r/WritingPrompts 的内容则纳入训练集。
其中 200 个为原创内容,50 个改编自 Super-Natural Instructions 数据集。在 200 个原创样本的创作中,作者采用统一口吻(“a helpful AI assistant”,即 “一个乐于助人的 AI 助手”),并包含少量恶意 prompt 及对应的对抗性 response。研究发现,统一口吻可显著提升模型表现,其作用类似 “let's think step by step”(“让我们一步步思考”)类提示词,能引导模型形成思维链(chain of thought),助力推理过程的结构化呈现。
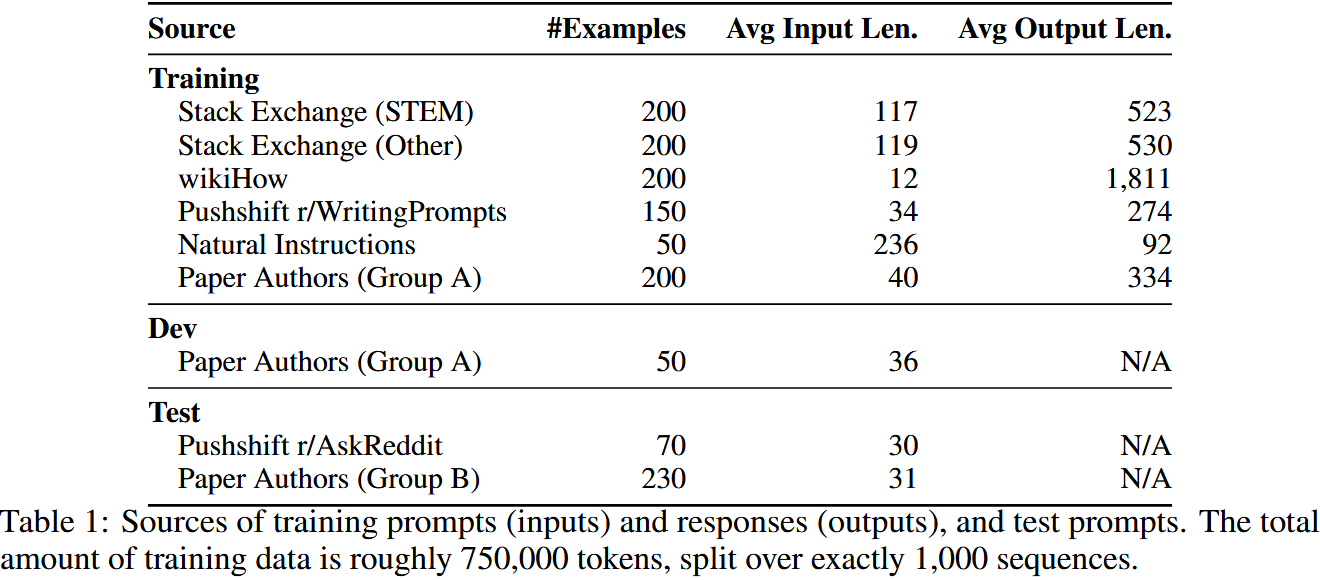
2 Training LIMA
- 模型与训练集:基于 LLaMa 65B,使用 1000 条示例的对齐训练集进行微调。
- 特殊标记:引入 EOT(end-of-turn)标记区分用户与助手发言,功能同 EOS 但避免歧义。
- 超参数:特殊设置:采用残差 dropout,底层 p_d=0.0,顶层线性升至 0.3(小模型为 0.2)。
- 优化器:AdamW(β₁=0.9,β₂=0.95,权重衰减 0.1)。
- 学习率:初始 1e-5,无预热,线性衰减至 1e-6,共训练 15 个 epoch。
- 批次大小:32(小模型为 64),文本长度超 2048 tokens 则截断。
- 特殊设置:采用残差 dropout,底层 $p_d=0.0$,顶层线性升至 0.3(小模型为 0.2)。
- checkpoint 选择:因困惑度与生成质量无关,从 5-10 epoch 中结合 50 条示例的开发集手动选择。
3 Human Evaluation
- 评估内容呈现:在每一步评估中,向标注者展示一个单一提示(prompt)以及由不同模型生成的两个可能回复(responses)。
- 标注任务要求:标注者需判断哪一个回复更优,或两个回复之间无显著差异(具体表述详见附录 C)。
- 平行标注设置:同时让 GPT-4 按照与人类标注者完全相同的指令和数据进行标注,以获取平行的评估结果。
结果表明,尽管该任务存在一定主观性,但人类标注者之间具有良好的一致性。GPT-4 的标注表现与人类标注者相当,基本通过了该任务的 “Turking Test”(即机器标注质量可媲美人类标注)。
对比评估准则
对于训练好的LIMA模型,为测试集中的每一个prompt生成一个回答,并通过两种方式进行评估:
- 绝对评估。对每一个 prompt 生成的 response 的质量通过人工和GPT-4进行评判。根据 response 的质量,分为 Fail, Pass 及 Excellent 三种级别。
- 将 LIMA 与其他模型进行两两比较:对于一个 prompt,双方各自生成一个 response,然后比较生成的response的质量。
绝对评估的结果如下图所示:
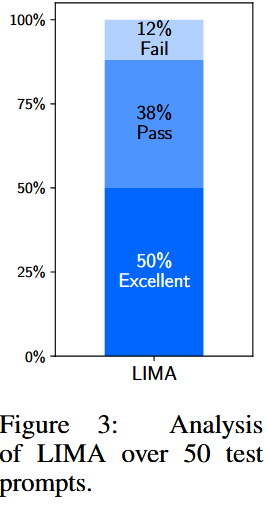
从图中可以看出,对于测试集中绝大部分的 prompt,其response皆为Excellent 或者 Pass,说明LIMA的效果不错。
将 LIMA 与其他模型进行两两比较

左右子图分别呈现人类偏好评估与 GPT-4 评估结果,显示 LIMA 的效果优于训练数据量远超于它、且 DaVinci003 还经 RLHF 微调的 Alpaca 65B 及 DaVinci003,该结果支持了上文假设。
消融实验
- 研究目的:通过消融实验探究训练数据的多样性、质量和数量的影响。
- 核心发现:在模型对齐方面,增加输入多样性和输出质量有显著积极作用,仅增加数量则未必。
- 实验设置:基于 7B 参数的 LLaMa 模型微调,控制超参数一致;对每个测试集提示生成 5 个回应,由 ChatGPT(GPT-3.5 Turbo)按 1-6 分李克特量表评估有用性,结果报告平均分及 95% 双侧置信区间。
多样性:为测试提示多样性的影响,在控制质量和数量的情况下,对比了经质量过滤的 Stack Exchange 数据(提示异质、回应优质)与 wikiHow 数据(提示同质、回应优质)的训练效果。从两者各选取 2000 个训练样本,结果(图 5)显示,多样性更高的 Stack Exchange 数据使模型表现显著更优,但需注意两数据源可能存在其他干扰因素。
质量:从 Stack Exchange 选取 2000 个无质量或风格过滤的样本,与经过滤样本训练的模型对比。图 5 显示,两者存在显著的 0.5 分差异。
数量:从 Stack Exchange 选取呈指数增长的训练集进行测试。如图 6 所示,意外发现将训练集规模翻倍并未提升回应质量。
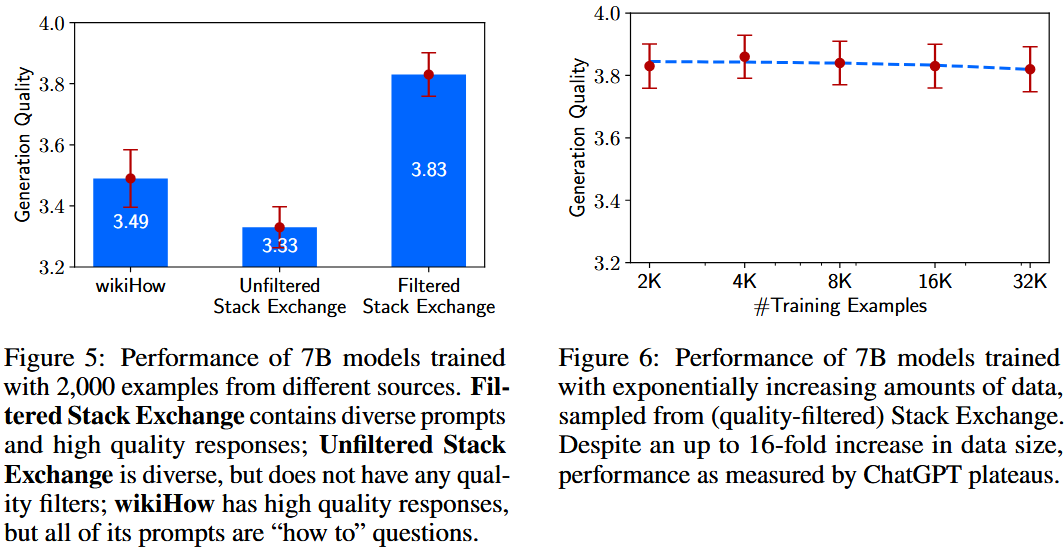
- 数据多样性影响:控制质量和数量,对比训练于高质量但提示同质化的 wikiHow 数据与高质量且提示多样化的 Stack Exchange 数据的 7B 模型,发现后者性能显著更高。
- 数据质量影响:对比训练于经过质量筛选和未筛选的 Stack Exchange 数据(各 2000 个示例)的 7B 模型,前者性能明显更优,差距达 0.5 分。
- 数据数量影响:使用质量筛选后的 Stack Exchange 数据,以指数级增加训练示例数量(2K 到 32K)训练 7B 模型,发现性能并未随数量增加而提升,反而趋于平稳。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号