


1000w的模拟数据-导入mysql和postgreSQL过程,模糊查询和深分页优化
1、数据来源
下载下来:1000w的模拟数据.zip,大小227.3M
解压出来是

2、数据处理
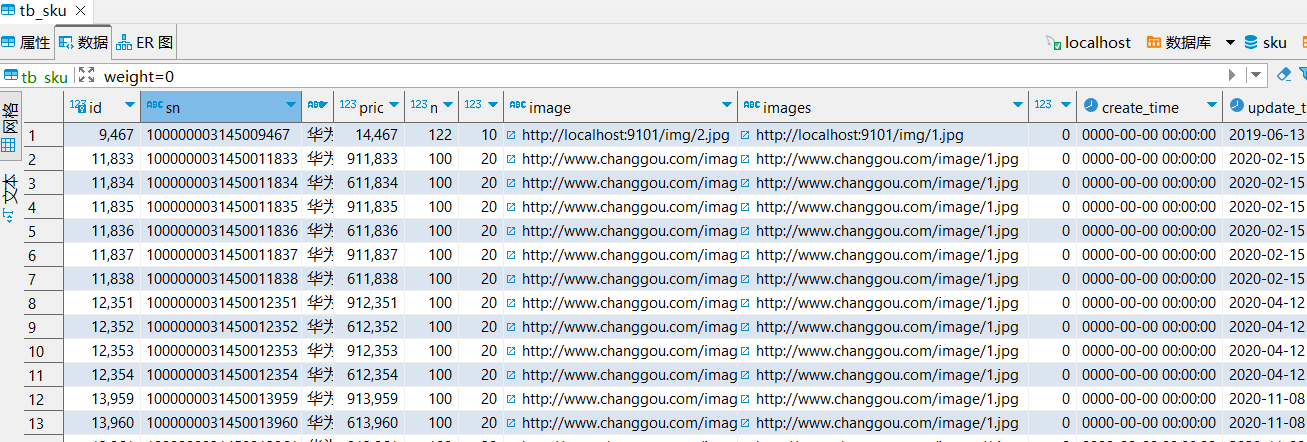
查看数据(其实是导入后)发现,images这个字段可能是多张图片,但是tb_sku1.sql中第9467行imges会取第二http,第三个http会赋值给下个字段,造成数据错乱

不进行数据处理,数据错乱的情况如下
数据处理程序如下(以java为例)


package com.oy; import java.io.*; import java.util.ArrayList; import java.util.List; public class TextProcessor { public static void main(String[] args) { String inputFilePath = "D:\\BaiduNetdiskDownload\\sku\\tb_sku5.sql"; String outputFilePath = "D:\\BaiduNetdiskDownload\\sku\\tb_sku5_output.sql"; processFile(inputFilePath, outputFilePath); } /** * java实现方法:给定一个txt文件,每行数据形如 * 9467,http://localhost:9101/img/2.jpg,http://localhost:9101/img/1.jpg,http://localhost:9101/img/7.jpg,11,2019-06-13, * 首先查询该行包含多少个 'http',若大于2个,将第2个到后面的'http'合并为[http://1|http://2]。对于前面的示例数据则改为 * 9467,http://localhost:9101/img/2.jpg,[http://localhost:9101/img/1.jpg|http://localhost:9101/img/7.jpg],11,2019-06-13 */ private static void processFile(String inputFilePath, String outputFilePath) { try (BufferedReader reader = new BufferedReader(new FileReader(inputFilePath)); BufferedWriter writer = new BufferedWriter(new FileWriter(outputFilePath))) { String line; while ((line = reader.readLine()) != null) { String processedLine = processLine(line); writer.write(processedLine); writer.newLine(); } } catch (IOException e) { e.printStackTrace(); } } private static String processLine(String line) { String[] parts = line.split(","); List<String> newParts = new ArrayList<>(); int httpCount = 0; StringBuilder httpUrls = new StringBuilder(); for (String part : parts) { if (part.startsWith("http")) { httpCount++; if (httpCount == 1) { newParts.add(part); } else { if (httpCount == 2) { httpUrls.append(part); } else { httpUrls.append("|").append(part); } } } else { if (httpCount > 1) { newParts.add("[" + httpUrls.toString() + "]"); httpCount = 0; httpUrls.setLength(0); } newParts.add(part); } } if (httpCount > 1) { newParts.add("[" + httpUrls.toString() + "]"); } return String.join(",", newParts); } }
数据处理后生成 tb_sku1_output.sql ~ tb_sku5_output.sql
3、导入mysql
创建库和表
CREATE DATABASE `sku` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
use sku; CREATE TABLE `tb_sku` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id', `sn` varchar(100) NOT NULL COMMENT '商品条码', `name` varchar(200) NOT NULL COMMENT 'SKU名称', `price` int(20) NOT NULL COMMENT '价格(分)', `num` int(10) NOT NULL COMMENT '库存数量', `alert_num` int(11) DEFAULT NULL COMMENT '库存预警数量', `image` varchar(200) DEFAULT NULL COMMENT '商品图片', `images` varchar(2000) DEFAULT NULL COMMENT '商品图片列表', `weight` int(11) DEFAULT NULL COMMENT '重量(克)', `create_time` datetime DEFAULT NULL COMMENT '创建时间', `update_time` datetime DEFAULT NULL COMMENT '更新时间', `category_name` varchar(200) DEFAULT NULL COMMENT '类目名称', `brand_name` varchar(100) DEFAULT NULL COMMENT '品牌名称', `spec` varchar(200) DEFAULT NULL COMMENT '规格', `sale_num` int(11) DEFAULT '0' COMMENT '销量', `comment_num` int(11) DEFAULT '0' COMMENT '评论数', `status` char(1) DEFAULT '1' COMMENT '商品状态 1-正常,2-下架,3-删除', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
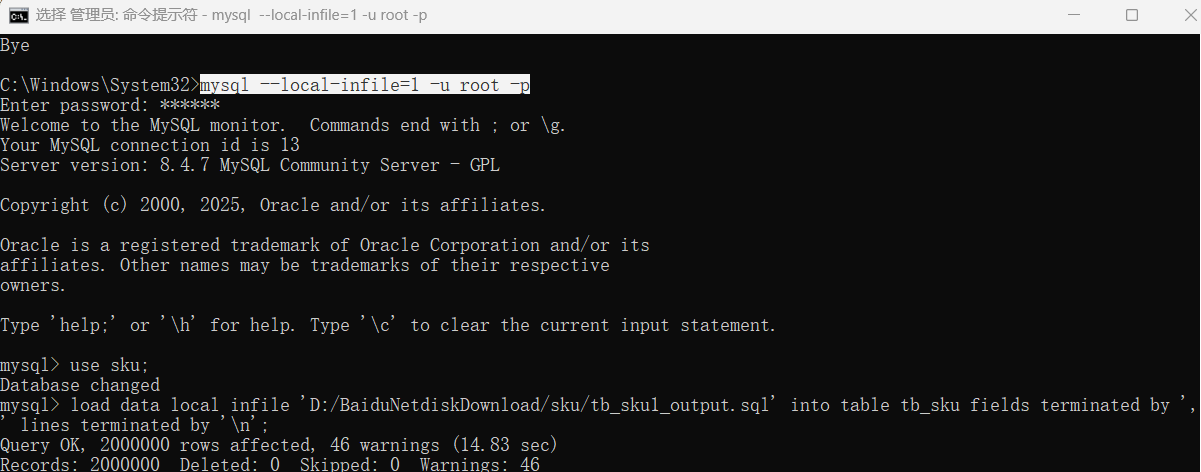
导入指令
load data local infile 'D:/BaiduNetdiskDownload/sku/tb_sku1_output.sql' into table tb_sku fields terminated by ',' lines terminated by '\n';
4、导入postgreSQL
建表脚本
CREATE TABLE tb_sku ( id SERIAL PRIMARY KEY, sn VARCHAR(100) NOT NULL, name VARCHAR(200) NOT NULL, price INT NOT NULL, num INT NOT NULL, alert_num INT DEFAULT NULL, image VARCHAR(200) DEFAULT NULL, images VARCHAR(2000) DEFAULT NULL, weight INT DEFAULT NULL, create_time TIMESTAMP DEFAULT NULL, update_time TIMESTAMP DEFAULT NULL, category_name VARCHAR(200) DEFAULT NULL, brand_name VARCHAR(100) DEFAULT NULL, spec VARCHAR(200) DEFAULT NULL, sale_num INT DEFAULT 0, comment_num INT DEFAULT 0, status CHAR(1) DEFAULT '1' ); -- 为表添加注释 COMMENT ON TABLE tb_sku IS '商品表'; -- 为列添加注释 COMMENT ON COLUMN tb_sku.id IS '商品id'; COMMENT ON COLUMN tb_sku.sn IS '商品条码'; COMMENT ON COLUMN tb_sku.name IS 'SKU名称'; COMMENT ON COLUMN tb_sku.price IS '价格(分)'; COMMENT ON COLUMN tb_sku.num IS '库存数量';
导入脚本
COPY public.tb_sku FROM 'D:/BaiduNetdiskDownload/sku/tb_sku1_output.sql' WITH (FORMAT csv, HEADER false, NULL 'null', ENCODING 'utf8');
NULL 'null':指定文件中 null 字符串代表NULL值
HEADER false:没有表头
参考:PostgreSQL 复制CSV文件中的NULL值到Postgres数据库
5、测试模糊查询和深分页
以下都是以MySQL为例。首先创建索引
CREATE INDEX idx_name ON tb_sku(name);
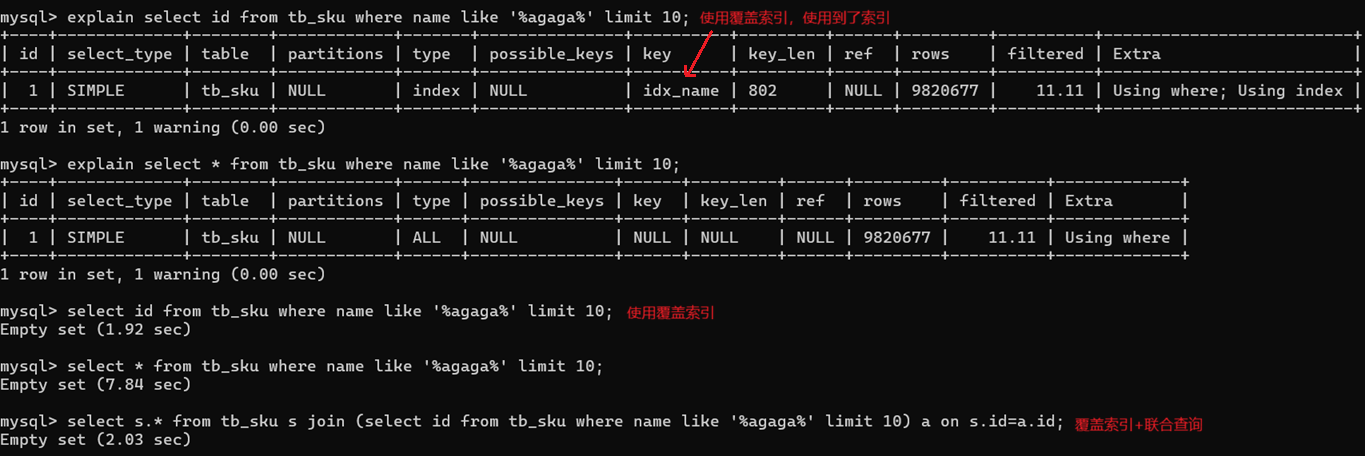
5.1、模糊查询
使用【覆盖索引+连接查询】优化模糊查询
5.2、深分页
1)覆盖索引+联合查询/子查询(子查询不支持limit),select s.* from tb_sku s join (select id from tb_sku limit 10000000,10) a on a.id=s.id;
2)游标分页:业务上只提供根据日期筛选,及下一页查询,select id from tb_sku where id > 10000000 limit 10;
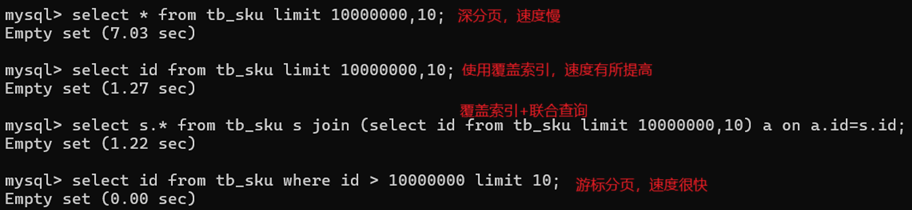
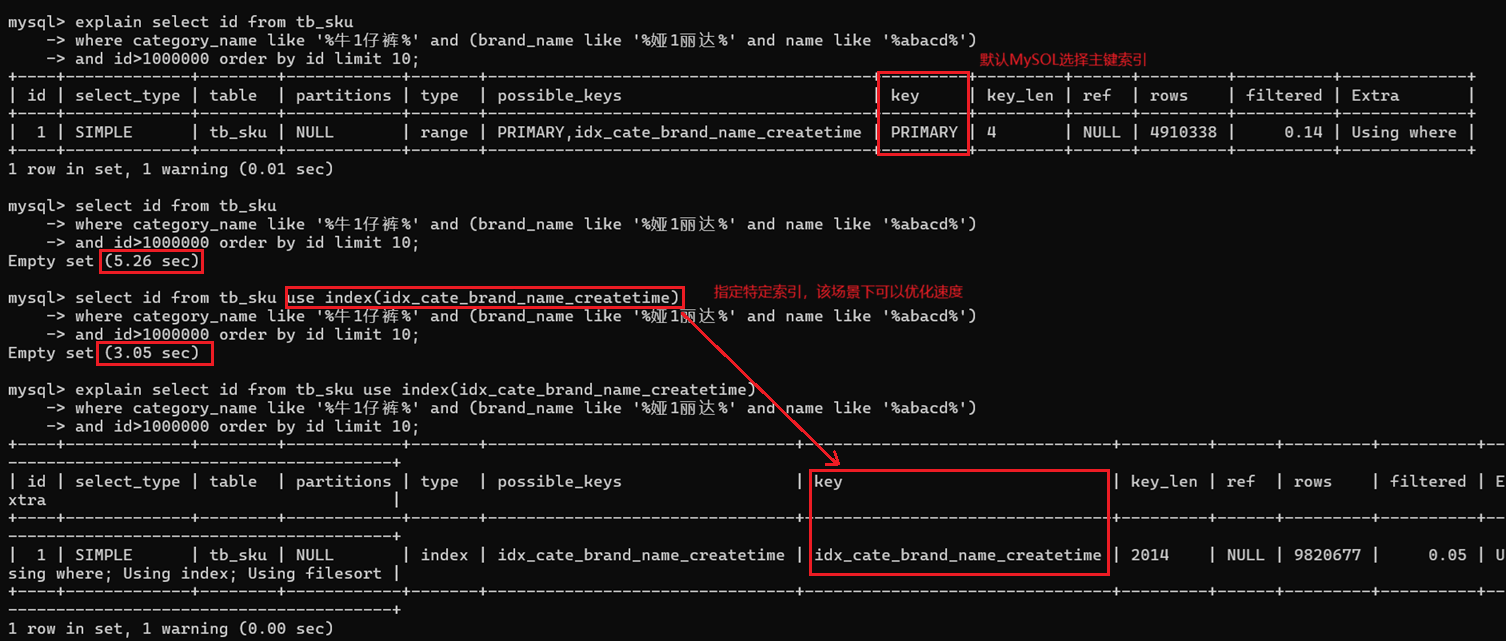
where id > 10000000 limit 10 后会导致mysql直接走主键索引,某些情况下需要修改走其他的【复合索引】
比如,创建索引
create index idx_cate_brand_name_createtime on tb_sku(category_name, brand_name, name, update_time);
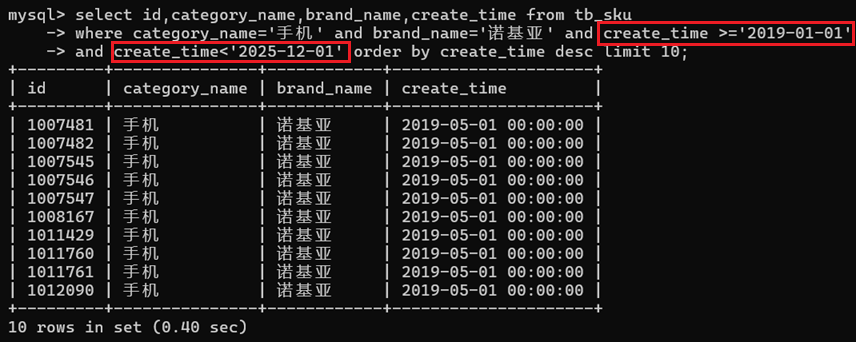
很多场景要根据日期时间排序,比如根据 create_time desc 排序,此时 create_time 应该在该业务查询场景是不重复的(例如银行流水)。
以下是,模拟手机APP银行流水的日期区间查询【第一次查询】;然后查询下一页时,SQL应该是 create_time<上一次返回数据的最后一条记录的 create_time(web场景由前端传)。
6、导入mysql时解决:ERROR 3948 (42000): Loading local data is disabled; this must be enabled on both the client and server sides
1、管理员打开cmd 2、net stop mysql, net start mysql 3、mysql --local-infile=1 -u root -p 4、SHOW VARIABLES LIKE 'local_infile'; 5、use sku; 6、load data local infile 'D:/BaiduNetdiskDownload/sku/tb_sku1_output.sql' into table tb_sku fields terminated by ',' lines terminated by '\n';
或
#客户端连接服务端时,加上参数 --local-infile mysql --local-infile -uroot -p #设置全局参数local-infile为1,开启从本地加载文件导入数据的开关 set global local_infile=1; #执行load指令 load data local infile 'D:/BaiduNetdiskDownload/sku/tb_sku1_output.sql' into table tb_sku fields terminated by ',' lines terminated by '\n';
posted on 2025-12-17 14:55 wenbin_ouyang 阅读(7) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号