第六次作业
-
作业①:
-
要求:
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
- 了解正则的使用方法
-
候选网站:豆瓣电影:https://movie.douban.com/top250
-
输出信息:
排名 电影名称 导演 主演 上映时间 国家 电影类型 评分 评价人数 引用 文件路径 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 1994 美国 犯罪 剧情 9.7 2192734 希望让人自由。 肖申克的救赎.jpg 2......
-
实现代码:
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import threading from prettytable import PrettyTable table = PrettyTable(["排名", '电影名称', '导演', '主演', '上映时间','国家','电影类型','评分','评价人数']) def imageSpider(start_url): global threads global count try: urls = [] req = urllib.request.Request(start_url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") # 筛选下载所有图片 images = soup.select("img") for image in images: try: src = image["src"] alt = image["alt"] # 图片链接和图片名 url = urllib.request.urljoin(start_url, src) if url not in urls: urls.append(url) print(url) count = count + 1 T = threading.Thread(target=download, args=(url, count, alt)) T.setDaemon(False) T.start() threads.append(T) except Exception as err: print(err) # 获取打印每个信息块的数据 lis = soup.select("ol[class='grid_view'] li") for li in lis: rank = li.select("div[class='item'] div em")[0].text name = li.select("div[class='info'] div a span[class='title']")[0].text info = li.select("div[class='info'] div[class='bd'] p")[0].text.replace("\n","").replace(" ","").split("\xa0") #数据分割获取 dir = info[0][3:] act = info[3][3:-4] year = info[3][-4:] country = info[5] tag = info[7] com = li.select("div[class='bd'] div[class='star'] span[class='rating_num']")[0].text aud = li.select("div[class='star'] span")[3].text table.add_row([rank,name,dir,act,year,country,tag,com,aud]) except Exception as err: print(err) def download(url, count, alt): #图片文件下载 try: if (url[len(url)-4] == "."): ext = url[len(url)-4:] else: ext = "" req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("images\\" + alt + ext, "wb") fobj.write(data) fobj.close() print("downloaded " + alt + ext) except Exception as err: print(err) start_url = "https://movie.douban.com/top250" headers = {"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} count = 0 threads = [] imageSpider(start_url) for t in threads: t.join() print(table)
实验结果:

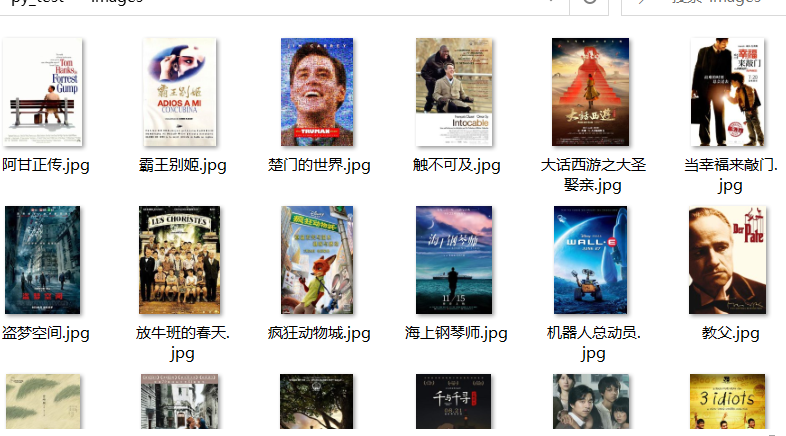
心得体会:
复习使用第三次作业的框架,增加了信息的爬取,一些基础知识的运用,虽然在糅合的数据进行分割时卡了一下,但整个过程相对顺利。
-
作业②:
-
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
- 爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下
![image-20201124133319576]()
-

实现代码:
ctable:
CREATE TABLE `xy669`.`ctable` ( `No` VARCHAR(8) NOT NULL, `Name` VARCHAR(512) NULL, `City` VARCHAR(256) NULL, `Url` VARCHAR(256) NULL, `Info` VARCHAR(32) NULL, PRIMARY KEY (`No`));
MySpider
import scrapy # import sys # sys.path.append('..') from ..items import collegeItem from bs4 import UnicodeDammit from bs4 import BeautifulSoup class MySpider(scrapy.Spider): name = 'myspider' start_url = 'https://www.shanghairanking.cn/rankings/bcur/2020' headers = { "User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} def start_requests(self): #程序开始时会调用 url = MySpider.start_url yield scrapy.Request(url=url, callback=self.parse)# 调用parse函数 def parse(self, response): dammit = UnicodeDammit(response.body, ["utf-8", "gdk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data) lis =selector.xpath("//div[@class='rk-table-box']/table/tbody/tr") #获取每行信息 for li in lis: no = li.xpath("./td[position()=1]/text()").extract_first().replace("\n","").replace(" ","")#部分信息含有换行和空格 name = li.xpath("./td[@class='align-left']/a/text()").extract_first() city = li.xpath("./td[position()=3]/text()").extract_first().replace("\n","").replace(" ","") url = li.xpath("./td[@class='align-left']/a//@href").extract() item = collegeItem() item["no"] = no item["name"] = name item["city"] = city item["url"] = url #访问url获取个体的具体信息 info_url = "https://www.shanghairanking.cn/" + url yield scrapy.Request(url=info_url,callback=self.parse_info)#调用info_parse函数 def parse_info(self, response): dammit = UnicodeDammit(response.body, ["utf-8", "gdk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data) images =selector.xpath("//div[@class='info-container']/table/tbody/tr/td[@class='univ-logo']/img/@src").extract() info = selector.xpath("//div[@class='univ-introduce']/p/text()") # item = collegeItem() item["info"] = info item["src"] = images yield item
Piplines:
from itemadapter import ItemAdapter import pymysql from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request class CollegePipeline: # 爬虫开始是执行的函数 def open_spider(self, spider): print("opened") try: # 连接数据库 self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="xy669", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from ctable") self.opened = True self.count = 0 except Exception as err: print(err) self.opened = False def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.opened = False print("closed") print("总共爬取", self.count, "所学校") def process_item(self, item, spider): print(item["no"]) print(item["name"]) print(item["city"]) print(item["url"]) print(item["info"]) url = item['src'] if (url[len(url) - 4] == "."): ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("C:/example/demo/demo/images/" + str(self.count) + ext, "wb") fobj.write(data) #保存图片 fobj.close() if self.opened: self.count += 1 self.cursor.execute("insert into university(`No`,`Name`,`City`,Url,`Info`) values(%s,%s,%s,%s,%s)",(item["no"], item["name"], item["city"], item["url"],item["info"])) return item
实验结果:


心得体会:
复习使用scrapy框架和mysql。好久没用显得有些生疏,在获取单个学校的具体信息时也出现了许多问题。
-
作业③:
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
- 使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
- 其中模拟登录账号环节需要录制gif图。
-
候选网站: 中国mooc网:https://www.icourse163.org
-
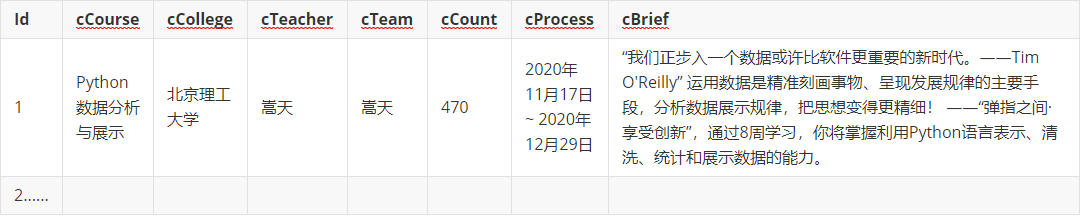
输出信息:MYSQL数据库存储和输出格式如下
![image-20201124133334348]()
-
实现代码:
from selenium import webdriver from selenium.webdriver.chrome.options import Options import urllib.request import threading import sqlite3 import os import datetimeimport time from selenium.webdriver.support.ui import WebDriverWait import pymysql def startup(): chrome_options = Options() chrome_options.add_argument("——headless") chrome_options.add_argument("——disable-gpu") driver = webdriver.Chrome(chrome_options=chrome_options) num = 0 # 连接数据库 try: con = sqlite3.connect("xy669.db") cursor = con.cursor() try: cursor.execute("drop table ctable") #删除同名表 except: pass try: sql = "create table ctable(Id varchar(64),Course varchar(64),College varchar(64),Teacher varchar(64),Team varchar(64),Count varchar(64),Process varchar(64),Brief varchar(512))" cursor.execute(sql) #创建表用于存储数据 except: pass except Exception as err: print(err) # def insertDB(self, ): # #数据插入 # try: # sql = "insert into courses (number,name,college,teacher,team,count,process,brief) values (?,?,?,?,?,?,?,?)" # self.cursor.execute(sql, (number,name,college,teacher,team,count,process,brief)) # except Exception as err: # print(err) driver = webdriver.Chrome("D:\Download\chromedriver.exe") driver.get("https://www.icourse163.org/") #访问并登录网页(电话) # driver.implicitly_wait(10) # time.sleep(1) # driver.maximize_window()#全屏 # time.sleep(1) driver.find_element_by_xpath("//div[@class='unlogin']/a").click()#登录/注册按钮 time.sleep(1) driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']/span").click()#其他登录方式 time.sleep(1) driver.find_elements_by_xpath("//div[@class='ux-tabs-underline']/ul/li")[1].click()#电话登录 time.sleep(1) #电话输入 driver.find_elements_by_xpath("//div[@class='u-input box']/input[@type='tel']").send_keys('') time.sleep(1) #密码输入 driver.find_elements_by_xpath("//div[@class='u-input box']/input[@type='password']").send_keys('') time.sleep(1) driver.find_element_by_xpath("//div[@class='f-cb loginbox']/a").click()#登录按钮 time.sleep(10) #进入用户页面获取课程信息 driver.find_element_by_xpath("//div[@class='_3uWA6']").click()#我的课程 time.sleep(1) number = 0 cous = driver.find_elements_by_xpath("//div[@class='course-card-body-wrapper']/box")#每一个课程块 for cou in cous: #进入课程界面 number+=1 college = cou.find_elements_by_xpath("./div[@class='school']/a").text process = cou.find_elements_by_xpath("./div[@class='personal-info']/div/div[@class='course-status']").text cou.click() course = driver.find_element_by_xpath("//div[@class='f-fl info']/div[@class='f-cb']/a/h4[@class='f-fc3 courseTxt']").text teacher = driver.find_element_by_xpath("//div[@class='f-fl info']/h5[@class='f-fc3 courseTxt']").text driver.find_element_by_xpath("div[@class='f-fl info']/a/h4[@class='f-fc3 courseTxt']").click() #进入课程信息界面(点击课程名) time.sleep(3) count = driver.find_elements_by_xpath("//div[@class='course-enroll-info_course-enroll_price-enroll']/span")[0].text+"人参加" #分开显示,取前 brief = driver.find_element_by_xpath("//div[@class='f-richEditorText']").text.strip() # 插入数据 try: cursor.execute("INSERT INTO ctable (`Id`,`Course`,`College`,`Teacher`,`Team`,`Count`,`Process`,`Brief`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)",(str(number), course,college,teacher,team,count,process,brief)) except Exception as err: print(err) con.commit() con.close() driver.close() startup()
实验结果:

心得体会:
复习使用Selenium框架。因为数据信息不在一个页面中,需要进行多次的点击跳转和返回,查找xpath内容也花了不少时间。
相对前面的,该实验完成就麻烦很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号