
102302122许志安作业4
作业一:基于 Selenium + MySQL 的沪深 A 股股票数据爬取
要求:
▪ 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内
容。
▪ 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、
“深证A股”3个板块的股票数据信息。
o 候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
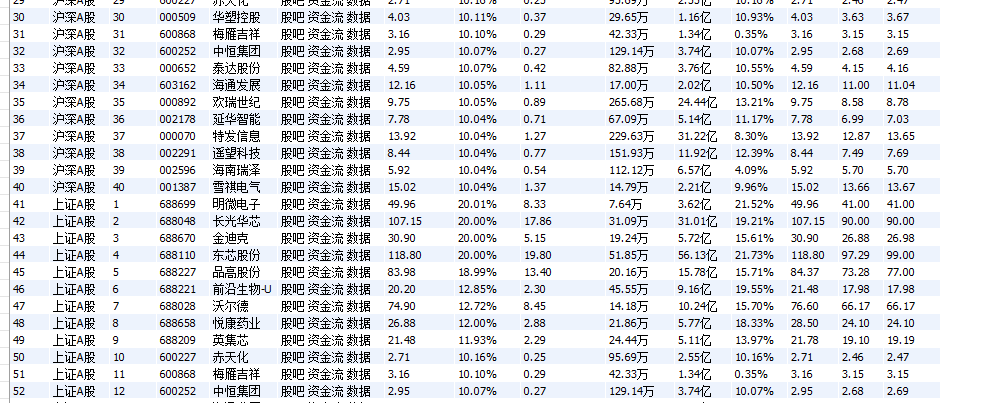
o 输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码:bStockNo……,由同学们自行定义设计表头:
思路:从前端检查找到对应所需按钮xpath,实现页面自动跳转或指定数据爬取
代码结果如下:
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
db = pymysql.connect(
host="localhost",
user="root",
password="xuzhian123",
database="stockdb",
charset="utf8mb4"
)
cursor = db.cursor()
def insert_stock(data):
sql = """
INSERT INTO eastmoney_stock(
board, xuhao, daima, mingcheng, zuixinbaojia,
zhangdiefu, zhangdiee, chengjiaoliang,
chengjiaoe, zhenfu, zuigao, zuidi,
jinkai, zuoshou
) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
cursor.execute(sql, data)
db.commit()
def crawl_board(board_name, url):
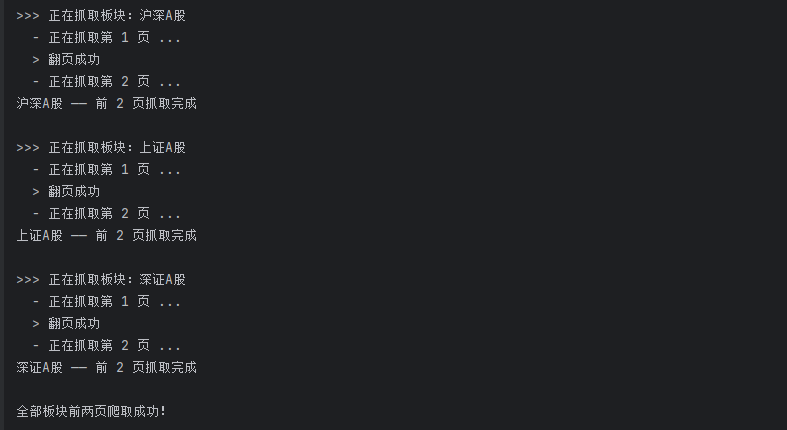
print(f"\n>>> 正在抓取板块:{board_name}")
driver.get(url)
wait = WebDriverWait(driver, 15)
time.sleep(2)
for page in range(1, 3):
print(f" - 正在抓取第 {page} 页 ...")
wait.until(EC.presence_of_element_located((By.XPATH, "//table//tbody/tr")))
rows = driver.find_elements(By.XPATH, "//table//tbody/tr")
for r in rows:
tds = r.find_elements(By.TAG_NAME, "td")
if len(tds) < 13:
continue
xuhao = tds[0].text.strip()
daima = tds[1].text.strip()
mingcheng = tds[2].text.strip()
zuixinbaojia = tds[3].text.strip()
zhangdiefu = tds[4].text.strip()
zhangdiee = tds[5].text.strip()
chengjiaoliang = tds[6].text.strip()
chengjiaoe = tds[7].text.strip()
zhenfu = tds[8].text.strip()
zuigao = tds[9].text.strip()
zuidi = tds[10].text.strip()
jinkai = tds[11].text.strip()
zuoshou = tds[12].text.strip()
if not daima.isdigit():
continue
data = (
board_name, xuhao, daima, mingcheng, zuixinbaojia,
zhangdiefu, zhangdiee, chengjiaoliang,
chengjiaoe, zhenfu, zuigao, zuidi,
jinkai, zuoshou
)
insert_stock(data)
if page < 2:
try:
next_btn = wait.until(
EC.element_to_be_clickable(
(By.XPATH, '//*[@id="mainc"]/div/div/div[4]/div/a[@title="下一页"]')
)
)
next_btn.click()
print(" > 翻页成功")
time.sleep(2)
except Exception as e:
print(" - 找不到下一页按钮,提前结束:", e)
break
print(f"{board_name} —— 前 2 页抓取完成")
if __name__ == "__main__":
driver = webdriver.Chrome()
boards = {
"沪深A股": "https://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"上证A股": "https://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"深证A股": "https://quote.eastmoney.com/center/gridlist.html#sz_a_board",
}
for name, url in boards.items():
crawl_board(name, url)
driver.quit()
db.close()
print("\n全部板块前两页爬取成功!")
作业二:基于 Selenium + MySQL 的中国大学MOOC课程信息爬取▪ 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、
等待HTML元素等内容。
▪ 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国mooc网:https://www.icourse163.org
o 输出信息:MYSQL数据库存储和输出格式
思路:与上一题相同,也是从前端检查找到对应所需按钮xpath,实现页面自动跳转或指定数据爬取,增添cookies验证登录爬取。
代码结果如下:
主爬虫:
import json, os, time, pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
COOKIE_FILE = "cookies.json"
# ---------- 基础工具 ----------
def safe_text(wait, xpath):
try: return wait.until(EC.presence_of_element_located((By.XPATH, xpath))).text.strip()
except: return ""
def safe_attr(wait, xpath, attr):
try: return wait.until(EC.presence_of_element_located((By.XPATH, xpath))).get_attribute(attr)
except: return ""
# ---------- 加载 cookie 登录 ----------
def load_cookies(driver):
if not os.path.exists(COOKIE_FILE):
print("cookies.json 不存在,请先生成 cookie!")
exit()
driver.get("https://www.icourse163.org/")
time.sleep(2)
for c in json.load(open(COOKIE_FILE, "r", encoding="utf-8")):
c.pop("sameSite", None)
c.pop("expiry", None)
try: driver.add_cookie(c)
except: pass
driver.get("https://www.icourse163.org/")
time.sleep(2)
print("使用 cookie 登录成功!")
# ---------- 获取老师 ----------
def get_all_teachers(driver):
all_teachers = []
def collect():
lst = []
try:
items = driver.find_elements(By.XPATH,
"//div[@class='m-teachers_teacher-list']//div[@class='um-list-slider_con_item']//img"
)
for img in items:
name = img.get_attribute("alt")
if name: lst.append(name)
except: pass
return lst
# 第 1 页
all_teachers += collect()
# 翻页按钮(0/1/2 个)
while True:
buttons = driver.find_elements(
By.XPATH, "//div[@class='um-list-slider_con']/div/div[1]/span"
)
if len(buttons) == 2: # 中间页:点右边按钮
buttons[1].click()
time.sleep(1.5)
all_teachers += collect()
else:
break
return all_teachers
# ---------- 单课程爬取 ----------
def crawl_course(driver, wait, url, cursor, db):
print(f"\n正在爬取:{url}")
driver.get(url)
time.sleep(2)
cCourse = safe_text(wait, "/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[2]/div[1]/span[1]")
cCollege = safe_attr(wait, "/html/body/div[5]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/a/img", "alt")
teachers = get_all_teachers(driver)
print(f"共找到 {len(teachers)} 位老师:{teachers}")
cTeacher = teachers[0] if teachers else ""
cTeam = ",".join(teachers)
cCount = safe_text(wait, "/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[3]/div/div[1]/div[4]/span[2]")
cProcess = safe_text(wait, "/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[3]/div/div[1]/div[2]/div/span[2]")
cBrief = safe_text(wait, "/html/body/div[5]/div[2]/div[2]/div[2]/div[1]/div[1]/div[2]/div[2]/div[1]")
cursor.execute("""
INSERT INTO course_info(url, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s)
""", (url, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
print(f"爬取完成:{cCourse}")
# ---------- 主程序 ----------
def main():
db = pymysql.connect(
host="localhost", user="root", password="xuzhian123",
database="mooc_comment_db", charset="utf8mb4"
)
cursor = db.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS course_info(
id INT AUTO_INCREMENT PRIMARY KEY,
url VARCHAR(255),
cCourse VARCHAR(255),
cCollege VARCHAR(255),
cTeacher VARCHAR(255),
cTeam TEXT,
cCount VARCHAR(50),
cProcess VARCHAR(255),
cBrief TEXT
);
""")
db.commit()
# selenium
driver = webdriver.Chrome(options=webdriver.ChromeOptions()
.add_experimental_option('excludeSwitches',['enable-logging']))
wait = WebDriverWait(driver, 20)
load_cookies(driver)
# 输入 URL
print("请输入课程 URL(可输入多个,用空格或换行分隔,输入空行结束):")
urls = []
while True:
line = input().strip()
if not line: break
urls.extend(line.split())
if not urls:
print("未输入任何 URL,程序退出。")
return
for url in urls:
crawl_course(driver, wait, url, cursor, db)
driver.quit()
db.close()
print("\n全部课程爬取完毕!")
if __name__ == "__main__":
main()保存cookie:
import json, time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
COOKIE_FILE = "cookies.json"
def save_cookies(driver):
with open(COOKIE_FILE, "w", encoding="utf-8") as f:
json.dump(driver.get_cookies(), f, ensure_ascii=False, indent=2)
print("Cookie 已保存到 cookies.json!")
def generate_cookie():
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
options.add_argument('--log-level=3')
driver = webdriver.Chrome(options=options)
wait = WebDriverWait(driver, 20)
print("请扫码登录,按回车继续…")
driver.get("https://www.icourse163.org/")
time.sleep(2)
# ---------- 打开登录弹窗 ----------
login_selectors = [
"/html/body/div[5]/div[2]/div[1]/div/div/div[1]/div[3]/div[3]/div",
"//div[contains(text(),'登录')]"
]
for sel in login_selectors:
try:
wait.until(EC.element_to_be_clickable((By.XPATH, sel))).click()
print("已打开登录弹窗")
break
except:
pass
else:
print("无法找到主页登录按钮")
driver.quit()
return
time.sleep(2)
# ---------- 切换二维码登录方式 ----------
qrcode_selectors = [
"/html/body/div[13]/div/div[2]/div/div/div/div/div/div[1]/div/div[2]/div[2]/img",
"//img[contains(@alt,'码') or contains(@title,'码')]",
"//div[contains(@class,'qrcode')]//img",
"//*[contains(text(),'扫码登录') or contains(text(),'二维码')]"
]
for sel in qrcode_selectors:
try:
wait.until(EC.element_to_be_clickable((By.XPATH, sel))).click()
print("已切换到二维码登录方式,请扫码...")
break
except:
pass
input("扫码完成后按回车继续...")
save_cookies(driver)
driver.quit()
if __name__ == "__main__":
generate_cookie()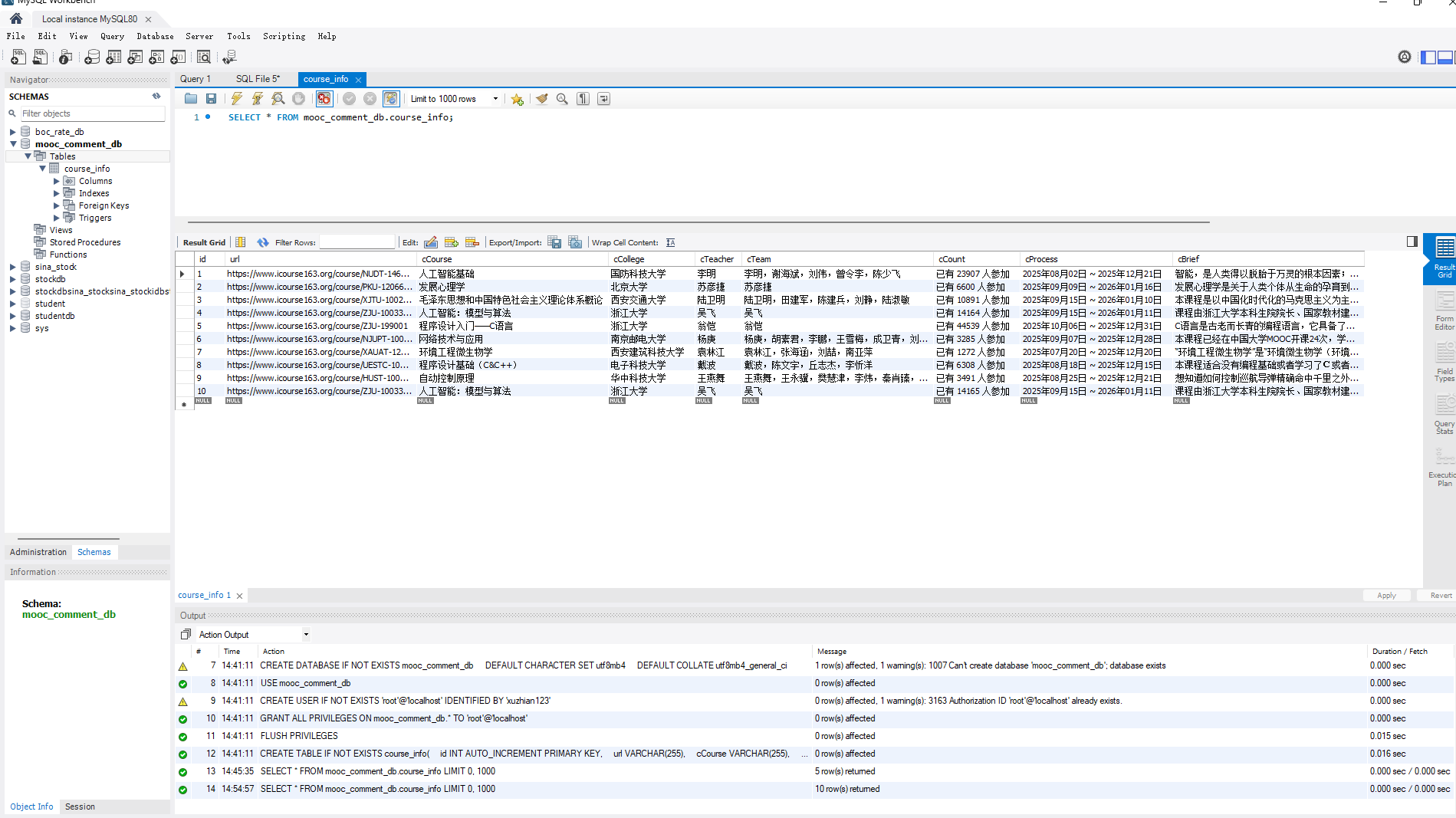
作业心得:对Selenium的认识更进一步
• 作业③:
• 掌握大数据相关服务,熟悉Xshell的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部
分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
• 环境搭建:
·任务一:开通MapReduce服务
• 实时分析开发实战:
·任务一:Python脚本生成测试数据
·任务二:配置Kafka
·任务三: 安装Flume客户端
·任务四:配置Flume采集数据
输出:实验关键步骤或结果截图。
实验二:大数据实时分析
1.1申请弹性公网IP

1.2购买MapReduce集群

1.3开通云数据库服务RDS
1.4创建弹性资源池


1.5开通数据可视化服务(DLV)
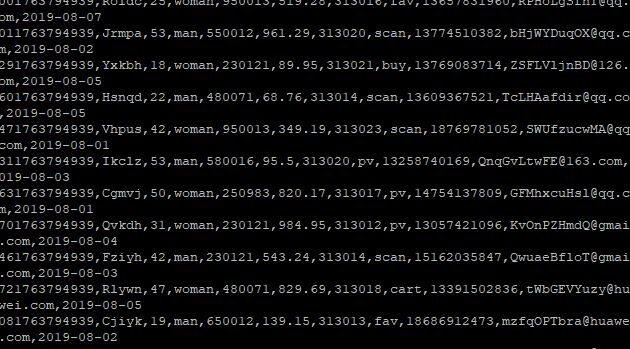
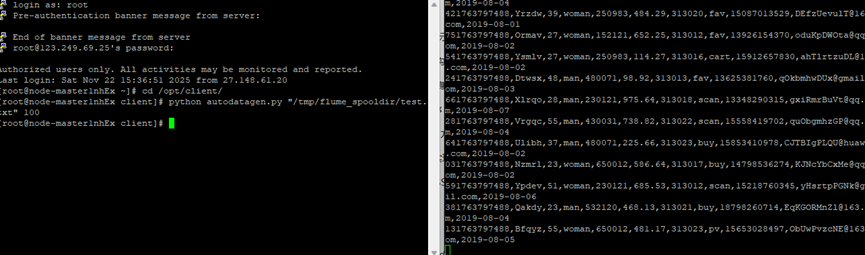
 2.1 Python脚本生成测试数据
2.1 Python脚本生成测试数据
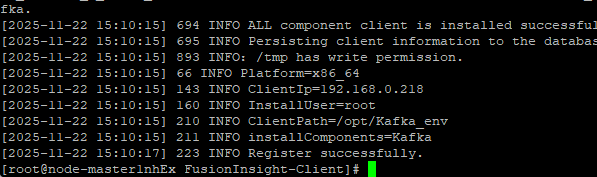
2.2配置Kafka
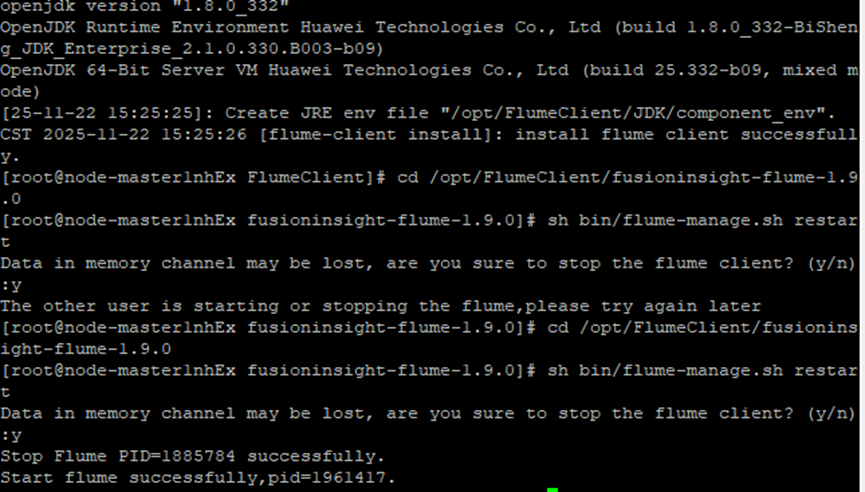
2.3安装Flume客户端
2.4配置Flume采集数据
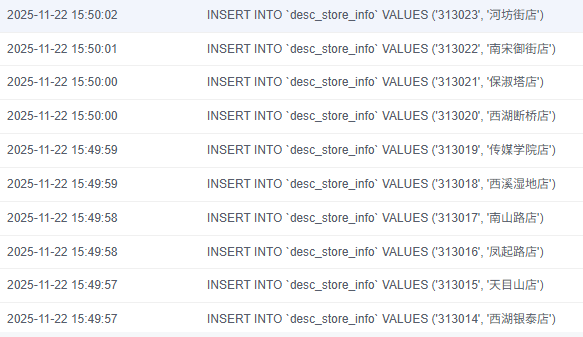
2.5 MySQL中准备结果表与维度表数据
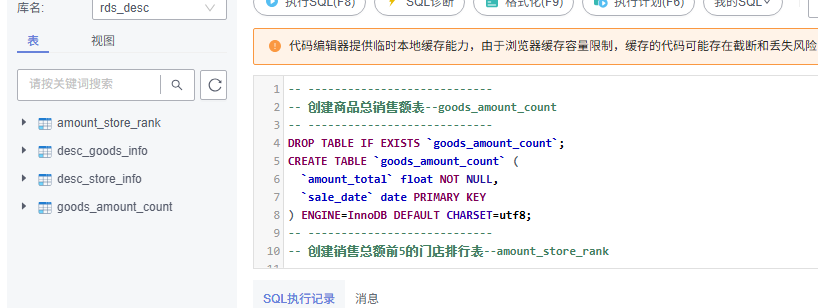
创建Flink作业的结果表,查看创建表
2.6使用DLI中的Flink作业进行数据分析
编辑Flink作业的SQL脚本
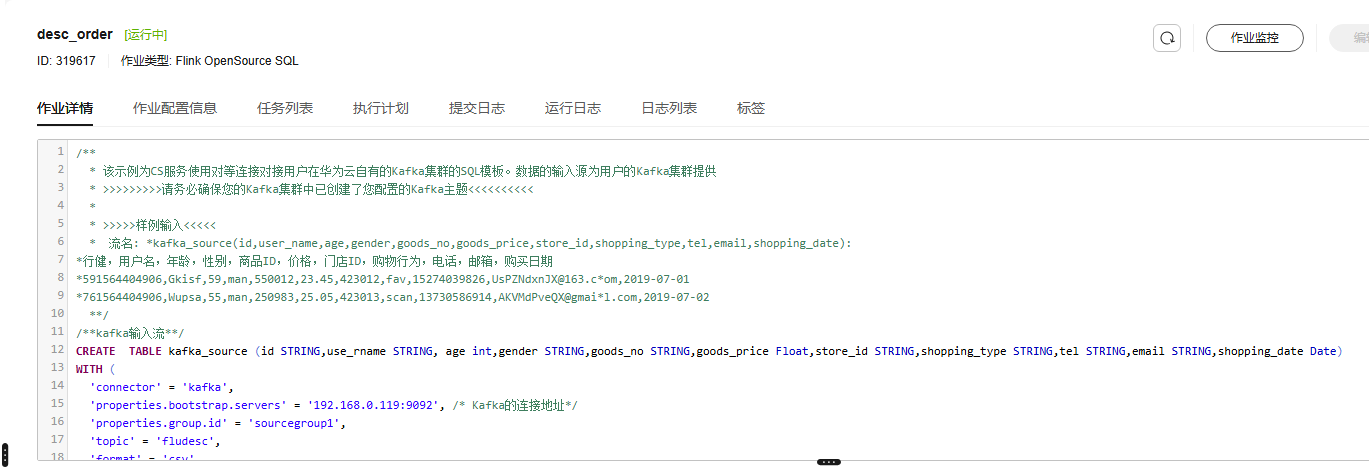
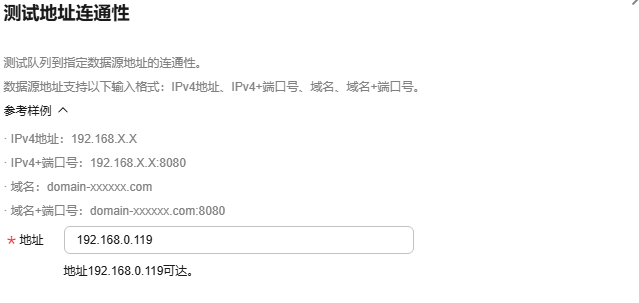
测试地址连通性
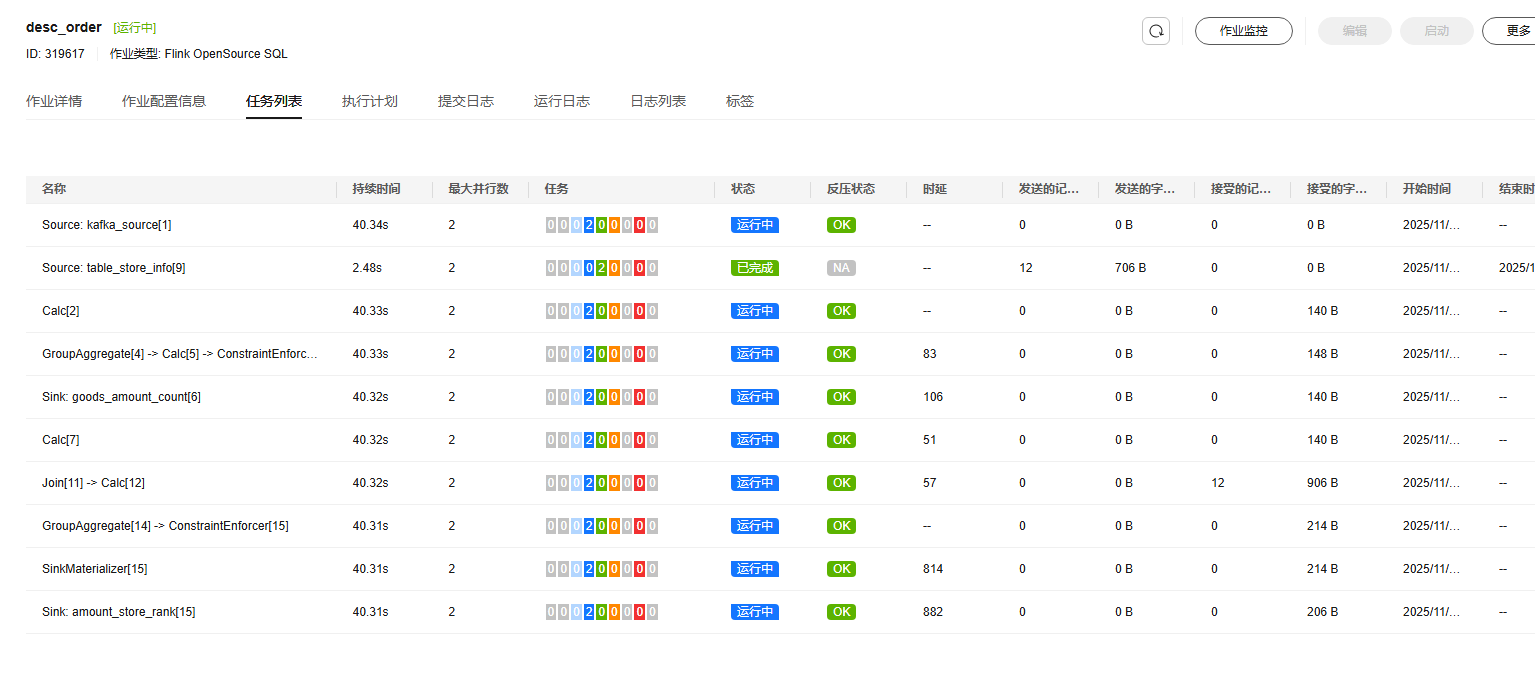
查看作业运行详情
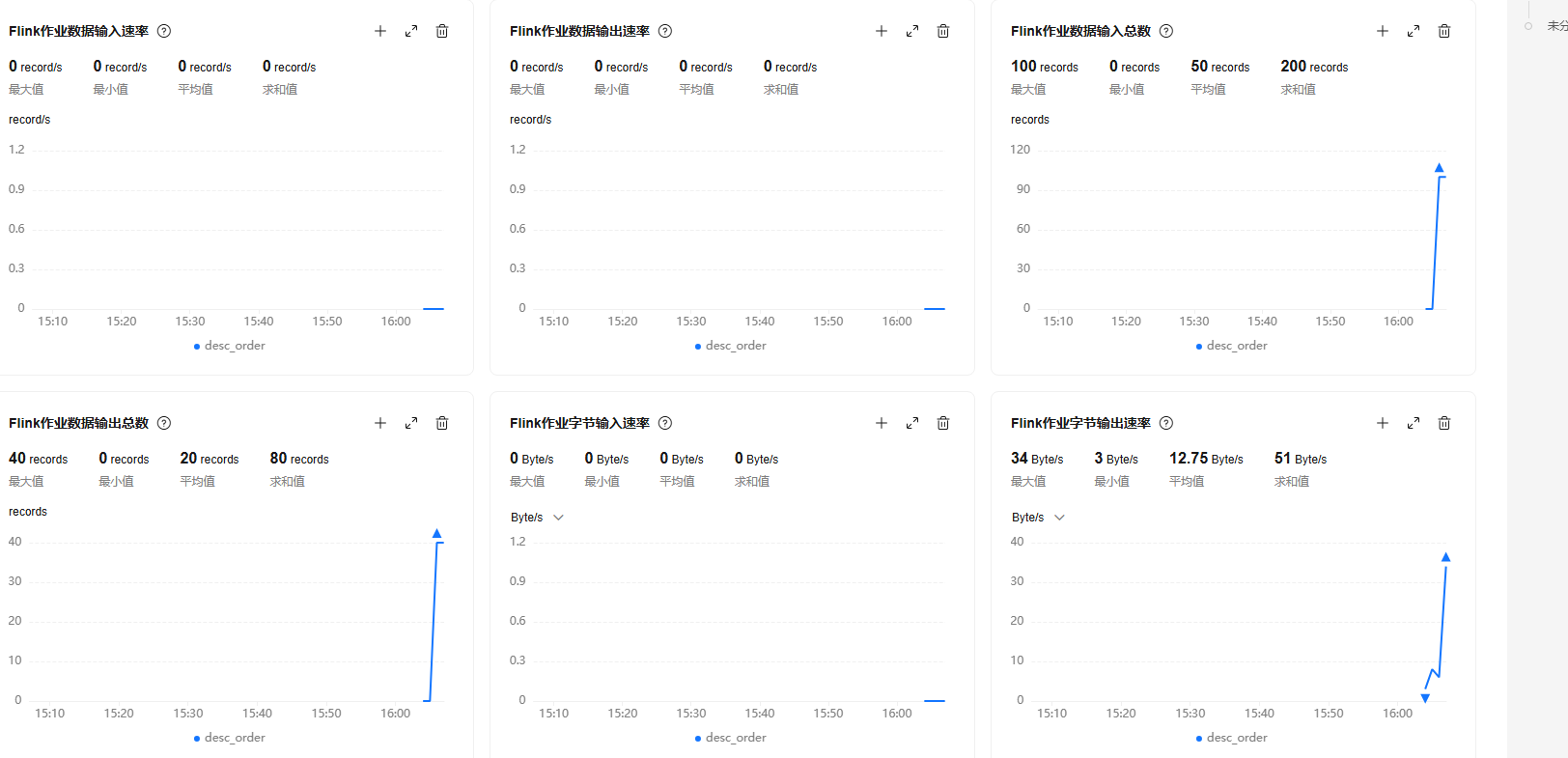
2.7 DLV数据可视化
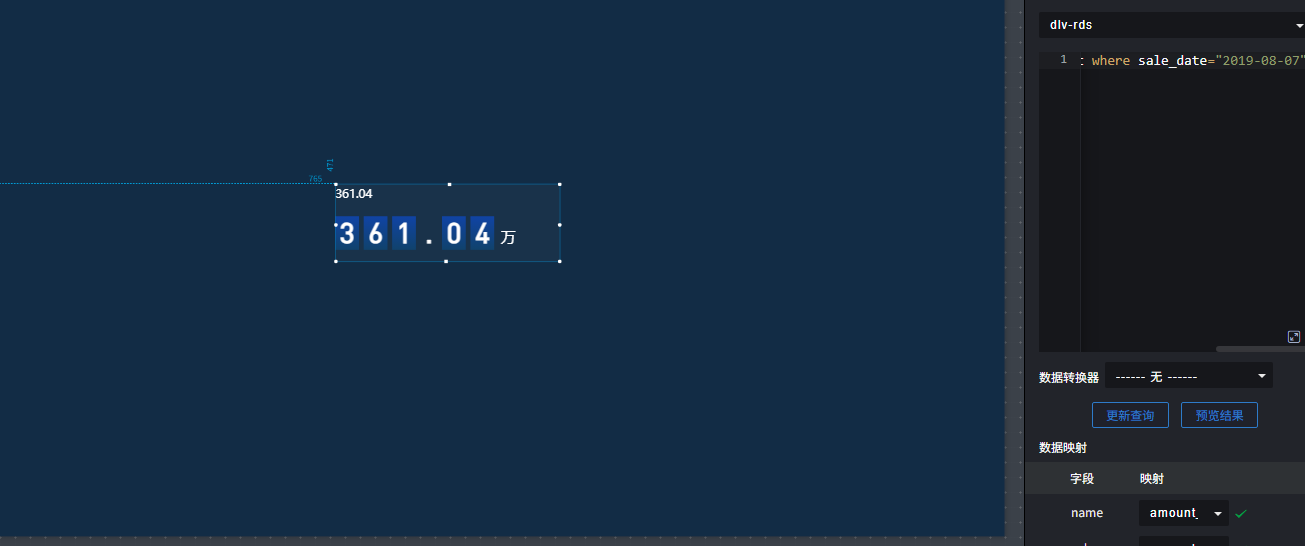
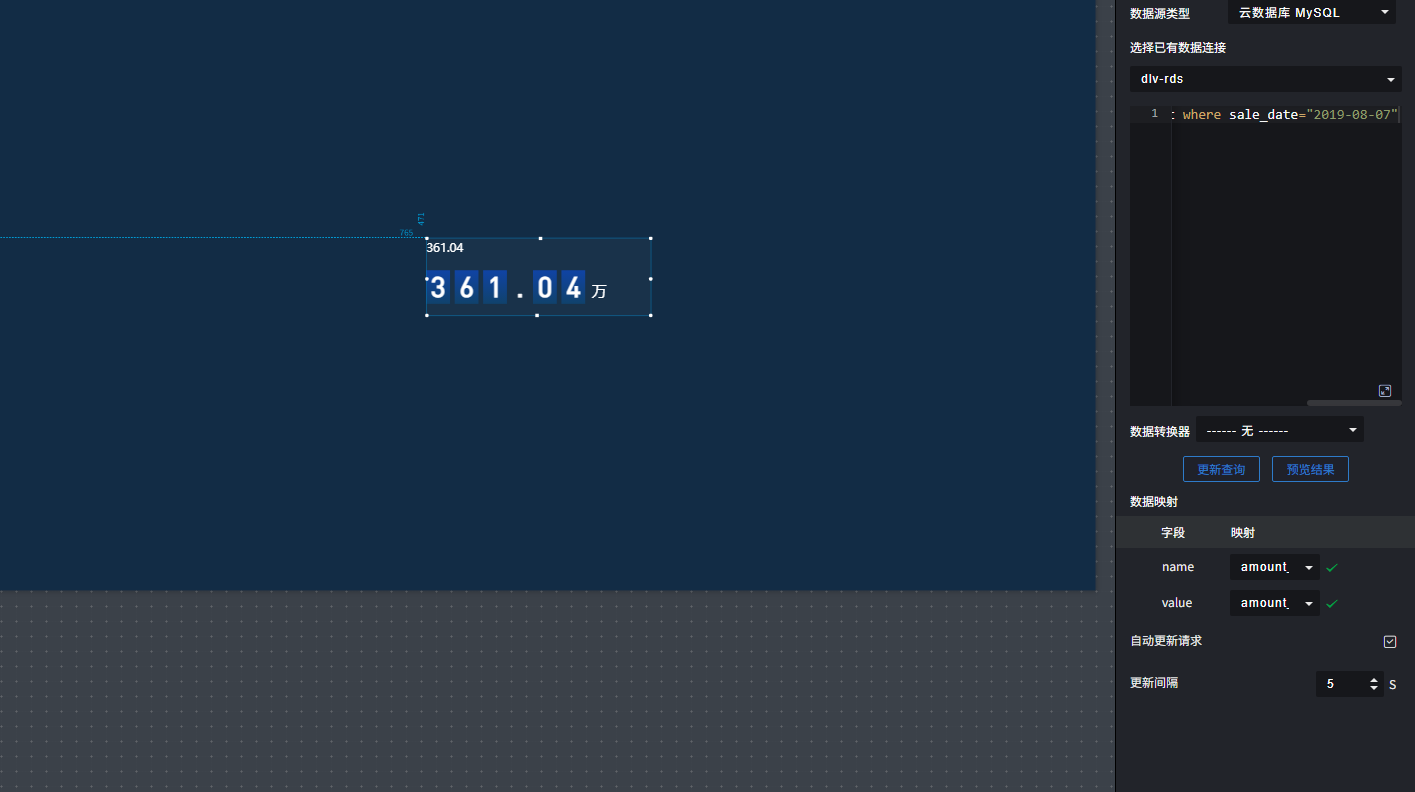
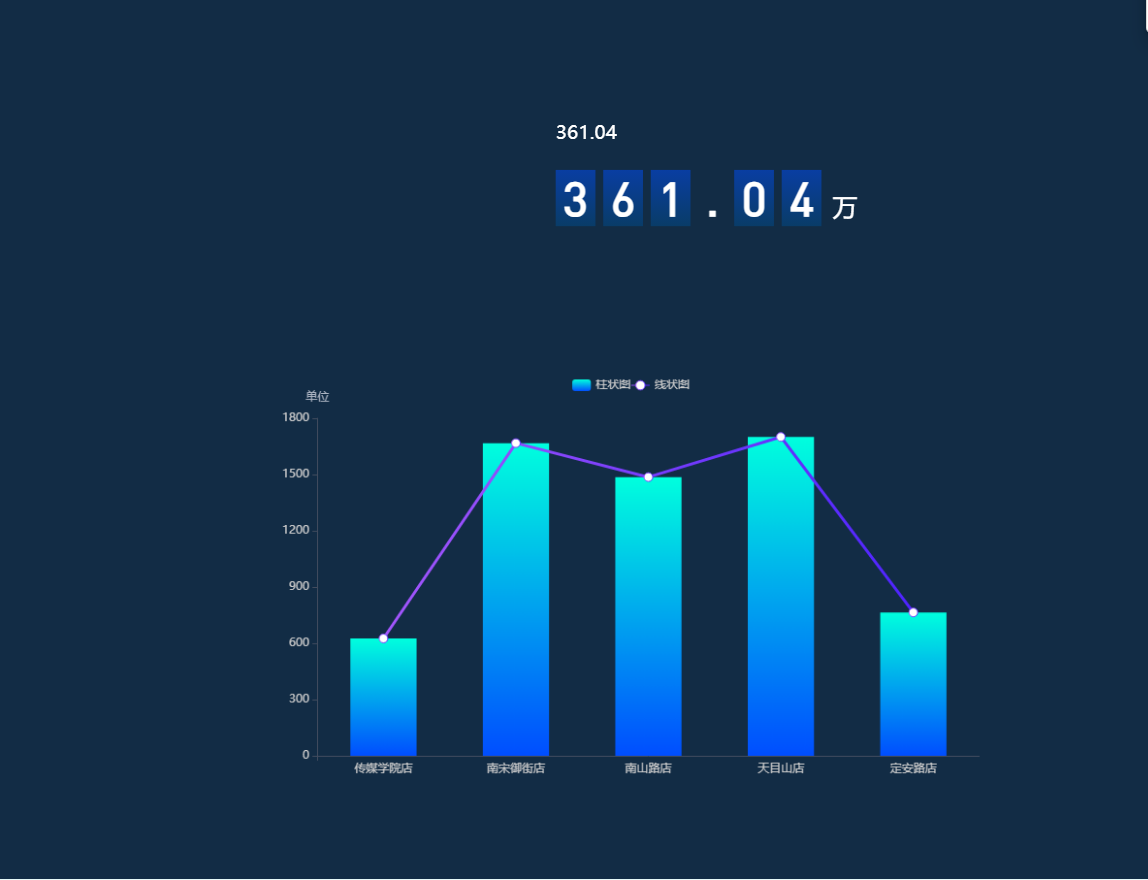

 浙公网安备 33010602011771号
浙公网安备 33010602011771号