
102302122许志安作业3

要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
代码如下:
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor
BASE_URL = "http://www.weather.com.cn"
SAVE_DIR = "images"
os.makedirs(SAVE_DIR, exist_ok=True)
HEADERS = {"User-Agent": "Mozilla/5.0"}
def get_image_urls(url):
try:
html = requests.get(url, headers=HEADERS, timeout=10).text
soup = BeautifulSoup(html, "html.parser")
return [urljoin(url, img.get("src")) for img in soup.find_all("img") if img.get("src")]
except Exception as e:
print(f"[获取失败] {e}")
return []
def download(img_url):
try:
name = os.path.join(SAVE_DIR, os.path.basename(img_url.split("?")[0]))
r = requests.get(img_url, headers=HEADERS, timeout=10)
if r.ok and "image" in r.headers.get("Content-Type", ""):
with open(name, "wb") as f: f.write(r.content)
print(f"[下载成功] {img_url}")
except Exception as e:
print(f"[失败] {img_url} -> {e}")
if __name__ == "__main__":
imgs = get_image_urls(BASE_URL)
print(f"共发现 {len(imgs)} 张图片:")
for i in imgs: print(i)
mode = input("\n选择下载方式:1.单线程 2.多线程 > ").strip()
if mode == "1":
for i in imgs: download(i)
else:
with ThreadPoolExecutor(10) as ex: ex.map(download, imgs)
结果: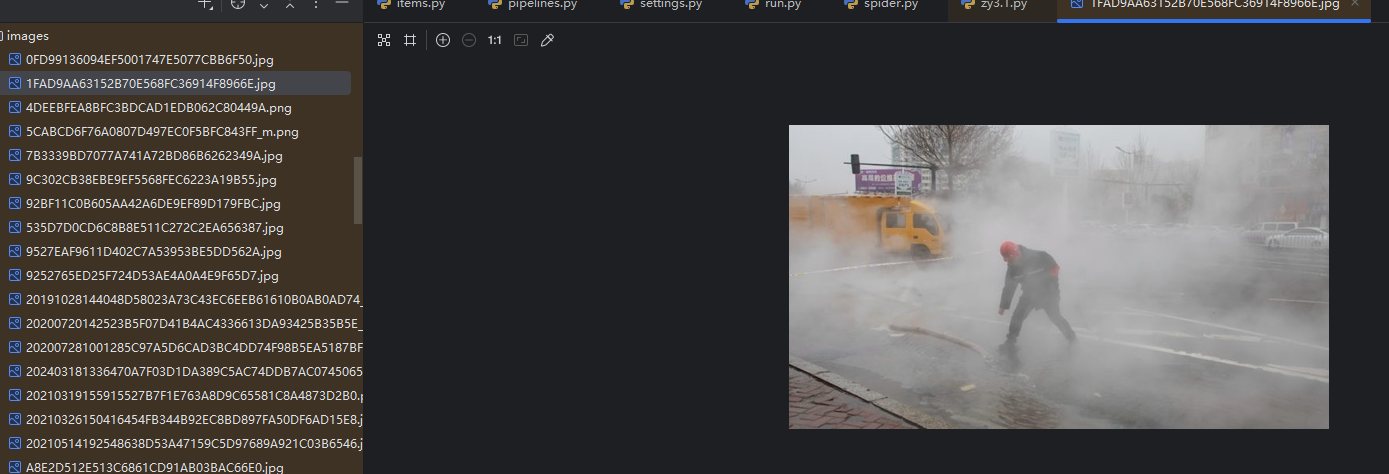
spider代码如下:
import scrapy
import json
from sina_stock.items import SinaStockItem
class StockSpider(scrapy.Spider):
name = "stock_spider"
allowed_domains = ["vip.stock.finance.sina.com.cn"]
start_urls = [
"https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?node=hs_a&page=1"
]
def parse(self, response):
data = json.loads(response.text)
for stock in data:
item = SinaStockItem()
item["bStockNo"] = stock.get("code")
item["bName"] = stock.get("name")
item["bPrice"] = stock.get("trade")
item["bChangeRate"] = stock.get("changepercent")
item["bChange"] = stock.get("pricechange")
item["bVolume"] = stock.get("volume")
item["bAmount"] = stock.get("amount")
item["bAmplitude"] = stock.get("amplitude")
item["bHigh"] = stock.get("high")
item["bLow"] = stock.get("low")
item["bOpen"] = stock.get("open")
item["bPrevClose"] = stock.get("settlement")
yield item
# 翻页逻辑(抓取前 5 页)
current_page = int(response.url.split("=")[-1])
if current_page < 5:
next_page = current_page + 1
next_url = f"https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?node=hs_a&page={next_page}"
yield scrapy.Request(next_url, callback=self.parse)
结果: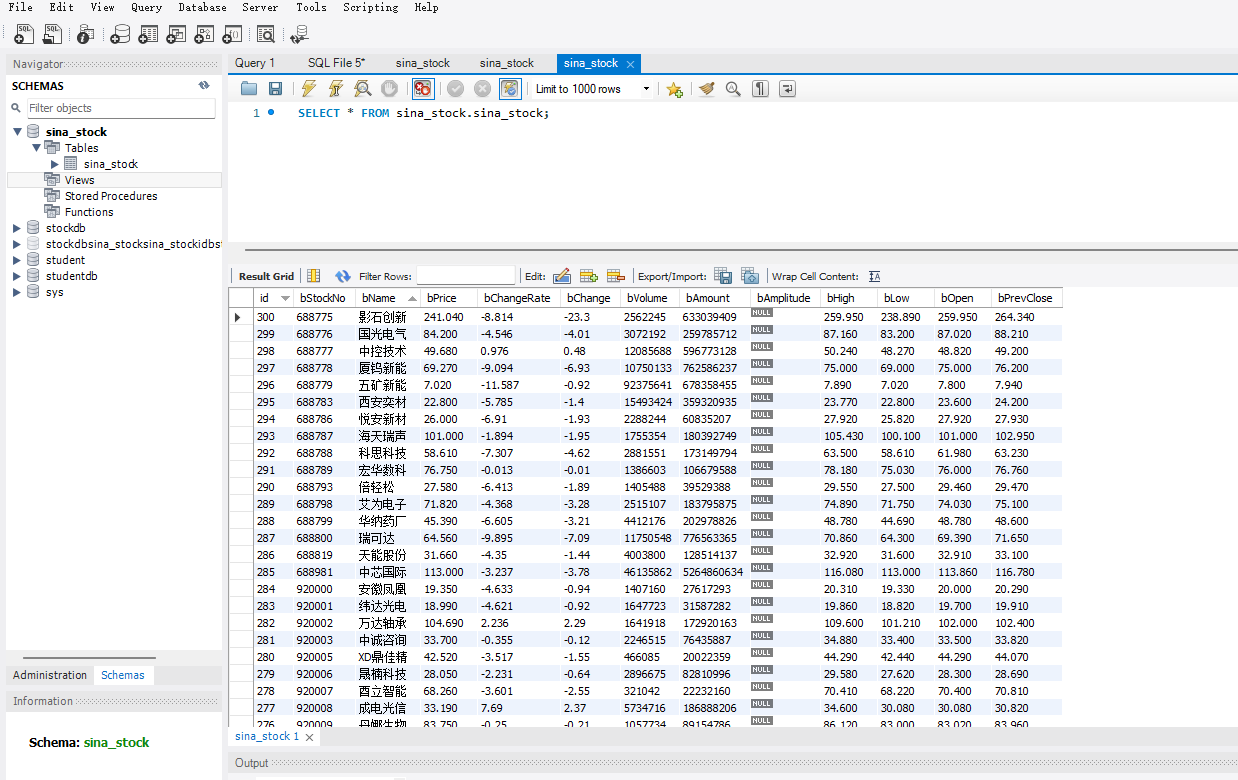

spider代码如下:
# boc_rate/spiders/boc_spider.py
import scrapy
from boc_rate.items import BocRateItem
class BocSpider(scrapy.Spider):
name = "boc_rate"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
custom_settings = {
'ROBOTSTXT_OBEY': False
}
def parse(self, response):
rows = response.xpath('//table//tr')[1:]
for row in rows:
item = BocRateItem()
item['货币名称'] = row.xpath('./td[1]/text()').get(default='').strip()
item['现汇买入价'] = row.xpath('./td[2]/text()').get(default='').strip()
item['现钞买入价'] = row.xpath('./td[3]/text()').get(default='').strip()
item['现汇卖出价'] = row.xpath('./td[4]/text()').get(default='').strip()
item['现钞卖出价'] = row.xpath('./td[5]/text()').get(default='').strip()
item['中行折算价'] = row.xpath('./td[6]/text()').get(default='').strip()
item['发布日期'] = row.xpath('./td[7]/text()').get(default='').strip()
item['发布时间'] = row.xpath('./td[8]/text()').get(default='').strip()
yield item
结果: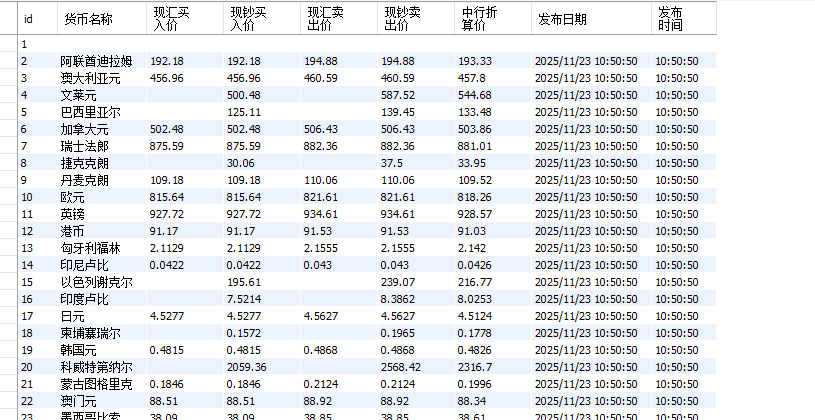

 浙公网安备 33010602011771号
浙公网安备 33010602011771号